Recognition: unknown
Program Analysis Guided LLM Agent for Proof-of-Concept Generation
Pith reviewed 2026-05-10 17:00 UTC · model grok-4.3
The pith
A hybrid system that feeds lightweight static analysis and sanitizer coverage to an LLM agent raises proof-of-concept generation success by 132 percent over prior agentic methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
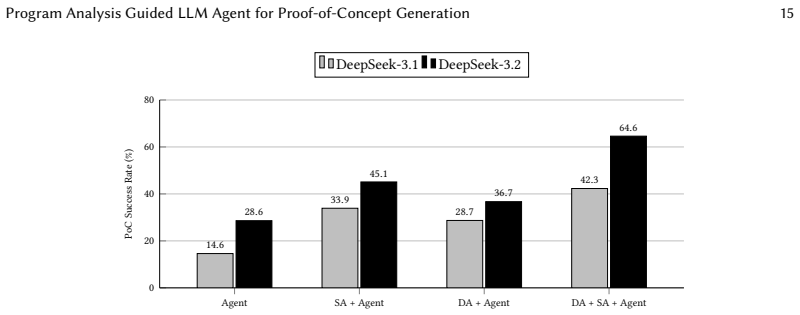
The paper claims that PAGENT, by interleaving lightweight static analysis guidance and sanitizer-derived dynamic coverage information with an LLM PoC generation agent, produces a scalable hybrid method whose success rate on automated vulnerability reproduction is 132 percent higher than the strongest prior agentic approach.
What carries the argument
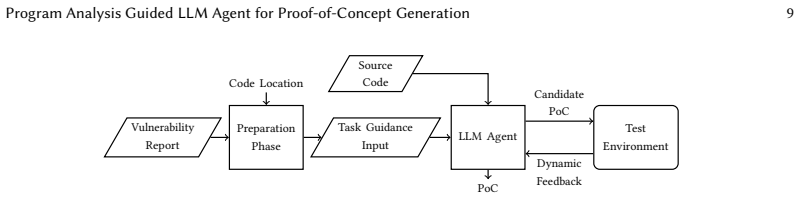
PAGENT, the agent that receives static-analysis rules and sanitizer coverage signals to steer its generation of trigger inputs for a given vulnerability location.
If this is right
- Developers can obtain concrete trigger inputs for reported vulnerabilities with far less manual reproduction effort.
- Security teams can respond to vulnerability disclosures at larger scale without relying on expert-guided symbolic or fuzzing pipelines.
- The same guidance pattern could reduce the expert steps currently needed when symbolic execution or fuzzing is applied to PoC tasks.
- Automated reproduction becomes feasible for projects whose size previously made manual or expert-assisted methods impractical.
Where Pith is reading between the lines
- Similar static-plus-sanitizer guidance layers could be tested on LLM agents for adjacent tasks such as generating regression tests or localizing bugs.
- If the guidance remains effective when the underlying sanitizer or static checker changes, the approach may transfer across different language runtimes.
- The performance gain might shrink on vulnerabilities whose triggering conditions lie outside the coverage signals the sanitizers currently report.
Load-bearing premise
The lightweight static analysis phases and the sanitizer coverage data must deliver accurate, non-misleading signals that the LLM agent can reliably exploit.
What would settle it
On a held-out collection of vulnerabilities, measure whether PAGENT's PoC success rate fails to exceed the prior top agentic baseline by a substantial margin.
Figures







read the original abstract
Software developers frequently receive vulnerability reports that require them to reproduce the vulnerability in a reliable manner by generating a proof-of-concept (PoC) input that triggers it. Given the source code for a software project and a specific code location for a potential vulnerability, automatically generating a PoC for the given vulnerability has been a challenging research problem. Symbolic execution and fuzzing techniques require expert guidance and manual steps and face scalability challenges for PoC generation. Although recent advances in LLMs have increased the level of automation and scalability, the success rate of PoC generation with LLMs remains quite low. In this paper, we present a novel approach called Program Analysis Guided proof of concept generation agENT (PAGENT) that is scalable and significantly improves the success rate of automated PoC generation compared to prior results. PAGENT integrates lightweight and rule-based static analysis phases for providing static analysis guidance and sanitizer-based profiling and coverage information for providing dynamic analysis guidance with a PoC generation agent. Our experiments demonstrate that the resulting hybrid approach significantly outperforms the prior top-performing agentic approach by 132% for the PoC generation task.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PAGENT, a hybrid system that combines lightweight rule-based static analysis phases and sanitizer-based dynamic profiling/coverage information to guide an LLM-based agent in automatically generating proof-of-concept (PoC) inputs that trigger reported vulnerabilities, given source code and a target location. It claims this approach is more scalable than symbolic execution or fuzzing and significantly outperforms the prior top agentic baseline by 132% on the PoC generation task.
