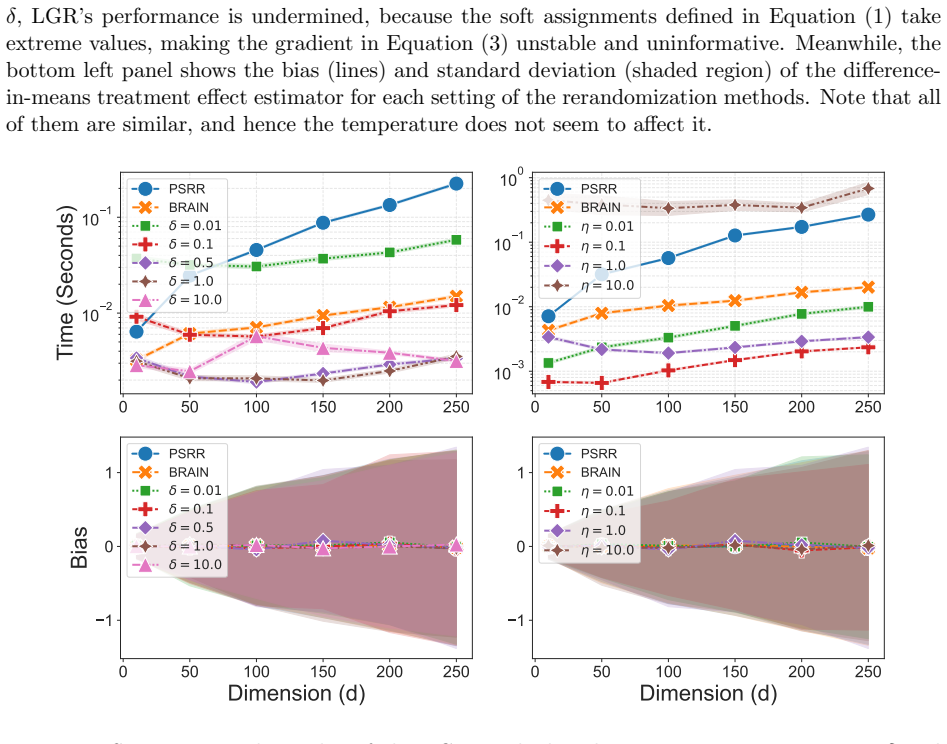
Recognition: unknown
Langevin-Gradient Rerandomization
Pith reviewed 2026-05-10 17:27 UTC · model grok-4.3
The pith
Langevin-Gradient Rerandomization finds balanced treatment assignments in high dimensions by using stochastic gradient Langevin dynamics on a continuous relaxation of the assignment problem.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
LGR mitigates the dimensionality challenge in rerandomization by navigating a continuous relaxation of the treatment assignment space using Stochastic Gradient Langevin Dynamics. It samples from a non-uniform distribution over balanced randomizations but retains valid inference via randomization tests, and generates acceptable assignments orders of magnitude faster than rejection sampling or other discrete methods in high dimensions.
What carries the argument
Stochastic Gradient Langevin Dynamics (SGLD) applied to the continuous relaxation of the binary treatment assignment vector, driven by the gradient of a covariate balance metric.
If this is right
- Rerandomization becomes practical for experiments with many covariates.
- Statistical analyses gain increased precision and power without relying on model assumptions.
- Randomization tests continue to deliver exact or asymptotically valid inference despite non-uniform sampling.
- Experiments can mitigate p-hacking through better balanced designs at lower computational cost.
Where Pith is reading between the lines
- The continuous relaxation might be adaptable to other combinatorial problems in causal inference or optimization.
- Further work could examine the finite-sample properties of the non-uniform distribution under LGR.
- Integration with modern balance metrics from machine learning could enhance the method further.
Load-bearing premise
The continuous relaxation approximates the discrete assignment problem sufficiently well that randomization tests still yield valid inference despite the non-uniform sampling distribution.
What would settle it
A Monte Carlo simulation showing that randomization tests under LGR produce confidence intervals with coverage rates significantly below the nominal level in high-dimensional settings would falsify the validity of the inference procedure.
