Recognition: no theorem link
PanoSAM2: Lightweight Distortion- and Memory-aware Adaptions of SAM2 for 360 Video Object Segmentation
Pith reviewed 2026-05-10 18:21 UTC · model grok-4.3
The pith
Lightweight changes to SAM2 fix distortion and memory gaps for consistent object masks in 360 videos.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
PanoSAM2 adapts SAM2 via a Pano-Aware Decoder with seam-consistent receptive fields and iterative distortion refinement, a Distortion-Guided Mask Loss that emphasizes stretched regions and boundaries, and a Long-Short Memory Module that maintains a compact long-term object pointer to re-instantiate and align short-term memories, yielding reliable temporally-consistent 360 video object segmentation while preserving the original user-friendly prompting design.
What carries the argument
The Pano-Aware Decoder together with the Distortion-Guided Mask Loss and Long-Short Memory Module, which together handle spherical boundary continuity, pixel weighting by distortion, and object memory reuse.
If this is right
- SAM2 can support promptable 360VOS without full retraining on panoramic data.
- Temporal coherence improves because long-term object pointers refresh short-term memory states.
- Boundary continuity is maintained across the 0/360 seam through wrapped receptive fields and refinement.
- Stretched and boundary pixels receive higher training emphasis via distortion-weighted loss.
- The original SAM2 prompting interface remains usable for 360 video tasks.
Where Pith is reading between the lines
- Similar seam-aware and distortion-weighted modules could be tested on other non-planar projections such as fisheye video for robotics.
- The long-short memory design may generalize to other foundation models that suffer from object sparsity in long sequences.
- If the gains hold across more 360 datasets, the approach reduces reliance on creating large dedicated panoramic training collections.
Load-bearing premise
The three proposed lightweight modules together resolve projection distortion, seam inconsistency, and sparse memory without introducing new artifacts or requiring dataset-specific retraining.
What would settle it
Running PanoSAM2 on the 360VOTS or PanoVOS test sets and observing either lower accuracy than baseline SAM2 or visible new artifacts at the left-right seam would show the adaptations do not deliver the claimed gains.
Figures











read the original abstract
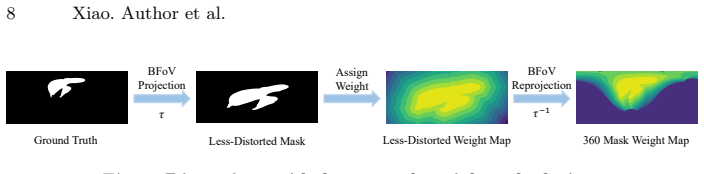
360 video object segmentation (360VOS) aims to predict temporally-consistent masks in 360 videos, offering full-scene coverage, benefiting applications, such as VR/AR and embodied AI. Learning 360VOS model is nontrivial due to the lack of high-quality labeled dataset. Recently, Segment Anything Models (SAMs), especially SAM2 -- with its design of memory module -- shows strong, promptable VOS capability. However, directly using SAM2 for 360VOS yields implausible results as 360 videos suffer from the projection distortion, semantic inconsistency of left-right sides, and sparse object mask information in SAM2's memory. To this end, we propose PanoSAM2, a novel 360VOS framework based on our lightweight distortion- and memory-aware adaptation strategies of SAM2 to achieve reliable 360VOS while retaining SAM2's user-friendly prompting design. Concretely, to tackle the projection distortion and semantic inconsistency issues, we propose a Pano-Aware Decoder with seam-consistent receptive fields and iterative distortion refinement to maintain continuity across the 0/360 degree boundary. Meanwhile, a Distortion-Guided Mask Loss is introduced to weight pixels by distortion magnitude, stressing stretched regions and boundaries. To address the object sparsity issue, we propose a Long-Short Memory Module to maintain a compact long-term object pointer to re-instantiate and align short-term memories, thereby enhancing temporal coherence. Extensive experiments show that PanoSAM2 yields substantial gains over SAM2: +5.6 on 360VOTS and +6.7 on PanoVOS, showing the effectiveness of our method.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PanoSAM2 as a lightweight adaptation of SAM2 for 360 video object segmentation (360VOS). It identifies three core challenges with direct SAM2 application—projection distortion, semantic inconsistency across the 0/360° seam, and sparse object memory—and addresses them via a Pano-Aware Decoder (seam-consistent receptive fields plus iterative distortion refinement), a Distortion-Guided Mask Loss that weights pixels by distortion magnitude, and a Long-Short Memory Module that maintains a compact long-term object pointer to align short-term memories. The central empirical claim is that these adaptations yield +5.6 on 360VOTS and +6.7 on PanoVOS over SAM2 while preserving SAM2’s promptable interface; ablations and qualitative results are used to attribute the gains to the individual modules.
