Recognition: 2 theorem links
· Lean TheoremTarot-SAM3: Training-free SAM3 for Any Referring Expression Segmentation
Pith reviewed 2026-05-10 18:06 UTC · model grok-4.3
The pith
Tarot-SAM3 turns any natural-language referring expression into reliable image masks by feeding structured prompts to SAM3 and then refining the results with DINOv3 feature comparisons.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
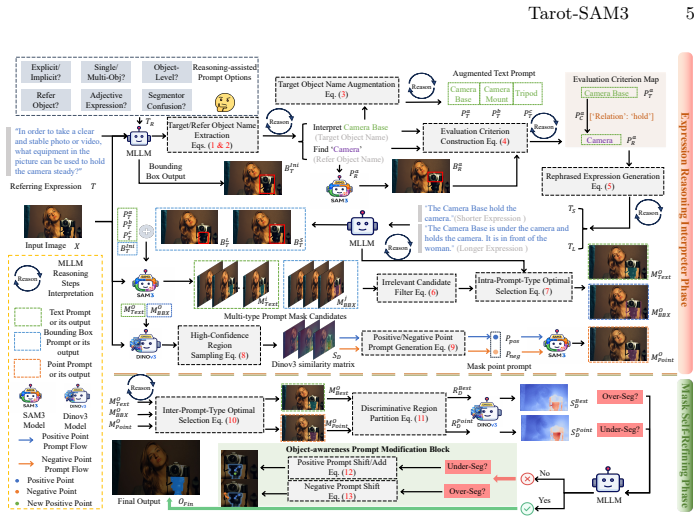
Tarot-SAM3 is a training-free framework with two phases: the Expression Reasoning Interpreter phase that applies reasoning-assisted prompt options for structured parsing and evaluation-aware rephrasing to convert arbitrary queries into robust heterogeneous prompts for SAM3 mask generation, and the Mask Self-Refining phase that selects the best mask across prompt types and performs self-refinement by leveraging DINOv3 feature relationships to compare regions and infer target affiliation, thereby correcting over- and under-segmentation.
What carries the argument
The two-phase Tarot-SAM3 process in which the Expression Reasoning Interpreter converts expressions into heterogeneous SAM3 prompts and the Mask Self-Refining stage uses DINOv3 feature comparisons to select and correct masks.
Load-bearing premise
The Expression Reasoning Interpreter can reliably turn arbitrary expressions into prompts that produce usable SAM3 initial masks, and DINOv3 feature comparisons can correctly identify region affiliation without introducing new errors.
What would settle it
A benchmark set of complex implicit expressions where the ERI-generated masks remain poor after refinement and overall accuracy falls below that of trained RES models.
Figures





read the original abstract
Referring Expression Segmentation (RES) aims to segment image regions described by natural-language expressions, serving as a bridge between vision and language understanding. Existing RES methods, however, rely heavily on large annotated datasets and are limited to either explicit or implicit expressions, hindering their ability to generalize to any referring expression. Recently, the Segment Anything Model 3 (SAM3) has shown impressive robustness in Promptable Concept Segmentation. Nonetheless, applying it to RES remains challenging: (1) SAM3 struggles with longer or implicit expressions; (2) naive coupling of SAM3 with a multimodal large language model (MLLM) makes the final results overly dependent on the MLLM's reasoning capability, without enabling refinement of SAM3's segmentation outputs. To this end, we present Tarot-SAM3, a novel training-free framework that can accurately segment from any referring expression. Specifically, Tarot-SAM3 consists of two key phases. First, the Expression Reasoning Interpreter (ERI) phase introduces reasoning-assisted prompt options to support structured expression parsing and evaluation-aware rephrasing. This transforms arbitrary queries into robust heterogeneous prompts for generating reliable masks with SAM3. Second, the Mask Self-Refining (MSR) phase selects the best mask across prompt types and performs self-refinement by leveraging rich feature relationships from DINOv3 to compare discriminative regions among ERI outputs. It then infers region affiliation to the target, thereby correcting over- and under-segmentation. Extensive experiments demonstrate that Tarot-SAM3 achieves strong performance on both explicit and implicit RES benchmarks, as well as open-world scenarios. Ablation studies further validate the effectiveness of each phase.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Tarot-SAM3, a training-free framework for referring expression segmentation (RES) applicable to any expression. It comprises two phases: the Expression Reasoning Interpreter (ERI), which parses arbitrary natural-language expressions via reasoning-assisted prompts and evaluation-aware rephrasing to produce heterogeneous inputs for SAM3 mask generation; and the Mask Self-Refining (MSR) phase, which selects the best mask across prompt variants and applies DINOv3 feature comparisons to infer target region affiliation, thereby correcting over- and under-segmentation. The central claim is that this pipeline achieves strong performance on explicit and implicit RES benchmarks as well as open-world scenarios without any training or annotated data.
