Recognition: no theorem link
An Empirical Study on Influence-Based Pretraining Data Selection for Code Large Language Models
Pith reviewed 2026-05-10 18:08 UTC · model grok-4.3
The pith
Filtering pretraining data for code LLMs by its influence on validation loss improves performance on programming tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
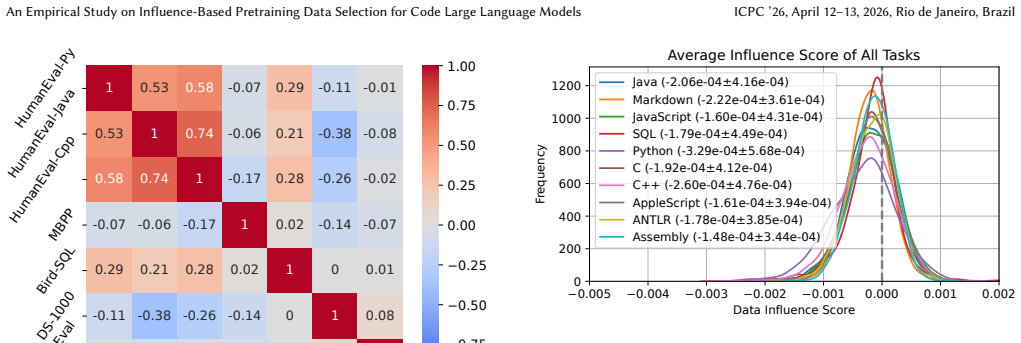
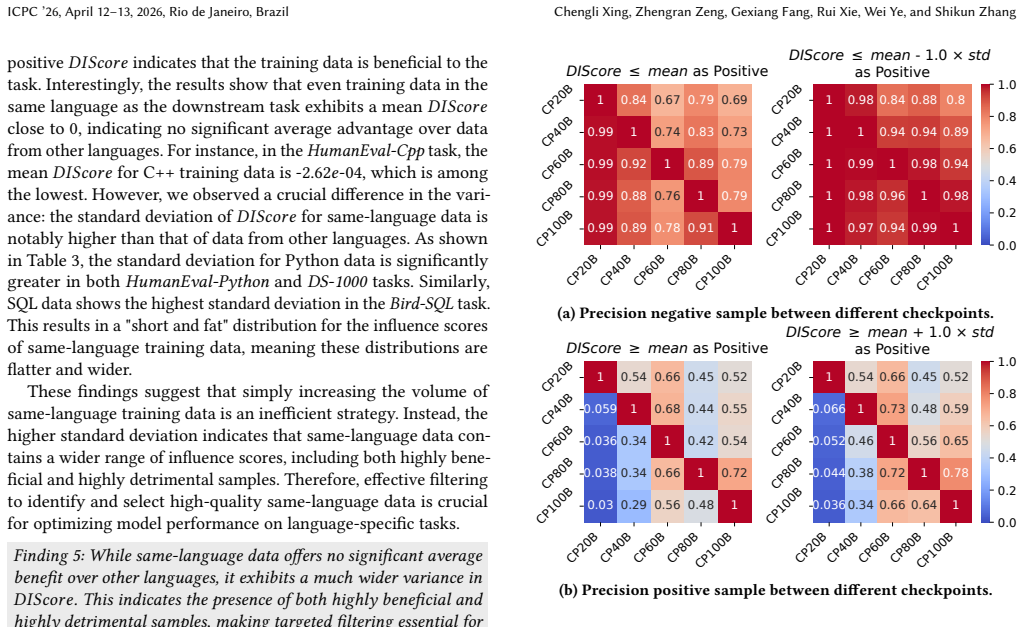
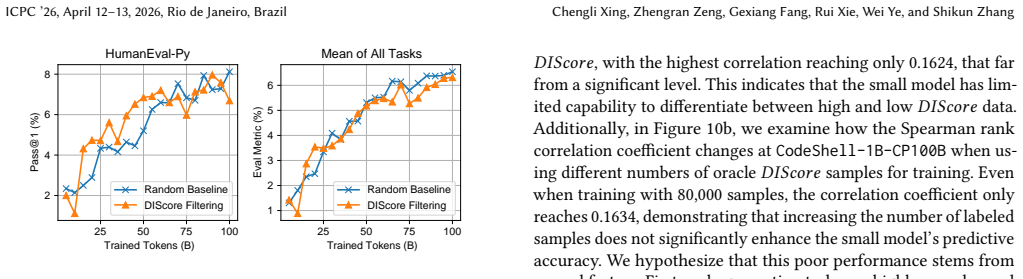
Data-influence-score filtering based on validation-set-loss can enhance models programming performance. Moreover, the criteria of beneficial training data differ significantly across various downstream programming tasks. This conclusion follows from transforming coding tasks into validation sets, computing influence scores for each pretraining example via loss reduction, training the model on the resulting filtered corpus, and measuring downstream accuracy gains.
