Recognition: unknown
Visual Perceptual to Conceptual First-Order Rule Learning Networks
Pith reviewed 2026-05-10 16:56 UTC · model grok-4.3
The pith
γILP creates a fully differentiable pipeline that learns first-order rules directly from raw images by substituting constants and inducing structures while inventing predicates automatically.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
γILP provides a fully differentiable pipeline from image constant substitution to rule structure induction and achieves strong performance on classical symbolic relational datasets as well as on relational image data and pure image datasets such as Kandinsky patterns.
What carries the argument
The γILP pipeline that maps perceptual image features into conceptual predicates for end-to-end first-order rule induction.
If this is right
- The method succeeds on symbolic relational datasets using the same pipeline.
- It extends to relational image data without requiring supporting labels.
- Pure image datasets such as Kandinsky patterns are handled with automatic predicate invention.
- Rule structures emerge through end-to-end differentiation rather than separate symbolic stages.
Where Pith is reading between the lines
- Similar pipelines might extract rules from video or sensor streams where rules involve temporal relations.
- The approach could be tested for improving interpretability in larger vision models by extracting rules from their feature representations.
Load-bearing premise
That image elements can be substituted as logical constants in a manner that supports fully differentiable induction of rule structures without any image labels or predefined predicates.
What would settle it
Applying γILP to a fresh Kandinsky-style image dataset whose ground-truth rules require invention of multiple new predicates and checking whether the induced rules match the intended ones at high accuracy.
Figures

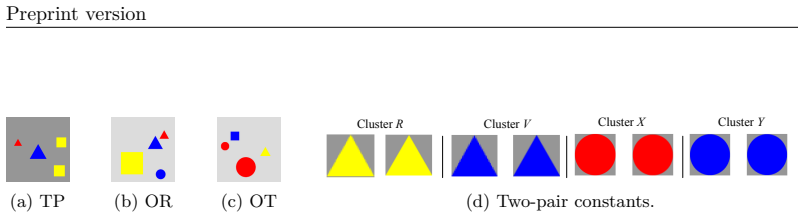
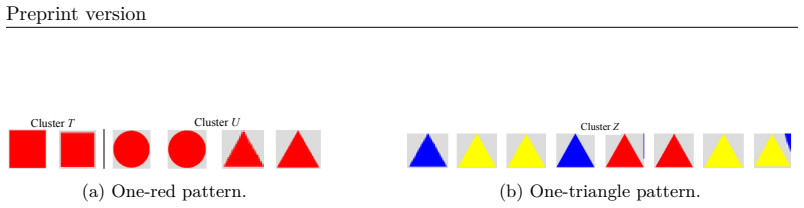


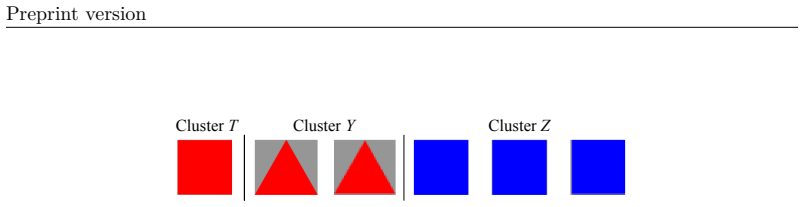






read the original abstract
Learning rules plays a crucial role in deep learning, particularly in explainable artificial intelligence and enhancing the reasoning capabilities of large language models. While existing rule learning methods are primarily designed for symbolic data, learning rules from image data without supporting image labels and automatically inventing predicates remains a challenge. In this paper, we tackle these inductive rule learning problems from images with a framework called {\gamma}ILP, which provides a fully differentiable pipeline from image constant substitution to rule structure induction. Extensive experiments demonstrate that {\gamma}ILP achieves strong performance not only on classical symbolic relational datasets but also on relational image data and pure image datasets, such as Kandinsky patterns.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces γILP, a framework providing a fully differentiable pipeline that maps raw images through constant substitution into rule structure induction and first-order logic learning. It claims to automatically invent predicates without image-level labels and reports strong performance on classical symbolic relational datasets, relational image data, and pure image datasets such as Kandinsky patterns.
