Administrative Decentralization in Edge-Cloud Multi-Agent for Mobile Automation
Pith reviewed 2026-05-10 17:54 UTC · model grok-4.3
The pith
AdecPilot decentralizes administration in edge-cloud multi-agent systems so edge agents can handle tactical planning and self-correction independently for mobile automation tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
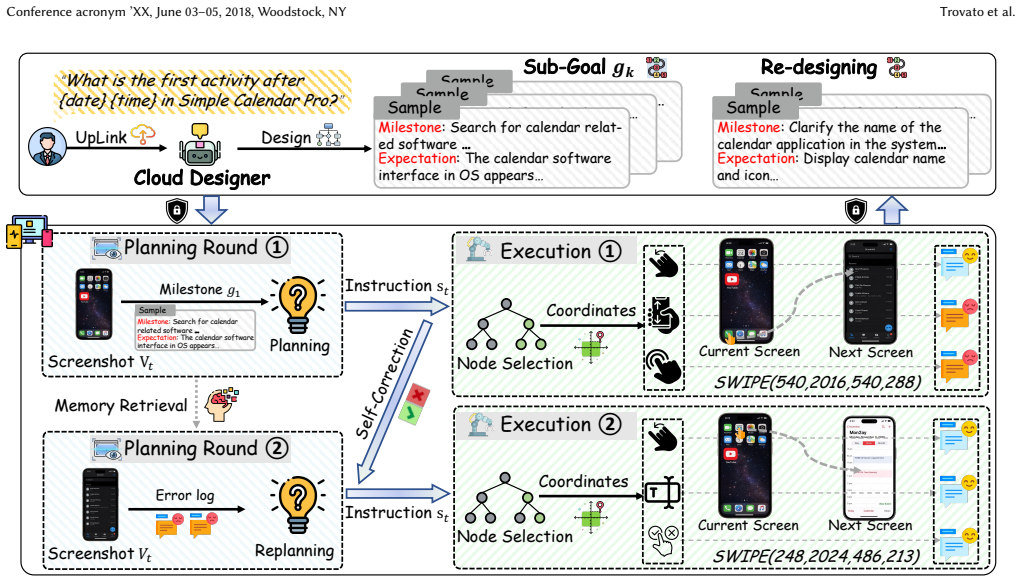
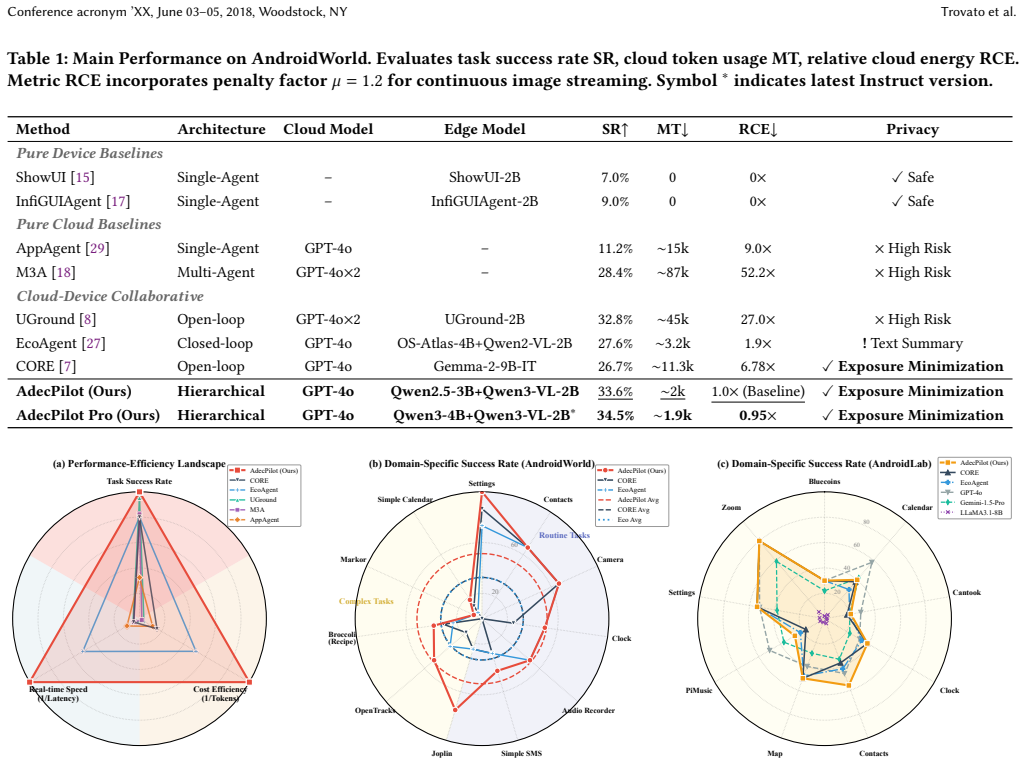
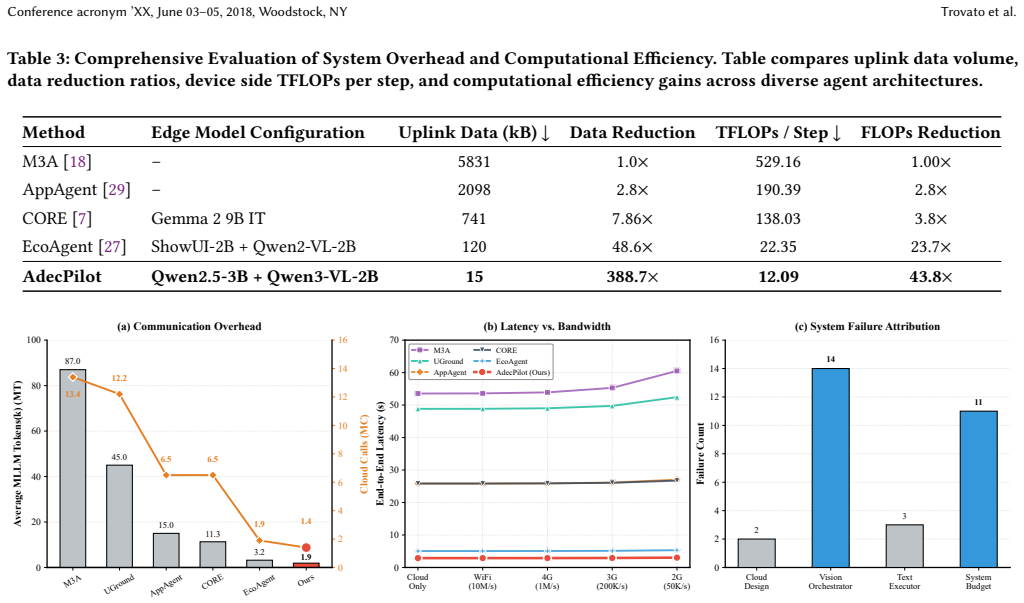
By redefining edge agency through administrative decentralization, AdecPilot pairs a UI-agnostic cloud designer that emits abstract milestones with a bimodal edge team that performs autonomous tactical planning and self-correction. The Hierarchical Implicit Termination protocol supplies deterministic stopping conditions. This structure yields a 21.7 percent higher task success rate and 37.5 percent lower cloud token consumption than EcoAgent together with an 88.9 percent latency reduction versus CORE.
What carries the argument
Administrative decentralization that decouples cloud-generated abstract milestones from an autonomous bimodal edge team plus the Hierarchical Implicit Termination protocol that enforces deterministic completion.
If this is right
- Task success rate rises 21.7 percent over EcoAgent.
- Cloud token consumption falls 37.5 percent.
- End-to-end latency drops 88.9 percent compared with CORE.
- Edge agents operate without constant cloud oversight for real-time UI changes.
- Post-completion hallucinations are prevented by deterministic termination.
Where Pith is reading between the lines
- The same separation of strategic milestones from tactical execution could be tested in non-UI domains such as robotic navigation or sensor-driven control loops.
- Greater edge autonomy might further lower privacy exposure by reducing the volume of UI state sent to the cloud.
- The termination protocol could be adapted to other multi-agent systems to curb runaway agent behavior after goal achievement.
Load-bearing premise
The bimodal edge team can reliably perform autonomous tactical planning and self-correction without cloud intervention across varied real-world mobile UI dynamics and task types.
