Recognition: unknown
Linear Representations of Hierarchical Concepts in Language Models
Pith reviewed 2026-05-10 16:55 UTC · model grok-4.3
The pith
Language models encode concept hierarchies like country-region-continent relations as linear transformations in their activations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We investigate how and to what extent hierarchical relations are encoded in the internal representations of language models. Building on linear relational concepts, we train linear transformations specific to each hierarchical depth and semantic domain. Experiments show that, within a domain, hierarchical relations can be linearly recovered from model representations. We find that it is encoded in a relatively low-dimensional subspace and that this subspace tends to be domain-specific. Our main result is that hierarchy representation is highly similar across these domain-specific subspaces. Overall, we find that all models considered in our experiments encode concept hierarchies in the form
What carries the argument
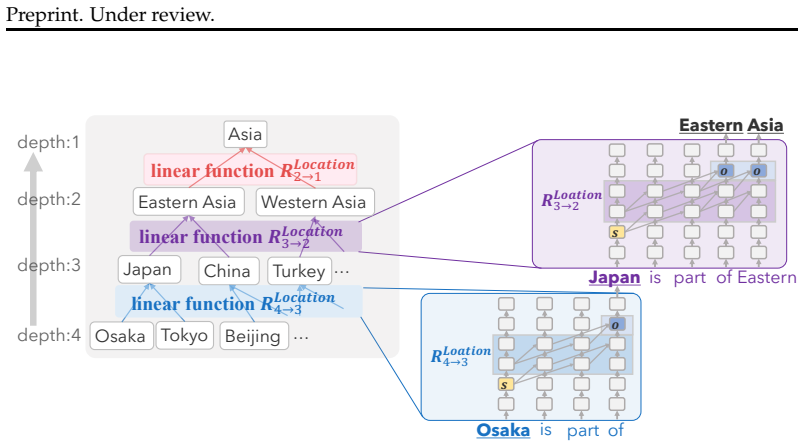
Linear transformations trained on model activations, one per hierarchical depth and semantic domain, that recover the inclusion relations from activations across multiple layers and multi-token entities.
If this is right
- Within any single semantic domain the hierarchical level of a concept can be read out linearly from the model's hidden states.
- The relevant information occupies a low-dimensional subspace of the activation space.
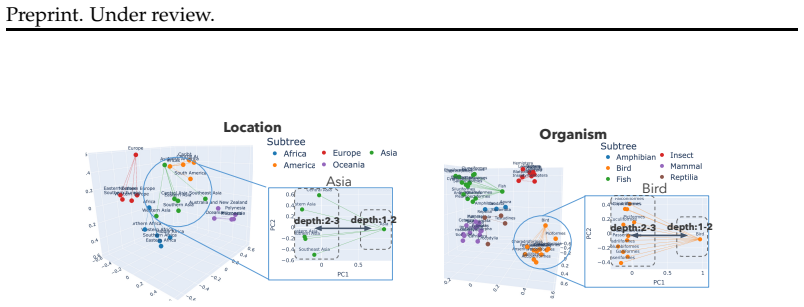
- Subspaces learned for different domains are nevertheless highly aligned with one another.
- The same linear structure appears across multiple model families and layers.
Where Pith is reading between the lines
- If the subspaces are as similar as reported, a single set of linear probes trained on one domain might transfer to many others without retraining.
- The low-dimensional character suggests that hierarchy information could be edited or suppressed by simple vector operations on activations.
- The finding raises the question of whether non-hierarchical relations, such as part-whole or temporal ordering, also admit comparable linear encodings.
Load-bearing premise
The trained linear transformations capture the model's genuine internal encoding of hierarchies instead of patterns introduced by the choice of training examples or the probing procedure itself.