Significance. If the empirical results and the reliability of the guidance signals can be substantiated, the work would represent a meaningful step toward more automated and scalable vulnerability reproduction, potentially reducing the manual effort required for security triage. The core idea of using program analysis outputs as non-misleading signals to steer LLM agents is a natural and timely direction at the intersection of static/dynamic analysis and agentic LLMs.
major comments (2)
- [Abstract] Abstract: the claim that the hybrid approach 'significantly outperforms the prior top-performing agentic approach by 132%' supplies no information on the number of benchmarks, the exact baseline agent, the definition of success for PoC generation, or statistical significance. Without these details the central empirical claim cannot be evaluated.
- [Evaluation] Evaluation section (and associated tables/figures): no quantitative evidence is provided on the accuracy of the lightweight static-analysis warnings or the sanitizer-derived coverage signals (e.g., precision of warnings, coverage delta attributable to sanitizers, or an ablation that removes the guidance phases). If these signals contain false positives or noise that the LLM agent cannot reliably filter, the reported 132% gain cannot be attributed to the proposed guidance mechanism.
minor comments (1)
- [Abstract] The abstract and title use the stylized acronym 'PAGENT' and 'agENT'; ensure consistent capitalization and expansion on first use in the body.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the major comments point by point below and will revise the paper to improve clarity and substantiate the claims where needed.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the hybrid approach 'significantly outperforms the prior top-performing agentic approach by 132%' supplies no information on the number of benchmarks, the exact baseline agent, the definition of success for PoC generation, or statistical significance. Without these details the central empirical claim cannot be evaluated.
Authors: We agree that the abstract would benefit from additional context to make the central claim self-contained. In the revised manuscript, we will expand the abstract to summarize the number of benchmarks, identify the specific prior top-performing agentic baseline used for comparison, clarify the definition of success for PoC generation (an input that triggers the vulnerability as confirmed by the sanitizer), and note the statistical significance of the 132% relative improvement. These details are already elaborated in the Evaluation section and will be condensed into the abstract for better accessibility. revision: yes
-
Referee: [Evaluation] Evaluation section (and associated tables/figures): no quantitative evidence is provided on the accuracy of the lightweight static-analysis warnings or the sanitizer-derived coverage signals (e.g., precision of warnings, coverage delta attributable to sanitizers, or an ablation that removes the guidance phases). If these signals contain false positives or noise that the LLM agent cannot reliably filter, the reported 132% gain cannot be attributed to the proposed guidance mechanism.
Authors: We acknowledge that the current evaluation focuses on end-to-end PoC generation success and does not include dedicated metrics or ablations for the individual guidance signals. To address this, we will add an ablation study in the revised manuscript that removes the static analysis guidance and the dynamic sanitizer-based guidance phases separately, quantifying their individual contributions to the overall success rate. We will also report the precision of the lightweight static-analysis warnings on the benchmark set and the coverage improvements attributable to the sanitizer profiling. This will help demonstrate that the LLM agent effectively leverages these signals and that the performance gains can be attributed to the hybrid guidance approach. revision: yes
Circularity Check
No circularity: empirical outperformance claim is externally measured
full rationale
