Recognition: 2 theorem links
· Lean TheoremOn the Decompositionality of Neural Networks
Pith reviewed 2026-05-10 17:51 UTC · model grok-4.3
The pith
Neural networks can be decomposed while preserving semantic behavior along their decision boundaries.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
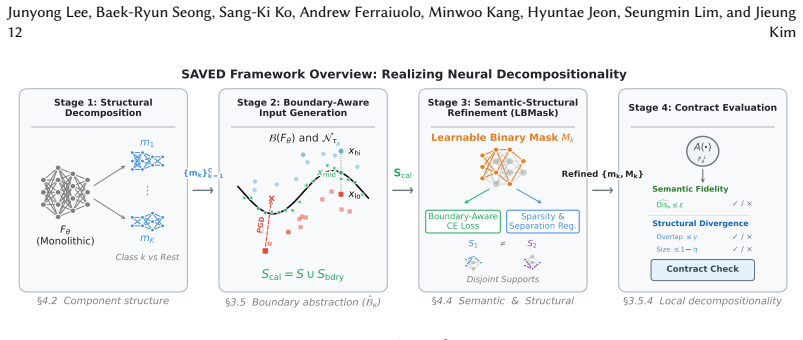
Neural decompositionality is a formal notion defined as a semantic-preserving abstraction over neural architectures. The key insight is that decompositionality should be characterized by the preservation of semantic behavior along the model's decision boundary, which governs classification outcomes. This yields a semantic contract between the original model and its components. Building on this, the SAVED framework combines counterexample mining over low logic-margin inputs, probabilistic coverage, and structure-aware pruning. Evaluations on CNNs, language Transformers, and Vision Transformers show language Transformers largely preserve boundary semantics under decomposition, whereas vision模型
What carries the argument
The decision boundary of the network, which defines the semantic contract that any valid decomposition must satisfy to preserve classification behavior.
Load-bearing premise
That preserving semantic behavior only along the decision boundary is the correct and sufficient way to determine when a neural network can be meaningfully decomposed.
What would settle it
A SAVED-generated decomposition that matches the original model on low-margin boundary inputs but produces different outputs on high-confidence inputs away from the boundary.
Figures


read the original abstract
Recent advances in deep neural networks have achieved state-of-the-art performance across vision and natural language processing tasks. In practice, however, most models are treated as monolithic black-box functions, limiting maintainability, component-wise optimization, and systematic testing and verification. Despite extensive work on pruning and empirical decomposition, the field still lacks a principled semantic notion of when a neural network can be meaningfully decomposed. We introduce neural decompositionality, a formal notion defined as a semantic-preserving abstraction over neural architectures. Our key insight is that decompositionality should be characterized by the preservation of semantic behavior along the model's decision boundary, which governs classification outcomes. This yields a semantic contract between the original model and its components, enabling a rigorous formulation of decomposition. Building on this foundation, we develop a boundary-aware framework, SAVED (Semantic-Aware Verification-Driven Decomposition), which operationalizes the proposed definition. SAVED combines counterexample mining over low logic-margin inputs, probabilistic coverage, and structure-aware pruning to construct decompositions that preserve decision-boundary semantics. We evaluate our approach on CNNs, language Transformers, and Vision Transformers. Results show clear architectural differences: language Transformers largely preserve boundary semantics under decomposition, whereas vision models frequently violate the decompositionality criterion, indicating intrinsic limits. Overall, our work establishes decompositionality as a formally definable and empirically testable property, providing a foundation for modular reasoning about neural networks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces 'neural decompositionality' as a formal semantic-preserving abstraction for neural networks, characterized specifically by preservation of semantic behavior along the model's decision boundary. It presents the SAVED framework (combining counterexample mining over low logic-margin inputs, probabilistic coverage, and structure-aware pruning) to construct decompositions satisfying this contract. Evaluation on CNNs, language Transformers, and Vision Transformers reports that language Transformers largely preserve boundary semantics under decomposition while vision models frequently violate the criterion, which the authors interpret as indicating intrinsic limits to decompositionality in vision architectures.
