Recognition: no theorem link
VSAS-Bench: Real-Time Evaluation of Visual Streaming Assistant Models
Pith reviewed 2026-05-10 17:33 UTC · model grok-4.3
The pith
Conventional vision-language models adapted for streaming outperform specialized streaming models without any extra training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
VSAS-Bench supplies temporally dense annotations and standardized synchronous and asynchronous protocols that isolate proactiveness and consistency alongside accuracy. When this framework is applied to current video and streaming VLMs, conventional models adapted to streaming settings without additional training achieve higher performance than recent dedicated streaming VLMs.
What carries the argument
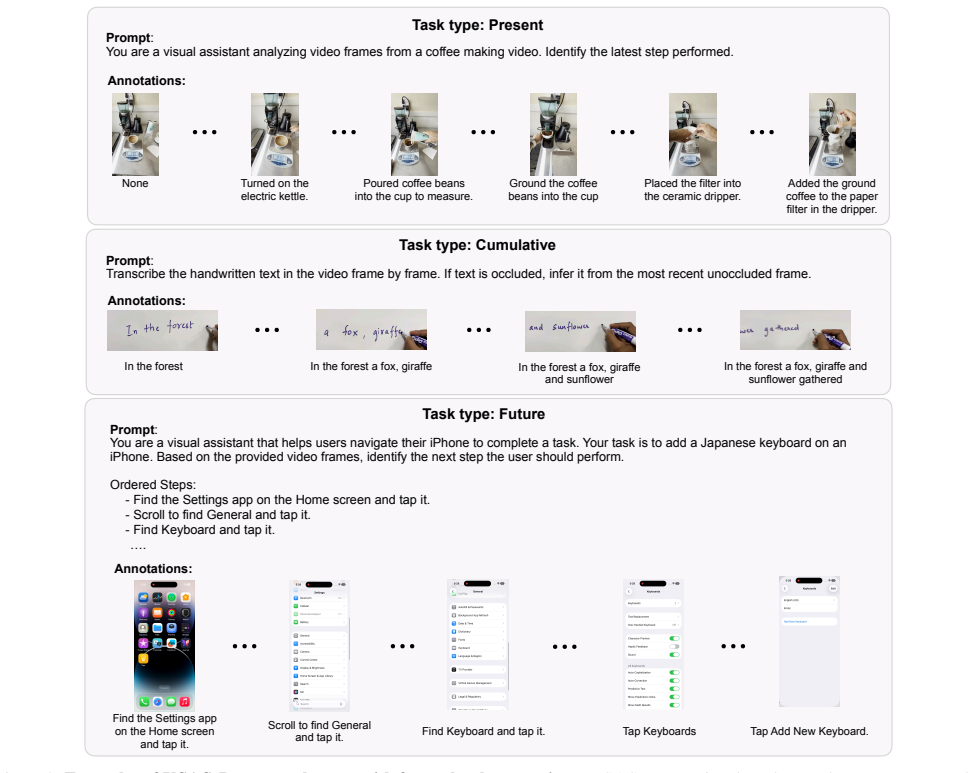
VSAS-Bench, a benchmark that supplies temporally dense annotations, synchronous and asynchronous evaluation protocols, and separate metrics for proactiveness and consistency to test real-time streaming vision-language models.
If this is right
- Performance depends on concrete design choices such as memory buffer length, memory access policy, and input resolution, with measurable accuracy-latency trade-offs.
- The benchmark supports standardized comparisons across both video VLMs and streaming VLMs using the new metrics.
- Adapted conventional models establish a stronger baseline for streaming performance than current purpose-built streaming models.
- Practical configuration guidelines emerge for balancing speed and quality in deployed streaming assistants.
Where Pith is reading between the lines
- The result suggests streaming behavior may arise naturally from general video-language training rather than needing separate architectures or data.
- The same protocols and metrics could be reused to evaluate streaming models in other modalities such as audio or sensor streams.
- Teams building live assistants may achieve faster progress by adapting existing models instead of training new streaming-specific ones from scratch.