Significance. If the empirical claims hold, the work is significant as a training-free, generalizable alternative to dataset-dependent RES methods and naive SAM3+MLLM couplings. It explicitly leverages pre-trained models (SAM3 for promptable segmentation and DINOv3 for feature-based refinement) in a procedural pipeline, avoiding the need for large annotated datasets or fine-tuning. This addresses a clear limitation in current RES literature regarding generalization to implicit and open-world expressions.
major comments (3)
- [Abstract] Abstract: The assertion that Tarot-SAM3 'achieves strong performance on both explicit and implicit RES benchmarks, as well as open-world scenarios' is not accompanied by any quantitative metrics, baseline comparisons, or ablation numbers. This is load-bearing for the central claim, as the effectiveness of ERI prompt generation and MSR correction cannot be assessed without these results.
- [Mask Self-Refining (MSR) phase] Mask Self-Refining (MSR) phase: The claim that DINOv3 feature comparisons reliably infer region affiliation and correct SAM3 over-/under-segmentation for implicit expressions lacks supporting error analysis, failure cases, or quantitative ablation isolating MSR's correction rate. This assumption is load-bearing because visual similarity in DINOv3 embeddings may not align with linguistic intent in complex implicit cases, potentially introducing new mismatches rather than fixing them.
- [Expression Reasoning Interpreter (ERI) phase] Expression Reasoning Interpreter (ERI) phase: The description of how 'reasoning-assisted prompt options' and 'evaluation-aware rephrasing' transform arbitrary queries into robust heterogeneous prompts for SAM3 provides no implementation details, pseudocode, or examples of the reasoning process. This is necessary to evaluate the reliability of the initial masks on which MSR depends.
minor comments (2)
- [Abstract] The acronym 'SAM3' is used before its expansion as 'Segment Anything Model 3' in the abstract; define all acronyms at first use.
- [Abstract] The abstract contains several long compound sentences that reduce readability; consider splitting for clarity.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed review of our manuscript. We have carefully addressed each major comment below, providing clarifications and committing to specific revisions that will strengthen the paper's clarity, reproducibility, and empirical support without misrepresenting our contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The assertion that Tarot-SAM3 'achieves strong performance on both explicit and implicit RES benchmarks, as well as open-world scenarios' is not accompanied by any quantitative metrics, baseline comparisons, or ablation numbers. This is load-bearing for the central claim, as the effectiveness of ERI prompt generation and MSR correction cannot be assessed without these results.