Significance. If the central definition and empirical split are robust, the work supplies a testable, formally stated property that could support modular reasoning, verification, and component-wise optimization of neural networks. The reported architectural contrast between language Transformers and vision models is a concrete, falsifiable observation that merits further study. However, the significance is tempered by the absence of an independent argument linking boundary preservation to the practical benefits (maintainability, systematic testing) invoked in the motivation.
major comments (3)
- [Abstract and §2] Abstract and §2 (definition of neural decompositionality): the central claim that boundary-semantic preservation constitutes a 'semantic contract' enabling 'meaningful' decomposition is introduced by fiat rather than derived from an independent semantic or practical contract; no argument shows that satisfying this boundary condition is necessary or sufficient for the stated benefits of maintainability and component-wise optimization, nor rules out alternative decompositions that preserve end-to-end behavior.
- [Evaluation section] Evaluation section (results on architectural differences): the reported split (language Transformers preserve, vision models violate) rests on the chosen definition; without an ablation or alternative decomposition criterion, it is unclear whether the violations reflect intrinsic limits or merely the particular boundary-preservation contract, undermining the conclusion that vision models have 'intrinsic limits'.
- [SAVED framework] SAVED framework description: the combination of counterexample mining, probabilistic coverage, and structure-aware pruning is presented as operationalizing the definition, but no formal semantics, soundness proof, or quantitative metrics (e.g., coverage guarantees, violation rates per architecture) are supplied to show that the constructed decompositions actually meet the boundary-preservation criterion.
minor comments (2)
- [SAVED framework] Notation for 'low logic-margin inputs' and 'probabilistic coverage' is introduced without explicit definitions or references to prior work on margin-based verification.
- [Abstract] The abstract claims 'clear architectural differences' but supplies no numerical results, tables, or statistical tests; these should be added for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract and §2] Abstract and §2 (definition of neural decompositionality): the central claim that boundary-semantic preservation constitutes a 'semantic contract' enabling 'meaningful' decomposition is introduced by fiat rather than derived from an independent semantic or practical contract; no argument shows that satisfying this boundary condition is necessary or sufficient for the stated benefits of maintainability and component-wise optimization, nor rules out alternative decompositions that preserve end-to-end behavior.
Authors: The definition is motivated by the observation that classification outcomes are governed by decision-boundary behavior, which directly supports modular analysis and verification without requiring full end-to-end re-evaluation. In the revised manuscript we will expand §2 with an explicit derivation linking boundary preservation to the practical benefits: it ensures that decomposed components can be analyzed or optimized independently while guaranteeing identical classification decisions on the original inputs. We will also clarify that this contract is not claimed to be the only possible one, but that it is sufficient for the maintainability and testing goals outlined in the introduction. revision: yes
-
Referee: [Evaluation section] Evaluation section (results on architectural differences): the reported split (language Transformers preserve, vision models violate) rests on the chosen definition; without an ablation or alternative decomposition criterion, it is unclear whether the violations reflect intrinsic limits or merely the particular boundary-preservation contract, undermining the conclusion that vision models have 'intrinsic limits'.
Authors: The observed split is reported specifically under the boundary-semantic-preservation criterion we propose. We interpret the higher violation rates for vision models as indicating architectural challenges in satisfying this particular semantic contract. To address the concern we will add a short discussion in the evaluation section contrasting the results with a baseline that preserves only end-to-end accuracy; this will show that the architectural distinction remains visible even under weaker criteria, thereby supporting the claim of intrinsic limits for vision models when a semantically meaningful decomposition is required. revision: partial
-
Referee: [SAVED framework] SAVED framework description: the combination of counterexample mining, probabilistic coverage, and structure-aware pruning is presented as operationalizing the definition, but no formal semantics, soundness proof, or quantitative metrics (e.g., coverage guarantees, violation rates per architecture) are supplied to show that the constructed decompositions actually meet the boundary-preservation criterion.