Significance. If the reported gains hold under the provided ablations, the work offers a practical, low-overhead route to reliable promptable 360VOS, which is relevant for VR/AR and embodied-AI pipelines. A strength is the explicit empirical attribution of improvements to the three proposed components rather than training differences, together with retention of SAM2’s user-friendly prompting design.
major comments (1)
- [§3.3] §3.3 (Long-Short Memory Module): the description of how the long-term pointer re-instantiates and aligns short-term memories is clear, yet the paper does not state whether this module introduces any learnable parameters or requires even light fine-tuning; if it is purely inference-time, this should be stated explicitly to support the “no dataset-specific retraining” claim.
minor comments (3)
- [Abstract] Abstract: the quantitative claims (+5.6 / +6.7) are given without dataset sizes, number of sequences, or prompting protocol; adding one sentence with these details would improve reproducibility.
- [Table 2] Table 2 (ablations): the per-module gains are reported, but the table would be clearer if it also listed the absolute scores for the full PanoSAM2 and the SAM2 baseline on both datasets.
- [Figure 4] Figure 4 (qualitative results): arrows or zoomed insets highlighting the seam and distortion regions would make the visual comparison more immediate.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation, the recommendation of minor revision, and the constructive comment on the Long-Short Memory Module. We address the point below and will update the manuscript accordingly.
read point-by-point responses
-
Referee: [§3.3] §3.3 (Long-Short Memory Module): the description of how the long-term pointer re-instantiates and aligns short-term memories is clear, yet the paper does not state whether this module introduces any learnable parameters or requires even light fine-tuning; if it is purely inference-time, this should be stated explicitly to support the “no dataset-specific retraining” claim.
Authors: We appreciate the referee highlighting this omission. The Long-Short Memory Module is strictly an inference-time component and introduces no learnable parameters or fine-tuning. It reuses the existing memory bank and attention mechanisms of the frozen SAM2 backbone, computing the compact long-term object pointer via a deterministic aggregation (e.g., temporal averaging of object tokens weighted by similarity) that requires no gradients or dataset-specific optimization. This design directly supports our claim of no dataset-specific retraining. We will add an explicit statement to this effect in the revised §3.3. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper describes three lightweight engineering adaptations (Pano-Aware Decoder with seam-consistent fields, Distortion-Guided Mask Loss, and Long-Short Memory Module) to SAM2 for 360VOS. These are presented as design choices whose value is demonstrated via ablation studies and quantitative gains on 360VOTS/PanoVOS benchmarks. No equations, first-principles derivations, or predictions appear that reduce by construction to fitted parameters, self-definitions, or self-citation chains. The central claims rest on empirical attribution rather than any load-bearing mathematical equivalence or imported uniqueness theorem.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Athar, A., Hermans, A., Luiten, J., Ramanan, D., Leibe, B.: Tarvis: A unified approach for target-based video segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 18738–18748 (2023)
2023
-
[2]
In: Proceedings of the IEEE/CVF In- ternational Conference on Computer Vision
Bekuzarov, M., Bermudez, A., Lee, J.Y., Li, H.: Xmem++: Production-level video segmentation from few annotated frames. In: Proceedings of the IEEE/CVF In- ternational Conference on Computer Vision. pp. 635–644 (2023)
2023
-
[3]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2024)
Chen, H., Hou, Y., Qu, C., Testini, I., Hong, X., Jiao, J.: 360+x: A panoptic multi- modal scene understanding dataset. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2024)