Figures


read the original abstract
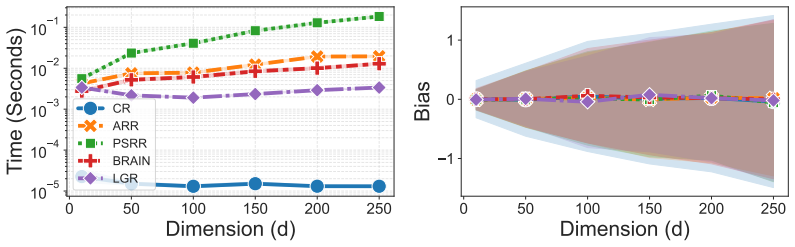
Rerandomization is an experimental design technique that repeatedly randomizes treatment assignments until covariates are balanced between treatment groups. Rerandomization in the design stage of an experiment can lead to many asymptotic benefits in the analysis stage, such as increased precision, increased statistical power for hypothesis testing, reduced sensitivity to model specification, and mitigation of p-hacking. However, the standard implementation of rerandomization via rejection sampling faces a severe computational bottleneck in high-dimensional settings, where the probability of finding an acceptable randomization vanishes. Although alternatives based on Metropolis-Hastings and constrained optimization techniques have been proposed, these alternatives rely on discrete procedures that lack information from the gradient of the covariate balance metric, limiting their efficiency in high-dimensional spaces. We propose Langevin-Gradient Rerandomization (LGR), a new sampling method that mitigates this dimensionality challenge by navigating a continuous relaxation of the treatment assignment space using Stochastic Gradient Langevin Dynamics. We discuss the trade-offs of this approach, specifically that LGR samples from a non-uniform distribution over the set of balanced randomizations. We demonstrate how to retain valid inference under this design using randomization tests and empirically show that LGR generates acceptable randomizations orders of magnitude faster than current rerandomization methods in high dimensions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Langevin-Gradient Rerandomization (LGR), a method that applies Stochastic Gradient Langevin Dynamics to a continuous relaxation of the binary treatment assignment space in order to generate covariate-balanced randomizations much faster than rejection sampling in high dimensions. It explicitly acknowledges that LGR induces a non-uniform distribution over acceptable assignments and outlines a procedure for performing valid randomization tests under this design, while reporting empirical speed-ups of orders of magnitude relative to existing rerandomization techniques.
Significance. If the validity argument for randomization inference under the induced non-uniform distribution can be made rigorous, the work would address a genuine computational barrier in high-dimensional experimental design and could enable more widespread use of rerandomization for improved precision and power. The explicit use of gradient information from the balance metric is a natural and potentially powerful extension of existing discrete methods; the empirical demonstration of substantial speed gains is a concrete strength that would be strengthened by quantitative reporting.
major comments (2)
- [§4] §4 (Inference under LGR): The manuscript states that randomization tests can be used to retain valid inference despite the non-uniform distribution, yet provides no explicit derivation, theorem, or finite-sample calibration study showing that the combination of continuous relaxation, SGLD approximation, and discrete mapping yields p-values that are either exactly valid or asymptotically valid under the actual sampling distribution employed. This is load-bearing for the central claim that LGR preserves the inferential benefits of rerandomization.
- [§5] §5 (Empirical results): The reported speed gains are described only qualitatively (“orders of magnitude faster”); the section contains no tables or figures with concrete metrics such as wall-clock time ratios, effective sample size per second, or acceptance rates across increasing covariate dimensions, making it impossible to assess the practical magnitude of the improvement or to compare against the Metropolis-Hastings and constrained-optimization baselines mentioned in the introduction.
minor comments (2)
- Notation for the continuous relaxation (e.g., the precise form of the target density on [-1,1]^n and the discretization map back to {-1,+1}^n) is introduced without a dedicated equation or algorithm box, making it difficult to reproduce the exact procedure.
- The abstract and introduction refer to “acceptable randomizations” without defining the balance threshold or the precise form of the balance metric used inside the Langevin dynamics; a single clarifying sentence or equation would improve readability.
Simulated Author's Rebuttal
We thank the referee for their constructive and insightful comments on our manuscript. We address each major comment below and will revise the paper to incorporate additional rigor and quantitative detail as suggested.
read point-by-point responses
-
Referee: [§4] §4 (Inference under LGR): The manuscript states that randomization tests can be used to retain valid inference despite the non-uniform distribution, yet provides no explicit derivation, theorem, or finite-sample calibration study showing that the combination of continuous relaxation, SGLD approximation, and discrete mapping yields p-values that are either exactly valid or asymptotically valid under the actual sampling distribution employed. This is load-bearing for the central claim that LGR preserves the inferential benefits of rerandomization.