Authors: We agree that the abstract should include concrete quantitative support for the performance claims. Although the full manuscript contains extensive experimental results with metrics, baselines, and ablations, these are not summarized in the abstract. In the revised version, we will update the abstract to report key mIoU and other metrics on explicit/implicit benchmarks and open-world scenarios, along with brief baseline comparisons and ablation highlights. This will make the central claims more self-contained and evidence-based. revision: yes
-
Referee: [Mask Self-Refining (MSR) phase] Mask Self-Refining (MSR) phase: The claim that DINOv3 feature comparisons reliably infer region affiliation and correct SAM3 over-/under-segmentation for implicit expressions lacks supporting error analysis, failure cases, or quantitative ablation isolating MSR's correction rate. This assumption is load-bearing because visual similarity in DINOv3 embeddings may not align with linguistic intent in complex implicit cases, potentially introducing new mismatches rather than fixing them.
Authors: This is a valid point; while the manuscript includes ablation studies validating each phase overall, it does not provide a dedicated quantitative isolation of MSR's correction rate, error analysis, or failure cases for implicit expressions. We will revise the paper to add a focused ablation measuring MSR's improvement (e.g., percentage of over-/under-segmented masks corrected), representative failure cases with analysis of when DINOv3 similarity may diverge from linguistic intent, and a balanced discussion of limitations. This will directly address the load-bearing assumption. revision: yes
-
Referee: [Expression Reasoning Interpreter (ERI) phase] Expression Reasoning Interpreter (ERI) phase: The description of how 'reasoning-assisted prompt options' and 'evaluation-aware rephrasing' transform arbitrary queries into robust heterogeneous prompts for SAM3 provides no implementation details, pseudocode, or examples of the reasoning process. This is necessary to evaluate the reliability of the initial masks on which MSR depends.
Authors: We agree that additional implementation transparency is needed for the ERI phase to support evaluation and reproducibility. The current description is high-level; in the revised manuscript, we will include pseudocode for the full ERI pipeline, concrete examples of reasoning-assisted prompt options and evaluation-aware rephrasing applied to sample expressions (both explicit and implicit), and details on how these produce heterogeneous inputs for SAM3. This will clarify the process and allow assessment of initial mask reliability. revision: yes
Circularity Check
No circularity: training-free procedural pipeline on external models
full rationale
The paper describes a two-phase framework (ERI for prompt parsing/rephrasing and MSR for DINOv3-based mask refinement) that operates as a procedural composition of pre-trained external models (SAM3, DINOv3, MLLM). No equations, parameter fitting, self-definitional loops, or derivations appear; performance claims rest on empirical benchmark results rather than any reduction of outputs to inputs by construction. No load-bearing self-citations or ansatzes are invoked in the abstract or described method.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption SAM3 produces reliable initial masks when given heterogeneous prompts derived from expression reasoning
- domain assumption DINOv3 features allow accurate inference of region affiliation to correct over- and under-segmentation
invented entities (2)
-
Expression Reasoning Interpreter (ERI)
no independent evidence
-
Mask Self-Refining (MSR)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearTarot-SAM3 consists of two key phases. First, the Expression Reasoning Interpreter (ERI) phase... Second, the Mask Self-Refining (MSR) phase selects the best mask... leveraging DINOv3 feature relationships
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearMSR... infers region affiliation to the target, thereby correcting over- and under-segmentation
Reference graph
Works this paper leans on
-
[1]
In: European Conference on Computer Vision