Load-bearing premise
The new metrics for proactiveness and consistency, together with the temporally dense annotations and the chosen evaluation protocols, validly capture the capabilities required for real-time visual streaming assistants.
What would settle it
An independent test on a new set of live video streams with fresh human ratings of response timeliness and consistency in which the adapted conventional models no longer outperform the specialized streaming models.
Figures






read the original abstract
Streaming vision-language models (VLMs) continuously generate responses given an instruction prompt and an online stream of input frames. This is a core mechanism for real-time visual assistants. Existing VLM frameworks predominantly assess models in offline settings. In contrast, the performance of a streaming VLM depends on additional metrics beyond pure video understanding, including proactiveness, which reflects the timeliness of the model's responses, and consistency, which captures the robustness of its responses over time. To address this limitation, we propose VSAS-Bench, a new framework and benchmark for Visual Streaming Assistants. In contrast to prior benchmarks that primarily employ single-turn question answering on video inputs, VSAS-Bench features temporally dense annotations with over 18,000 annotations across diverse input domains and task types. We introduce standardized synchronous and asynchronous evaluation protocols, along with metrics that isolate and measure distinct capabilities of streaming VLMs. Using this framework, we conduct large-scale evaluations of recent video and streaming VLMs, analyzing the accuracy-latency trade-off under key design factors such as memory buffer length, memory access policy, and input resolution, yielding several practical insights. Finally, we show empirically that conventional VLMs can be adapted to streaming settings without additional training, and demonstrate that these adapted models outperform recent streaming VLMs. For example, Qwen3-VL-4B surpasses Dispider, the best streaming VLM on our benchmark, by 3% under the asynchronous protocol. The benchmark and code will be available at https://github.com/apple/ml-vsas-bench.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces VSAS-Bench, a benchmark for real-time evaluation of visual streaming assistant (VSA) models. Unlike prior offline video QA benchmarks, it provides temporally dense annotations (>18k across domains and tasks), defines proactiveness (timeliness of responses) and consistency (robustness over time) metrics, and specifies synchronous and asynchronous evaluation protocols. Large-scale experiments on video and streaming VLMs analyze accuracy-latency trade-offs under factors such as memory buffer length, access policy, and resolution; the central empirical result is that conventional VLMs can be adapted to streaming without retraining and outperform dedicated streaming models (e.g., Qwen3-VL-4B exceeds Dispider by 3% under the asynchronous protocol).
Significance. If the proactiveness/consistency metrics and protocols prove to be valid proxies for real-time assistant utility, the benchmark fills a clear gap in streaming VLM evaluation and supplies actionable design insights. The planned public release of the benchmark and code supports reproducibility and future work in the area.
major comments (2)
- [Metrics and Evaluation Protocols (abstract and §4)] The claim that adapted conventional VLMs outperform dedicated streaming models (e.g., the 3% asynchronous gap) is load-bearing and rests entirely on the newly introduced proactiveness and consistency metrics together with the synchronous/asynchronous protocols. The manuscript contains no human correlation study, no ablation demonstrating that these metrics predict downstream task success in live interaction, and no comparison against alternative proxies such as end-to-end user utility; without such evidence the observed differences could be artifacts of metric construction rather than genuine streaming capability.
- [Experimental Results (§5)] §5 (experimental results) reports concrete outperformance numbers and accuracy-latency curves but does not provide statistical significance tests, confidence intervals, or details on data splits and annotation quality control for the >18k temporally dense labels. These omissions prevent assessment of whether the reported 3% margin and design-factor insights are robust.
minor comments (2)
- [Abstract] The abstract states 'over 18,000 annotations' without an exact count or per-domain/task breakdown; the main text should supply the precise figure and a table summarizing annotation distribution.
