Recognition: no theorem link
Towards Knowledgeable Deep Research: Framework and Benchmark
Pith reviewed 2026-05-10 18:12 UTC · model grok-4.3
The pith
A new multi-agent framework lets deep research agents combine tables, figures, and text to generate more accurate reports than prior methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors establish that the Hybrid Knowledge Analysis framework, built around a Structured Knowledge Analyzer that employs both coding models and vision-language models, enables deep research agents to integrate structured and unstructured knowledge into coherent multimodal reports, resulting in higher scores than prior agents on the three categories of metrics defined for KDR-Bench.
What carries the argument
The Structured Knowledge Analyzer inside the Hybrid Knowledge Analysis multi-agent architecture, which converts tables and figures into insights using coding and vision-language models.
If this is right
- Deep research agents can now perform quantitative computations directly from tables rather than relying solely on textual summaries.
- Multimodal reports that incorporate figures and tables achieve higher scores on vision-enhanced evaluation metrics.
- Systematic benchmarks like KDR-Bench allow comparison of agents across general-purpose, knowledge-centric, and vision-enhanced dimensions.
- Future deep-research systems can treat structured knowledge as a core input rather than an optional add-on.
Where Pith is reading between the lines
- The separation of structured and unstructured analysis in the framework could extend to other agent tasks that require both numerical reasoning and narrative synthesis.
- If the benchmark's tables were replaced with live database connections, the same architecture might support ongoing monitoring or forecasting applications.
- Adoption in specialized fields such as economics or biology could reveal whether the coding-plus-vision approach scales to domain-specific data formats.
Load-bearing premise
That the 41 expert-level questions and 1,252 tables in KDR-Bench across nine domains provide a representative test of an agent's ability to perform deep, structure-aware knowledge analysis.
What would settle it
A follow-up evaluation on a fresh collection of expert questions that include tables outside the original nine domains, where HKA fails to maintain its reported advantage on knowledge-centric or vision-enhanced metrics.
Figures



read the original abstract
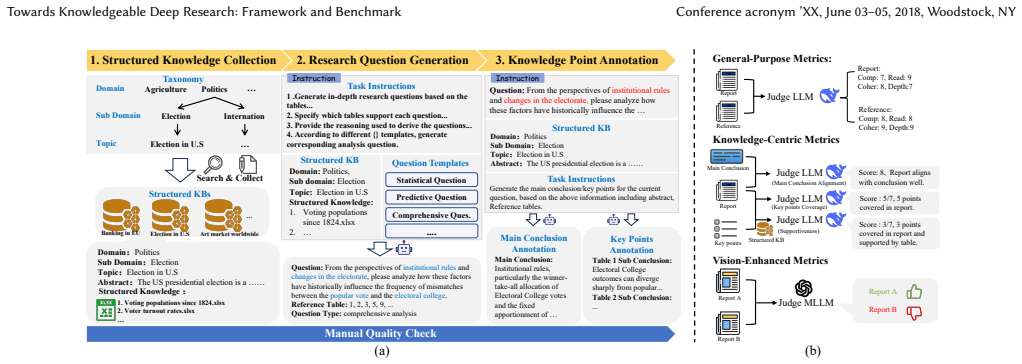
Deep Research (DR) requires LLM agents to autonomously perform multi-step information seeking, processing, and reasoning to generate comprehensive reports. In contrast to existing studies that mainly focus on unstructured web content, a more challenging DR task should additionally utilize structured knowledge to provide a solid data foundation, facilitate quantitative computation, and lead to in-depth analyses. In this paper, we refer to this novel task as Knowledgeable Deep Research (KDR), which requires DR agents to generate reports with both structured and unstructured knowledge. Furthermore, we propose the Hybrid Knowledge Analysis framework (HKA), a multi-agent architecture that reasons over both kinds of knowledge and integrates the texts, figures, and tables into coherent multimodal reports. The key design is the Structured Knowledge Analyzer, which utilizes both coding and vision-language models to produce figures, tables, and corresponding insights. To support systematic evaluation, we construct KDR-Bench, which covers 9 domains, includes 41 expert-level questions, and incorporates a large number of structured knowledge resources (e.g., 1,252 tables). We further annotate the main conclusions and key points for each question and propose three categories of evaluation metrics including general-purpose, knowledge-centric, and vision-enhanced ones. Experimental results demonstrate that HKA consistently outperforms most existing DR agents on general-purpose and knowledge-centric metrics, and even surpasses the Gemini DR agent on vision-enhanced metrics, highlighting its effectiveness in deep, structure-aware knowledge analysis. Finally, we hope this work can serve as a new foundation for structured knowledge analysis in DR agents and facilitate future multimodal DR studies.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Knowledgeable Deep Research (KDR) as a task requiring LLM agents to generate reports that integrate both structured (tables, figures) and unstructured knowledge. It proposes the Hybrid Knowledge Analysis (HKA) multi-agent framework, centered on a Structured Knowledge Analyzer that combines coding and vision-language models to produce and interpret multimodal outputs. To evaluate this, the authors construct KDR-Bench covering 9 domains with 41 expert-level questions and 1,252 tables, annotate key conclusions, and define three metric categories (general-purpose, knowledge-centric, vision-enhanced). Experimental results claim that HKA consistently outperforms most existing DR agents on the first two metric types and surpasses the Gemini DR agent on vision-enhanced metrics.
