Recognition: 3 theorem links
· Lean TheoremSepSeq: A Training-Free Framework for Long Numerical Sequence Processing in LLMs
Pith reviewed 2026-05-10 18:29 UTC · model grok-4.3
The pith
Inserting separator tokens lets LLMs handle long numerical sequences with higher accuracy and fewer tokens.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper shows that strategically placed separator tokens function as attention sinks within the transformer layers. By drawing dispersed attention back to relevant local parts of long numerical sequences, these tokens reduce the effects of softmax dispersion and improve task accuracy while preserving overall context access.
What carries the argument
SepSeq, the training-free insertion of separator tokens that act as attention sinks to recalibrate softmax distributions across local segments.
If this is right
- Accuracy on numerical tasks improves across diverse domains without any model retraining.
- Total tokens consumed during inference drop on average because the model processes sequences more efficiently.
- The method works as a plug-in on many existing LLMs with no architecture changes.
- Global context stays available even as local attention becomes more focused.
Where Pith is reading between the lines
- The same separator approach might reduce attention issues in long non-numerical sequences such as extended code or documents.
- Optimal separator spacing could be determined empirically for different model sizes and sequence lengths.
- The technique might combine with other context-extension methods to push the practical limits of current LLMs further.
Load-bearing premise
The main reason LLMs fail on long numerical sequences is attention dispersion in the softmax, and separator tokens can redirect focus without adding errors or losing global information.
What would settle it
Running the same long numerical benchmarks on multiple LLMs and finding no accuracy gain or a clear increase in errors after adding separators would show the attention-sink mechanism does not work as claimed.
Figures



read the original abstract
While transformer-based Large Language Models (LLMs) theoretically support massive context windows, they suffer from severe performance degradation when processing long numerical sequences. We attribute this failure to the attention dispersion in the Softmax mechanism, which prevents the model from concentrating attention. To overcome this, we propose Separate Sequence (SepSeq), a training-free, plug-and-play framework to mitigate dispersion by strategically inserting separator tokens. Mechanistically, we demonstrate that separator tokens act as an attention sink, recalibrating attention to focus on local segments while preserving global context. Extensive evaluations on 9 widely-adopted LLMs confirm the effectiveness of our approach: SepSeq yields an average relative accuracy improvement of 35.6% across diverse domains while reducing total inference token consumption by 16.4% on average.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SepSeq, a training-free, plug-and-play framework for LLMs processing long numerical sequences. It attributes performance degradation to attention dispersion in the softmax mechanism and proposes inserting separator tokens that act as attention sinks to recalibrate focus on local segments while preserving global context. Evaluations across 9 LLMs report an average 35.6% relative accuracy improvement and 16.4% reduction in total inference token consumption over diverse domains.
Significance. If substantiated, the training-free nature and multi-model evaluation would make this a practical contribution for improving numerical reasoning in long-context LLMs without retraining costs. The plug-and-play design and reported efficiency gains are strengths that could aid applications in data analysis and mathematical tasks. However, the significance hinges on validating the specific mechanistic attribution rather than alternative explanations like segmentation effects.
major comments (3)
- [Abstract and Evaluation section] Abstract and Evaluation section: The central claims of 35.6% relative accuracy improvement and 16.4% token reduction are reported only as aggregates across 9 LLMs and diverse domains, with no details on task descriptions, dataset sizes, per-domain or per-model breakdowns, baseline comparisons (e.g., standard long-context prompting or chunking), error bars, or statistical tests. This leaves the empirical support for the framework unverifiable and undermines assessment of robustness.
- [Method section (mechanistic analysis)] Method section (mechanistic analysis): The load-bearing claim that separator tokens mitigate softmax dispersion by acting as attention sinks (recalibrating local focus without losing global information or introducing errors) lacks isolating ablations, such as comparisons to random token insertions at the same positions, boundary-only markers, or attention-masked variants. Without these or quantitative attention weight analyses, alternative mechanisms (e.g., explicit segmentation aiding numerical parsing) cannot be ruled out, making the design rationale insecure.