What carries the argument
Data-influence-score, computed as the change in model loss on task-specific validation sets obtained by transforming downstream coding problems into generative formats.
If this is right
- Models trained on the filtered data achieve higher accuracy on code generation and related benchmarks.
- Uniform data selection rules cannot be applied across all programming tasks because beneficial examples differ by task.
- Prediction-based approximations to the influence scores remain practical for scaling the method to larger corpora.
- Pretraining runs become more sample-efficient by discarding examples that increase validation loss.
Where Pith is reading between the lines
- General data filters developed for text may need replacement by task-aware scores when the target domain is code.
- Curating pretraining corpora for code models should incorporate multiple validation sets rather than a single general one.
- The same influence calculation could be reused to rank data for fine-tuning stages after pretraining.
Load-bearing premise
Loss measured on transformed validation sets from downstream coding tasks serves as a reliable proxy for how much each pretraining example actually improves the model's final capabilities.
What would settle it
Retrain the model on the influence-filtered subset and find no consistent accuracy gains (or even losses) on held-out versions of the same programming tasks.
Figures






read the original abstract
Recent advancements in code large language models (Code-LLMs) have demonstrated remarkable capabilities in resolving programming related tasks. Meanwhile, researchers have recognized that the quality of pre-training data is crucial for improving LLM performance. However, most of the existing research on pre-training data filtering has focused on general datasets, and little attention for programming datasets. In this paper, we aim to address this gap by exploring the effectiveness of a widely used general data filtering technique, i.e., data-influence-score filtering, within the context of programming-related datasets. To this end, we first introduce a method for calculating data-influence-score for generative programming tasks which involves transforming a variety of downstream coding tasks into validation sets and using the models loss on these sets as a performance metric. Next, we pre-train a Code-LLMs with 1 billion parameters from scratch on a dataset of 100 billion code tokens. Based on it, we conduct an extensive empirical study to evaluate the effectiveness of data-influence-score filtering methods. Specifically, we examine how well this technique improves model performance, investigate how the characteristics of beneficial training data vary across different training stages and programming tasks, and assess the feasibility of prediction-based data-influence-score filtering method. Our findings show that data-influence-score filtering based on validation-set-loss can enhance models programming performance. Moreover, we observe that the criteria of beneficial training data differ significantly across various downstream programming tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that data-influence-score filtering—computed via model loss on validation sets obtained by transforming downstream coding tasks (e.g., code completion/generation) into next-token prediction format—can enhance Code-LLM programming performance when applied to pretraining data selection. A 1B-parameter model is pretrained from scratch on 100B code tokens; experiments then compare filtered vs. unfiltered data, report task-dependent differences in beneficial data characteristics, and assess prediction-based variants of the influence metric.
Significance. If the results hold, the work would supply concrete empirical evidence that influence-based filtering using validation loss improves code pretraining outcomes and that optimal data criteria vary by downstream task, addressing a noted gap relative to general-domain filtering studies. The from-scratch pretraining at 100B-token scale is a clear strength that supports reproducibility of the core comparison. Significance is limited by the absence of explicit verification that loss reductions on the transformed validation sets translate to gains on execution-based metrics such as pass@k or functional correctness.
major comments (1)
- [Evaluation / Experimental Results] The central claim that influence-score filtering enhances programming performance rests on the untested assumption that loss on transformed validation sets is a reliable proxy for true data influence on code-generation capabilities. Because downstream tasks are ultimately judged by execution metrics rather than token-level loss, the manuscript must demonstrate (via correlation analysis or ablation) that examples reducing validation loss also improve functional correctness; otherwise the filtering benefit could be an artifact of the next-token transformation discarding multi-step or execution semantics.
minor comments (2)
- [Abstract] Abstract: key quantitative results (e.g., absolute or relative gains on specific benchmarks, number of tasks evaluated, statistical significance) are omitted, making it impossible to gauge effect sizes from the summary alone.