Significance. If the performance claims hold under rigorous evaluation, the work provides a concrete benchmark and framework for incorporating structured knowledge into deep research agents, filling a gap between unstructured web-based DR and quantitative, multimodal analysis. The explicit construction of KDR-Bench with annotated conclusions and multimodal resources could serve as a reusable testbed for future studies, particularly if accompanied by reproducible code or detailed per-question results.
major comments (3)
- [Abstract / Experimental results] Abstract and experimental results section: the central claim of consistent outperformance across metric categories and domains rests on results from only 41 questions; no per-domain breakdowns, statistical significance tests, inter-question variance, or error analysis are supplied, leaving open the possibility that apparent wins are driven by a small subset of favorable items rather than robust superiority of HKA.
- [KDR-Bench construction] KDR-Bench description: the weakest assumption is that 41 expert-level questions plus 1,252 tables across nine domains constitute a representative test of deep, structure-aware knowledge analysis; without evidence of question diversity, domain balance, or coverage of edge cases (e.g., conflicting tables or complex figure-table interactions), the benchmark scale risks under-supporting the generalization claims.
- [HKA framework / Evaluation metrics] Framework and evaluation sections: the Structured Knowledge Analyzer is described as using both coding and vision-language models, yet no details are given on how outputs are fused, how baselines (including Gemini) were prompted or configured for fair comparison, or how vision-enhanced metrics were computed, making the reported superiority difficult to reproduce or verify.
minor comments (2)
- [Introduction] The abstract and introduction could more explicitly distinguish KDR from prior DR benchmarks (e.g., by citing specific limitations of unstructured-only approaches).
- [Evaluation metrics] Notation for the three metric categories is introduced without a summary table; adding one would improve clarity when comparing HKA to baselines.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point-by-point below, providing honest responses and indicating planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract / Experimental results] Abstract and experimental results section: the central claim of consistent outperformance across metric categories and domains rests on results from only 41 questions; no per-domain breakdowns, statistical significance tests, inter-question variance, or error analysis are supplied, leaving open the possibility that apparent wins are driven by a small subset of favorable items rather than robust superiority of HKA.
Authors: We acknowledge that the evaluation relies on 41 expert-level questions and that the current results section lacks the requested breakdowns and statistical rigor. In the revised manuscript, we will add per-domain performance tables, report inter-question variance and standard deviations, include statistical significance tests (e.g., paired Wilcoxon tests against baselines), and provide an error analysis section that examines cases of strong and weak performance. These additions will allow readers to assess whether outperformance is robust or subset-driven. revision: yes
-
Referee: [KDR-Bench construction] KDR-Bench description: the weakest assumption is that 41 expert-level questions plus 1,252 tables across nine domains constitute a representative test of deep, structure-aware knowledge analysis; without evidence of question diversity, domain balance, or coverage of edge cases (e.g., conflicting tables or complex figure-table interactions), the benchmark scale risks under-supporting the generalization claims.
