Recognition: no theorem link
Open-Ended Video Game Glitch Detection with Agentic Reasoning and Temporal Grounding
Pith reviewed 2026-05-10 18:19 UTC · model grok-4.3
The pith
GliDe's agentic components enable multimodal models to detect, describe, and temporally localize glitches in open-ended gameplay videos more effectively than vanilla baselines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Open-ended video game glitch detection requires reasoning about game-specific dynamics such as mechanics, physics, rendering, animation, and expected state transitions directly over continuous gameplay videos and distinguishing true glitches from unusual but valid in-game events. VideoGlitchBench supplies 5238 gameplay videos from 120 games, each annotated with detailed glitch descriptions and precise temporal spans. GliDe is an agentic framework whose game-aware contextual memory supports informed reasoning, debate-based reflector enables multi-perspective detection and verification, and event-level grounding module recovers complete glitch intervals from fragmented evidence. On the joint-1
What carries the argument
GliDe, the agentic framework built from a game-aware contextual memory for informed reasoning, a debate-based reflector for multi-perspective glitch detection and verification, and an event-level grounding module that recovers complete glitch intervals from fragmented temporal evidence.
Load-bearing premise
The annotations in VideoGlitchBench accurately distinguish true glitches from valid but unusual in-game events, and the three proposed GliDe components can be implemented to deliver the claimed gains without further unspecified details.
What would settle it
Re-running the evaluation protocol on VideoGlitchBench and finding no statistically significant improvement in GliDe's joint semantic-fidelity and temporal-accuracy scores relative to the corresponding vanilla multimodal baselines.
Figures










read the original abstract
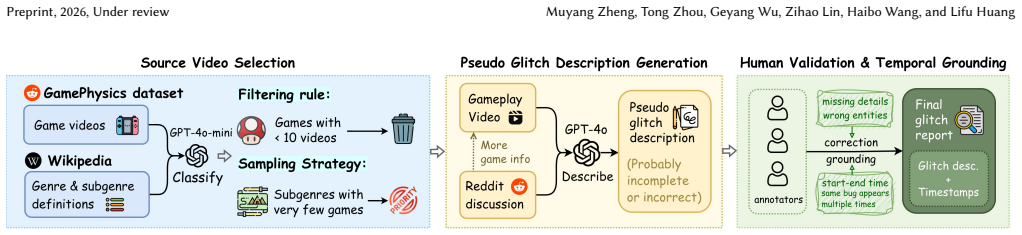
Open-ended video game glitch detection aims to identify glitches in gameplay videos, describe them in natural language, and localize when they occur. Unlike conventional game glitch understanding tasks which have largely been framed as image-level recognition or closed-form question answering, this task requires reasoning about game-specific dynamics such as mechanics, physics, rendering, animation, and expected state transitions directly over continuous gameplay videos and distinguishing true glitches from unusual but valid in-game events. To support this task, we introduce VideoGlitchBench, the first benchmark for open-ended video game glitch detection with temporal localization. VideoGlitchBench contains 5,238 gameplay videos from 120 games, each annotated with detailed glitch descriptions and precise temporal spans, enabling unified evaluation of semantic understanding and temporal grounding. We further propose GliDe, an agentic framework with three key components: a game-aware contextual memory for informed reasoning, a debate-based reflector for multi-perspective glitch detection and verification, and an event-level grounding module that recovers complete glitch intervals from fragmented temporal evidence. We also design a task-specific evaluation protocol that jointly measures semantic fidelity and temporal accuracy. Experiments show that this task remains highly challenging for current multimodal models, while GliDe achieves substantially stronger performance than corresponding vanilla model baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces VideoGlitchBench, the first benchmark for open-ended video game glitch detection, comprising 5,238 gameplay videos from 120 games each annotated with detailed natural-language glitch descriptions and precise temporal spans. It proposes GliDe, an agentic framework consisting of a game-aware contextual memory, a debate-based reflector for multi-perspective verification, and an event-level grounding module to recover complete glitch intervals. The work also defines a joint evaluation protocol for semantic fidelity and temporal accuracy. Experiments indicate that the task is highly challenging for current multimodal models, while GliDe substantially outperforms corresponding vanilla baselines.