What would settle it
Real-world trials in which the edge team repeatedly fails to self-correct on dynamic UI changes and must query the cloud, eliminating the reported latency and token reductions while dropping success rate below baseline.
Figures


read the original abstract
Collaborative edge-cloud frameworks have emerged as the main- stream paradigm for mobile automation, mitigating the latency and privacy risks inherent to monolithic cloud agents. However, existing approaches centralize administration in the cloud while relegating the device to passive execution, inducing a cognitive lag regard- ing real-time UI dynamics. To tackle this, we introduce AdecPilot by applying the principle of administrative decentralization to the edge-cloud multi-agent framework, which redefines edge agency by decoupling high-level strategic designing from tactical grounding. AdecPilot integrates a UI-agnostic cloud designer generating ab- stract milestones with a bimodal edge team capable of autonomous tactical planning and self-correction without cloud intervention. Furthermore, AdecPilot employs a Hierarchical Implicit Termi- nation protocol to enforce deterministic stops and prevent post- completion hallucinations. Extensive experiments demonstrate pro- posed approach improves task success rate by 21.7% while reducing cloud token consumption by 37.5% against EcoAgent and decreas- ing end to end latency by 88.9% against CORE. The source code is available at https://anonymous.4open.science/r/Anonymous_code- B8AB.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes AdecPilot, an edge-cloud multi-agent framework for mobile automation that decentralizes administration by assigning high-level strategic milestone design to a cloud component and autonomous tactical planning plus self-correction to a bimodal edge team. A Hierarchical Implicit Termination protocol is introduced to enforce deterministic task stops. Experiments are claimed to demonstrate a 21.7% higher task success rate and 37.5% lower cloud token consumption versus EcoAgent, together with an 88.9% end-to-end latency reduction versus CORE.
Significance. If the reported gains are reproducible, the work would meaningfully advance practical mobile automation by lowering cloud dependency, token costs, and latency while preserving privacy. The explicit separation of strategy from tactics and the open-source code release are concrete strengths that could influence subsequent multi-agent designs for dynamic UI environments.
major comments (3)
- [Abstract and Experiments section] Abstract and Experiments section: the headline metrics (21.7% success-rate gain, 37.5% token reduction vs EcoAgent, 88.9% latency reduction vs CORE) are stated without reporting task-suite composition, number of trials, statistical significance tests, exact baseline re-implementations, or controls for UI variability. These omissions prevent independent verification of the central empirical claims.
- [Section 3.2 (Bimodal Edge Team)] Section 3.2 (Bimodal Edge Team): the claim that the edge team performs reliable autonomous tactical planning and self-correction without cloud intervention across varied real-world UI dynamics is load-bearing for all three performance deltas, yet no intervention-frequency statistics, failure-mode analysis, or ablation on ambiguous or rapidly changing UI states are supplied. If fallback frequency is high, both latency and token savings collapse.
- [Section 3.3 (Hierarchical Implicit Termination)] Section 3.3 (Hierarchical Implicit Termination): the protocol is described only at a conceptual level; no pseudocode, formal termination condition, or quantitative evaluation of hallucination prevention is given, leaving the deterministic-stop guarantee unverified.
minor comments (2)
- [Abstract] The abstract introduces 'bimodal edge team' and 'UI-agnostic cloud designer' without a one-sentence definition or pointer to the corresponding figure; a brief gloss would improve first-read clarity.
- [References] Ensure EcoAgent and CORE are cited with full bibliographic details (venue, year) so readers can locate the exact prior implementations used for comparison.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We have addressed each major comment point by point below. Revisions have been made to improve the reproducibility and rigor of the empirical sections without altering the core claims or methodology.
read point-by-point responses
-
Referee: [Abstract and Experiments section] Abstract and Experiments section: the headline metrics (21.7% success-rate gain, 37.5% token reduction vs EcoAgent, 88.9% latency reduction vs CORE) are stated without reporting task-suite composition, number of trials, statistical significance tests, exact baseline re-implementations, or controls for UI variability. These omissions prevent independent verification of the central empirical claims.