Authors: SAVED is presented as an engineering framework that operationalizes the definition via targeted sampling near the boundary and structure-preserving reduction. While a complete formal soundness proof lies outside the scope of the current work, the evaluation already reports empirical preservation rates. In the revision we will add (i) a concise formal semantics for the decomposition contract, (ii) a high-level argument explaining why each SAVED component contributes to boundary preservation, and (iii) explicit quantitative metrics including per-architecture violation rates and coverage statistics. revision: yes
Circularity Check
No significant circularity; new definition applied independently to evaluation.
full rationale
The paper introduces neural decompositionality as a new formal notion explicitly defined by the authors as preservation of semantic behavior along the decision boundary, then builds the SAVED framework to operationalize that definition and reports empirical outcomes on CNNs, language Transformers, and Vision Transformers. No equations or steps reduce the central claims to fitted parameters, self-citations, or prior results by construction; the architectural differences are direct consequences of testing against the introduced criterion rather than presupposed inputs. This is a standard definitional approach with independent content, warranting a non-finding.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Preservation of semantic behavior along the decision boundary is the right way to characterize when a neural network can be meaningfully decomposed.
invented entities (2)
-
neural decompositionality
no independent evidence
-
SAVED framework
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
decompositionality ... preservation of semantic behavior along the model's decision boundary ... (ε,τ,γ,η)-global decompositionality
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Boundary Preservation Theorem ... Hoeffding bound (Thm 3)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Aws Albarghouthi. 2021. Introduction to Neural Network Verification.Foundations and Trends in Programming Languages7, 1-2 (12 2021), 1–157. https://doi.org/10.1561/2500000051 arXiv:https://www.emerald.com/ftpgl/article- pdf/7/1-2/1/11044581/2500000051en.pdf
-
[2]
Estimating or Propagating Gradients Through Stochastic Neurons for Conditional Computation
Yoshua Bengio, Nicholas Léonard, and Aaron C. Courville. 2013. Estimating or Propagating Gradients Through Stochastic Neurons for Conditional Computation.CoRRabs/1308.3432 (2013). arXiv:1308.3432 http://arxiv.org/abs/ 1308.3432
work page internal anchor Pith review arXiv 2013
-
[3]
Nicholas Carlini and David A. Wagner. 2017. Towards Evaluating the Robustness of Neural Networks. In2017 IEEE Symposium on Security and Privacy, SP 2017, San Jose, CA, USA, May 22-26, 2017. IEEE Computer Society, 39–57. https://doi.org/10.1109/SP.2017.49
-
[4]
Hongrong Cheng, Miao Zhang, and Javen Qinfeng Shi. 2024. A Survey on Deep Neural Network Pruning: Taxonomy, Comparison, Analysis, and Recommendations.IEEE Transactions on Pattern Analysis and Machine Intelligence46, 12 (2024), 10558–10578. https://doi.org/10.1109/TPAMI.2024.3447085
-
[5]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019, Minneapolis, MN, USA, June 2-7, 2019, Vol...