Authors: We appreciate the referee's emphasis on this central point. The manuscript outlines that randomization tests remain valid under the non-uniform distribution induced by LGR because the test conditions on assignments drawn from the same distribution used in the design. However, we agree that an explicit derivation and supporting calibration would strengthen the argument. In the revised manuscript we will add a formal proposition establishing exact finite-sample validity of the randomization test under the LGR sampling measure (leveraging the fact that the test statistic is evaluated under the identical distribution), together with a small-scale simulation study that reports empirical type-I error rates across dimensions to confirm calibration. revision: yes
-
Referee: [§5] §5 (Empirical results): The reported speed gains are described only qualitatively (“orders of magnitude faster”); the section contains no tables or figures with concrete metrics such as wall-clock time ratios, effective sample size per second, or acceptance rates across increasing covariate dimensions, making it impossible to assess the practical magnitude of the improvement or to compare against the Metropolis-Hastings and constrained-optimization baselines mentioned in the introduction.
Authors: We concur that quantitative benchmarks are necessary for a clear evaluation of computational performance. In the revision we will expand §5 with a new table and figure that report wall-clock times, acceptance rates, effective sample sizes per second, and scaling behavior for LGR versus the Metropolis-Hastings and constrained-optimization baselines across a range of covariate dimensions (e.g., p = 10 to p = 500). These additions will enable direct numerical comparison of the reported speed-ups. revision: yes
Circularity Check
No significant circularity; proposal is self-contained
full rationale
The paper introduces LGR by applying established Stochastic Gradient Langevin Dynamics to a continuous relaxation of the discrete assignment problem, explicitly noting the resulting non-uniform distribution over balanced randomizations and describing how randomization tests can still be used for valid inference. No load-bearing step reduces by construction to a fitted parameter, self-definition, or self-citation chain; the speed claims rest on external empirical comparisons, and the validity discussion invokes standard design-based inference principles rather than re-deriving them from the method's own outputs. This matches the default expectation of a non-circular algorithmic proposal.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
doi: 10.1016/bs.hefe.2016.10.003. Yuehao Bai. Optimality of matched-pair designs in randomized controlled trials.American Eco- nomic Review, 112:3911–3940,
-
[2]
Zach Branson, Tirthankar Dasgupta, and Donald B
doi: 10.1257/aer.20201856. Zach Branson, Tirthankar Dasgupta, and Donald B. Rubin. Improving covariate balance in 2 K factorial designs via rerandomization with an application to a New York City Department of Education High School Study.The Annals of Applied Statistics, 10:1958–1976,
-
[3]
Miriam Bruhn and David McKenzie
doi: 10.1093/biomet/asad027. Miriam Bruhn and David McKenzie. In pursuit of balance: Randomization in practice in develop- ment field experiments.American Economic Journal: Applied Economics, 1:200–232,
-
[4]
doi: 10.1257/app.1.4.200. B. P. Carlin, T. D. Cook, J. J. Faraway, J. Zidek, M. A. Tanner, and D. L. DeMets.Introduction to Statistical Methods for Clinical Trials. Chapman & Hall/CRC,
-
[5]
doi: 10.1111/j.2517-6161. 1950.tb00062.x. Feifang Hu and William F. Rosenberger.The Theory of Response-Adaptive Randomization in Clinical Trials. John Wiley & Sons,
-
[6]
doi: 10.1002/sim.3337. H. L. Jones. Inadmissible samples and confidence limits.Journal of the American Statistical Association, 53:482–490,
-
[7]