- [Experimental Setup] Notation for the memory buffer length, access policy, and input resolution parameters is introduced in the experimental section but would benefit from a consolidated table of symbols and default values for reader clarity.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments on our paper. We provide point-by-point responses to the major comments below.
read point-by-point responses
-
Referee: [Metrics and Evaluation Protocols (abstract and §4)] The claim that adapted conventional VLMs outperform dedicated streaming models (e.g., the 3% asynchronous gap) is load-bearing and rests entirely on the newly introduced proactiveness and consistency metrics together with the synchronous/asynchronous protocols. The manuscript contains no human correlation study, no ablation demonstrating that these metrics predict downstream task success in live interaction, and no comparison against alternative proxies such as end-to-end user utility; without such evidence the observed differences could be artifacts of metric construction rather than genuine streaming capability.
Authors: We agree that empirical validation of the new metrics against human judgments or downstream utility would provide stronger support for the benchmark's relevance. The proactiveness and consistency metrics are motivated by the fundamental requirements of streaming assistants—responding in a timely manner and maintaining coherent responses over continuous input streams—which are not captured by standard offline accuracy metrics. The synchronous and asynchronous protocols are intended to model different real-world deployment scenarios. However, conducting a full human correlation study or user study is a substantial undertaking that lies beyond the scope of this initial benchmark paper. We will revise the manuscript to include a dedicated limitations section discussing the need for future validation of these metrics and to moderate the language around the outperformance claims, framing them as observations under the proposed evaluation framework rather than definitive proof of superiority. revision: partial
-
Referee: [Experimental Results (§5)] §5 (experimental results) reports concrete outperformance numbers and accuracy-latency curves but does not provide statistical significance tests, confidence intervals, or details on data splits and annotation quality control for the >18k temporally dense labels. These omissions prevent assessment of whether the reported 3% margin and design-factor insights are robust.
Authors: We acknowledge these omissions and will address them in the revised manuscript. We will include statistical significance tests (e.g., paired t-tests or bootstrap methods) and confidence intervals for the key performance differences, including the reported 3% margin under the asynchronous protocol. Additionally, we will expand the description of the benchmark construction in Section 3 to provide details on data splits, annotation guidelines, and quality control procedures used for the over 18,000 temporally dense annotations. revision: yes
- Conducting a human correlation study or ablation to validate the proactiveness and consistency metrics against real user utility, as this would require additional experiments and resources not feasible within the current revision timeline.
Circularity Check
No circularity: empirical benchmark with defined metrics and direct evaluations
full rationale
The paper introduces VSAS-Bench, new metrics (proactiveness, consistency), temporally dense annotations, and synchronous/asynchronous protocols, then reports direct empirical evaluations of existing VLMs on these. No mathematical derivations, fitted parameters repurposed as predictions, self-definitional loops, or load-bearing self-citations appear. The central claim (adapted conventional VLMs outperform dedicated streaming models) is an observation computed from the newly defined metrics applied to model outputs; it does not reduce to a fit or prior self-result by construction. External validation of the metrics (e.g., human correlation) is absent, but that is a validity concern, not circularity per the rules.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhao- hai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Jun- yang Lin. Qwen2.5-vl technical repor...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Activitynet: A large-scale video benchmark for human activity understanding