The paper presents PAGENT as an integration of lightweight static analysis, sanitizer-based dynamic guidance, and an LLM agent for PoC generation. Its central claim is an experimental result (132% outperformance over a prior agentic baseline). No equations, derivations, fitted parameters, or predictions appear in the provided text. The success rate is reported from head-to-head experiments rather than being forced by definition, self-citation chains, or renaming of known patterns. The approach description does not reduce to its own inputs by construction; the measured improvement is independent evidence.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Abramovich, M
T. Abramovich, M. Udeshi, M. Shao, K. Lieret, H. Xi, K. Milner, S. Jancheska, J. Yang, C. E. Jimenez, F. Khorrami, P. Krishnamurthy, B. Dolan-Gavitt, M. Shafique, K. Narasimhan, R. Karri, and O. Press. EnigMA: Enhanced interactive generative model agent for CTF challenges. Technical report
- [2]
-
[3]
Aslanyan, H
H. Aslanyan, H. Movsisyan, H. Hovhannisyan, Z. Gevorgyan, R. Mkoyan, A. Avetisyan, and S. Sargsyan. Combining static analysis with directed symbolic execution for scalable and accurate memory leak detection.IEEE Access, 12:80128–80137, 2024
2024
-
[4]
Baldoni, E
R. Baldoni, E. Coppa, D. C. D’elia, C. Demetrescu, and I. Finocchi. A survey of symbolic execution techniques.ACM Computing Surveys (CSUR), 51(3):1–39, 2018
2018
-
[5]
Barrett and S
L. Barrett and S. Moore. cclyzer++: Scalable and precise pointer analysis for llvm. https://galois.com/blog/2022/08/ cclyzer-scalable-and-precise-pointer-analysis-for-llvm/, 2022
2022
-
[6]
Böhme, C
M. Böhme, C. Cadar, and A. Roychoudhury. Fuzzing: Challenges and reflections.IEEE Software, 38(3):79–86, 2020
2020
-
[7]
Islem Bouzenia, Premkumar Devanbu, and Michael Pradel
I. Bouzenia, P. Devanbu, and M. Pradel. Repairagent: An autonomous, llm-based agent for program repair.arXiv preprint arXiv:2403.17134, 2024
-
[8]
Cadar, V
C. Cadar, V. Ganesh, P. M. Pawlowski, D. L. Dill, and D. R. Engler. Exe: Automatically generating inputs of death.ACM Transactions on Information and System Security (TISSEC), 12(2):1–38, 2008
2008
-
[9]
Cadar and K
C. Cadar and K. Sen. Symbolic execution for software testing: three decades later.Communications of the ACM, 56(2):82–90, 2013
2013
-
[10]
Cheng, K
B. Cheng, K. Wang, L. Shi, H. Wang, Y. Guo, D. Li, and X. Chen. Enhancing semantic understanding in pointer analysis using large language models. InProceedings of the 1st ACM SIGPLAN International Workshop on Language Models and Programming Languages, pages 112–117, New York, NY, USA, Oct. 2025. ACM
2025
-
[11]
Cve metrices
CVE. Cve metrices. https://www.cve.org/about/Metrics, 2026
2026
-
[12]
Feng and C
S. Feng and C. Chen. Prompting is all you need: Automated android bug replay with large language models. In Proceedings of the 46th IEEE/ACM International Conference on Software Engineering, pages 1–13, 2024
2024
-
[13]
Godefroid, M
P. Godefroid, M. Y. Levin, and D. Molnar. Sage: whitebox fuzzing for security testing.Communications of the ACM, 55(3):40–44, 2012
2012
-
[14]
OSS-Fuzz: Continuous fuzzing for open source software
Google. OSS-Fuzz: Continuous fuzzing for open source software. https://google.github.io/oss-fuzz/, 2016. Accessed: 2026-01
2016
-
[15]
K. Hassler, P. Görz, S. Lipp, T. Holz, and M. Böhme. A comparative study of fuzzers and static analysis tools for finding memory unsafety in c and c++.arXiv preprint arXiv:2505.22052, 2025
- [16]
-
[17]
Jordan, B
H. Jordan, B. Scholz, and P. Subotić. Soufflé: On synthesis of program analyzers. InComputer Aided Verification: 28th International Conference, CA V 2016, Toronto, ON, Canada, July 17-23, 2016, Proceedings, Part II 28, pages 422–430. Springer, 2016
2016
-
[18]
S. Kang, J. Yoon, N. Askarbekkyzy, and S. Yoo. Evaluating diverse large language models for automatic and general bug reproduction.IEEE Transactions on Software Engineering, 2024
2024
-
[19]
G. Li, M. Sridharan, and Z. Qian. Redefining indirect call analysis with kallgraph. In2025 IEEE Symposium on Security and Privacy (SP), pages 2957–2975. IEEE, 2025
2025
-
[20]
L. Li, T. F. Bissyandé, M. Papadakis, S. Rasthofer, A. Bartel, D. Octeau, J. Klein, and L. Traon. Static analysis of android apps: A systematic literature review.Information and Software Technology, 88:67–95, 2017
2017
-
[21]
X. Lin, Y. Ning, J. Zhang, Y. Dong, Y. Liu, Y. Wu, X. Qi, N. Sun, Y. Shang, K. Wang, et al. Llm-based agents suffer from hallucinations: A survey of taxonomy, methods, and directions.arXiv preprint arXiv:2509.18970, 2025. , Vol. 1, No. 1, Article . Publication date: April 2026. 20 Achintya Desai, Md Shafiuzzaman, Wenbo Guo, and Tevfik Bultan