Authors: We agree that the original presentation omitted key experimental details needed for verification. In the revised manuscript, the Experiments section has been expanded to explicitly report the task-suite composition (including the specific mobile automation scenarios and UI environments used), the total number of trials per condition, statistical significance tests (including p-values and confidence intervals), precise descriptions of how each baseline (EcoAgent and CORE) was re-implemented, and the controls applied for UI variability (such as randomization of UI states and device configurations). These additions enable independent reproduction of the reported gains. revision: yes
-
Referee: [Section 3.2 (Bimodal Edge Team)] Section 3.2 (Bimodal Edge Team): the claim that the edge team performs reliable autonomous tactical planning and self-correction without cloud intervention across varied real-world UI dynamics is load-bearing for all three performance deltas, yet no intervention-frequency statistics, failure-mode analysis, or ablation on ambiguous or rapidly changing UI states are supplied. If fallback frequency is high, both latency and token savings collapse.
Authors: The referee correctly identifies that autonomy metrics are essential to substantiate the performance deltas. We have revised Section 3.2 to include intervention-frequency statistics measured across all trials, a comprehensive failure-mode analysis categorizing cases where cloud fallback occurred, and a dedicated ablation study isolating performance under ambiguous and rapidly changing UI states. The added results show low fallback rates, confirming that the edge team's autonomous tactical planning and self-correction hold under the tested conditions and that the latency and token savings are not artifacts of frequent cloud intervention. revision: yes
-
Referee: [Section 3.3 (Hierarchical Implicit Termination)] Section 3.3 (Hierarchical Implicit Termination): the protocol is described only at a conceptual level; no pseudocode, formal termination condition, or quantitative evaluation of hallucination prevention is given, leaving the deterministic-stop guarantee unverified.
Authors: We acknowledge that the original description of the Hierarchical Implicit Termination protocol remained at a high level. The revised Section 3.3 now provides pseudocode for the full protocol, a formal mathematical definition of the termination condition (including the hierarchical triggering rules), and quantitative evaluation results from controlled experiments measuring hallucination rates with and without the protocol. These additions verify the deterministic-stop guarantee and its contribution to preventing post-completion hallucinations. revision: yes
Circularity Check
No circularity; purely empirical claims with no derivation chain
full rationale
The paper describes an architectural approach (AdecPilot) and reports empirical gains from experiments against baselines (EcoAgent, CORE). No equations, fitted parameters, predictions derived from inputs, or self-citation chains appear in the provided text. The central claims reduce to measured task success, token use, and latency deltas rather than any self-referential construction. The bimodal edge-team autonomy is presented as a design premise whose reliability is asserted via experiment, not derived by definition or prior self-work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Theodoros Aslanidis, Sokol Kosta, Spyros Lalis, and Dimitris Chatzopoulos. 2025. Cross-Domain DRL Agents for Efficient Job Placement in the Cloud-Edge Con- tinuum. InProceedings of the 5th Workshop on Machine Learning and Systems, EuroMLSys 2025, World Trade Center, Rotterdam, The Netherlands, 30 March 2025- 3 April 2025. 276–285
work page 2025
-
[2]
Hao Bai, Yifei Zhou, Jiayi Pan, Mert Cemri, Alane Suhr, Sergey Levine, and Aviral Kumar. 2024. DigiRL: Training In-The-Wild Device-Control Agents with Au- tonomous Reinforcement Learning. InAdvances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processing Systems 2024, NeurIPS 2024, Vancouver, BC, Canada, December 10...
