Recognition: no theorem link
Multi-Agent Orchestration for High-Throughput Materials Screening on a Leadership-Class System
Pith reviewed 2026-05-10 18:26 UTC · model grok-4.3
The pith
A hierarchical multi-agent framework lets LLMs orchestrate high-throughput materials screening scalably on exascale supercomputers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
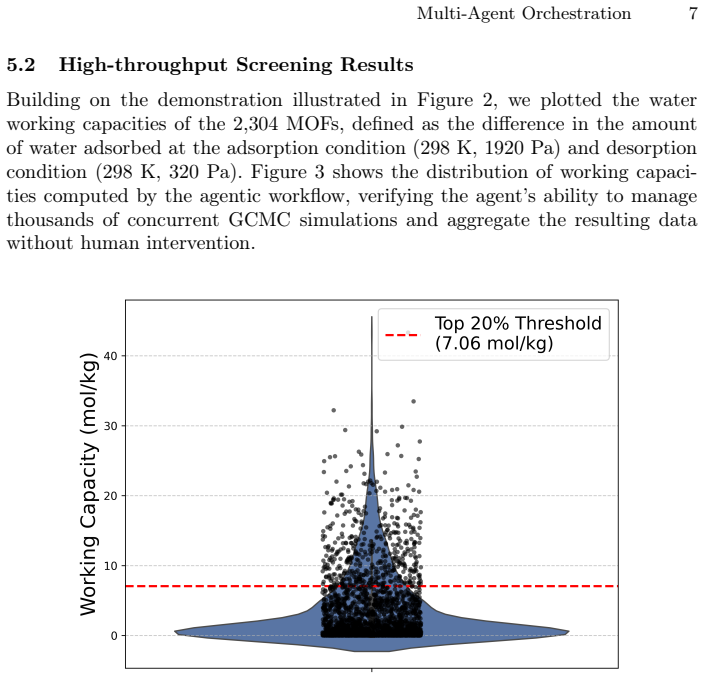
The authors present a scalable hierarchical multi-agent framework consisting of a central planning agent that dynamically partitions workloads and assigns subtasks to parallel executor agents. These agents interface with a shared Model Context Protocol server that uses the Parsl workflow engine to execute the tasks. Applied to a high-throughput screening of the CoRE MOF database for atmospheric water harvesting using the gpt-oss-120b model on the Aurora supercomputer, the framework achieves efficient execution characterized by low orchestration overhead and high task completion rates.
What carries the argument
The planner-executor architecture in which a central planning agent dynamically partitions workloads and assigns subtasks to a swarm of parallel executor agents connected via a shared Model Context Protocol server to the Parsl workflow engine.
Load-bearing premise
LLM agents can reliably plan, partition, and execute complex high-throughput simulation tasks without introducing errors or failures that require human intervention.
What would settle it
A demonstration where the multi-agent framework exhibits high rates of planning errors or task failures during the MOF screening on Aurora, leading to incomplete results or significant delays, would falsify the claim of efficient and scalable execution.
Figures


read the original abstract
The integration of Artificial Intelligence (AI) with High-Performance Computing (HPC) is transforming scientific workflows from human-directed pipelines into adaptive systems capable of autonomous decision-making. Large language models (LLMs) play a critical role in autonomous workflows; however, deploying LLM-based agents at scale remains a significant challenge. Single-agent architectures and sequential tool calls often become serialization bottlenecks when executing large-scale simulation campaigns, failing to utilize the massive parallelism of exascale resources. To address this, we present a scalable, hierarchical multi-agent framework for orchestrating high-throughput screening campaigns. Our planner-executor architecture employs a central planning agent to dynamically partition workloads and assign subtasks to a swarm of parallel executor agents. All executor agents interface with a shared Model Context Protocol (MCP) server that orchestrates tasks via the Parsl workflow engine. To demonstrate this framework, we employed the open-weight gpt-oss-120b model to orchestrate a high-throughput screening of the Computation-Ready Experimental (CoRE) Metal-Organic Framework (MOF) database for atmospheric water harvesting. The results demonstrate that the proposed agentic framework enables efficient and scalable execution on the Aurora supercomputer, with low orchestration overhead and high task completion rates. This work establishes a flexible paradigm for LLM-driven scientific automation on HPC systems, with broad applicability to materials discovery and beyond.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a hierarchical multi-agent framework for LLM-driven orchestration of high-throughput materials screening on the Aurora supercomputer. A central planning agent dynamically partitions workloads and assigns subtasks to parallel executor agents, all interfacing via a shared Model Context Protocol (MCP) server with the Parsl workflow engine. The framework is demonstrated using the open-weight gpt-oss-120b model to screen the CoRE MOF database for atmospheric water harvesting applications. The authors claim that this architecture enables efficient, scalable execution with low orchestration overhead and high task completion rates, establishing a paradigm for autonomous AI-HPC scientific workflows.