What would settle it
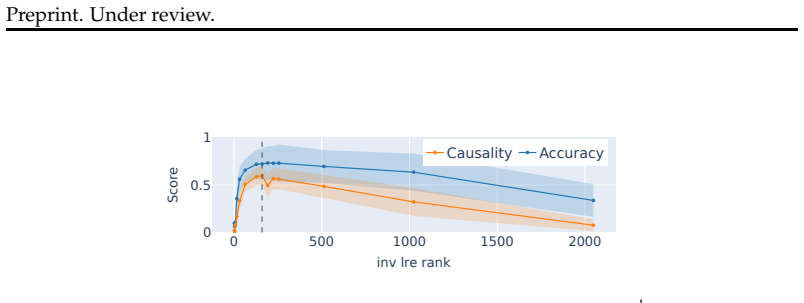
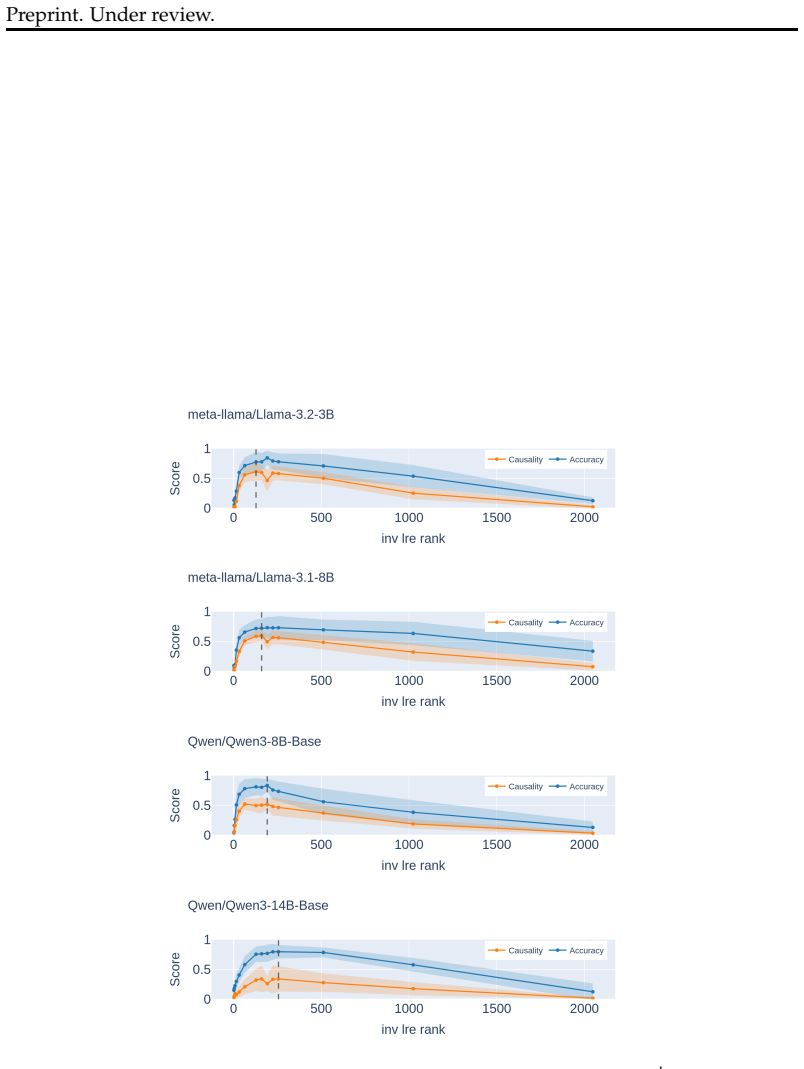
If new hierarchical pairs from the same domains, withheld from the linear training step, cannot be accurately classified by the learned transformations at rates well above chance, the claim of linear recoverability would be refuted.