Significance. If the differentiability and predicate-invention claims hold with supporting evidence, the work would advance neuro-symbolic AI by enabling end-to-end rule learning directly from perceptual inputs, addressing a gap in explainable reasoning for vision systems. The pipeline's applicability across symbolic and image domains would be a notable contribution if quantitatively validated.
major comments (2)
- [Abstract] Abstract: the claim that γILP 'achieves strong performance' on multiple dataset types (including Kandinsky patterns) without supporting labels is unsupported by any metrics, baselines, ablation studies, or error analysis in the provided text, rendering the central claim unverifiable.
- [Method (implied by abstract description)] The differentiability of rule structure induction and automatic predicate invention (central to the pipeline from image constants to rules) depends on an unspecified continuous relaxation of clause selection and unification; without explicit description of how gradients discover semantically meaningful predicates rather than dataset-specific perceptual patterns, the 'no supporting labels' and 'automatic invention' aspects remain unverified.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address the major comments point by point below, with clarifications from the full manuscript and proposed revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that γILP 'achieves strong performance' on multiple dataset types (including Kandinsky patterns) without supporting labels is unsupported by any metrics, baselines, ablation studies, or error analysis in the provided text, rendering the central claim unverifiable.
Authors: We agree the abstract itself contains no numerical metrics. The full manuscript (Section 5) provides quantitative results with metrics, baselines, ablations, and error analysis across symbolic relational datasets, relational images, and Kandinsky patterns, all without image-level labels. We will revise the abstract to incorporate key performance numbers and explicit cross-references to the experimental section so the claim is directly verifiable. revision: yes
-
Referee: [Method (implied by abstract description)] The differentiability of rule structure induction and automatic predicate invention (central to the pipeline from image constants to rules) depends on an unspecified continuous relaxation of clause selection and unification; without explicit description of how gradients discover semantically meaningful predicates rather than dataset-specific perceptual patterns, the 'no supporting labels' and 'automatic invention' aspects remain unverified.
Authors: The continuous relaxation (softmax over clause structures and embedding-based differentiable unification) is specified in the Method section. Gradients optimize both rule structure and predicate embeddings via an end-to-end consistency loss on the observed data, enabling label-free predicate invention. Experiments show the invented predicates align with meaningful relations. We will expand the method with explicit relaxation equations, gradient-flow diagrams, and further analysis distinguishing semantic predicates from spurious patterns. revision: yes
Circularity Check
No significant circularity; new differentiable pipeline presented as independent contribution
full rationale
The paper introduces γILP as a novel fully differentiable framework mapping image constants to rule induction, with performance claims supported by experiments on symbolic, relational image, and Kandinsky datasets rather than by tautological re-derivation of inputs. No self-definitional equations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the abstract or described method; the central pipeline is positioned as addressing an open challenge (unlabeled predicate invention) via a new architecture instead of reducing to prior fitted quantities or author-specific uniqueness theorems. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Neuro-symbolic rule learning in real-world classification tasks
Kexin Gu Baugh, Nuri Cingillioglu, and Alessandra Russo. Neuro-symbolic rule learning in real-world classification tasks. In Proceedings of the AAAI 2023 Spring Symposium on Challenges Requiring the Combination of Machine Learning and Knowledge Engineering (AAAI-MAKE 2023), Hyatt Regency, San Francisco Airport, California, USA, March 27-29, 2023, volume 3...