- [Results section] Results section: The assertion of preserved global context alongside local recalibration is stated but unsupported by evidence on tasks requiring long-range dependencies or by attention map comparisons before/after separator insertion. This is critical because the token reduction claim (despite added separators) implies efficiency gains that depend on the mechanism working as described.
minor comments (3)
- [Method section] The notation and exact insertion strategy for separator tokens (e.g., frequency, type, and positioning rules) would benefit from pseudocode or a clear algorithm box in the method section for reproducibility.
- [Related work] Related work would be strengthened by explicit comparison to prior attention sink literature (e.g., StreamingLLM) to better highlight novelty versus incremental application to numerical sequences.
- [Figures] Figures illustrating attention distributions would be clearer with side-by-side before/after examples and quantitative metrics (e.g., entropy or max attention values) rather than qualitative descriptions alone.
Simulated Author's Rebuttal
We are grateful to the referee for the detailed and insightful comments, which have helped us identify areas for improvement in the manuscript. We address each major comment below, indicating the revisions we plan to make to enhance the empirical support and mechanistic validation of SepSeq.
read point-by-point responses
-
Referee: The central claims of 35.6% relative accuracy improvement and 16.4% token reduction are reported only as aggregates across 9 LLMs and diverse domains, with no details on task descriptions, dataset sizes, per-domain or per-model breakdowns, baseline comparisons (e.g., standard long-context prompting or chunking), error bars, or statistical tests.
Authors: We thank the referee for highlighting this issue. The aggregate reporting was intended to provide a high-level overview, but we agree it limits detailed assessment. In the revised manuscript, we will include comprehensive breakdowns by model and domain, full task and dataset descriptions, baseline comparisons including standard prompting and chunking, error bars, and statistical tests such as Wilcoxon signed-rank tests to demonstrate significance. These additions will be placed in an expanded Evaluation section. revision: yes
-
Referee: The load-bearing claim that separator tokens mitigate softmax dispersion by acting as attention sinks lacks isolating ablations, such as comparisons to random token insertions, boundary-only markers, or attention-masked variants. Without these or quantitative attention weight analyses, alternative mechanisms cannot be ruled out.
Authors: We appreciate this point on strengthening the mechanistic claims. The original manuscript includes attention visualizations showing the sink behavior, but to address potential alternatives like segmentation effects, we will incorporate additional ablations comparing to random insertions and boundary markers in the revised version. Quantitative attention analyses will be expanded. However, full attention-masked variants may not be feasible without modifying the model architecture significantly, but we will discuss this limitation. revision: partial
-
Referee: The assertion of preserved global context alongside local recalibration is stated but unsupported by evidence on tasks requiring long-range dependencies or by attention map comparisons before/after separator insertion.
Authors: We acknowledge the need for more direct evidence. While performance on diverse long-sequence tasks implies preservation of global context, we will add specific evaluations on long-range dependency tasks and include comparative attention maps in the Results section of the revision to better support this claim. This will also help explain the token efficiency gains. revision: yes
Circularity Check
No circularity; empirical gains measured externally on multiple LLMs without self-referential derivations or fitted predictions
full rationale
The paper presents SepSeq as a training-free, plug-and-play insertion of separator tokens, with performance claims (35.6% relative accuracy gain, 16.4% token reduction) derived from direct evaluations across 9 external LLMs rather than any internal fitting, self-definition, or self-citation chain. The mechanistic claim that separators act as attention sinks is offered as a post-hoc demonstration (likely via attention visualization), not as a load-bearing mathematical derivation that reduces to the input assumptions by construction. No equations, parameter fits, uniqueness theorems, or ansatzes are invoked that would create circularity per the enumerated patterns. The framework remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Transformer LLMs suffer severe performance degradation on long numerical sequences due to attention dispersion in Softmax
invented entities (1)
-
separator tokens acting as attention sinks
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearseparator tokens act as an attention sink, recalibrating attention to focus on local segments while preserving global context
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclearperformance gains saturate for intervals k ≥ 8
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_strictMono_of_one_lt unclearSepSeq(S, k) = ... ⊕τsep ⊕ ... (segmented at every k-th interval)
Reference graph
Works this paper leans on
-
[1]
MateICL: Mitigating attention dispersion in large-scale in-context learning.arXiv preprint, abs/2505.01110. Anthropic. 2025. System card: Claude opus 4 & claude sonnet 4. Federico Barbero, Andrea Banino, Steven Kaptur- owski, Dharshan Kumaran, João G.M. Araújo, Alex Vitvitskyi, Razvan Pascanu, and Petar Veli ˇckovi´c
-
[2]
ReTool: Reinforcement Learning for Strategic Tool Use in LLMs
Transformers need glasses! Information over- squashing in language tasks. InAdvances in Neural Information Processing Systems 37, pages 98111– 98142, Vancouver, Canada. Guoxuan Chen, Han Shi, Jiawei Li, Yihang Gao, Xi- aozhe Ren, Yimeng Chen, Xin Jiang, Zhenguo Li, Weiyang Liu, and Chao Huang. 2024. SepLLM: Ac- celerate large language models by compressin...