2024
-
[4]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Cheng, H.K., Oh, S.W., Price, B., Lee, J.Y., Schwing, A.: Putting the object back into video object segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 3151–3161 (2024)
2024
-
[5]
In: European conference on computer vision
Cheng, H.K., Schwing, A.G.: Xmem: Long-term video object segmentation with an atkinson-shiffrin memory model. In: European conference on computer vision. pp. 640–658. Springer (2022)
2022
-
[6]
Cheng, H.K., Tai, Y.W., Tang, C.K.: Rethinking space-time networks with im- provedmemorycoverageforefficientvideoobjectsegmentation.Advancesinneural information processing systems34, 11781–11794 (2021)
2021
-
[7]
In: European conference on computer vision
Cho, S., Lee, H., Lee, M., Park, C., Jang, S., Kim, M., Lee, S.: Tackling background distraction in video object segmentation. In: European conference on computer vision. pp. 446–462. Springer (2022)
2022
-
[8]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Ding, S., Qian, R., Dong, X., Zhang, P., Zang, Y., Cao, Y., Guo, Y., Lin, D., Wang, J.: Sam2long: Enhancing sam 2 for long video segmentation with a training- free memory tree. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 13614–13624 (2025)
2025
-
[9]
In: Stephanidis, C., Antona, M
Eger Passos, D., Jung, B.: Measuring the accuracy of inside-out tracking in xr devices using a high-precision robotic arm. In: Stephanidis, C., Antona, M. (eds.) HCI International 2020 - Posters. pp. 19–26. Springer International Publishing, Cham (2020)
2020
-
[10]
In: 2022 International Conference on Robotics and Automation (ICRA)
Huang, H., Yeung, S.K.: 360vo: Visual odometry using a single 360 camera. In: 2022 International Conference on Robotics and Automation (ICRA). pp. 5594–
2022
-
[11]
Disability and Rehabilitation: Assistive Technology16(6), 632–636 (2021)
Jost, T.A., Nelson, B., Rylander, J.: Quantitative analysis of the oculus rift s in controlled movement. Disability and Rehabilitation: Assistive Technology16(6), 632–636 (2021)
2021
-
[12]
arXiv preprint arXiv:1612.02646 (2016)
Khoreva, A., Perazzi, F., Benenson, R., Schiele, B., Sorkine-Hornung, A.: Learning video object segmentation from static images. arXiv preprint arXiv:1612.02646 (2016)
-
[13]
In: Proceedings of the IEEE/CVF international conference on computer vision
Kirillov, A., Mintun, E., Ravi, N., Mao, H., Rolland, C., Gustafson, L., Xiao, T., Whitehead, S., Berg, A.C., Lo, W.Y., et al.: Segment anything. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 4015–4026 (2023)
2023
-
[14]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Li, M., Hu, L., Xiong, Z., Zhang, B., Pan, P., Liu, D.: Recurrent dynamic embed- ding for video object segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 1332–1341 (2022)
2022
-
[15]
Advances in Neural Information Processing Systems33, 3430–3441 (2020) 16 Xiao
Liang, Y., Li, X., Jafari, N., Chen, J.: Video object segmentation with adaptive feature bank and uncertain-region refinement. Advances in Neural Information Processing Systems33, 3430–3441 (2020) 16 Xiao. Author et al
2020
-
[16]
In: Larochelle, H., Ranzato, M., Hadsell,R.,Balcan,M.F.,Lin,H.(eds.)AdvancesinNeuralInformationProcessing Systems
Liang, Y., Li, X., Jafari, N., Chen, J.: Video object segmentation with adaptive feature bank and uncertain-region refinement. In: Larochelle, H., Ranzato, M., Hadsell,R.,Balcan,M.F.,Lin,H.(eds.)AdvancesinNeuralInformationProcessing Systems. vol. 33, pp. 3430–3441. Curran Associates, Inc. (2020)
2020
-
[17]
arXiv preprint arXiv:2408.07931 (2024)
Liu, H., Zhang, E., Wu, J., Hong, M., Jin, Y.: Surgical sam 2: Real-time segment anything in surgical video by efficient frame pruning. arXiv preprint arXiv:2408.07931 (2024)
-
[18]
Decoupled Weight Decay Regularization
Loshchilov, I., Hutter, F.: Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[19]
In: European conference on computer vision
Lu, X., Wang, W., Danelljan, M., Zhou, T., Shen, J., Van Gool, L.: Video object segmentation with episodic graph memory networks. In: European conference on computer vision. pp. 661–679. Springer (2020)