Authors: We agree that explicit evidence of representativeness strengthens the benchmark. The 41 questions were curated by domain experts for breadth across the nine domains, and the 1,252 tables include varied structures. In revision, we will expand the KDR-Bench section with: (i) quantitative domain-balance statistics, (ii) question-selection criteria and diversity metrics, and (iii) concrete examples of included edge cases such as conflicting tables and figure-table interactions. While we cannot immediately scale the question count without new expert annotations, we will release the full benchmark and annotation guidelines to support community extensions. revision: partial
-
Referee: [HKA framework / Evaluation metrics] Framework and evaluation sections: the Structured Knowledge Analyzer is described as using both coding and vision-language models, yet no details are given on how outputs are fused, how baselines (including Gemini) were prompted or configured for fair comparison, or how vision-enhanced metrics were computed, making the reported superiority difficult to reproduce or verify.
Authors: We apologize for the missing implementation details that impede reproducibility. The revised manuscript will include: (1) a precise description of the fusion process between coding-model outputs (tables, executed computations) and vision-language model interpretations; (2) the exact prompting templates, temperature settings, and configuration details used for all baselines including the Gemini DR agent; and (3) the full computation procedure for vision-enhanced metrics, including how visual elements are matched to annotated conclusions. We will also release the complete code, prompts, and evaluation scripts. revision: yes
Circularity Check
No significant circularity; empirical claims rest on new benchmark and external baselines
full rationale
The paper introduces the KDR task, proposes the HKA multi-agent framework, constructs the KDR-Bench dataset (41 questions, 1,252 tables across 9 domains), defines three metric categories, and reports empirical outperformance against external DR agents including Gemini. No equations, derivations, fitted parameters, or self-referential definitions appear in the abstract or described content. The central experimental claim does not reduce by construction to any input; it depends on comparisons with independent baselines on a newly created testbed. No load-bearing self-citations, uniqueness theorems, or ansatz smuggling are present. This is a standard systems/benchmark paper whose validity can be assessed externally via the benchmark itself rather than internal reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Perplexity AI. 2025. Introducing Perplexity Deep Research. https://www. perplexity.ai/hub/blog/introducing-perplexity-deep-research. Accessed: 2025-12
2025
-
[2]
Anthropic. 2025. Claude Haiku 4.5 (Thinking). https://www.anthropic.com/ claude. Accessed via Anthropic API, model version: claude-haiku-4-5-20251001- thinking
2025
-
[3]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, and et al. 2023. Qwen Technical Report.arXiv preprint arXiv:2309.16609(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhaohai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng Lin, Junyang Lin, Xuejing Liu, Jiawei Liu, Chenglong Liu, Yang Liu, Dayiheng Liu, Shixuan ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [5]
-
[6]
Zijian Chen, Xueguang Ma, Shengyao Zhuang, Ping Nie, Kai Zou, Andrew Liu, Joshua Green, Kshama Patel, Ruoxi Meng, Mingyi Su, Sahel Sharifymoghaddam, Yanxi Li, Haoran Hong, Xinyu Shi, Xuye Liu, Nandan Thakur, Crystina Zhang, Luyu Gao, Wenhu Chen, and Jimmy Lin. 2025. BrowseComp-Plus: A More Fair and Transparent Evaluation Benchmark of Deep-Research Agent.a...