Significance. If the benchmark labels prove reliable and the reported gains hold under detailed scrutiny, the work would meaningfully advance multimodal video reasoning, temporal localization, and agentic systems for anomaly detection in complex dynamic domains. The creation of VideoGlitchBench and the explicit agentic decomposition in GliDe are constructive steps that could seed follow-on research in game AI and open-ended video understanding.
major comments (3)
- [VideoGlitchBench] VideoGlitchBench section: no inter-annotator agreement statistics (e.g., Cohen’s kappa) or explicit annotation guidelines are provided for distinguishing true glitches (mechanics/physics/rendering failures) from valid but atypical gameplay events. This directly affects the interpretability of both the difficulty claim and GliDe’s performance gains.
- [Experiments] Experiments section: the manuscript supplies no quantitative metrics, baseline specifications, ablation results, or error analysis to support the claim that GliDe achieves substantially stronger performance than vanilla models. Without these, the central empirical assertion cannot be evaluated.
- [GliDe] GliDe framework description: the three components (game-aware contextual memory, debate-based reflector, event-level grounding module) are introduced at a conceptual level with no implementation details, pseudocode, or ablation studies demonstrating their individual contributions to the reported improvements.
minor comments (2)
- [Evaluation Protocol] The evaluation protocol is described only at a high level; concrete formulas or pseudocode for the joint semantic-temporal score would improve reproducibility.
- [Tables/Figures] Table or figure captions for benchmark statistics and model comparisons should explicitly list the number of games, video lengths, and exact baseline models used.
Simulated Author's Rebuttal
Thank you for the opportunity to respond to the referee's report. We value the constructive criticism and will revise the manuscript to address the concerns raised regarding the benchmark reliability, experimental details, and framework implementation. Below we provide detailed responses to each major comment.
read point-by-point responses
-
Referee: [VideoGlitchBench] VideoGlitchBench section: no inter-annotator agreement statistics (e.g., Cohen’s kappa) or explicit annotation guidelines are provided for distinguishing true glitches (mechanics/physics/rendering failures) from valid but atypical gameplay events. This directly affects the interpretability of both the difficulty claim and GliDe’s performance gains.
Authors: We acknowledge this limitation in the current manuscript. We will add the explicit annotation guidelines used to distinguish glitches from atypical events and report inter-annotator agreement statistics such as Cohen's kappa to enhance the reliability and interpretability of VideoGlitchBench. revision: yes
-
Referee: [Experiments] Experiments section: the manuscript supplies no quantitative metrics, baseline specifications, ablation results, or error analysis to support the claim that GliDe achieves substantially stronger performance than vanilla models. Without these, the central empirical assertion cannot be evaluated.
Authors: We agree that more detailed empirical support is necessary. The revised manuscript will include quantitative metrics for semantic fidelity and temporal accuracy, specifications of all baselines, ablation studies, and error analysis to allow proper evaluation of GliDe's improvements. revision: yes
-
Referee: [GliDe] GliDe framework description: the three components (game-aware contextual memory, debate-based reflector, event-level grounding module) are introduced at a conceptual level with no implementation details, pseudocode, or ablation studies demonstrating their individual contributions to the reported improvements.
Authors: We concur that additional details are required. We will provide implementation details, pseudocode for the key modules, and ablation studies demonstrating the contribution of each component (game-aware contextual memory, debate-based reflector, and event-level grounding module) in the revised version. revision: yes
Circularity Check
No circularity detected in derivation or claims
full rationale
The paper introduces a new benchmark (VideoGlitchBench) and a new agentic framework (GliDe) for open-ended glitch detection, then reports empirical comparisons against vanilla baselines on semantic and temporal metrics. No equations, fitted parameters, or self-referential definitions appear in the abstract or described structure; the central claims rest on newly collected data and direct experimental evaluation rather than any reduction of outputs to inputs by construction, self-citation chains, or renamed prior results. This is the expected non-circular outcome for an empirical benchmark paper.