2023
-
[2]
Neural DNF-MT: A neuro-symbolic approach for learning interpretable and editable policies
Kexin Gu Baugh, Luke Dickens, and Alessandra Russo. Neural DNF-MT: A neuro-symbolic approach for learning interpretable and editable policies. In Proceedings of the 24th International Conference on Autonomous Agents and Multiagent Systems, AAMAS 2025, Detroit, MI, USA, May 19-23, 2025, pp. 252–260,
2025
-
[3]
William W. Cohen. Fast effective rule induction. In Armand Prieditis and Stuart Russell (eds.), Machine Learning, Proceedings of the Twelfth International Conference on Machine Learning, Tahoe City, California, USA, July 9-12, 1995, pp. 115–123. Morgan Kaufmann,
1995
-
[4]
Faithful reasoning using large language models.arXiv preprint arXiv:2208.14271, 2022
Antonia Creswell and Murray Shanahan. Faithful reasoning using large language models. CoRR, abs/2208.14271,
-
[5]
Muggleton
Andrew Cropper and Stephen H. Muggleton. Learning higher-order logic programs through abstraction and invention. In Subbarao Kambhampati (ed.), Proceedings of the Twenty- Fifth International Joint Conference on Artificial Intelligence, IJCAI 2016, New York, NY, USA, 9-15 July 2016, pp. 1418–1424,
2016
-
[6]
Neuro-symbolic learning of answer set programs from raw data
Daniel Cunnington, Mark Law, Jorge Lobo, and Alessandra Russo. Neuro-symbolic learning of answer set programs from raw data. In Proceedings of the Thirty-Second International Joint Conference on Artificial Intelligence, IJCAI 2023, 19th-25th August 2023, Macao, SAR, China, pp. 3586–3596,
2023
-
[7]
The role of founda- tion models in neuro-symbolic learning and reasoning
Daniel Cunnington, Mark Law, Jorge Lobo, and Alessandra Russo. The role of founda- tion models in neuro-symbolic learning and reasoning. In Neural-Symbolic Learning and Reasoning - 18th International Conference, NeSy 2024, Barcelona, Spain, September 9- 12, 2024, Proceedings, Part I, volume 14979 of Lecture Notes in Computer Science, pp. 84–100,
2024
-
[8]
Carvalho, and André Freitas
João Pedro Gandarela de Souza, Danilo S. Carvalho, and André Freitas. Inductive learning of logical theories with llms: A expressivity-graded analysis. In AAAI-25, Sponsored by the Association for the Advancement of Artificial Intelligence, February 25 - March 4, 2025, Philadelphia, PA, USA, pp. 23752–23759,
2025
-
[9]
Predicate renaming via large language models
Elisabetta Gentili, Tony Ribeiro, Fabrizio Riguzzi, and Katsumi Inoue. Predicate renaming via large language models. CoRR, abs/2510.25517,
-
[10]
Pragmatic norms are all you need - why the symbol grounding problem does not apply to LLMs
Reto Gubelmann. Pragmatic norms are all you need - why the symbol grounding problem does not apply to LLMs. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, EMNLP 2024, Miami, FL, USA, November 12-16, 2024, pp. 11663–11678,
2024
-
[11]
Fabbri, Wojciech Kryscinski, Semih Yavuz, Ye Liu, Xi Victoria Lin, Shafiq Joty, Yingbo Zhou, Caiming Xiong, Rex Ying, Arman Cohan, and Dragomir Radev
Simeng Han, Hailey Schoelkopf, Yilun Zhao, Zhenting Qi, Martin Riddell, Wenfei Zhou, James Coady, David Peng, Yujie Qiao, Luke Benson, Lucy Sun, Alexander Wardle- Solano, Hannah Szabó, Ekaterina Zubova, Matthew Burtell, Jonathan Fan, Yixin Liu, Brian Wong, Malcolm Sailor, Ansong Ni, Linyong Nan, Jungo Kasai, Tao Yu, Rui Zhang, Alexander R. Fabbri, Wojciec...