-
[7]
DeepSeek-AI, Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, and Bochao Wu et. al. 2024. DeepSeek-V3 Technical Report. arXiv:2412.19437 [cs.CL] https: //arxiv.org/abs/2412.19437
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
Guanting Dong, Licheng Bao, Zhongyuan Wang, Kangzhi Zhao, Xiaoxi Li, Jiajie Jin, Jinghan Yang, Hangyu Mao, Fuzheng Zhang, Kun Gai, Guorui Zhou, Yutao Zhu, Ji-Rong Wen, and Zhicheng Dou. 2025. Agentic Entropy-Balanced Policy Optimization. arXiv:2510.14545 [cs.LG] https://arxiv.org/abs/2510.14545
-
[9]
Matthijs Douze, Alexandr Guzhva, Chengqi Deng, Jeff Johnson, Gergely Szilvasy, Pierre-Emmanuel Mazaré, Maria Lomeli, Lucas Hosseini, and Hervé Jégou. 2024. The Faiss library. (2024). arXiv:2401.08281 [cs.LG]
work page internal anchor Pith review arXiv 2024
- [10]
-
[11]
Google. 2024. Gemini 2.0 Flash. https://gemini.google.com. Accessed: 12/2024
2024
-
[12]
Google AI. 2025. Gemini Deep Research Agent Documentation. https://ai.google. dev/gemini-api/docs/deep-research. Official documentation for Gemini Deep Research agent, accessed December 2025
2025
- [13]
- [14]
- [15]
-
[16]
langchain-ai. 2025. Open Deep Research. https://github.com/langchain-ai/open_ deep_research. Open-source deep research agent built on LangGraph, accessed December 2025
2025
-
[17]
Kuan Li, Zhongwang Zhang, Huifeng Yin, Liwen Zhang, Litu Ou, Jialong Wu, Wenbiao Yin, Baixuan Li, Zhengwei Tao, Xinyu Wang, Weizhou Shen, Junkai Zhang, Dingchu Zhang, Xixi Wu, Yong Jiang, Ming Yan, Pengjun Xie, Fei Huang, and Jingren Zhou. 2025. WebSailor: Navigating Super-human Reasoning for Web Agent. arXiv:2507.02592 [cs.CL] https://arxiv.org/abs/2507.02592
- [18]
-
[19]
Yuan Liang, Jiaxian Li, Yuqing Wang, Piaohong Wang, Motong Tian, Pai Liu, Shuofei Qiao, Runnan Fang, He Zhu, Ge Zhang, Minghao Liu, Yuchen Eleanor Jiang, Ningyu Zhang, and Wangchunshu Zhou. 2025. Towards Personalized Deep Research: Benchmarks and Evaluations. arXiv:2509.25106 [cs.CL] https: //arxiv.org/abs/2509.25106
-
[20]
Fan Liu, Zherui Yang, Cancheng Liu, Tianrui Song, Xiaofeng Gao, and Hao Liu
-
[21]
arXiv:2505.14148 [cs.AI] https://arxiv.org/abs/2505.14148
MM-Agent: LLM as Agents for Real-world Mathematical Modeling Problem. arXiv:2505.14148 [cs.AI] https://arxiv.org/abs/2505.14148
-
[22]
MiniMax-AI. 2025. MiniMax M2. https://github.com/MiniMax-AI/MiniMax-M2. Open-source model for coding and agentic workflows released by MiniMax_AI; accessed Oct 2025
2025
-
[23]
OpenAI. 2024. text-embedding-3 family embedding models. https://platform. openai.com/docs/api-reference/embeddings. Accessed: Month Day, Year
2024
-
[24]
OpenAI. 2025. Deep research System Card. https://cdn.openai.com/deep- research-system-card.pdf. Accessed: 2025-12
2025
-
[25]
Long Phan, Alice Gatti, Ziwen Han, Nathaniel Li, Josephina Hu, Hugh Zhang, Sean Shi, Michael Choi, Anish Agrawal, Arnav Chopra, Adam Khoja, Ryan Kim, Jason Hausenloy, Oliver Zhang, Mantas Mazeika, Daron Anderson, Tung Towards Knowledgeable Deep Research: Framework and Benchmark Conference acronym ’XX, June 03–05, 2018, Woodstock, NY Nguyen, Mobeen Mahmood...
work page internal anchor Pith review doi:10.48550/arxiv.2501.14249 2018
- [26]
-
[27]
Serper.dev. 2025. Serper: The World’s Fastest & Cheapest Google Search API. https://serper.dev/
2025
-
[28]
Zhengliang Shi, Yiqun Chen, Haitao Li, Weiwei Sun, Shiyu Ni, Yougang Lyu, Run-Ze Fan, Bowen Jin, Yixuan Weng, Minjun Zhu, Qiujie Xie, Xinyu Guo, Qu Yang, Jiayi Wu, Jujia Zhao, Xiaqiang Tang, Xinbei Ma, Cunxiang Wang, Jiaxin Mao, Qingyao Ai, Jen-Tse Huang, Wenxuan Wang, Yue Zhang, Yiming Yang, Zhaopeng Tu, and Zhaochun Ren. 2025. Deep Research: A Systemati...