Figures














read the original abstract
We investigate how and to what extent hierarchical relations (e.g., Japan $\subset$ Eastern Asia $\subset$ Asia) are encoded in the internal representations of language models. Building on Linear Relational Concepts, we train linear transformations specific to each hierarchical depth and semantic domain, and characterize representational differences associated with hierarchical relations by comparing these transformations. Going beyond prior work on the representational geometry of hierarchies in LMs, our analysis covers multi-token entities and cross-layer representations. Across multiple domains we learn such transformations and evaluate in-domain generalization to unseen data and cross-domain transfer. Experiments show that, within a domain, hierarchical relations can be linearly recovered from model representations. We then analyze how hierarchical information is encoded in representation space. We find that it is encoded in a relatively low-dimensional subspace and that this subspace tends to be domain-specific. Our main result is that hierarchy representation is highly similar across these domain-specific subspaces. Overall, we find that all models considered in our experiments encode concept hierarchies in the form of highly interpretable linear representations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that language models encode hierarchical relations (e.g., Japan ⊂ Eastern Asia ⊂ Asia) as linear structures in their internal representations. Building on linear relational concepts, it trains per-depth and per-domain linear transformations on activations, reports in-domain generalization to unseen data and cross-domain transfer, finds that hierarchies occupy low-dimensional domain-specific subspaces that are nevertheless highly similar across domains, and concludes that all tested models encode concept hierarchies in highly interpretable linear representations, with extensions to multi-token entities and cross-layer analysis.
Significance. If substantiated, the result would strengthen evidence that LMs maintain structured, linearly recoverable representations of hierarchies rather than purely distributed or non-linear encodings. It extends prior geometry work by addressing multi-token and cross-layer cases and by quantifying subspace similarity, which could inform interpretability methods and targeted knowledge editing.
major comments (2)
- Abstract: the claim of in-domain generalization and cross-domain subspace similarity is stated without any quantitative metrics, baselines, statistical tests, or details on data exclusion criteria, making it impossible to evaluate whether the evidence supports linear recoverability or the main result on subspace similarity.
- Probing setup (experiments section): linear transformations are fit to labeled hierarchical relations drawn from the same data distribution used for evaluation; without controls that isolate model-internal geometry from regularities in entity selection or parent-child annotation, both the reported recoverability and the cross-domain similarity could be artifacts of the probing method rather than evidence of the LM's encoding.
minor comments (2)
- Clarify the precise procedure and metric used to compare independently trained transformations across domains (e.g., cosine similarity after alignment, Procrustes distance).
- Specify the number of models, domains, hierarchical depths, and entity counts, along with any hyperparameter choices for the linear probes.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and detailed comments, which highlight important aspects of clarity and methodological rigor. We address each major comment below and outline revisions to the manuscript.
read point-by-point responses
-
Referee: Abstract: the claim of in-domain generalization and cross-domain subspace similarity is stated without any quantitative metrics, baselines, statistical tests, or details on data exclusion criteria, making it impossible to evaluate whether the evidence supports linear recoverability or the main result on subspace similarity.
Authors: We agree that the abstract should include key quantitative results to support the claims. In the revised version, we will add specific metrics for in-domain generalization (e.g., accuracy on held-out entities), cross-domain transfer performance, subspace dimensionality, and similarity measures (such as average cosine similarity between domain subspaces), along with references to the statistical tests and data exclusion criteria already detailed in the experiments section. revision: yes
-
Referee: Probing setup (experiments section): linear transformations are fit to labeled hierarchical relations drawn from the same data distribution used for evaluation; without controls that isolate model-internal geometry from regularities in entity selection or parent-child annotation, both the reported recoverability and the cross-domain similarity could be artifacts of the probing method rather than evidence of the LM's encoding.
Authors: We acknowledge this valid concern regarding potential artifacts. Our current setup already evaluates on unseen entities held out from the fitting process, and we compare against random baselines. However, to more directly isolate model-internal geometry, we will add control experiments in the revision, including label permutation tests and analysis of entity selection criteria from the source knowledge bases. These additions will help demonstrate that the linear recoverability and cross-domain similarities reflect the model's representations rather than annotation regularities. revision: partial
Circularity Check
No significant circularity; derivation relies on independent probes and held-out evaluation
full rationale
The paper trains per-domain, per-depth linear transformations on model activations to recover hierarchical relations, then evaluates in-domain generalization on held-out data and cross-domain transfer. The key claim of similar hierarchy representations across domain-specific subspaces is obtained by comparing these independently trained transformations rather than by any self-definitional reduction, fitted-parameter renaming, or load-bearing self-citation chain. All steps use standard probing with explicit held-out splits and external model activations, keeping the derivation self-contained against the input data and labels.