- [Method] The description of how downstream tasks are transformed into validation sets (e.g., prompt formatting, tokenization details) should be expanded with concrete examples to allow replication of the influence-score computation.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and detailed review. The feedback highlights an important aspect of validating our influence-based filtering approach. We address the major comment point-by-point below and outline the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Evaluation / Experimental Results] The central claim that influence-score filtering enhances programming performance rests on the untested assumption that loss on transformed validation sets is a reliable proxy for true data influence on code-generation capabilities. Because downstream tasks are ultimately judged by execution metrics rather than token-level loss, the manuscript must demonstrate (via correlation analysis or ablation) that examples reducing validation loss also improve functional correctness; otherwise the filtering benefit could be an artifact of the next-token transformation discarding multi-step or execution semantics.
Authors: We agree that directly linking the observed loss reductions to gains on execution-based metrics such as pass@k would provide stronger evidence for the practical impact of the filtering method. Our study follows established practices in influence estimation by using next-token prediction loss on transformed validation sets, which is a natural fit for the generative code tasks considered. Nevertheless, we acknowledge that this leaves open the possibility that benefits are partly tied to the proxy rather than functional correctness. In the revised manuscript, we will add a dedicated analysis section that evaluates the final 1B models (both filtered and unfiltered) on standard execution-based benchmarks (e.g., HumanEval-style tasks) using pass@k and functional correctness metrics. We will also report correlation coefficients between the per-example loss reductions achieved by filtering and the corresponding improvements in these execution metrics, thereby addressing the concern that the next-token transformation may discard relevant semantics. revision: yes
Circularity Check
No circularity: purely empirical comparison of filtered vs. unfiltered pretraining data
full rationale
The paper performs an empirical study: it pre-trains a 1B-parameter Code-LLM from scratch on 100B tokens, computes influence scores as validation loss after transforming downstream coding tasks into next-token prediction format, applies filtering, and retrains/evaluates the resulting models on external benchmarks. All claims rest on direct performance comparisons (not on any derivation that reduces to the influence metric by construction). No equations, self-definitional loops, fitted-input-as-prediction, or load-bearing self-citations appear in the described chain. The study is self-contained against external validation sets and task metrics.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Loss on downstream-task validation sets is a valid proxy for measuring the influence of individual pretraining examples on final model performance.
Reference graph
Works this paper leans on
-
[1]
[n. d.]. An Empirical Study on Data Influence-Based Pretraining Data Selection for Code Large Language Models. https://github.com/ZZR0/DIScore. Accessed: 2025-10-23
2025
-
[2]
2023. ChatGPT. Website. https://openai.com/blog/chatgpt
2023
- [3]
- [4]
-
[5]
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, et al. 2021. Program Synthesis with Large Language Models.arXiv preprint arXiv:2108.07732(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[6]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Pondé de Oliveira Pinto, Jared Kaplan, Harrison Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavar...
work page internal anchor Pith review Pith/arXiv arXiv 2021
- [7]
-
[8]
Sarah Fakhoury, Saikat Chakraborty, Madan Musuvathi, and Shuvendu K. Lahiri
-
[9]
Towards Generating Functionally Correct Code Edits from Natural Language Issue Descriptions.CoRRabs/2304.03816 (2023). arXiv:2304.03816 doi:10.48550/ARXIV.2304.03816 ICPC ’26, April 12–13, 2026, Rio de Janeiro, Brazil Chengli Xing, Zhengran Zeng, Gexiang Fang, Rui Xie, Wei Ye, and Shikun Zhang
-
[10]
Angela Fan, Beliz Gokkaya, Mark Harman, Mitya Lyubarskiy, Shubho Sengupta, Shin Yoo, and Jie M. Zhang. 2023. Large Language Models for Software Engi- neering: Survey and Open Problems. InIEEE/ACM International Conference on Software Engineering: Future of Software Engineering, ICSE-FoSE 2023, Melbourne, Australia, May 14-20, 2023. IEEE, 31–53. doi:10.1109...
