Recognition: unknown
DialBGM: A Benchmark for Background Music Recommendation from Everyday Multi-Turn Dialogues
Pith reviewed 2026-05-10 17:03 UTC · model grok-4.3
The pith
No model exceeds 35 percent accuracy selecting background music that fits everyday multi-turn dialogues.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
DialBGM shows that existing models cannot reliably identify suitable background music for natural multi-turn conversations, as measured by human preference rankings on contextual relevance, non-intrusiveness, and consistency, with no system reaching more than 35 percent Hit@1 on the top-ranked clip.
What carries the argument
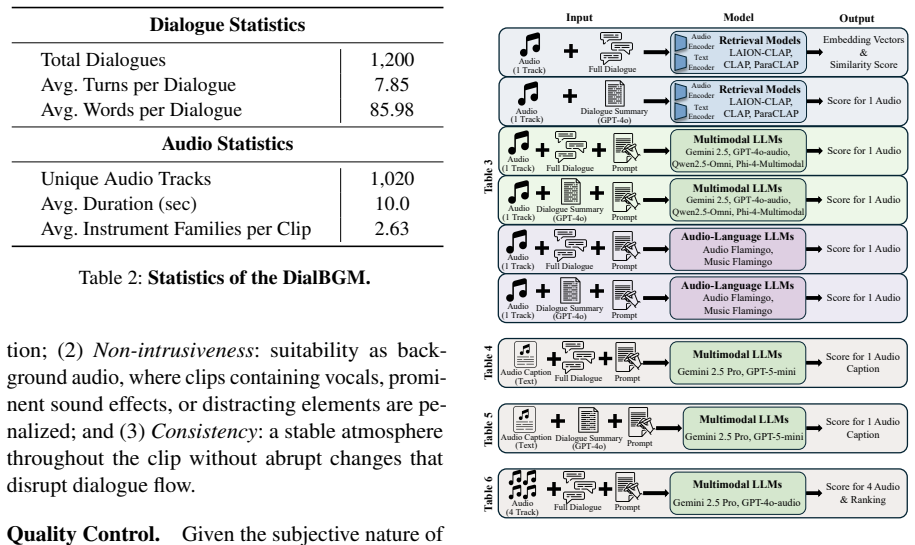
DialBGM dataset of 1,200 annotated dialogues with four music clips each, scored via Hit@1 against human rankings derived from background suitability criteria.
If this is right
- Retrieval and generative approaches both require explicit mechanisms for tracking multi-turn dialogue context to approach human-level BGM selection.
- Standardized benchmarks like DialBGM enable direct comparison of future discourse-aware music systems against the reported model ceiling.
- Media and interactive systems that rely on automated BGM will continue to need human oversight until model performance improves substantially.
- The task highlights the gap between current multimodal capabilities and the nuanced, non-explicit cues humans use when choosing background audio.
Where Pith is reading between the lines
- Improved dialogue-conditioned selection could reduce manual effort in film, game, and podcast post-production workflows.
- Extending the benchmark to include music generation rather than clip selection would test whether models can create original fitting tracks.
- Longer or more emotionally varied dialogues may expose even larger performance drops, suggesting a need for temporal reasoning over extended exchanges.
Load-bearing premise
Human rankings that weigh contextual relevance, non-intrusiveness, and consistency accurately reflect what makes music suitable as background for conversations.
What would settle it
Any model that surpasses 35 percent Hit@1 on the DialBGM test set, or a controlled listener study in which actual audience ratings diverge from the provided human preference rankings.
Figures





read the original abstract
Selecting an appropriate background music (BGM) that supports natural human conversation is a common production step in media and interactive systems. In this paper, we introduce dialogue-conditioned BGM recommendation, where a model should select non-intrusive, fitting music for a multi-turn conversation that often contains no music descriptors. To study this novel problem, we present DialBGM, a benchmark of 1,200 open-domain daily dialogues, each paired with four candidate music clips and annotated with human preference rankings. Rankings are determined by background suitability criteria, including contextual relevance, non-intrusiveness, and consistency. We evaluate a wide range of open-source and proprietary models, including audio-language models and multimodal LLMs, and show that current models fall far short of human judgments; no model exceeds 35% Hit@1 when selecting the top-ranked clip. DialBGM provides a standardized benchmark for developing discourse-aware methods for BGM selection and for evaluating both retrieval-based and generative models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DialBGM, a benchmark of 1,200 open-domain daily dialogues each paired with four candidate music clips and annotated with human preference rankings according to criteria of contextual relevance, non-intrusiveness, and consistency. It evaluates a range of open-source and proprietary models (audio-language models and multimodal LLMs) on the task of selecting the top-ranked clip and reports that no model exceeds 35% Hit@1, concluding that current models fall far short of human judgments for dialogue-conditioned background music recommendation.