doi: 10.1080/01621459.1958.10501453. A. M. Krieger, D. Azriel, and A. Kapelner. Nearly random designs with greatly improved balance. Biometrika, 106:695–701,
-
[8]
doi: 10.1093/biomet/asz026. Xinran Li and Peng Ding. Rerandomization and regression adjustment.Journal of the Royal Statistical Society Series B: Statistical Methodology, 82:241–268,
-
[9]
Xinran Li, Peng Ding, and Donald B
doi: 10.1111/rssb.12353. Xinran Li, Peng Ding, and Donald B. Rubin. Asymptotic theory of rerandomization in treat- ment–control experiments.Proc. Natl. Acad. Sci. U.S.A., 115:9157–9162,
-
[10]
doi: 10.1214/18-AOS1790. 11 J. A. List.Experimental Economics: Theory and Practice. The University of Chicago Press,
-
[11]
arXiv:2312.17230. Xin Lu and Peng Ding. Rerandomization for covariate balance mitigates p-hacking in regression adjustment.preprint,
-
[12]
Xin Lu, Tianle Liu, Hanzhong Liu, and Peng Ding
arXiv:2505.01137. Xin Lu, Tianle Liu, Hanzhong Liu, and Peng Ding. Design-based theory for cluster rerandomization. Biometrika, 110:467–483,
-
[13]
doi: 10.1093/biomet/asac045. Luke W. Miratrix, Jasjeet S. Sekhon, and Bin Yu. Adjusting treatment effect estimates by post- stratification in randomized experiments.Journal of the Royal Statistical Society Series B: Sta- tistical Methodology, 75:369–396,
-
[14]
doi: 10.1111/j.1467-9868.2012.01048.x. Kari Lock Morgan and Donald B. Rubin. Rerandomization to improve covariate balance in exper- iments.Annals of Statistics, 40:1263–1282,
-
[15]
doi: 10.1214/12-AOS1008. F. Mosteller.Evidence Matters: Randomized Trials in Education Research. Brookings Institution Press,
-
[16]
doi: 10.3102/10769986211027240. Antˆ onio C. H. Ribeiro Junior and Zach Branson. Does Rerandomization Help Beyond Covariate Adjustment? A Review and Guide for Theory and Practice.preprint,
- [17]
-
[18]
doi: 10.1214/08-STS269. William F. Rosenberger and John M. Lachin.Randomization in Clinical Trials: Theory and Prac- tice. John Wiley & Sons,
-
[19]
doi: 10.1198/016214508000001011. Donald B. Rubin. Estimating causal effects of treatments in randomized and nonrandomized stud- ies.Journal of Educational Psychology, 66:688–701,
-
[20]
doi: 10.1037/h0037350. L. J. Savage.The Foundations of Statistical Inference. John Wiley & Sons Inc.,
-
[21]
Wenqi Shi, Anqi Zhao, and Hanzhong Liu
arXiv:2403.12815. Wenqi Shi, Anqi Zhao, and Hanzhong Liu. Rerandomization and covariate adjustment in split-plot designs.Journal of Business & Economic Statistics, pages 1–22,
-
[22]
doi: 10.1080/07350015. 2024.2429464. 12 Max Tabord-Meehan. Stratification trees for adaptive randomization in randomized controlled trials. arxiv:1806.05127,
-
[23]
arXiv:2406.02834. Yuhao Wang and Xinran Li. Asymptotic theory of the best-choice rerandomization using the Mahalanobis distance.Journal of Econometrics, 251,
-
[24]
Zihao Yang, Tianyi Qu, and Xinran Li
doi: 10.1016/j.jeconom.2025.106049. Zihao Yang, Tianyi Qu, and Xinran Li. Rejective sampling, rerandomization, and regression adjust- ment in survey experiments.Journal of the American Statistical Association, 118(542):1207–1221,
-
[25]
doi: 10.1080/01621459.2021.1984926. Anqi Zhao and Peng Ding. No star is good news: A unified look at rerandomization based on p- values from covariate balance tests.Journal of Econometrics, 241,
-
[26]
doi: 10.1016/j.jeconom. 2024.105724. Quan Zhou, Philip A. Ernst, Kari Lock Morgan, Donald B. Rubin, and Anru Zhang. Sequential rerandomization.Biometrika, 105:745–752,
-
[27]
doi: 10.1093/biomet/asy031. Ke Zhu and Hanzhong Liu. Pair-Switching Rerandomization.Biometrics, 79:2127–2142,
-
[28]
doi: 10.1111/biom.13712. A Proofs A.1 Proof of Theorem 3.4 Proof.Let Ω denote the set of all possible trajectories (chains) of the latent variable vectors gen- erated by the LGR algorithm: θ(0), ..., θ(t), ..., θ(T) ,whereθ (t) ∈R n. Letπbe any permutation of the indices{1, ..., n}. Consider any realized chainϑ= ϑ(0), ..., ϑ(T) ∈Ω.We compare the probabili...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.