Fabian Caba Heilbron, Victor Escorcia, Bernard Ghanem, and Juan Carlos Niebles. Activitynet: A large-scale video benchmark for human activity understanding. InProceed- ings of the ieee conference on computer vision and pattern recognition, pages 961–970, 2015. 2
2015
-
[3]
Temporalbench: Bench- marking fine-grained temporal understanding for multimodal video models, 2024
Mu Cai, Reuben Tan, Jianrui Zhang, Bocheng Zou, Kai Zhang, Feng Yao, Fangrui Zhu, Jing Gu, Yiwu Zhong, Yuzhang Shang, Yao Dou, Jaden Park, Jianfeng Gao, Yong Jae Lee, and Jianwei Yang. Temporalbench: Bench- marking fine-grained temporal understanding for multimodal video models, 2024. 2
2024
-
[4]
Videollm-online: Online video large language model for streaming video
Joya Chen, Zhaoyang Lv, Shiwei Wu, Kevin Qinghong Lin, Chenan Song, Difei Gao, Jia-Wei Liu, Ziteng Gao, Dongxing Mao, and Mike Zheng Shou. Videollm-online: Online video large language model for streaming video. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18407–18418, 2024. 1, 2, 3, 7
2024
-
[5]
Livecc: Learning video llm with stream- ing speech transcription at scale
Joya Chen, Ziyun Zeng, Yiqi Lin, Wei Li, Zejun Ma, and Mike Zheng Shou. Livecc: Learning video llm with stream- ing speech transcription at scale. InCVPR, 2025. 3
2025
-
[6]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blis- tein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025. 1
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Video-MME: The First-Ever Comprehensive Evaluation Benchmark of Multi-modal LLMs in Video Analysis
Chaoyou Fu, Yuhan Dai, Yondong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan Wang, Chenyu Zhou, Yunhang Shen, Mengdan Zhang, et al. Video-mme: The first-ever compre- hensive evaluation benchmark of multi-modal llms in video analysis.arXiv preprint arXiv:2405.21075, 2024. 2
work page internal anchor Pith review arXiv 2024
-
[8]
Ego4d: Around the world in 3,000 hours of egocentric video
Kristen Grauman, Andrew Westbury, Eugene Byrne, Zachary Chavis, Antonino Furnari, Rohit Girdhar, Jackson Hamburger, Hao Jiang, Miao Liu, Xingyu Liu, et al. Ego4d: Around the world in 3,000 hours of egocentric video. In Proceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 18995–19012, 2022. 1, 2
2022
-
[9]
Cogvlm2: Visual language models for image and video un- derstanding
Wenyi Hong, Weihan Wang, Ming Ding, Wenmeng Yu, Qingsong Lv, Yan Wang, Yean Cheng, Shiyu Huang, Jun- hui Ji, Zhao Xue, et al. Cogvlm2: Visual language mod- els for image and video understanding.arXiv preprint arXiv:2408.16500, 2024. 2
-
[10]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perel- man, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Weli- hinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card. arXiv preprint arXiv:2410.21276, 2024. 1
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Fast in- ference from transformers via speculative decoding
Yaniv Leviathan, Matan Kalman, and Yossi Matias. Fast in- ference from transformers via speculative decoding. InIn- ternational Conference on Machine Learning, pages 19274– 19286. PMLR, 2023. 8
2023
-
[12]
Llava-onevision: Easy visual task transfer,
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Yanwei Li, Ziwei Liu, and Chunyuan Li. Llava-onevision: Easy visual task transfer,
-
[13]
Junming Lin, Zheng Fang, Chi Chen, Zihao Wan, Fuwen Luo, Peng Li, Yang Liu, and Maosong Sun. Streamingbench: Assessing the gap for mllms to achieve streaming video un- derstanding.arXiv preprint arXiv:2411.03628, 2024. 1, 2
-
[14]
G-eval: NLG evaluation using gpt- 4 with better human alignment
Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. G-eval: NLG evaluation using gpt- 4 with better human alignment. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Pro- cessing, pages 2511–2522, Singapore, 2023. Association for Computational Linguistics. 6
2023
-
[15]
Ye Liu, Zongyang Ma, Zhongang Qi, Yang Wu, Chang Wen Chen, and Ying Shan. E.t. bench: Towards open-ended event-level video-language understanding. InNeural Infor- mation Processing Systems (NeurIPS), 2024. 1, 2
2024
-
[16]
Nvila: Efficient frontier visual language models, 2024
Zhijian Liu, Ligeng Zhu, Baifeng Shi, Zhuoyang Zhang, Yuming Lou, Shang Yang, Haocheng Xi, Shiyi Cao, Yux- ian Gu, Dacheng Li, Xiuyu Li, Yunhao Fang, Yukang Chen, Cheng-Yu Hsieh, De-An Huang, An-Chieh Cheng, Vish- wesh Nath, Jinyi Hu, Sifei Liu, Ranjay Krishna, Daguang Xu, Xiaolong Wang, Pavlo Molchanov, Jan Kautz, Hongxu Yin, Song Han, and Yao Lu. Nvila:...