2019
-
[6]
Chun Fan, Jiwei Li, Tianwei Zhang, Xiang Ao, Fei Wu, Yuxian Meng, and Xiaofei Sun. 2021. Layer-wise Model Pruning based on Mutual Information. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, EMNLP 2021. Association for Computational Linguistics, 3079–3090
2021
- [7]
-
[8]
Marc Fischer, Christian Sprecher, Dimitar Iliev Dimitrov, Gagandeep Singh, and Martin Vechev. 2022. Shared Certificates for Neural Network Verification. InComputer Aided Verification, Sharon Shoham and Yakir Vizel (Eds.). Springer International Publishing, Cham, 127–148
2022
-
[9]
Jonathan Frankle and Michael Carbin. 2019. The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks. In7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6-9, 2019. OpenReview.net. https://openreview.net/forum?id=rJl-b3RcF7
2019
-
[10]
2016.Deep Learning
Ian Goodfellow, Yoshua Bengio, and Aaron Courville. 2016.Deep Learning. MIT Press. http://www.deeplearningbook. org
2016
-
[11]
Explaining and Harnessing Adversarial Examples
Ian J. Goodfellow, Jonathon Shlens, and Christian Szegedy. 2015. Explaining and Harnessing Adversarial Examples. In 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7-9, 2015, Conference Track Proceedings, Yoshua Bengio and Yann LeCun (Eds.). http://arxiv.org/abs/1412.6572
work page internal anchor Pith review arXiv 2015
-
[12]
Sorin Grigorescu, Bogdan Trasnea, Tiberiu Cocias, and Gigel Macesanu. 2020. A survey of deep learning tech- niques for autonomous driving.Journal of Field Robotics37, 3 (2020), 362–386. https://doi.org/10.1002/rob.21918 arXiv:https://onlinelibrary.wiley.com/doi/pdf/10.1002/rob.21918
-
[13]
Song Han, Huizi Mao, and William J. Dally. 2016. Deep Compression: Compressing Deep Neural Network with Pruning, Trained Quantization and Huffman Coding. In4th International Conference on Learning Representations, ICLR 2016, San Juan, Puerto Rico, May 2-4, 2016, Conference Track Proceedings, Yoshua Bengio and Yann LeCun (Eds.). http://arxiv.org/abs/1510.00149
work page internal anchor Pith review arXiv 2016
-
[14]
Harleen Hanspal and Alessio Lomuscio. 2023. Efficient Verification of Neural Networks Against LVM-Based Specifica- tions. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2023, Vancouver, BC, Canada, June 17-24, 2023. IEEE, 3894–3903. https://doi.org/10.1109/CVPR52729.2023.00379
-
[15]
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016. Deep Residual Learning for Image Recognition. In 2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016. IEEE Computer Society, 770–778
2016
-
[16]
Yang He and Lingao Xiao. 2024. Structured Pruning for Deep Convolutional Neural Networks: A Survey.IEEE Trans. Pattern Anal. Mach. Intell.46, 5 (2024), 2900–2919
2024
-
[17]
Xiaowei Huang, Daniel Kroening, Wenjie Ruan, James Sharp, Youcheng Sun, Emese Thamo, Min Wu, and Xinping Yi
-
[18]
A survey of safety and trustworthiness of deep neural networks: Verification, testing, adversarial attack and defence, and interpretability.Comput. Sci. Rev.37 (2020), 100270. https://doi.org/10.1016/J.COSREV.2020.100270 On the Decompositionality of Neural Networks 25
-
[19]
Sayem Mohammad Imtiaz, Fraol Batole, Astha Singh, Rangeet Pan, Breno Dantas Cruz, and Hridesh Rajan. 2023. Decomposing a Recurrent Neural Network into Modules for Enabling Reusability and Replacement. In45th IEEE/ACM International Conference on Software Engineering, ICSE 2023, Melbourne, Australia, May 14-20, 2023. IEEE, 1020–1032
2023
-
[20]
Robert A. Jacobs, Michael I. Jordan, Steven J. Nowlan, and Geoffrey E. Hinton. 1991. Adaptive Mix- tures of Local Experts.Neural Computation3, 1 (03 1991), 79–87. https://doi.org/10.1162/neco.1991.3.1.79 arXiv:https://direct.mit.edu/neco/article-pdf/3/1/79/812104/neco.1991.3.1.79.pdf
-
[21]
Hamid Karimi and Tyler Derr. 2022. Decision Boundaries of Deep Neural Networks. In2022 21st IEEE International Conference on Machine Learning and Applications (ICMLA). 1085–1092. https://doi.org/10.1109/ICMLA55696.2022.00179
- [22]
-
[23]
Guy Katz, Derek A. Huang, Duligur Ibeling, Kyle Julian, Christopher Lazarus, Rachel Lim, Parth Shah, Shantanu Thakoor, Haoze Wu, Aleksandar Zeljic, David L. Dill, Mykel J. Kochenderfer, and Clark W. Barrett. 2019. The Marabou Framework for Verification and Analysis of Deep Neural Networks. InComputer Aided Verification - 31st International Conference, CA ...