work page 2024
-
[3]
Ronshee Chawla, Daniel Vial, Sanjay Shakkottai, and R. Srikant. 2023. Col- laborative Multi-Agent Heterogeneous Multi-Armed Bandits. InInternational Conference on Machine Learning, ICML 2023, 23-29 July 2023, Honolulu, Hawaii, USA (Proceedings of Machine Learning Research, Vol. 202). 4189–4217
work page 2023
-
[4]
Xinran Chen, Yuchen Li, Hengyi Cai, Zhuoran Ma, Xuanang Chen, Haoyi Xiong, Shuaiqiang Wang, Ben He, Le Sun, and Dawei Yin. 2025. Multi-agent proactive information seeking with adaptive llm orchestration for non-factoid question answering. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2. 4341–4352
work page 2025
-
[5]
Tong Cheng, Hang Dong, Lu Wang, Bo Qiao, Si Qin, Qingwei Lin, Dongmei Zhang, Saravan Rajmohan, and Thomas Moscibroda. 2023. Multi-Agent Rein- forcement Learning with Shared Policy for Cloud Quota Management Problem. InCompanion Proceedings of the ACM Web Conference 2023, WWW 2023, Austin, TX, USA, 30 April 2023 - 4 May 2023. 391–395
work page 2023
-
[6]
Alex Clinton, Yiding Chen, Jerry Zhu, and Kirthevasan Kandasamy. 2025. Col- laborative Mean Estimation Among Heterogeneous Strategic Agents: Individual Rationality, Fairness, and Truthful Contribution. InForty-second International Conference on Machine Learning, ICML 2025, Vancouver, BC, Canada, July 13-19, 2025
work page 2025
-
[7]
Gucongcong Fan, Chaoyue Niu, chengfei lv, Fan Wu, and Guihai Chen. 2025. CORE: Reducing UI Exposure in Mobile Agents via Collaboration Between Cloud and Local LLMs. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems
work page 2025
-
[8]
Boyu Gou, Ruohan Wang, Boyuan Zheng, Yanan Xie, Cheng Chang, Yiheng Shu, Huan Sun, and Yu Su. 2025. Navigating the Digital World as Humans Do: Universal Visual Grounding for GUI Agents. InThe Thirteenth International Conference on Learning Representations
work page 2025
-
[9]
Xuehang Guo, Xingyao Wang, Yangyi Chen, Sha Li, Chi Han, Manling Li, and Heng Ji. 2025. SyncMind: Measuring Agent Out-of-Sync Recovery in Collabora- tive Software Engineering. InForty-second International Conference on Machine Learning, ICML 2025, Vancouver, BC, Canada, July 13-19, 2025
work page 2025
-
[10]
Xiao Han, Chen Zhu, Hengshu Zhu, and Xiangyu Zhao. 2025. Swarm intelligence in geo-localization: A multi-agent large vision-language model collaborative framework. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2. 814–825
work page 2025
-
[11]
Senkang Hu, Yihang Tao, Guowen Xu, Yiqin Deng, Xianhao Chen, Yuguang Fang, and Sam Kwong. 2025. CP-Guard: Malicious Agent Detection and Defense in Collaborative Bird’s Eye View Perception. InAAAI-25, Sponsored by the Associ- ation for the Advancement of Artificial Intelligence, February 25 - March 4, 2025, Philadelphia, PA, USA. 23203–23211
work page 2025
-
[12]
Guanjie Huang, Danny HK Tsang, Shan Yang, Guangzhi Lei, and Li Liu. 2025. Cued-Agent: A Collaborative Multi-Agent System for Automatic Cued Speech Recognition. InProceedings of the 33rd ACM International Conference on Multime- dia. 8313–8321
work page 2025
-
[13]
Zaid Khan, Elias Stengel-Eskin, Jaemin Cho, and Mohit Bansal. 2025. DataEn- vGym: Data Generation Agents in Teacher Environments with Student Feedback. InThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025
work page 2025
-
[14]
Senyao Li, Haozhao Wang, Wenchao Xu, Rui Zhang, Song Guo, Jingling Yuan, Xian Zhong, Tianwei Zhang, and Ruixuan Li. 2025. Collaborative inference and learning between edge slms and cloud LLMs: A survey of algorithms, execution, and open challenges.arXiv preprint arXiv:2507.16731(2025)
-
[15]
Kevin Qinghong Lin, Linjie Li, Difei Gao, Zhengyuan Yang, Shiwei Wu, Zechen Bai, Stan Weixian Lei, Lijuan Wang, and Mike Zheng Shou. 2025. Showui: One vision-language-action model for gui visual agent. InProceedings of the Computer Vision and Pattern Recognition Conference. 19498–19508
work page 2025
-
[16]