Significance. If substantiated with concrete performance data, this work would represent a meaningful engineering contribution to scalable LLM-agent orchestration on leadership-class HPC systems. It directly targets serialization bottlenecks in single-agent LLM setups for parallel simulation campaigns and integrates established tools (Parsl) with a novel MCP server, potentially broadening applicability to other materials discovery and high-throughput screening tasks. The use of an open-weight model and focus on exascale resources adds practical value for reproducible autonomous workflows.
major comments (2)
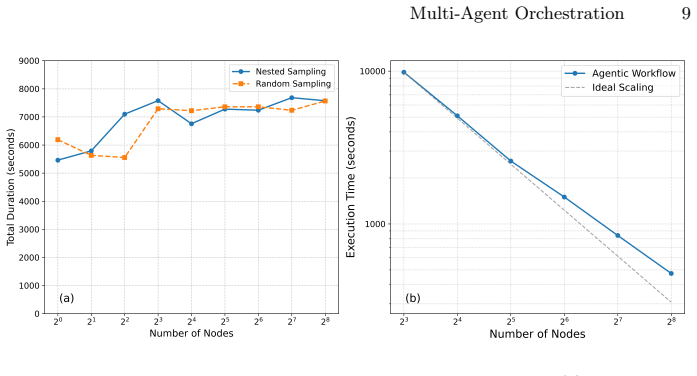
- Abstract and results description: The central claims of 'low orchestration overhead' and 'high task completion rates' are asserted without any quantitative metrics (e.g., overhead fractions as percentages of total runtime, completion percentages, scaling curves with node count, or failure rates). No baseline comparisons to single-agent or non-agentic Parsl workflows, error analysis, or data on agent-induced failures are provided, leaving the performance assertions unsupported by visible evidence in the manuscript.
- Demonstration section (MOF screening experiment): The description of the CoRE MOF screening campaign lacks details on how the planner-executor agents handled task partitioning, error recovery, or any observed failures requiring human intervention. Without these, it is impossible to evaluate the reliability assumption that LLM agents can autonomously manage complex high-throughput simulation tasks at scale.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive comments. We address each major comment below and will revise the manuscript to incorporate the requested quantitative evidence and additional experimental details.
read point-by-point responses
-
Referee: Abstract and results description: The central claims of 'low orchestration overhead' and 'high task completion rates' are asserted without any quantitative metrics (e.g., overhead fractions as percentages of total runtime, completion percentages, scaling curves with node count, or failure rates). No baseline comparisons to single-agent or non-agentic Parsl workflows, error analysis, or data on agent-induced failures are provided, leaving the performance assertions unsupported by visible evidence in the manuscript.
Authors: We agree that the performance claims require explicit quantitative support to be fully substantiated. In the revised manuscript we will add concrete metrics including orchestration overhead as a percentage of total runtime, task completion rates, scaling curves with node count on Aurora, failure rates, and direct comparisons against single-agent LLM baselines as well as non-agentic Parsl workflows. A dedicated error analysis subsection will also be included to report any agent-induced failures. revision: yes
-
Referee: Demonstration section (MOF screening experiment): The description of the CoRE MOF screening campaign lacks details on how the planner-executor agents handled task partitioning, error recovery, or any observed failures requiring human intervention. Without these, it is impossible to evaluate the reliability assumption that LLM agents can autonomously manage complex high-throughput simulation tasks at scale.