-
[24]
Alex Krizhevsky, Geoffrey Hinton, et al. 2009. Learning multiple layers of features from tiny images. (2009)
2009
-
[25]
Yann LeCun, Yoshua Bengio, and Geoffrey Hinton. 2015. Deep learning.Nature521, 7553 (2015), 436–444. https: //doi.org/10.1038/nature14539
-
[26]
Hao Li, Asim Kadav, Igor Durdanovic, Hanan Samet, and Hans Peter Graf. 2017. Pruning Filters for Efficient ConvNets. In5th International Conference on Learning Representations, ICLR 2017. OpenReview.net
2017
-
[27]
Aleksander Madry, Aleksandar Makelov, Ludwig Schmidt, Dimitris Tsipras, and Adrian Vladu. 2018. Towards Deep Learning Models Resistant to Adversarial Attacks. In6th International Conference on Learning Representations, ICLR 2018, Vancouver, BC, Canada, April 30 - May 3, 2018, Conference Track Proceedings
2018
-
[28]
Seyed-Mohsen Moosavi-Dezfooli, Alhussein Fawzi, and Pascal Frossard. 2016. DeepFool: A Simple and Accurate Method to Fool Deep Neural Networks. In2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, Las Vegas, NV, USA, June 27-30, 2016. IEEE Computer Society, 2574–2582. https://doi.org/10.1109/CVPR.2016.282
-
[29]
Andersen, and Ian J
Augustus Odena, Catherine Olsson, David G. Andersen, and Ian J. Goodfellow. 2019. TensorFuzz: Debugging Neural Networks with Coverage-Guided Fuzzing. InProceedings of the 36th International Conference on Machine Learning, ICML 2019, 9-15 June 2019, Long Beach, California, USA (Proceedings of Machine Learning Research, Vol. 97), Kamalika Chaudhuri and Rusl...
2019
-
[30]
Daniel W Otter, Julian R Medina, and Jugal K Kalita. 2020. A survey of the usages of deep learning for natural language processing.IEEE transactions on neural networks and learning systems32, 2 (2020), 604–624
2020
-
[31]
Edouard Oyallon. 2017. Building a Regular Decision Boundary with Deep Networks. In2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, July 21-26, 2017. IEEE Computer Society, 1886–1894. https://doi.org/10.1109/CVPR.2017.204
-
[32]
Rangeet Pan and Hridesh Rajan. 2020. On decomposing a deep neural network into modules. InESEC/FSE ’20: 28th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering, Virtual Event, USA, November 8-13, 2020, Prem Devanbu, Myra B. Cohen, and Thomas Zimmermann (Eds.). ACM, 889–900. https://doi.org/10.1145/3...
-
[33]
Rangeet Pan and Hridesh Rajan. 2022. Decomposing Convolutional Neural Networks into Reusable and Replaceable Modules. In44th IEEE/ACM 44th International Conference on Software Engineering, ICSE 2022, Pittsburgh, PA, USA, May 25-27, 2022. ACM, 524–535. https://doi.org/10.1145/3510003.3510051
-
[34]
Xiaoning Ren, Yun Lin, Yinxing Xue, Ruofan Liu, Jun Sun, Zhiyong Feng, and Jin Song Dong. 2023. DeepArc: Modularizing Neural Networks for the Model Maintenance. In45th IEEE/ACM International Conference on Software Engineering, ICSE 2023. IEEE, 1008–1019
2023
-
[35]
Sara Sabour, Nicholas Frosst, and Geoffrey E. Hinton. 2017. Dynamic routing between capsules. InProceedings of the 31st International Conference on Neural Information Processing Systems(Long Beach, California, USA)(NIPS’17). Curran Associates Inc., Red Hook, NY, USA, 3859–3869
2017
-
[36]
Hadi Salman, Greg Yang, Huan Zhang, Cho-Jui Hsieh, and Pengchuan Zhang. 2019. A Convex Relaxation Barrier to Tight Robustness Verification of Neural Networks. InAdvances in Neural Information Processing Systems, H. Wallach, H. Larochelle, A. Beygelzimer, F. d'Alché-Buc, E. Fox, and R. Garnett (Eds.), Vol. 32. Curran Associates, Inc. https: //proceedings.n...