Axiom & Free-Parameter Ledger
free parameters (1)
- Linear transformation matrices per hierarchical depth and semantic domain
axioms (1)
- domain assumption Hierarchical relations between concepts are linearly separable in the model's representation space
Reference graph
Works this paper leans on
-
[1]
Can Language Models Encode Perceptual Structure Without Grounding?
Mostafa Abdou, Artur Kulmizev, Daniel Hershcovich, Stella Frank, Ellie Pavlick, and Anders S gaard. Can language models encode perceptual structure without grounding? a case study in color. In Arianna Bisazza and Omri Abend (eds.), Proceedings of the 25th Conference on Computational Natural Language Learning, pp.\ 109--132, Online, November 2021. Associat...
-
[2]
Refusal in language models is mediated by a single direction
Andy Arditi, Oscar Obeso, Aaquib Syed, Daniel Paleka, Nina Panickssery, Wes Gurnee, and Neel Nanda. Refusal in language models is mediated by a single direction. Advances in Neural Information Processing Systems, 37: 0 136037--136083, 2024
2024
-
[3]
Openalex topic classification v1 model artifacts and training data, January 2024
Justin Barrett. Openalex topic classification v1 model artifacts and training data, January 2024. URL https://doi.org/10.5281/zenodo.10568402
-
[4]
Discovering latent knowledge in language models without supervision
Collin Burns, Haotian Ye, Dan Klein, and Jacob Steinhardt. Discovering latent knowledge in language models without supervision. In The Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023 . OpenReview.net, 2023. URL https://openreview.net/forum?id=ETKGuby0hcs
2023
-
[5]
stackoverflow-dataset, 2022
Sunny Bhaveen Chandra. stackoverflow-dataset, 2022. URL https://huggingface.co/datasets/c17hawke/stackoverflow-dataset. Uploaded by Hugging Face user c17hawke. Accessed 2026-02-21
2022
-
[6]
Identifying linear relational concepts in large language models
David Chanin, Anthony Hunter, and Oana-Maria Camburu. Identifying linear relational concepts in large language models. In Kevin Duh, Helena Gomez, and Steven Bethard (eds.), Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pp.\ 1524--1535...
-
[7]
Dimitri Coelho Mollo and Raphaël Millière. The vector grounding problem. Philosophy and the Mind Sciences, 7 0 (1), Feb. 2026. doi:10.33735/phimisci.2026.12307. URL https://philosophymindscience.org/index.php/phimisci/article/view/12307
-
[8]
Val \' e rie Costa, Thomas Fel, Ekdeep Singh Lubana, Bahareh Tolooshams, and Demba E. Ba. From flat to hierarchical: Extracting sparse representations with matching pursuit. In Advances in Neural Information Processing Systems 36 (NeurIPS 2025), 2025
2025
-
[9]
ISO-3166-Countries-with-Regional-Codes
Luke Duncalfe. ISO-3166-Countries-with-Regional-Codes . https://github.com/lukes/ISO-3166-Countries-with-Regional-Codes/releases/tag/v10.0, 2024
2024
-
[10]
Conceptual spaces: The geometry of thought
Peter Gardenfors. Conceptual spaces: The geometry of thought. MIT press, 2004
2004
-
[11]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, Amy Yang, Angela Fan, Anirudh Goyal, Anthony Hartshorn, Aobo Yang, Archi Mitra, Archie Sravankumar, Artem Korenev, Arthur Hinsvark, Arun Rao, Aston Zhang, Aurelien Rodriguez, Austen Gregerson, Ava S...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Language models represent space and time
Wes Gurnee and Max Tegmark. Language models represent space and time. In The Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024 . OpenReview.net, 2024. URL https://openreview.net/forum?id=jE8xbmvFin
2024
-
[13]
Monotonic representation of numeric attributes in language models
Benjamin Heinzerling and Kentaro Inui. Monotonic representation of numeric attributes in language models. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar (eds.), Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pp.\ 175--195, Bangkok, Thailand, August 2024. Association for Computational Lin...