Axiom & Free-Parameter Ledger
invented entities (3)
-
game-aware contextual memory
no independent evidence
-
debate-based reflector
no independent evidence
-
event-level grounding module
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Anthropic. 2024. Model Card Addendum: Claude 3.5 Haiku and Upgraded Claude 3.5 Sonnet. https://assets.anthropic.com/m/1cd9d098ac3e6467/original/Claude-3- Model-Card-October-Addendum.pdf
2024
-
[2]
Sinan Ariyurek, Aysu Betin-Can, and Elif Surer. 2019. Automated video game testing using synthetic and humanlike agents.IEEE Transactions on Games13, 1 (2019), 50–67
2019
-
[3]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. 2025. Qwen2.5-VL Technical Rep...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Joakim Bergdahl, Camilo Gordillo, Konrad Tollmar, and Linus Gisslén. 2020. Augmenting automated game testing with deep reinforcement learning. In2020 IEEE Conference on Games (CoG). IEEE, 600–603
2020
-
[5]
Bryce Boe. 2023. PRAW: The Python Reddit API Wrapper Documentation. https: //praw.readthedocs.io/
2023
- [6]
- [7]
-
[8]
Nicolas Carion, Laura Gustafson, Yuan-Ting Hu, Shoubhik Debnath, Ronghang Hu, Didac Suris, Chaitanya Ryali, Kalyan Vasudev Alwala, Haitham Khedr, An- drew Huang, et al. 2025. Sam 3: Segment anything with concepts.arXiv preprint arXiv:2511.16719(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Zhe Chen, Weiyun Wang, Yue Cao, Yangzhou Liu, Zhangwei Gao, Erfei Cui, Jinguo Zhu, Shenglong Ye, Hao Tian, Zhaoyang Liu, et al . 2024. Expanding Performance Boundaries of Open-Source Multimodal Models with Model, Data, and Test-Time Scaling.arXiv preprint arXiv:2412.05271(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
Dong Gong, Lingqiao Liu, Vuong Le, Budhaditya Saha, Moussa Reda Mansour, Svetha Venkatesh, and Anton van den Hengel. 2019. Memorizing normality to detect anomaly: Memory-augmented deep autoencoder for unsupervised anomaly detection. InProceedings of the IEEE/CVF international conference on computer vision. 1705–1714
2019
-
[11]
Google. 2024. Introducing Gemini 2.0: our new AI model for the agen- tic era. https://blog.google/innovation-and-ai/models-and-research/google- deepmind/google-gemini-ai-update-december-2024/
2024
-
[12]
Mahmudul Hasan, Jonghyun Choi, Jan Neumann, Amit K Roy-Chowdhury, and Larry S Davis. 2016. Learning temporal regularity in video sequences. InProceed- ings of the IEEE conference on computer vision and pattern recognition. 733–742
2016
- [13]
-
[14]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. 2024. Gpt-4o system card.arXiv preprint arXiv:2410.21276(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Amazon Artificial General Intelligence. 2024. The Amazon Nova Family of Models: Technical Report and Model Card. https://www.amazon.science/publications/the- amazon-nova-family-of-models-technical-report-and-model-card
2024
-
[16]
Harold W Kuhn. 1955. The Hungarian method for the assignment problem.Naval research logistics quarterly2, 1-2 (1955), 83–97
1955
-
[17]
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Yanwei Li, Ziwei Liu, and Chunyuan Li. 2024. LLaVA-OneVision: Easy Visual Task Transfer.arXiv preprint arXiv:2408.03326(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
Dayi Lin, Cor-Paul Bezemer, and Ahmed E Hassan. 2019. Identifying gameplay videos that exhibit bugs in computer games.Empirical Software Engineering24, 6 (2019), 4006–4033
2019
-
[19]