2019
-
[37]
Vikash Sehwag, Shiqi Wang, Prateek Mittal, and Suman Jana. 2020. HYDRA: Pruning Adversarially Robust Neural Networks. InAdvances in Neural Information Processing Systems, H. Larochelle, M. Ranzato, R. Hadsell, M.F. Balcan, and H. Lin (Eds.), Vol. 33. Curran Associates, Inc., 19655–19666. https://proceedings.neurips.cc/paper_files/paper/ 2020/file/e3a72c79...
2020
-
[38]
Khan, Syed Waqas Zamir, Muhammad Haris Khan, Munawar Hayat, Fahad Shahbaz Khan, and Huazhu Fu
Fahad Shamshad, Salman H. Khan, Syed Waqas Zamir, Muhammad Haris Khan, Munawar Hayat, Fahad Shahbaz Khan, and Huazhu Fu. 2023. Transformers in medical imaging: A survey.Medical Image Anal.88 (2023), 102802
2023
-
[39]
Le, Geoffrey E
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc V. Le, Geoffrey E. Hinton, and Jeff Dean. 2017. Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer. In5th International Conference on Learning Representations, ICLR 2017, Toulon, France, April 24-26, 2017, Conference Track Proceedings. OpenReview.net. https:/...
2017
-
[40]
Dongdong She, Kexin Pei, Dave Epstein, Junfeng Yang, Baishakhi Ray, and Suman Jana. 2019. NEUZZ: Efficient Fuzzing with Neural Program Smoothing. In2019 IEEE Symposium on Security and Privacy (SP). 803–817. https: //doi.org/10.1109/SP.2019.00052
-
[41]
Gagandeep Singh, Timon Gehr, Matthew Mirman, Markus Püschel, and Martin T. Vechev. 2018. Fast and Effective Robustness Certification. InAdvances in Neural Information Processing Systems 31: Annual Conference on Neural Information Processing Systems 2018, NeurIPS 2018, December 3-8, 2018, Montréal, Canada, Samy Bengio, Hanna M. Wallach, Hugo Larochelle, Kr...
2018
-
[42]
Gagandeep Singh, Timon Gehr, Markus Püschel, and Martin T. Vechev. 2019. An abstract domain for certifying neural networks.Proc. ACM Program. Lang.3, POPL (2019), 41:1–41:30
2019
-
[43]
MViTv2: Improved Multiscale Vision Transformers for Classification and Detection , isbn =
Gowthami Somepalli, Liam Fowl, Arpit Bansal, Ping-Yeh Chiang, Yehuda Dar, Richard G. Baraniuk, Micah Goldblum, and Tom Goldstein. 2022. Can Neural Nets Learn the Same Model Twice? Investigating Reproducibility and Double Descent from the Decision Boundary Perspective. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans...
-
[44]
Zico Kolter
Mingjie Sun, Zhuang Liu, Anna Bair, and J. Zico Kolter. 2024. A Simple and Effective Pruning Approach for Large Language Models. InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net. https://openreview.net/forum?id=PxoFut3dWW
2024
-
[45]
Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, and Herve Jegou. 2021. Training data-efficient image transformers & distillation through attention. InProceedings of the 38th International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 139), Marina Meila and Tong Zhang (Eds.). PMLR, ...