-
[14]
Linearity of relation decoding in transformer language models
Evan Hernandez, Arnab Sen Sharma, Tal Haklay, Kevin Meng, Martin Wattenberg, Jacob Andreas, Yonatan Belinkov, and David Bau. Linearity of relation decoding in transformer language models. In The Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024 . OpenReview.net, 2024. URL https://openreview.net/forum?...
2024
-
[15]
Position: The platonic representation hypothesis
Minyoung Huh, Brian Cheung, Tongzhou Wang, and Phillip Isola. Position: The platonic representation hypothesis. In Forty-first International Conference on Machine Learning, 2024. URL https://openreview.net/forum?id=BH8TYy0r6u
2024
-
[16]
Simon Kornblith, Mohammad Norouzi, Honglak Lee, and Geoffrey E. Hinton. Similarity of neural network representations revisited. In Kamalika Chaudhuri and Ruslan Salakhutdinov (eds.), Proceedings of the 36th International Conference on Machine Learning, ICML 2019, 9-15 June 2019, Long Beach, California, USA , Proceedings of Machine Learning Research, pp.\ ...
2019
-
[17]
Frontiers in Systems Neuroscience , VOLUME=
Nikolaus Kriegeskorte, Marieke Mur, and Peter Bandettini. Representational similarity analysis - connecting the branches of systems neuroscience. Frontiers in Systems Neuroscience, 2, 2008. ISSN 1662-5137. doi:10.3389/neuro.06.004.2008. URL https://www.frontiersin.org/articles/10.3389/neuro.06.004.2008
-
[18]
Nelson Francis
Henry Ku c era and W. Nelson Francis. Computational Analysis of Present-Day American English. Brown University Press, Providence, RI, 1967
1967
-
[19]
Maas, Raymond E
Andrew L. Maas, Raymond E. Daly, Peter T. Pham, Dan Huang, Andrew Y. Ng, and Christopher Potts. Learning word vectors for sentiment analysis. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, pp.\ 142--150, Portland, Oregon, USA, June 2011. Association for Computational Linguistics. UR...
2011
-
[20]
Language models implement simple W ord2 V ec-style vector arithmetic
Jack Merullo, Carsten Eickhoff, and Ellie Pavlick. Language models implement simple W ord2 V ec-style vector arithmetic. In Kevin Duh, Helena Gomez, and Steven Bethard (eds.), Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pp.\ 5030--50...
-
[21]
Llama 3.2 model card
Meta . Llama 3.2 model card. https://github.com/meta-llama/llama-models/blob/main/models/llama3_2/MODEL_CARD.md, 2024. Official model card
2024
-
[22]
Emergent Linear Representations in World Models of Self-Supervised Sequence Models
Neel Nanda, Andrew Lee, and Martin Wattenberg. Emergent linear representations in world models of self-supervised sequence models. In Yonatan Belinkov, Sophie Hao, Jaap Jumelet, Najoung Kim, Arya McCarthy, and Hosein Mohebbi (eds.), Proceedings of the 6th BlackboxNLP Workshop: Analyzing and Interpreting Neural Networks for NLP, pp.\ 16--30, Singapore, Dec...