2020
-
[20]
In: Proceedings of the IEEE/CVF international conference on computer vision
Mao, Y., Wang, N., Zhou, W., Li, H.: Joint inductive and transductive learning for video object segmentation. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 9670–9679 (2021)
2021
-
[21]
In: Proceedings of the Com- puter Vision and Pattern Recognition Conference
Mei, H., Zhang, P., Shou, M.Z.: Sam-i2v: Upgrading sam to support promptable video segmentation with less than 0.2% training cost. In: Proceedings of the Com- puter Vision and Pattern Recognition Conference. pp. 3417–3426 (2025)
2025
-
[22]
arXiv preprint arXiv:2509.11772 (2025)
Mendonça, D., Barros, T., Premebida, C., Nunes, U.J.: Seg2track-sam2: Sam2- based multi-object tracking and segmentation for zero-shot generalization. arXiv preprint arXiv:2509.11772 (2025)
-
[23]
In: Proceedings of the IEEE/CVF international conference on computer vision
Oh, S.W., Lee, J.Y., Xu, N., Kim, S.J.: Video object segmentation using space-time memory networks. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 9226–9235 (2019)
2019
-
[24]
Advances in neural information processing sys- tems32(2019)
Paszke, A., Gross, S., Massa, F., Lerer, A., Bradbury, J., Chanan, G., Killeen, T., Lin, Z., Gimelshein, N., Antiga, L., et al.: Pytorch: An imperative style, high- performance deep learning library. Advances in neural information processing sys- tems32(2019)
2019
-
[25]
In: European Conference on Computer Vision
Paul, M., Danelljan, M., Mayer, C., Van Gool, L.: Robust visual tracking by seg- mentation. In: European Conference on Computer Vision. pp. 571–588. Springer (2022)
2022
-
[26]
In: 2016 IEEE Conference on Computer Vision and Pattern Recog- nition (CVPR)
Perazzi, F., Pont-Tuset, J., McWilliams, B., Van Gool, L., Gross, M., Sorkine- Hornung, A.: A benchmark dataset and evaluation methodology for video object segmentation. In: 2016 IEEE Conference on Computer Vision and Pattern Recog- nition (CVPR). pp. 724–732 (2016)
2016
-
[27]
In: Proceedings of the AAAI conference on artificial intelligence
Perez, E., Strub, F., De Vries, H., Dumoulin, V., Courville, A.: Film: Visual rea- soning with a general conditioning layer. In: Proceedings of the AAAI conference on artificial intelligence. vol. 32 (2018)
2018
-
[28]
IEEE Transactions on Intelligent Transportation Systems23(10), 17271–17283 (2022)
Petrovai, A., Nedevschi, S.: Semantic cameras for 360-degree environment percep- tion in automated urban driving. IEEE Transactions on Intelligent Transportation Systems23(10), 17271–17283 (2022)
2022
-
[29]
The 2017 DAVIS Challenge on Video Object Segmentation
Pont-Tuset, J., Perazzi, F., Caelles, S., Arbeláez, P., Sorkine-Hornung, A., Van Gool, L.: The 2017 davis challenge on video object segmentation. arXiv preprint arXiv:1704.00675 (2017)
work page internal anchor Pith review arXiv 2017
-
[30]
In: 2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)
Rajič, F., Ke, L., Tai, Y.W., Tang, C.K., Danelljan, M., Yu, F.: Segment anything meets point tracking. In: 2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV). pp. 9302–9311. IEEE (2025)
2025
-
[31]
SAM 2: Segment Anything in Images and Videos
Ravi, N., Gabeur, V., Hu, Y.T., Hu, R., Ryali, C., Ma, T., Khedr, H., Rädle, R., Rolland, C., Gustafson, L., et al.: Sam 2: Segment anything in images and videos. arXiv preprint arXiv:2408.00714 (2024) PanoSAM2 17
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
Ryali, C., Hu, Y.T., Bolya, D., Wei, C., Fan, H., Huang, P.Y., Aggarwal, V., Chowdhury, A., Poursaeed, O., Hoffman, J., et al.: Hiera: A hierarchical vision transformerwithoutthebells-and-whistles.In:Internationalconferenceonmachine learning. pp. 29441–29454. PMLR (2023)
2023
-
[33]
arXiv preprint arXiv:2412.03552 (2024)
Tan, J., Yang, S., Wu, T., He, J., Guo, Y., Liu, Z., Lin, D.: Imagine360: Immersive 360 video generation from perspective anchor. arXiv preprint arXiv:2412.03552 (2024)
-
[34]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Wen, Y., Zhao, Y., Liu, Y., Jia, F., Wang, Y., Luo, C., Zhang, C., Wang, T., Sun, X., Zhang, X.: Panacea: Panoramic and controllable video generation for autonomous driving. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 6902–6912 (2024)