2024
-
[17]
Egoschema: A diagnostic benchmark for very long- form video language understanding, 2023
Karttikeya Mangalam, Raiymbek Akshulakov, and Jitendra Malik. Egoschema: A diagnostic benchmark for very long- form video language understanding, 2023. 2
2023
-
[18]
SmolVLM: Redefining small and efficient multimodal models
Andr ´es Marafioti, Orr Zohar, Miquel Farr ´e, Merve Noyan, Elie Bakouch, Pedro Cuenca, Cyril Zakka, Loubna Ben Allal, Anton Lozhkov, Nouamane Tazi, Vaibhav Srivastav, Joshua Lochner, Hugo Larcher, Mathieu Morlon, Lewis Tun- stall, Leandro von Werra, and Thomas Wolf. Smolvlm: Redefining small and efficient multimodal models.arXiv preprint arXiv:2504.05299...
work page internal anchor Pith review arXiv 2025
-
[19]
Junbo Niu, Yifei Li, Ziyang Miao, Chunjiang Ge, Yuanhang Zhou, Qihao He, Xiaoyi Dong, Haodong Duan, Shuangrui Ding, Rui Qian, et al. Ovo-bench: How far is your video- llms from real-world online video understanding? InPro- ceedings of the Computer Vision and Pattern Recognition Conference, pages 18902–18913, 2025. 1, 2
2025
-
[20]
Gpt-5 system card
OpenAI. Gpt-5 system card. Technical Report TR-GPT5- 2025, OpenAI, 2025. Technical report. Available athttps: //cdn.openai.com/gpt- 5- system- card.pdf (accessed 2025-11-13). 3, 7, 2
2025
-
[21]
Perception test: A diagnostic benchmark for multimodal video models
Viorica P ˘atr˘aucean, Lucas Smaira, Ankush Gupta, Adri`a Re- casens Continente, Larisa Markeeva, Dylan Banarse, Skanda 9 Koppula, Joseph Heyward, Mateusz Malinowski, Yi Yang, Carl Doersch, Tatiana Matejovicova, Yury Sulsky, Antoine Miech, Alex Frechette, Hanna Klimczak, Raphael Koster, Junlin Zhang, Stephanie Winkler, Yusuf Aytar, Simon Osin- dero, Dima ...
2023
-
[22]
Dispider: Enabling video llms with active real-time interaction via dis- entangled perception, decision, and reaction
Rui Qian, Shuangrui Ding, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Yuhang Cao, Dahua Lin, and Jiaqi Wang. Dispider: Enabling video llms with active real-time interaction via dis- entangled perception, decision, and reaction. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 24045–24055, 2025. 3, 7
2025
-
[23]
Coin: A large-scale dataset for comprehensive instructional video analysis
Yansong Tang, Dajun Ding, Yongming Rao, Yu Zheng, Danyang Zhang, Lili Zhao, Jiwen Lu, and Jie Zhou. Coin: A large-scale dataset for comprehensive instructional video analysis. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1207– 1216, 2019. 1, 2
2019
-
[24]
Qwen3 technical report, 2025
Qwen Team. Qwen3 technical report, 2025. 1, 2, 7
2025
-
[25]
Fastvlm: Efficient vision encoding for vision language models
Pavan Kumar Anasosalu Vasu, Fartash Faghri, Chun-Liang Li, Cem Koc, Nate True, Albert Antony, Gokul San- thanam, James Gabriel, Peter Grasch, Oncel Tuzel, and Hadi Pouransari. Fastvlm: Efficient vision encoding for vision language models. InProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR),
-
[26]
arXiv preprint arXiv:2505.05467 , year=
Haibo Wang, Bo Feng, Zhengfeng Lai, Mingze Xu, Shiyu Li, Weifeng Ge, Afshin Dehghan, Meng Cao, and Ping Huang. Streambridge: Turning your offline video large language model into a proactive streaming assistant.arXiv preprint arXiv:2505.05467, 2025. 3, 7
-