work page internal anchor Pith review arXiv 2024
-
[3]
Qwen3 technical report.arXiv preprint, abs/2505.09388. Junchi Yao, Shu Yang, Jianhua Xu, Lijie Hu, Mengdi Li, and Di Wang. 2025. Understanding the repeat curse in large language models from a feature perspective. arXiv preprint, abs/2504.14218. Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2023. React: Synergi...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Qwen3-30B-A3B: https://huggingface.co /Qwen/Qwen3-30B-A3B
-
[6]
QwQ-32B: https://huggingface.co/Qwen/ QwQ-32B
-
[7]
DeepSeek-V3: https://huggingface.co/d eepseek-ai/DeepSeek-V3-0324
-
[8]
DeepSeek-R1: https://huggingface.co/d eepseek-ai/DeepSeek-R1-0528
-
[9]
Claude-3.7-Sonnet: https://openrouter.a i/anthropic/claude-3.7-sonnet
-
[10]
Gemini-2.5-Pro: https://openrouter.ai/go ogle/gemini-2.5-pro
-
[11]
GPT-4.1: https://openrouter.ai/openai /gpt-4.1
-
[12]
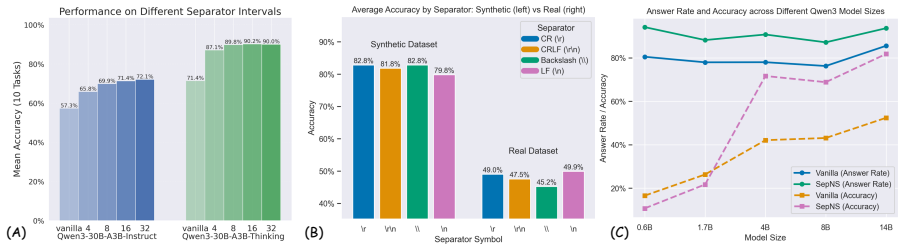
GPT-4o: https://openrouter.ai/openai/g pt-4o-2024-08-06 For robustness evaluation (RQ2),separator in- terval analysis, we compare instruction and rea- soning variants:
2024
-
[13]
Qwen3-30B-A3B-Instruct: https://huggin gface.co/Qwen/Qwen3-30B-A3B-Instruc t-2507
-
[14]
Formodel size analysis, we evaluate across dif- ferent parameter scales:
Qwen3-30B-A3B-Thinking: https://huggin gface.co/Qwen/Qwen3-30B-A3B-Thinkin g-2507 Forseparator symbol analysis, we use Qwen3- 30B-A3B-Instruct (https://huggingface.co/Q wen/Qwen3-30B-A3B-Instruct-2507). Formodel size analysis, we evaluate across dif- ferent parameter scales:
-
[15]
Qwen3-0.6B: https://huggingface.co/Qwe n/Qwen3-0.6B
-
[16]
Qwen3-1.7B: https://huggingface.co/Qwe n/Qwen3-1.7B
-
[17]
Qwen3-4B: https://huggingface.co/Qwen/ Qwen3-4B
-
[18]
Qwen3-8B: https://huggingface.co/Qwen/ Qwen3-8B
-
[19]
Qwen3-14B: https://huggingface.co/Qwe n/Qwen3-14B
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.