2021
-
[46]
Shubham Ugare, Gagandeep Singh, and Sasa Misailovic. 2022. Proof transfer for fast certification of multiple approximate neural networks.Proc. ACM Program. Lang.6, OOPSLA1, Article 75 (apr 2022), 29 pages. https: //doi.org/10.1145/3527319
-
[47]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Ł ukasz Kaiser, and Illia Polosukhin. 2017. Attention is All you Need. InAdvances in Neural Information Processing Systems, I. Guyon, U. Von Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett (Eds.), Vol. 30. Curran Associates, Inc. https://proc...
2017
-
[48]
Zico Kolter
Shiqi Wang, Huan Zhang, Kaidi Xu, Xue Lin, Suman Jana, Cho-Jui Hsieh, and J. Zico Kolter. 2021. Beta-CROWN: Efficient Bound Propagation with Per-neuron Split Constraints for Neural Network Robustness Verification. In Advances in Neural Information Processing Systems, M. Ranzato, A. Beygelzimer, Y. Dauphin, P.S. Liang, and J. Wortman Vaughan (Eds.), Vol. 3...
2021
-
[49]
In: International Conference on Computer Aided Verification
Haoze Wu, Omri Isac, Aleksandar Zeljic, Teruhiro Tagomori, Matthew L. Daggitt, Wen Kokke, Idan Refaeli, Guy Amir, Kyle Julian, Shahaf Bassan, Pei Huang, Ori Lahav, Min Wu, Min Zhang, Ekaterina Komendantskaya, Guy Katz, and Clark W. Barrett. 2024. Marabou 2.0: A Versatile Formal Analyzer of Neural Networks. InComputer Aided Verification - 36th Internationa...
-
[50]
Kaidi Xu, Zhouxing Shi, Huan Zhang, Yihan Wang, Kai-Wei Chang, Minlie Huang, Bhavya Kailkhura, Xue Lin, and Cho- Jui Hsieh. 2020. Automatic Perturbation Analysis for Scalable Certified Robustness and Beyond. InAdvances in Neural Information Processing Systems, H. Larochelle, M. Ranzato, R. Hadsell, M.F. Balcan, and H. Lin (Eds.), Vol. 33. Curran Asso- cia...
2020
-
[51]
Kaidi Xu, Huan Zhang, Shiqi Wang, Yihan Wang, Suman Jana, Xue Lin, and Cho-Jui Hsieh. 2021. Fast and Complete: Enabling Complete Neural Network Verification with Rapid and Massively Parallel Incomplete Verifiers. InInternational Conference on Learning Representations. https://openreview.net/forum?id=nVZtXBI6LNn
2021
-
[52]
Yuancheng Xu, Yanchao Sun, Micah Goldblum, Tom Goldstein, and Furong Huang. 2023. Exploring and Exploiting Decision Boundary Dynamics for Adversarial Robustness. InThe Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net. https://openreview.net/forum?id= aRTKuscKByJ On the Decompositionali...
2023
-
[53]
Huan Zhang, Tsui-Wei Weng, Pin-Yu Chen, Cho-Jui Hsieh, and Luca Daniel. 2018. Efficient Neural Network Robustness Certification with General Activation Functions. InAdvances in Neural Information Processing Systems, S. Bengio, H. Wallach, H. Larochelle, K. Grauman, N. Cesa-Bianchi, and R. Garnett (Eds.), Vol. 31. Curran Associates, Inc. https://proceeding...
2018
-
[54]
Xiang Zhang, Junbo Jake Zhao, and Yann LeCun. 2015. Character-level Convolutional Networks for Text Classifi- cation. InAdvances in Neural Information Processing Systems 28: Annual Conference on Neural Information Process- ing Systems 2015, December 7-12, 2015, Montreal, Quebec, Canada, Corinna Cortes, Neil D. Lawrence, Daniel D. Lee, Masashi Sugiyama, an...
2015
-
[55]
Siyan Zhao, Tung Nguyen, and Aditya Grover. 2024. Probing the Decision Boundaries of In-context Learning in Large Language Models. InAdvances in Neural Information Processing Systems, A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang (Eds.), Vol. 37. Curran Associates, Inc., 130408–130432. https://doi.org/10.52202/ 079017-4144
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.