[27]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Yang Fan, Kai Dang, Mengfei Du, Xuancheng Ren, Rui Men, Dayiheng Liu, Chang Zhou, Jingren Zhou, and Jun- yang Lin. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024. 2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
arXiv preprint arXiv:2411.10442 , year=
Weiyun Wang, Zhe Chen, Wenhai Wang, Yue Cao, Yangzhou Liu, Zhangwei Gao, Jinguo Zhu, Xizhou Zhu, Lewei Lu, Yu Qiao, and Jifeng Dai. Enhancing the reason- ing ability of multimodal large language models via mixed preference optimization.arXiv preprint arXiv:2411.10442,
-
[29]
Star: A benchmark for situated reasoning in real-world videos
Bo Wu, Shoubin Yu, Zhenfang Chen, Joshua B Tenenbaum, and Chuang Gan. Star: A benchmark for situated reasoning in real-world videos. InThirty-fifth Conference on Neural Information Processing Systems (NeurIPS), 2021. 3
2021
-
[30]
Longvideobench: A benchmark for long-context interleaved video-language understanding, 2024
Haoning Wu, Dongxu Li, Bei Chen, and Junnan Li. Longvideobench: A benchmark for long-context interleaved video-language understanding, 2024. 2
2024
-
[31]
Next-qa: Next phase of question-answering to explaining temporal actions
Junbin Xiao, Xindi Shang, Angela Yao, and Tat-Seng Chua. Next-qa: Next phase of question-answering to explaining temporal actions. InProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR), pages 9777–9786, 2021. 2
2021
-
[32]
Msr-vtt: A large video description dataset for bridging video and language
Jun Xu, Tao Mei, Ting Yao, and Yong Rui. Msr-vtt: A large video description dataset for bridging video and language. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 5288–5296, 2016. 2
2016
-
[33]
arXiv preprint arXiv:2510.09608 , year=
Ruyi Xu, Guangxuan Xiao, Yukang Chen, Liuning He, Kelly Peng, Yao Lu, and Song Han. Streamingvlm: Real-time understanding for infinite video streams.arXiv preprint arXiv:2510.09608, 2025. 1
-
[34]
MiniCPM-V: A GPT-4V Level MLLM on Your Phone
Yuan Yao, Tianyu Yu, Ao Zhang, Chongyi Wang, Junbo Cui, Hongji Zhu, Tianchi Cai, Haoyu Li, Weilin Zhao, Zhihui He, et al. Minicpm-v: A gpt-4v level mllm on your phone.arXiv preprint arXiv:2408.01800, 2024. 2
work page internal anchor Pith review arXiv 2024
-
[35]
Haoji Zhang, Yiqin Wang, Yansong Tang, Yong Liu, Jiashi Feng, Jifeng Dai, and Xiaojie Jin. Flash-vstream: Memory- based real-time understanding for long video streams.arXiv preprint arXiv:2406.08085, 2024. 1, 2, 3, 7
-
[36]
Towards automatic learning of procedures from web instructional videos
Luowei Zhou, Chenliang Xu, and Jason Corso. Towards automatic learning of procedures from web instructional videos. InProceedings of the AAAI Conference on Artificial Intelligence, 2018. 3 10 VSAS-BENCH: Real-Time Evaluation of Visual Streaming Assistant Models Supplementary Material A. Dataset Preprocessing and Annotations As detailed in Sec. 3.1, our be...
2018
-
[37]
A model predicted response
-
[38]
No places visited yet
A ground truth answer Your task is to compare the model’s response with the ground truth and decide if they match meaningfully. ########### Instruction on how to evaluate ########### ### Your Output Format: Return only a JSON dictionary with the following keys: * ’pred’: ”yes” if the model response meaningfully matches the ground truth, ”no” otherwise. * ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.