Authors: We appreciate the request for greater transparency. The revised demonstration section will be expanded to describe the planner agent's specific task-partitioning logic with examples from the CoRE MOF campaign, the error-recovery mechanisms used by executor agents, and any observed failures (including those that required human intervention) together with overall reliability statistics. revision: yes
Circularity Check
No significant circularity in the engineering demonstration
full rationale
The paper is an engineering demonstration of a hierarchical multi-agent orchestration framework for HPC workflows on Aurora, using external components (Parsl, MCP server) and the gpt-oss-120b model to run a concrete MOF screening campaign. Performance claims rest on direct runtime measurements of overhead fractions and task completion rates rather than any derivation, fitted parameter, or self-referential definition. No equations, predictions, or load-bearing self-citations appear in the manuscript; the central result is an observable execution outcome on an independent supercomputer platform.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs such as gpt-oss-120b can dynamically partition and assign complex simulation subtasks without frequent errors
invented entities (1)
-
Model Context Protocol (MCP) server
no independent evidence
Reference graph
Works this paper leans on
-
[1]
A comprehensive overview of large language models.ACM Trans
Humza Naveed et al. “A Comprehensive Overview of Large Language Models”. In:ACM Trans. Intell. Syst. Technol.16.5 (Aug. 2025).issn: 2157-6904.doi: 10.1145/3744746
-
[2]
Autonomous chemical research with large language mod- els
Daniil A Boiko et al. “Autonomous chemical research with large language mod- els”. In:Nature624.7992 (2023), pp. 570–578.doi:10.1038/s41586-023-06792- 0
-
[3]
LangChain, Inc.LangGraph: A Framework for Building Stateful, Multi-Actor Applications with LLMs.https://github.com/langchain-ai/langgraph. 2025
2025
-
[4]
Parsl: Pervasive parallel programming in python
Yadu Babuji et al. “Parsl: Pervasive parallel programming in python”. In:28th International Symposium on High-Performance Parallel and Distributed Com- puting (HPDC). 2019, pp. 25–36
2019
-
[5]
The Chemistry and Applications of Metal-Organic Frameworks
Hiroyasu Furukawa et al. “The Chemistry and Applications of Metal-Organic Frameworks”. In:Science341.6149 (Aug. 30, 2013), p. 1230444.doi:10.1126/ science.1230444
2013
-
[6]
Metal–Organic Frameworks for Water Har- vesting from Air, Anywhere, Anytime
Wentao Xu and Omar M. Yaghi. “Metal–Organic Frameworks for Water Har- vesting from Air, Anywhere, Anytime”. In:ACS Central Science6.8 (Aug. 26, 2020), pp. 1348–1354.issn: 2374-7943.doi:10.1021/acscentsci.0c00678
-
[7]
Peyman Z. Moghadam et al. “Development of a Cambridge Structural Database Subset: A Collection of Metal–Organic Frameworks for Past, Present, and Fu- ture”. In:Chemistry of Materials29.7 (Apr. 11, 2017), pp. 2618–2625.issn: 0897-4756.doi:10.1021/acs.chemmater.7b00441
-
[8]
Guobin Zhao et al. “CoRE MOF DB: A curated experimental metal-organic framework database with machine-learned properties for integrated material- process screening”. In:Matter8.6 (2025), p. 102140.issn: 2590-2385.doi:https: //doi.org/10.1016/j.matt.2025.102140
-
[9]
Early Application Experiences on Aurora at ALCF: Moving From Petascale to Exascale Systems
Colleen Bertoni et al. “Early Application Experiences on Aurora at ALCF: Moving From Petascale to Exascale Systems”. In:Proceedings of the Cray User Group. CUG ’24. Association for Computing Machinery, 2025, pp. 12–23.isbn: 9798400713286.doi:10.1145/3725789.3725791
-
[10]
Shunyu Yao et al.ReAct: Synergizing Reasoning and Acting in Language Models
-
[11]
arXiv:2210.03629 [cs.CL].url:https://arxiv.org/abs/2210.03629
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Augmenting large language models with chemistry tools
Andres M Bran et al. “Augmenting large language models with chemistry tools”. In:Nature Machine Intelligence6 (2024), pp. 525–535
2024
-
[13]
ChemGraphasanagentic framework for computational chemistry workflows
ThangD. Pham,AdityaTanikanti,and MuratKeçeli. “ChemGraphasanagentic framework for computational chemistry workflows”. In:Communications Chem- istry9.1 (Jan. 8, 2026), p. 33.issn: 2399-3669.doi:10 . 1038 / s42004 - 025 - 01776-9
2026
-
[14]
El Agente: An autonomous agent for quantum chemistry
Yunheng Zou et al. “El Agente: An autonomous agent for quantum chemistry”. In:Matter8.7 (July 2, 2025).issn: 2590-2393.doi:10 . 1016 / j . matt . 2025 . 102263
2025
-
[15]
McNaughton, Gautham Krishna Sankar Ramalaxmi, Agustin Kruel, Carter R