2024
-
[35]
arXiv preprint arXiv:2507.22792 (2025)
Xu, G., Udupa, J.K., Yu, Y., Shao, H.C., Zhao, S., Liu, W., Zhang, Y.: Seg- ment anything for video: A comprehensive review of video object segmentation and tracking from past to future. arXiv preprint arXiv:2507.22792 (2025)
-
[36]
Youtube-vos: A large-scale video object segmentation benchmark.arXiv preprint arXiv:1809.03327, 2018
Xu, N., Yang, L., Fan, Y., Yue, D., Liang, Y., Yang, J., Huang, T.: Youtube-vos: A large-scale video object segmentation benchmark. arXiv preprint arXiv:1809.03327 (2018)
-
[37]
IEEE Transactions on Pattern Analysis and Machine Intelligence (2025)
Xu, Y., Huang, H., Chen, Y., Yeung, S.K.: 360vots: Visual object tracking and segmentation in omnidirectional videos. IEEE Transactions on Pattern Analysis and Machine Intelligence (2025)
2025
-
[38]
In: European conference on computer vision
Yan, B., Jiang, Y., Sun, P., Wang, D., Yuan, Z., Luo, P., Lu, H.: Towards grand unification of object tracking. In: European conference on computer vision. pp. 733–751. Springer (2022)
2022
-
[39]
In: European Conference on Computer Vision
Yan, S., Xu, X., Zhang, R., Hong, L., Chen, W., Zhang, W., Zhang, W.: Panovos: Bridging non-panoramic and panoramic views with transformer for video segmen- tation. In: European Conference on Computer Vision. pp. 346–365. Springer (2024)
2024
-
[40]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Yang, W., Anwar, S., Park, B., Yuan, S., Sarcevic, A., Linguraru, M.G., Burd, R.S., Marsic, I.: Maps: A morphology-aware ppe segmentation framework for healthcare settings. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 4383–4391 (2025)
2025
-
[41]
In: European Conference on Computer Vision
Yang, Z., Wei, Y., Yang, Y.: Collaborative video object segmentation by foreground-background integration. In: European Conference on Computer Vision. pp. 332–348. Springer (2020)
2020
-
[42]
Advances in Neural Information Processing Systems34, 2491–2502 (2021)
Yang, Z., Wei, Y., Yang, Y.: Associating objects with transformers for video object segmentation. Advances in Neural Information Processing Systems34, 2491–2502 (2021)
2021
-
[43]
IEEE Transactions on Pattern Analysis and Machine Intelligence44(9), 4701–4712 (2021)
Yang, Z., Wei, Y., Yang, Y.: Collaborative video object segmentation by multi- scale foreground-background integration. IEEE Transactions on Pattern Analysis and Machine Intelligence44(9), 4701–4712 (2021)
2021
-
[44]
IEEE transactions on visualization and computer graphics24(4), 1671–1680 (2018)
Zhang, J., Langbehn, E., Krupke, D., Katzakis, N., Steinicke, F.: Detection thresh- olds for rotation and translation gains in 360 video-based telepresence systems. IEEE transactions on visualization and computer graphics24(4), 1671–1680 (2018)
2018
-
[45]
Person- alize segment anything model with one shot.arXiv preprint arXiv:2305.03048, 2023
Zhang, R., Jiang, Z., Guo, Z., Yan, S., Pan, J., Ma, X., Dong, H., Gao, P., Li, H.: Personalize segment anything model with one shot. arXiv preprint arXiv:2305.03048 (2023)
-
[46]
arXiv preprint arXiv:2403.16370 (2024)
Zhang, W., Liu, Y., Zheng, X., Wang, L.: Goodsam: Bridging domain and ca- pacity gaps via segment anything model for distortion-aware panoramic semantic segmentation. arXiv preprint arXiv:2403.16370 (2024)
-
[47]
arXiv preprint arXiv:2506.14271 (2025) 18 Xiao
Zhang, W., Xiao, D., Dai, A., Liu, Y., Pan, T., Wen, S., Chen, L., Wang, L.: Leader360v: The large-scale, real-world 360 video dataset for multi-task learning in diverse environment. arXiv preprint arXiv:2506.14271 (2025) 18 Xiao. Author et al
-
[48]
Zhou, Y., Sun, G., Li, Y., Fu, Y., Benini, L., Konukoglu, E.: Camsam2: Segment anything accurately in camouflaged videos. arXiv preprint arXiv:2503.19730 (2025) PanoSAM2 19 A More Details of Methodology Due to space limitations in the main paper, we provide additional explanations of the novel design within the PanoSAM2 framework using pseudocode. Sec. A....
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.