Wenjin Liu, Haoran Luo, Xueyuan Lin, Haoming Liu, Tiesunlong Shen, Jiapu Wang, Rui Mao, and Erik Cambria. 2025. Prompt-R1: Collaborative Automatic Prompting Framework via End-to-end Reinforcement Learning.arXiv preprint arXiv:2511.01016(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Yuhang Liu, Pengxiang Li, Zishu Wei, Congkai Xie, Xueyu Hu, Xinchen Xu, Shengyu Zhang, Xiaotian Han, Hongxia Yang, and Fei Wu. 2026. Infiguiagent: A multimodal generalist gui agent with native reasoning and reflection. InPro- ceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers). 1035–1051
work page 2026
- [18]
-
[19]
Jiayuan Rao, Zifeng Li, Haoning Wu, Ya Zhang, Yanfeng Wang, and Weidi Xie
-
[20]
InProceedings of the 33rd ACM International Conference on Multimedia
Multi-agent system for comprehensive soccer understanding. InProceedings of the 33rd ACM International Conference on Multimedia. 3654–3663
-
[21]
Chris Rawles, Sarah Clinckemaillie, Yifan Chang, Jonathan Waltz, Gabrielle Lau, Marybeth Fair, Alice Li, William Bishop, Wei Li, Folawiyo Campbell-Ajala, Daniel Toyama, Robert Berry, Divya Tyamagundlu, Timothy Lillicrap, and Oriana Riva
-
[22]
InInternational Conference on Representation Learning
AndroidWorld: A Dynamic Benchmarking Environment for Autonomous Agents. InInternational Conference on Representation Learning. 406–441
-
[23]
Chenyang Shao, Xinyuan Hu, Yutang Lin, and Fengli Xu. 2025. Division-of- Thoughts: Harnessing Hybrid Language Model Synergy for Efficient On-Device Agents. InProceedings of the ACM on Web Conference 2025, WWW 2025, Sydney, NSW, Australia, 28 April 2025- 2 May 2025. 1822–1833
work page 2025
-
[24]
Hongda Sun, Hongzhan Lin, Haiyu Yan, Yang Song, Xin Gao, and Rui Yan. 2025. MockLLM: A Multi-Agent Behavior Collaboration Framework for Online Job Seeking and Recruiting. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining, V.2, KDD 2025, Toronto ON, Canada, August 3-7, 2025. 2714–2724
work page 2025
-
[25]
Hao Sun, Jiayi Wu, Hengyi Cai, Xiaochi Wei, Yue Feng, Bo Wang, Shuaiqiang Wang, Yan Zhang, and Dawei Yin. 2024. AdaSwitch: Adaptive Switching between Small and Large Agents for Effective Cloud-Local Collaborative Learning. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, EMNLP 2024, Miami, FL, USA, November 12-16,...
work page 2024
- [26]
-
[27]
Quanmin Wei, Penglin Dai, Wei Li, Bingyi Liu, and Xiao Wu. 2025. CoPEFT: Fast Adaptation Framework for Multi-Agent Collaborative Perception with Parameter- Efficient Fine-Tuning. InAAAI-25, Sponsored by the Association for the Advance- ment of Artificial Intelligence, February 25 - March 4, 2025, Philadelphia, PA, USA. 23351–23359
work page 2025
-
[28]
Yifan Xu, Xiao Liu, Xueqiao Sun, Siyi Cheng, Hao Yu, Hanyu Lai, Shudan Zhang, Dan Zhang, Jie Tang, and Yuxiao Dong. 2025. Androidlab: Training and systematic benchmarking of android autonomous agents. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2144–2166
work page 2025
- [29]
- [30]
-
[31]
Chi Zhang, Zhao Yang, Jiaxuan Liu, Yanda Li, Yucheng Han, Xin Chen, Zebiao Huang, Bin Fu, and Gang Yu. 2025. Appagent: Multimodal agents as smartphone users. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems. 1–20
work page 2025
-
[32]
Guibin Zhang, Luyang Niu, Junfeng Fang, Kun Wang, Lei Bai, and Xiang Wang
-
[33]
Multi-agent Architecture Search via Agentic Supernet. InForty-second International Conference on Machine Learning, ICML 2025, Vancouver, BC, Canada, July 13-19, 2025
work page 2025
-
[34]
Shaokun Zhang, Ming Yin, Jieyu Zhang, Jiale Liu, Zhiguang Han, Jingyang Zhang, Beibin Li, Chi Wang, Huazheng Wang, Yiran Chen, and Qingyun Wu. 2025. Which Agent Causes Task Failures and When? On Automated Failure Attribution of LLM Multi-Agent Systems. InForty-second International Conference on Machine Learning, ICML 2025, Vancouver, BC, Canada, July 13-1...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.