-
[11]
Vitaly Feldman and Chiyuan Zhang. 2020. What neural networks memorize and why: Discovering the long tail via influence estimation.Advances in Neural Information Processing Systems33 (2020), 2881–2891
2020
-
[12]
Shuzheng Gao, Cuiyun Gao, Yulan He, Jichuan Zeng, Lunyiu Nie, Xin Xia, and Michael Lyu. 2023. Code structure–guided transformer for source code summa- rization.ACM Transactions on Software Engineering and Methodology32, 1 (2023), 1–32
2023
-
[13]
Suriya Gunasekar, Yi Zhang, Jyoti Aneja, Caio César Teodoro Mendes, Allie Del Giorno, Sivakanth Gopi, Mojan Javaheripi, Piero Kauffmann, Gustavo de Rosa, Olli Saarikivi, et al . 2023. Textbooks are all you need.arXiv preprint arXiv:2306.11644(2023)
work page internal anchor Pith review arXiv 2023
-
[14]
Daya Guo, Qihao Zhu, Dejian Yang, Zhenda Xie, Kai Dong, Wentao Zhang, Guanting Chen, Xiao Bi, Yu Wu, YK Li, et al. 2024. DeepSeek-Coder: When the Large Language Model Meets Programming–The Rise of Code Intelligence.arXiv preprint arXiv:2401.14196(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Shengding Hu, Yuge Tu, Xu Han, Chaoqun He, Ganqu Cui, Xiang Long, Zhi Zheng, Yewei Fang, Yuxiang Huang, Weilin Zhao, et al. 2024. Minicpm: Unveiling the potential of small language models with scalable training strategies.arXiv preprint arXiv:2404.06395(2024)
work page internal anchor Pith review arXiv 2024
-
[16]
Binyuan Hui, Jian Yang, Zeyu Cui, Jiaxi Yang, Dayiheng Liu, Lei Zhang, Tianyu Liu, Jiajun Zhang, Bowen Yu, Kai Dang, et al. 2024. Qwen2. 5-coder technical report.arXiv preprint arXiv:2409.12186(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [17]
-
[18]
Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R. Narasimhan. 2024. SWE-bench: Can Language Models Resolve Real-world Github Issues?. InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net. https://openreview.net/forum?id=VTF8yNQM66
2024
-
[19]
Pang Wei Koh and Percy Liang. 2017. Understanding black-box predictions via influence functions. InInternational conference on machine learning. PMLR, 1885–1894
2017
- [20]
-
[21]
Hugo Laurençon, Lucile Saulnier, Thomas Wang, Christopher Akiki, Albert Villanova del Moral, Teven Le Scao, Leandro Von Werra, Chenghao Mou, Eduardo González Ponferrada, Huu Nguyen, et al. 2022. The bigscience roots corpus: A 1.6 tb composite multilingual dataset.Advances in Neural Information Processing Systems35 (2022), 31809–31826
2022
-
[22]
Jinyang Li, Binyuan Hui, Ge Qu, Jiaxi Yang, Binhua Li, Bowen Li, Bailin Wang, Bowen Qin, Ruiying Geng, Nan Huo, et al . 2024. Can llm already serve as a database interface? a big bench for large-scale database grounded text-to-sqls. Advances in Neural Information Processing Systems36 (2024)
2024
-
[23]
Raymond Li, Loubna Ben Allal, Yangtian Zi, Niklas Muennighoff, Denis Kocetkov, Chenghao Mou, Marc Marone, Christopher Akiki, Jia Li, Jenny Chim, Qian Liu, Evgenii Zheltonozhskii, Terry Yue Zhuo, Thomas Wang, Olivier Dehaene, Mishig Davaadorj, Joel Lamy-Poirier, João Monteiro, Oleh Shliazhko, Nicolas Gontier, Nicholas Meade, Armel Zebaze, Ming-Ho Yee, Loge...
-
[24]
StarCoder: may the source be with you!
StarCoder: may the source be with you!CoRRabs/2305.06161 (2023). arXiv:2305.06161 doi:10.48550/ARXIV.2305.06161
work page internal anchor Pith review doi:10.48550/arxiv.2305.06161 2023
- [25]
- [26]
-
[27]
Yinhan Liu. 2019. Roberta: A robustly optimized bert pretraining approach.arXiv preprint arXiv:1907.11692(2019)
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[28]
StarCoder 2 and The Stack v2: The Next Generation
Anton Lozhkov, Raymond Li, Loubna Ben Allal, Federico Cassano, Joel Lamy- Poirier, Nouamane Tazi, Ao Tang, Dmytro Pykhtar, Jiawei Liu, Yuxiang Wei, Tianyang Liu, Max Tian, Denis Kocetkov, Arthur Zucker, Younes Belkada, Zi- jian Wang, Qian Liu, Dmitry Abulkhanov, Indraneil Paul, Zhuang Li, Wen-Ding Li, Megan Risdal, Jia Li, Jian Zhu, Terry Yue Zhuo, Evgeni...