Andrew D. McNaughton et al. “CACTUS: Chemistry Agent Connecting Tool Usage to Science”. In:ACS Omega9.46 (Nov. 19, 2024), pp. 46563–46573.doi: 10.1021/acsomega.4c08408. 12 T. D. Pham et al
-
[16]
Alok Kamatar et al.Empowering Scientific Workflows with Federated Agents
- [17]
-
[18]
FireWorks: a dynamic workflow system designed for high- throughput applications
Anubhav Jain et al. “FireWorks: a dynamic workflow system designed for high- throughput applications”. In:Concurrency and Computation: Practice and Ex- perience27.17 (2015), pp. 5037–5059
2015
-
[19]
Balsam: Near Real-Time Experimental Data Analysis on Supercomputers
Michael Salim et al. “Balsam: Near Real-Time Experimental Data Analysis on Supercomputers”. In:2019 IEEE/ACM 1st Annual Workshop on Large-scale Experiment-in-the-Loop Computing (XLOOP). 2019, pp. 26–31.doi:10.1109/ XLOOP49562.2019.00010
-
[20]
Gautham Dharuman et al. “MProt-DPO: Breaking the ExaFLOPS Barrier for Multimodal Protein Design Workflows with Direct Preference Optimization”. In:Proceedings of the International Conference for High Performance Comput- ing, Networking, Storage, and Analysis. SC ’24. Atlanta, GA, USA, 2024.isbn: 9798350352917.doi:10.1109/SC41406.2024.00013
-
[21]
Colmena: Scalable steering of ensemble simulations with artificial intelligence
Logan Ward et al. “Colmena: Scalable steering of ensemble simulations with artificial intelligence”. In:Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis (SC21). 2021, pp. 1– 12
2021
-
[22]
FIRST:FederatedInferenceResourceSchedulingToolkit for Scientific AI Model Access
Heng Ma et al. “LangChain-Parsl: Connect Large Language Model Agents to High Performance Computing Resource”. In:Proceedings of the SC ’25 Work- shops of the International Conference for High Performance Computing, Net- working, Storage and Analysis.SCWorkshops’25.2025,pp.78–85.isbn:9798400718717. doi:10.1145/3731599.3767349
-
[23]
Xinyi Hou et al.Model Context Protocol (MCP): Landscape, Security Threats, and Future Research Directions. 2025. arXiv:2503.23278 [cs.CR].url:https: //arxiv.org/abs/2503.23278
work page internal anchor Pith review arXiv 2025
-
[24]
Zhao Li et al. “Efficient Implementation of Monte Carlo Algorithms on Graphical Processing Units for Simulation of Adsorption in Porous Materials”. In:Journal of Chemical Theory and Computation20.23 (Dec. 10, 2024), pp. 10649–10666. issn: 1549-9618.doi:10.1021/acs.jctc.4c01058
-
[25]
UFF, a full periodic table force field for molecular mechanics and molecular dynamics simulations
A. K. Rappe et al. “UFF, a full periodic table force field for molecular mechanics and molecular dynamics simulations”. In:Journal of the American Chemical Society114.25 (1992), pp. 10024–10035.doi:10.1021/ja00051a040
-
[26]
Comparison of simple potential functions for sim- ulating liquid water
William L. Jorgensen et al. “Comparison of simple potential functions for sim- ulating liquid water”. In:The Journal of Chemical Physics79.2 (July 1983), pp. 926–935.issn: 0021-9606.doi:10.1063/1.445869
-
[27]
Vapor–liquid equilibria of mixtures con- taining alkanes, carbon dioxide, and nitrogen
Jeffrey J. Potoff and J. Ilja Siepmann. “Vapor–liquid equilibria of mixtures con- taining alkanes, carbon dioxide, and nitrogen”. In:AIChE Journal47.7 (2001), pp. 1676–1682.doi:https://doi.org/10.1002/aic.690470719
-
[28]
Predicting Partial Atomic Charges in Metal–Organic Frameworks: An Extension to Ionic MOFs
Thang D. Pham et al. “Predicting Partial Atomic Charges in Metal–Organic Frameworks: An Extension to Ionic MOFs”. In:The Journal of Physical Chem- istry C128.40 (Oct. 10, 2024), pp. 17165–17174.doi:10 . 1021 / acs . jpcc . 4c04879
2024
-
[29]
Accessed: 2025-11-01
Cambridge Crystallographic Data Centre (CCDC).Computation Ready Metal– Organic Frameworks (CoRE MOF) Database. Accessed: 2025-11-01. 2025
2025
-
[30]
FIRST:FederatedInferenceResourceSchedulingToolkit for Scientific AI Model Access
AdityaTanikantietal.“FIRST:FederatedInferenceResourceSchedulingToolkit for Scientific AI Model Access”. In:Proceedings of the SC ’25 Workshops of the International Conference for High Performance Computing, Networking, Storage and Analysis. SC Workshops ’25. 2025, pp. 52–60.isbn: 9798400718717.doi: 10.1145/3731599.3767346. Multi-Agent Orchestration 13
-
[31]
The Berkeley Function Calling Leaderboard (BFCL): From Tool Use to Agentic Evaluation of Large Language Models
Shishir G Patil et al. “The Berkeley Function Calling Leaderboard (BFCL): From Tool Use to Agentic Evaluation of Large Language Models”. In:Forty- second International Conference on Machine Learning. 2025.url:https : / / openreview.net/forum?id=2GmDdhBdDk
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.