-
[22]
A. Liu, B. Feng, B. Xue, B. Wang, B. Wu, C. Lu, C. Zhao, C. Deng, C. Zhang, C. Ruan, et al. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
A. Liu, A. Mei, B. Lin, B. Xue, B. Wang, B. Xu, B. Wu, B. Zhang, C. Lin, C. Dong, et al. Deepseek-v3. 2: Pushing the frontier of open large language models.arXiv preprint arXiv:2512.02556, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
J. Liu, C. S. Xia, Y. Wang, and L. Zhang. Is your code generated by chatgpt really correct? rigorous evaluation of large language models for code generation.Advances in Neural Information Processing Systems, 36:21558–21572, 2023
2023
-
[25]
K. Lu. Practical program modularization with type-based dependence analysis. In2023 IEEE Symposium on Security and Privacy (SP), pages 1256–1270. IEEE, 2023
2023
-
[26]
Lu and H
K. Lu and H. Hu. Where does it go? refining indirect-call targets with multi-layer type analysis. InProceedings of the 2019 ACM SIGSAC Conference on Computer and Communications Security, pages 1867–1881, 2019
2019
- [27]
- [28]
- [29]
-
[30]
OpenAI Codex CLI: Lightweight coding agent for the terminal
OpenAI. OpenAI Codex CLI: Lightweight coding agent for the terminal. https://github.com/openai/codex, 2025. Accessed: 2025-05-10
2025
-
[31]
C. S. Păsăreanu and N. Rungta. Symbolic pathfinder: symbolic execution of java bytecode. InProceedings of the 25th IEEE/ACM International Conference on Automated Software Engineering, pages 179–180, 2010
2010
-
[32]
Pomian, A
D. Pomian, A. Bellur, M. Dilhara, Z. Kurbatova, E. Bogomolov, T. Bryksin, and D. Dig. Next-generation refactoring: Combining llm insights and ide capabilities for extract method. In2024 IEEE International Conference on Software Maintenance and Evolution (ICSME), pages 275–287. IEEE, 2024
2024
-
[33]
G. Ryan, S. Jain, M. Shang, S. Wang, X. Ma, M. K. Ramanathan, and B. Ray. Code-aware prompting: A study of coverage-guided test generation in regression setting using llm.Proceedings of the ACM on Software Engineering, 1(FSE):951–971, 2024
2024
-
[34]
S. Saha, L. Sarker, M. Shafiuzzaman, C. Shou, A. Li, G. Sankaran, and T. Bultan. Rare path guided fuzzing. Inproceedings of the 32nd ACM sigsoft international symposium on software testing and analysis, pages 1295–1306, 2023
2023
-
[35]
K. Sen, D. Marinov, and G. Agha. Cute: A concolic unit testing engine for c.ACM SIGSOFT software engineering notes, 30(5):263–272, 2005
2005
-
[36]
Shafiuzzaman, A
M. Shafiuzzaman, A. Desai, L. Sarker, and T. Bultan. STASE: Static analysis guided symbolic execution for UEFI vulnerability signature generation. InProceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering, pages 1783–1794, 2024
2024
-
[37]
Shastry, M
B. Shastry, M. Leutner, T. Fiebig, K. Thimmaraju, F. Yamaguchi, K. Rieck, S. Schmid, J.-P. Seifert, and A. Feldmann. Static program analysis as a fuzzing aid. InInternational Symposium on Research in Attacks, Intrusions, and Defenses, pages 26–47. Springer, 2017
2017
- [38]
-
[39]
X. Wang, B. Li, Y. Song, F. F. Xu, X. Tang, M. Zhuge, J. Pan, Y. Song, B. Li, J. Singh, et al. Openhands: An open platform for ai software developers as generalist agents.arXiv preprint arXiv:2407.16741, 2024
work page internal anchor Pith review arXiv 2024
- [40]
-
[41]
Wüstholz and M
V. Wüstholz and M. Christakis. Targeted greybox fuzzing with static lookahead analysis. InProceedings of the ACM/IEEE 42nd International Conference on Software Engineering, pages 789–800, 2020
2020
-
[42]
C. S. Xia, M. Paltenghi, J. Le Tian, M. Pradel, and L. Zhang. Fuzz4all: Universal fuzzing with large language models. In Proceedings of the IEEE/ACM 46th International Conference on Software Engineering, pages 1–13, 2024
2024
-
[43]
J. Yang, C. E. Jimenez, A. Wettig, K. Lieret, S. Yao, K. Narasimhan, and O. Press. Swe-agent: Agent-computer interfaces enable automated software engineering.Advances in Neural Information Processing Systems, 37:50528–50652, 2024
2024
- [44]
-
[45]
Zheng, Z
Y. Zheng, Z. Song, Y. Sun, K. Cheng, H. Zhu, and L. Sun. An efficient greybox fuzzing scheme for linux-based iot programs through binary static analysis. In2019 IEEE 38th International Performance Computing and Communications Conference (IPCCC), pages 1–8. IEEE, 2019. , Vol. 1, No. 1, Article . Publication date: April 2026
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.