Guoqing Liu, Mengzhang Cai, Li Zhao, Tao Qin, Adrian Brown, Jimmy Bischoff, and Tie-Yan Liu. 2022. Inspector: Pixel-based automated game testing via ex- ploration, detection, and investigation. In2022 IEEE Conference on Games (CoG). IEEE, 237–244
2022
-
[20]
Wen Liu, Weixin Luo, Dongze Lian, and Shenghua Gao. 2018. Future frame prediction for anomaly detection–a new baseline. InProceedings of the IEEE conference on computer vision and pattern recognition. 6536–6545
2018
-
[21]
Ye Liu, Kevin Qinghong Lin, Chang Wen Chen, and Mike Zheng Shou. [n. d.]. VideoMind: A Chain-of-LoRA Agent for Temporal-Grounded Video Reasoning. InNeurIPS 2025 Workshop on Bridging Language, Agent, and World Models for Reasoning and Planning
2025
-
[22]
Weixin Luo, Wen Liu, and Shenghua Gao. 2017. A revisit of sparse coding based anomaly detection in stacked rnn framework. InProceedings of the IEEE international conference on computer vision. 341–349
2017
-
[23]
Iqra Qasim, Alexander Horsch, and Dilip Prasad. 2025. Dense video captioning: A survey of techniques, datasets and evaluation protocols.Comput. Surveys57, 6 (2025), 1–36
2025
-
[24]
Bharathkumar Ramachandra, Michael J Jones, and Ranga Raju Vatsavai. 2020. A survey of single-scene video anomaly detection.IEEE transactions on pattern analysis and machine intelligence44, 5 (2020), 2293–2312
2020
-
[25]
2008.Intro- duction to information retrieval
Hinrich Schütze, Christopher D Manning, and Prabhakar Raghavan. 2008.Intro- duction to information retrieval. Vol. 39. Cambridge University Press Cambridge
2008
-
[26]
ByteDance Seed. 2025. UI-TARS-1.5. https://seed-tars.com/1.5
2025
-
[27]
Alessandro Sestini, Linus Gisslén, Joakim Bergdahl, Konrad Tollmar, and An- drew David Bagdanov. 2022. Automated gameplay testing and validation with curiosity-conditioned proximal trajectories.IEEE Transactions on Games16, 1 (2022), 113–126
2022
-
[28]
Chuyi Shang, Amos You, Sanjay Subramanian, Trevor Darrell, and Roei Herzig
-
[29]
InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing
TraveLER: A Modular Multi-LMM Agent Framework for Video Question- Answering. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 9740–9766
2024
-
[31]
Waqas Sultani, Chen Chen, and Mubarak Shah. 2018. Real-world anomaly de- tection in surveillance videos. InProceedings of the IEEE conference on computer vision and pattern recognition. 6479–6488
2018
-
[32]
Mohammad Reza Taesiri and Cor-Paul Bezemer. 2025. Videogamebunny: To- wards vision assistants for video games. In2025 IEEE/CVF Winter Conference on Applications of Computer Vision (W ACV). IEEE, 1403–1413
2025
-
[33]
Mohammad Reza Taesiri, Tianjun Feng, Cor-Paul Bezemer, and Anh Nguyen
-
[34]
In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
GlitchBench: Can large multimodal models detect video game glitches?. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 22444–22455
-
[35]
Mohammad Reza Taesiri, Abhijay Ghildyal, Saman Zadtootaghaj, Nabajeet Bar- man, and Cor-Paul Bezemer. [n. d.]. VideoGameQA-Bench: Evaluating Vision- Language Models for Video Game Quality Assurance. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track
-
[36]
Mohammad Reza Taesiri, Finlay Macklon, and Cor-Paul Bezemer. 2022. Clip meets gamephysics: Towards bug identification in gameplay videos using zero- shot transfer learning. InProceedings of the 19th International Conference on Mining Software Repositories. 270–281
2022
- [37]
-
[38]