2024
-
[12]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In 2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, Las Vegas, NV, USA, June 27-30, 2016, pp. 770–778,
2016
-
[13]
Learning big logical rules by joining small rules
Céline Hocquette, Andreas Niskanen, Rolf Morel, Matti Järvisalo, and Andrew Cropper. Learning big logical rules by joining small rules. In Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence, IJCAI 2024, Jeju, South Korea, August 3-9, 2024, pp. 3430–3438,
2024
-
[14]
Kingma and Max Welling
Diederik P. Kingma and Max Welling. Auto-encoding variational bayes. In 2nd International Conference on Learning Representations, ICLR 2014, Banff, AB, Canada, April 14-16, 2014, Conference Track Proceedings,
2014
-
[15]
Domingos
Stanley Kok and Pedro M. Domingos. Statistical predicate invention. In Machine Learning, Proceedings of the Twenty-Fourth International Conference (ICML 2007), Corvallis, Ore- gon, USA, June 20-24, 2007, volume 227 of ACM International Conference Proceeding Series, pp. 433–440. ACM,
2007
-
[16]
Softened symbol grounding for neuro-symbolic systems
Zenan Li, Yuan Yao, Taolue Chen, Jingwei Xu, Chun Cao, Xiaoxing Ma, and Jian Lü. Softened symbol grounding for neuro-symbolic systems. In The Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023,
2023
-
[17]
Logicot: Logical chain-of-thought instruction tuning
Hanmeng Liu, Zhiyang Teng, Leyang Cui, Chaoli Zhang, Qiji Zhou, and Yue Zhang. Logicot: Logical chain-of-thought instruction tuning. In Findings of the Association for Computa- tional Linguistics: EMNLP 2023, Singapore, December 6-10, 2023, pp. 2908–2921,
2023
-
[18]
Ilya Loshchilov and Frank Hutter
ISBN 3-540-13299-6. Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. In 7th Interna- tional Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6-9, 2019,
2019
-
[19]
Muggleton and Wray L
Stephen H. Muggleton and Wray L. Buntine. Machine invention of first order predicates by inverting resolution. In Machine Learning, Proceedings of the Fifth International Conference on Machine Learning, Ann Arbor, Michigan, USA, June 12-14, 1988, pp. 339–352,
1988
-
[20]
Girshick, and Ali Farhadi
Joseph Redmon, Santosh Kumar Divvala, Ross B. Girshick, and Ali Farhadi. You only look once: Unified, real-time object detection. In 2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, Las Vegas, NV, USA, June 27-30, 2016, pp. 779–788,
2016
-
[21]
Techniques for symbol grounding with SATNet
14 Preprint version Sever Topan, David Rolnick, and Xujie Si. Techniques for symbol grounding with SATNet. In Advances in Neural Information Processing Systems 34: Annual Conference on Neural Information Processing Systems 2021, NeurIPS 2021, December 6-14, 2021, virtual, pp. 20733–20744,
2021
-
[22]
doi: 10.1145/321978.321991. Po-Wei Wang, Priya L. Donti, Bryan Wilder, and J. Zico Kolter. SATNet: Bridging deep learning and logical reasoning using a differentiable satisfiability solver. In Proceedings of the 36th International Conference on Machine Learning, ICML 2019, 9-15 June 2019, Long Beach, California, USA, volume 97, pp. 6545–6554. PMLR,
-
[23]
arXiv preprint arXiv:2502.14768 , year=
Tian Xie, Zitian Gao, Qingnan Ren, Haoming Luo, Yuqian Hong, Bryan Dai, Joey Zhou, Kai Qiu, Zhirong Wu, and Chong Luo. Logic-RL: Unleashing LLM reasoning with rule-based reinforcement learning. CoRR, abs/2502.14768,
-
[24]
RA VEN: A dataset for relational and analogical visual reasoning
Chi Zhang, Feng Gao, Baoxiong Jia, Yixin Zhu, and Song-Chun Zhu. RA VEN: A dataset for relational and analogical visual reasoning. In IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2019, Long Beach, CA, USA, June 16-20, 2019, pp. 5317–5327. Computer Vision Foundation / IEEE,
2019
-
[25]
Constants are textual; thus, we set g(x) = x and λ = 0 in Eq
15 Preprint version A Statistical Information of ILP Datasets To assess our differentiable substitution method, we evaluate γILP on classical ILP datasets ( Evans & Grefenstette , 2018). Constants are textual; thus, we set g(x) = x and λ = 0 in Eq. ( 4). We use pre-trained V AE as the encoder for textual relations and con- stants. We report results from b...
2018
-
[26]
Otherwise, recall is computed on facts involving constants not seen during training
When testing data is available, such as in the Husband and Uncle tasks, we compute the recall of the learned rules on the test set. Otherwise, recall is computed on facts involving constants not seen during training. Domain Task # Constant # Relation Arithmetic Predecessor 10 3 Odd 10 3 Even 10 3 Lessthan 10 3 Fizz 7 3 Buzz 10 3 Lists Member 8 3 Length 8 ...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.