-
[23]
The geometry of categorical and hierarchical concepts in large language models
Kiho Park, Yo Joong Choe, Yibo Jiang, and Victor Veitch. The geometry of categorical and hierarchical concepts in large language models. In The Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025 . OpenReview.net, 2025. URL https://openreview.net/forum?id=bVTM2QKYuA
2025
-
[24]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, Akshay Nathan, Alan Luo, Alec Helyar, Aleksander Madry, Aleksandr Efremov, Aleksandra Spyra, Alex Baker-Whitcomb, Alex Beutel, Alex Karpenko, Alex Makelov, Alex Neitz, Alex Wei, Alexandra Barr, Alexandre Kirchmeyer, Ale...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Daniel Freeman, Theodore R
Adly Templeton, Tom Conerly, Jonathan Marcus, Jack Lindsey, Trenton Bricken, Brian Chen, Adam Pearce, Craig Citro, Emmanuel Ameisen, Andy Jones, Hoagy Cunningham, Nicholas L Turner, Callum McDougall, Monte MacDiarmid, C. Daniel Freeman, Theodore R. Sumers, Edward Rees, Joshua Batson, Adam Jermyn, Shan Carter, Chris Olah, and Tom Henighan. Scaling monosema...
2024
-
[26]
Curt Tigges, Oskar John Hollinsworth, Atticus Geiger, and Neel Nanda. Linear representations of sentiment in large language models. CoRR, abs/2310.15154, 2023. doi:10.48550/ARXIV.2310.15154. URL https://doi.org/10.48550/arXiv.2310.15154
-
[27]
Wikidata: a free collaborative knowledgebase
Denny Vrande c i\' c and Markus Kr\" o tzsch. Wikidata: a free collaborative knowledgebase. Commun. ACM, 57 0 (10): 0 78–85, September 2014. ISSN 0001-0782. doi:10.1145/2629489. URL https://doi.org/10.1145/2629489
-
[28]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Character-level convolutional networks for text classification
Xiang Zhang, Junbo Jake Zhao, and Yann LeCun. Character-level convolutional networks for text classification. In Corinna Cortes, Neil D. Lawrence, Daniel D. Lee, Masashi Sugiyama, and Roman Garnett (eds.), Advances in Neural Information Processing Systems 28: Annual Conference on Neural Information Processing Systems 2015, December 7-12, 2015, Montreal, Q...
2015
-
[30]
Representation Engineering: A Top-Down Approach to AI Transparency
Andy Zou, Long Phan, Sarah Chen, James Campbell, Phillip Guo, Richard Ren, Alexander Pan, Xuwang Yin, Mantas Mazeika, Ann-Kathrin Dombrowski, et al. Representation engineering: A top-down approach to ai transparency, 2023. URL https://arxiv. org/abs/2310.01405, 97, 2023
work page internal anchor Pith review arXiv 2023
-
[31]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[32]
@esa (Ref
\@ifxundefined[1] #1\@undefined \@firstoftwo \@secondoftwo \@ifnum[1] #1 \@firstoftwo \@secondoftwo \@ifx[1] #1 \@firstoftwo \@secondoftwo [2] @ #1 \@temptokena #2 #1 @ \@temptokena \@ifclassloaded agu2001 natbib The agu2001 class already includes natbib coding, so you should not add it explicitly Type <Return> for now, but then later remove the command n...
-
[33]
\@lbibitem[] @bibitem@first@sw\@secondoftwo \@lbibitem[#1]#2 \@extra@b@citeb \@ifundefined br@#2\@extra@b@citeb \@namedef br@#2 \@nameuse br@#2\@extra@b@citeb \@ifundefined b@#2\@extra@b@citeb @num @parse #2 @tmp #1 NAT@b@open@#2 NAT@b@shut@#2 \@ifnum @merge>\@ne @bibitem@first@sw \@firstoftwo \@ifundefined NAT@b*@#2 \@firstoftwo @num @NAT@ctr \@secondoft...
-
[34]
@open @close @open @close and [1] URL: #1 \@ifundefined chapter * \@mkboth \@ifxundefined @sectionbib * \@mkboth * \@mkboth\@gobbletwo \@ifclassloaded amsart * \@ifclassloaded amsbook * \@ifxundefined @heading @heading NAT@ctr thebibliography [1] @ \@biblabel @NAT@ctr \@bibsetup #1 @NAT@ctr @ @openbib .11em \@plus.33em \@minus.07em 4000 4000 `\.\@m @bibit...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.