-
[29]
Aaditya Singh et al. 2026. OpenAI GPT-5 System Card. arXiv:2601.03267 [cs.CL] https://arxiv.org/abs/2601.03267
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[30]
GLM Team, Aohan Zeng, Xin Lv, Qinkai Zheng, Zhenyu Hou, Bin Chen, Chengx- ing Xie, Cunxiang Wang, Da Yin, Hao Zeng, Jiajie Zhang, Kedong Wang, Lucen Zhong, Mingdao Liu, Rui Lu, Shulin Cao, Xiaohan Zhang, Xuancheng Huang, Yao Wei, Yean Cheng, Yifan An, Yilin Niu, Yuanhao Wen, Yushi Bai, Zhengx- iao Du, Zihan Wang, Zilin Zhu, Bohan Zhang, Bosi Wen, Bowen Wu...
work page internal anchor Pith review arXiv 2025
- [31]
-
[32]
Tencent. 2024. Hunyuan 2.0. https://hunyuan.tencent.com. Accessed via Hunyuan API, model version: Hunyuan2.0
2024
-
[33]
thinkdepthai. 2025. Deep_Research: ThinkDepth.ai Deep Research. https://github. com/thinkdepthai/Deep_Research. GitHub repository, accessed on 2025-12-27
2025
-
[34]
2024.Crawl4AI: Open-source LLM Friendly Web Crawler & Scraper
UncleCode. 2024.Crawl4AI: Open-source LLM Friendly Web Crawler & Scraper
2024
-
[35]
Haiyuan Wan, Chen Yang, Junchi Yu, Meiqi Tu, Jiaxuan Lu, Di Yu, Jianbao Cao, Ben Gao, Jiaqing Xie, Aoran Wang, Wenlong Zhang, Philip Torr, and Dongzhan Zhou. 2025. DeepResearch Arena: The First Exam of LLMs’ Research Abilities via Seminar-Grounded Tasks. arXiv:2509.01396 [cs.AI] https://arxiv.org/abs/ 2509.01396
-
[36]
Jason Wei, Zhiqing Sun, Spencer Papay, Scott McKinney, Jeffrey Han, Isa Fulford, Hyung Won Chung, Alex Tachard Passos, William Fedus, and Amelia Glaese
-
[37]
BrowseComp: A Simple Yet Challenging Benchmark for Browsing Agents
BrowseComp: A Simple Yet Challenging Benchmark for Browsing Agents. arXiv:2504.12516 [cs.CL] https://arxiv.org/abs/2504.12516
work page internal anchor Pith review arXiv
- [38]
-
[39]
xAI. 2025. Grok 4 Model Card. https://data.x.ai/2025-08-20-grok-4-model- card.pdf. Official Grok 4 model card, August 2025
2025
- [40]
-
[41]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
Yi Yao, He Zhu, Piaohong Wang, Jincheng Ren, Xinlong Yang, Qianben Chen, Xiaowan Li, Dingfeng Shi, Jiaxian Li, Qiexiang Wang, Sinuo Wang, Xinpeng Liu, Jiaqi Wu, Minghao Liu, and Wangchunshu Zhou. 2026. O-Researcher: An Open Ended Deep Research Model via Multi-Agent Distillation and Agentic RL. arXiv:2601.03743 [cs.CL] https://arxiv.org/abs/2601.03743
-
[43]
Guibin Zhang, Hejia Geng, Xiaohang Yu, Zhenfei Yin, Zaibin Zhang, Zelin Tan, Heng Zhou, Zhongzhi Li, Xiangyuan Xue, Yijiang Li, Yifan Zhou, Yang Chen, Chen Zhang, Yutao Fan, Zihu Wang, Songtao Huang, Francisco Piedrahita-Velez, Yue Liao, Hongru Wang, Mengyue Yang, Heng Ji, Jun Wang, Shuicheng Yan, Philip Torr, and Lei Bai. 2025. The Landscape of Agentic R...
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [44]
-
[45]
Peilin Zhou, Bruce Leon, Xiang Ying, Can Zhang, Yifan Shao, Qichen Ye, Dading Chong, Zhiling Jin, Chenxuan Xie, Meng Cao, Yuxin Gu, Sixin Hong, Jing Ren, Jian Chen, Chao Liu, and Yining Hua. 2025. BrowseComp-ZH: Benchmarking Web Browsing Ability of Large Language Models in Chinese. arXiv:2504.19314 [cs.CL] https://arxiv.org/abs/2504.19314
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.