Significance. If the annotations are shown to be reliable, the work would be significant as the first standardized benchmark for discourse-aware BGM selection, a task relevant to media production and interactive systems. The creation of new annotated data and an explicit evaluation protocol are strengths that enable reproducible comparisons between retrieval-based and generative approaches.
major comments (1)
- [Abstract] Abstract: the description of the annotation process states that rankings are produced by the listed criteria but supplies no inter-annotator agreement figures, number of raters per dialogue, data collection protocol, or disagreement resolution method. This is load-bearing for the central claim that models fall short of human performance, because the reported 35% Hit@1 ceiling cannot be interpreted as a modeling limit without evidence that the ground-truth rankings are stable.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for identifying an important clarity issue in the abstract. We address the comment point-by-point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the description of the annotation process states that rankings are produced by the listed criteria but supplies no inter-annotator agreement figures, number of raters per dialogue, data collection protocol, or disagreement resolution method. This is load-bearing for the central claim that models fall short of human performance, because the reported 35% Hit@1 ceiling cannot be interpreted as a modeling limit without evidence that the ground-truth rankings are stable.
Authors: We agree that the abstract, as currently written, does not sufficiently summarize the annotation reliability details and that this information is important for interpreting the benchmark results. The full annotation protocol—including the number of raters per dialogue, data collection procedure via a crowdsourcing platform, inter-annotator agreement statistics, and disagreement resolution method—is described in Section 3.2 of the manuscript. We will revise the abstract to include a concise statement on these aspects (e.g., referencing the number of annotators and agreement level) so that readers can immediately assess the stability of the ground-truth rankings without needing to consult the main text. revision: yes
Circularity Check
No circularity: benchmark introduces new data and empirical evaluation without self-referential derivations
full rationale
The paper presents DialBGM as a new benchmark consisting of 1,200 dialogues paired with four music clips and human-annotated preference rankings based on contextual relevance, non-intrusiveness, and consistency. The central empirical claim (no model exceeds 35% Hit@1) is an observation on this freshly collected and annotated dataset rather than a derivation from prior fitted parameters, equations, or self-citations. No load-bearing self-citations, ansatzes, or uniqueness theorems are invoked; the work is self-contained as a data-and-protocol contribution with direct model evaluations.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Human annotators can consistently judge background music suitability using the stated criteria of contextual relevance, non-intrusiveness, and consistency.
Reference graph
Works this paper leans on
-
[1]
Phi-4-Mini Technical Report: Compact yet Powerful Multimodal Language Models via Mixture-of-LoRAs
Phi-4-mini tech- nical report: Compact yet powerful multimodal lan- guage models via mixture-of-loras.arXiv preprint arXiv:2503.01743. Andrea Agostinelli, Timo I Denk, Zalán Borsos, Jesse Engel, Mauro Verzetti, Antoine Caillon, Qingqing Huang, Aren Jansen, Adam Roberts, 9 Marco Tagliasacchi, and 1 others
work page internal anchor Pith review arXiv
-
[2]
MusicLM: Generating Music From Text
Musi- clm: Generating music from text.arXiv preprint arXiv:2301.11325. Alessandro Ansani, Marco Marini, Francesca D’Errico, and Isabella Poggi
work page internal anchor Pith review arXiv
-
[3]
In Machine Learning for Music Discovery Workshop, In- ternational Conference on Machine Learning (ICML 2019)
The mtg- jamendo dataset for automatic music tagging. In Machine Learning for Music Discovery Workshop, In- ternational Conference on Machine Learning (ICML 2019). Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, and 1 others
2019
-
[4]
Yunfei Chu, Jin Xu, Qian Yang, Haojie Wei, Xipin Wei, Zhifang Guo, Yichong Leng, Yuanjun Lv, Jinzheng He, Junyang Lin, and 1 others
Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901. Yunfei Chu, Jin Xu, Qian Yang, Haojie Wei, Xipin Wei, Zhifang Guo, Yichong Leng, Yuanjun Lv, Jinzheng He, Junyang Lin, and 1 others
1901
-
[5]
Qwen2-audio technical report.arXiv preprint arXiv:2407.10759. Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Mar- cel Blistein, Ori Ram, Dan Zhang, Evan Rosen, and 1 others
work page internal anchor Pith review arXiv
-
[6]
Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261. Seungheon Doh, Keunwoo Choi, Jongpil Lee, and Juhan Nam
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Lp-musiccaps: Llm-based pseudo music captioning. InIsmir 2023 Hybrid Conference. Seungheon Doh, Keunwoo Choi, and Juhan Nam. 2025a. Talkplay: Multimodal music recommenda- tion with large language models.arXiv preprint arXiv:2502.13713. Seungheon Doh, Keunwoo Choi, and Juhan Nam. 2025b. Talkplay-tools: Conversational music rec- ommendation with llm tool ca...