work page internal anchor Pith review doi:10.48550/arxiv.2402.19173 2024
-
[29]
Andreas Madsen, Siva Reddy, and Sarath Chandar. 2022. Post-hoc interpretability for neural nlp: A survey.Comput. Surveys55, 8 (2022), 1–42
2022
-
[30]
Garima Pruthi, Frederick Liu, Satyen Kale, and Mukund Sundararajan. 2020. Estimating training data influence by tracing gradient descent.Advances in Neural Information Processing Systems33 (2020), 19920–19930
2020
-
[31]
Chen Qian, Xin Cong, Cheng Yang, Weize Chen, Yusheng Su, Juyuan Xu, Zhiyuan Liu, and Maosong Sun. 2023. Communicative agents for software development. arXiv preprint arXiv:2307.07924(2023)
work page internal anchor Pith review arXiv 2023
-
[32]
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. 2020. Exploring the limits of transfer learning with a unified text-to-text transformer.Journal of machine learning research21, 140 (2020), 1–67
2020
-
[33]
Baptiste Rozière, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xi- aoqing Ellen Tan, Yossi Adi, Jingyu Liu, Tal Remez, Jérémy Rapin, Artyom Kozhevnikov, Ivan Evtimov, Joanna Bitton, Manish Bhatt, Cristian Canton-Ferrer, Aaron Grattafiori, Wenhan Xiong, Alexandre Défossez, Jade Copet, Faisal Azhar, Hugo Touvron, Louis Martin, Nicolas Usunier, Tho...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2308.12950 2023
-
[34]
Noveen Sachdeva, Benjamin Coleman, Wang-Cheng Kang, Jianmo Ni, Lichan Hong, Ed H Chi, James Caverlee, Julian McAuley, and Derek Zhiyuan Cheng
- [35]
- [36]
-
[37]
Gomez, Lukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. 2017. Attention is All you Need. InAdvances in Neural Information Processing Systems 30: An- nual Conference on Neural Information Processing Systems 2017, December 4- 9, 2017, Long Beach, CA, USA, Isabelle Guyon, Ulrike von Luxbur...
2017
- [38]
-
[39]
Chunqiu Steven Xia, Yinlin Deng, Soren Dunn, and Lingming Zhang. 2024. Agentless: Demystifying llm-based software engineering agents.arXiv preprint arXiv:2407.01489(2024)
work page internal anchor Pith review arXiv 2024
- [40]
-
[41]
Jiasheng Ye, Peiju Liu, Tianxiang Sun, Jun Zhan, Yunhua Zhou, and Xipeng Qiu
-
[42]
InThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025
Data Mixing Laws: Optimizing Data Mixtures by Predicting Language Modeling Performance. InThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenReview.net. https: //openreview.net/forum?id=jjCB27TMK3
2025
-
[43]
Hao Yu, Bo Shen, Dezhi Ran, Jiaxin Zhang, Qi Zhang, Yuchi Ma, Guangtai Liang, Ying Li, Tao Xie, and Qianxiang Wang. 2023. CoderEval: A Benchmark of Prag- matic Code Generation with Generative Pre-trained Models.CoRRabs/2302.00288 (2023). arXiv:2302.00288 doi:10.48550/ARXIV.2302.00288
- [44]
-
[45]
Jerrold H Zar. 2014. Spearman rank correlation: overview.Wiley StatsRef: Statistics Reference Online(2014)
2014
-
[46]
Zhengran Zeng, Yidong Wang, Rui Xie, Wei Ye, and Shikun Zhang. 2024. CoderUJB: An Executable and Unified Java Benchmark for Practical Program- ming Scenarios. InProceedings of the 33rd ACM SIGSOFT International Sym- posium on Software Testing and Analysis, ISSTA 2024, Vienna, Austria, Septem- ber 16-20, 2024, Maria Christakis and Michael Pradel (Eds.). AC...
-
[47]
Fengji Zhang, Bei Chen, Yue Zhang, Jin Liu, Daoguang Zan, Yi Mao, Jian-Guang Lou, and Weizhu Chen. 2023. Repocoder: Repository-level code completion through iterative retrieval and generation.arXiv preprint arXiv:2303.12570(2023). An Empirical Study on Influence-Based Pretraining Data Selection for Code Large Language Models ICPC ’26, April 12–13, 2026, R...
-
[48]
Peiyuan Zhang, Guangtao Zeng, Tianduo Wang, and Wei Lu. 2024. Tinyllama: An open-source small language model.arXiv preprint arXiv:2401.02385(2024)
work page internal anchor Pith review arXiv 2024
-
[49]
Ziyin Zhang, Chaoyu Chen, Bingchang Liu, Cong Liao, Zi Gong, Hang Yu, Jian- guo Li, and Rui Wang. 2023. A Survey on Language Models for Code.CoRR abs/2311.07989 (2023). arXiv:2311.07989 doi:10.48550/ARXIV.2311.07989
-
[50]
Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang, Junjie Zhang, Zican Dong, et al. 2023. A survey of large language models.arXiv preprint arXiv:2303.18223(2023)
work page internal anchor Pith review arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.