Yunlong Tang, Jing Bi, Siting Xu, Luchuan Song, Susan Liang, Teng Wang, Daoan Zhang, Jie An, Jingyang Lin, Rongyi Zhu, et al. 2025. Video understanding with large language models: A survey.IEEE Transactions on Circuits and Systems for Video Technology(2025)
2025
-
[39]
Xiaohan Wang, Yuhui Zhang, Orr Zohar, and Serena Yeung-Levy. 2024. Videoa- gent: Long-form video understanding with large language model as agent. In European Conference on Computer Vision. Springer, 58–76. Preprint, 2026, Under review Muyang Zheng, Tong Zhou, Geyang Wu, Zihao Lin, Haibo Wang, and Lifu Huang
2024
- [40]
-
[41]
Peng Wu, Jing Liu, Yujia Shi, Yujia Sun, Fangtao Shao, Zhaoyang Wu, and Zhiwei Yang. 2020. Not only look, but also listen: Learning multimodal violence detection under weak supervision. InEuropean conference on computer vision. Springer, 322–339
2020
-
[42]
Chenting Xu, Ke Xu, Xinghao Jiang, and Tanfeng Sun. 2025. Plovad: Prompting vision-language models for open vocabulary video anomaly detection.IEEE Transactions on Circuits and Systems for Video Technology35, 6 (2025), 5925–5938
2025
- [43]
-
[44]
Yuchen Yang, Kwonjoon Lee, Behzad Dariush, Yinzhi Cao, and Shao-Yuan Lo
-
[45]
InEuropean Conference on Computer Vision
Follow the rules: reasoning for video anomaly detection with large language models. InEuropean Conference on Computer Vision. Springer, 304–322
- [46]
-
[47]
Luca Zanella, Willi Menapace, Massimiliano Mancini, Yiming Wang, and Elisa Ricci. 2024. Harnessing large language models for training-free video anomaly detection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 18527–18536
2024
-
[48]
Huaxin Zhang, Xiaohao Xu, Xiang Wang, Jialong Zuo, Chuchu Han, Xiaonan Huang, Changxin Gao, Yuehuan Wang, and Nong Sang. 2024. Holmes-vad: Towards unbiased and explainable video anomaly detection via multi-modal llm. arXiv preprint arXiv:2406.12235(2024). A Details onVideoGlitchBench A.1 Statistics To support a diverse and balanced benchmark, we organize ...
-
[49]
Game-aware context: Action-adventure game with snowy mountain terrain
Rough Detection [W0] GLITCH (Visual, 0.75) – airborne anomaly [W1] GLITCH (Physics, 0.78) – clipping through barrier [W2] GLITCH (Physics, 0.75) – abnormal motion [W3] GLITCH (Physics, 0.75) – unrealistic interaction [W4] GLITCH (Physics, 0.75) – falling through terrain [W5-7] No glitch → 5 candidate glitch windows detected, covering both po- tential clip...
-
[50]
Describe ground interaction
Fine-grained Verification Window 0 Iteration 1: -Planner→VQA: "Describe ground interaction" - Answer: Character appears sliding/falling with continuous ground contact Advocate: glitch (possible hovering / missing collision) Skeptic: normal (intentional sliding or terrain interaction) Judge:NORMAL(confidence = 0.65, below threshold) Iteration 2: Preprint, ...
2026
-
[51]
Temporal Localization Initial clustering based on semantic similarity: - Cluster 1: [W1, W2] (clipping-related) - Cluster 2: [W3, W4] (teleportation-related) Bidirectional propagation with visual consistency check: - Cluster 1→[W1, W2, W4, W5, W6] - Cluster 2→[W2, W3, W4, W5, W6, W7] → Expands temporal coverage to capture long-range and recurring glitches
-
[52]
Timestamps: [2–5], [8– 13] Bug 2 (Teleportation): Character launches and disappears without physical cause
Final Glitch Report Generation Bug 1 (Clipping): Character phases through a wooden bar- rier, violating collision constraints. Timestamps: [2–5], [8– 13] Bug 2 (Teleportation): Character launches and disappears without physical cause. Timestamps: [4–15]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.