-
[8]
InICASSP 2020-2020 IEEE International Confer- ence on Acoustics, Speech and Signal Processing (ICASSP), pages 736–740
Clotho: An audio captioning dataset. InICASSP 2020-2020 IEEE International Confer- ence on Acoustics, Speech and Signal Processing (ICASSP), pages 736–740. IEEE. Benjamin Elizalde, Soham Deshmukh, Mahmoud Al Is- mail, and Huaming Wang
2020
-
[9]
InICASSP 2023-2023 IEEE International Confer- ence on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5
Clap learning audio concepts from natural language supervision. InICASSP 2023-2023 IEEE International Confer- ence on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5. IEEE. Sreyan Ghosh, Arushi Goel, Lasha Koroshinadze, Sang- gil Lee, Zhifeng Kong, Joao Felipe Santos, Ramani Duraiswami, Dinesh Manocha, Wei Ping, Moham- mad Shoeybi, and 1 others
2023
-
[10]
Music flamingo: Scaling music understanding in audio language models
Music flamingo: Scaling music understanding in audio language mod- els.arXiv preprint arXiv:2511.10289. Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, and 1 others
-
[11]
Gpt-4o system card.arXiv preprint arXiv:2410.21276. Xin Jing, Andreas Triantafyllopoulos, and Björn Schuller
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Paraclap–towards a general language- audio model for computational paralinguistic tasks. InProc. Interspeech 2024, pages 1155–1159. Jaeyong Kang and Dorien Herremans
2024
-
[13]
Audiocaps: Generating cap- tions for audios in the wild. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Hu- man Language Technologies, V olume 1 (Long and Short Papers), pages 119–132. Zhifeng Kong, Arushi Goel, Rohan Badlani, Wei Ping, Rafael Valle, and Bryan Catanzaro
2019
-
[14]
Yanran Li, Hui Su, Xiaoyu Shen, Wenjie Li, Ziqiang Cao, and Shuzi Niu
Talk the walk: Syn- thetic data generation for conversational music rec- ommendation.arXiv preprint arXiv:2301.11489. Yanran Li, Hui Su, Xiaoyu Shen, Wenjie Li, Ziqiang Cao, and Shuzi Niu
-
[15]
https:// openai.com/index/gpt-5-system-card/
GPT-5 System Card. https:// openai.com/index/gpt-5-system-card/ . Ac- cessed: 2025-01-06. Soujanya Poria, Devamanyu Hazarika, Navonil Ma- jumder, Gautam Naik, Erik Cambria, and Rada Mihal- cea
2025
-
[16]
MMAU: A Massive Multi-Task Audio Understanding and Reasoning Benchmark
Mmau: A massive multi-task audio under- standing and reasoning benchmark.arXiv preprint arXiv:2410.19168. Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, and 1 others
work page internal anchor Pith review arXiv
-
[17]
InICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Process- ing (ICASSP), pages 1–5
Large-scale contrastive language-audio pretraining with feature fusion and keyword-to-caption augmen- tation. InICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Process- ing (ICASSP), pages 1–5. IEEE. Jin Xu, Zhifang Guo, Jinzheng He, Hangrui Hu, Ting He, Shuai Bai, Keqin Chen, Jialin Wang, Yang Fan, Kai Dang, and 1 others
2023
-
[18]
Qwen2. 5-omni tech- nical report.arXiv preprint arXiv:2503.20215. Chunyi Zhou, Yuanyuan Jin, Kai Zhang, Jiahao Yuan, Shengyuan Li, and Xiaoling Wang
work page internal anchor Pith review arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.