An, X., Yang, K., Dai, X., Feng, Z., Deng, J.: Multi-label cluster discrimination for visual representation learning. In: European Conference on Computer Vision. pp. 428–444. Springer (2024)
2024
-
[2]
SAM 3: Segment Anything with Concepts
Carion, N., Gustafson, L., Hu, Y.T., Debnath, S., Hu, R., Suris, D., Ryali, C., Alwala,K.V.,Khedr,H.,Huang,A.,etal.:Sam3:Segmentanythingwithconcepts. arXiv preprint arXiv:2511.16719 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
In: Euro- pean Conference on Computer Vision
Chen, Y.C., Li, W.H., Sun, C., Wang, Y.C.F., Chen, C.S.: Sam4mllm: Enhance multi-modal large language model for referring expression segmentation. In: Euro- pean Conference on Computer Vision. pp. 323–340. Springer (2024)
2024
-
[4]
Chen, Y.C., Li, W.H., Sun, C., Wang, Y.C.F., Chen, C.S.: Sam4mllm: Enhance multi-modal large language model for referring expression segmentation. ArXiv abs/2409.10542(2024)
-
[5]
IEEE Transactions on Pattern Analysis and Machine Intelligence45(6), 7900–7916 (2022)
Ding, H., Liu, C., Wang, S., Jiang, X.: Vlt: Vision-language transformer and query generation for referring segmentation. IEEE Transactions on Pattern Analysis and Machine Intelligence45(6), 7900–7916 (2022)
2022
-
[6]
In: International Conference on Machine Learning (2023)
Driess, D., Xia, F., Sajjadi, M.S.M., Lynch, C., Chowdhery, A., Ichter, B., Wahid, A., Tompson, J., Vuong, Q.H., Yu, T., Huang, W., Chebotar, Y., Sermanet, P., Duckworth, D., Levine, S., Vanhoucke, V., Hausman, K., Toussaint, M., Greff, K., Zeng, A., Mordatch, I., Florence, P.R.: Palm-e: An embodied multimodal language model. In: International Conference ...
2023
-
[7]
Du, T., Li, H., Fan, Z., Zhang, J., Pan, P., Zhang, Y.: Sam-veteran: An mllm-based human-likesamagentforreasoningsegmentation.In:TheFourteenthInternational Conference on Learning Representations
-
[8]
In: European conference on computer vision
Hu, R., Rohrbach, M., Darrell, T.: Segmentation from natural language expres- sions. In: European conference on computer vision. pp. 108–124. Springer (2016)
2016
-
[9]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Hu, Y., Wang, Q., Shao, W., Xie, E., Li, Z., Han, J., Luo, P.: Beyond one-to-one: Rethinking the referring image segmentation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 4067–4077 (October 2023)
2023
-
[10]
In: Proceedings of the IEEE/CVF con- ference on computer vision and pattern recognition
Hu, Z., Feng, G., Sun, J., Zhang, L., Lu, H.: Bi-directional relationship inferring network for referring image segmentation. In: Proceedings of the IEEE/CVF con- ference on computer vision and pattern recognition. pp. 4424–4433 (2020)
2020
-
[11]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Huang, J., Xu, Z., Liu, T., Liu, Y., Han, H., Yuan, K., Li, X.: Densely connected parameter-efficient tuning for referring image segmentation. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 39, pp. 3653–3661 (2025)
2025
-
[12]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Huang, S., Hui, T., Liu, S., Li, G., Wei, Y., Han, J., Liu, L., Li, B.: Referring image segmentation via cross-modal progressive comprehension. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10488–10497 (2020)
2020
-
[13]
Jiang, C., Ding, T., Song, C., Tu, J., Yan, Z., Shao, Y., Wang, Z., Shang, Y., Han, T., Tian, Y.: Medical sam3: A foundation model for universal prompt-driven medical image segmentation. ArXivabs/2601.10880(2026) 16 Zhang. Author et al
-
[14]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Jing, Y., Kong, T., Wang, W., Wang, L., Li, L., Tan, T.: Locate then segment: A strong pipeline for referring image segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 9858–9867 (2021)
2021
-
[15]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Kim, N., Kim, D., Lan, C., Zeng, W., Kwak, S.: Restr: Convolution-free refer- ring image segmentation using transformers. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 18145–18154 (2022)
2022
-
[16]
2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp
Lai, X., Tian, Z., Chen, Y., Li, Y., Yuan, Y., Liu, S., Jia, J.: Lisa: Reasoning segmentation via large language model. 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp. 9579–9589 (2023)
2024
-
[17]
Pattern Recognition p
Li, J., Xie, Q., Gu, R., Xu, J., Liu, Y., Yu, X.: Lgd: Leveraging generative descrip- tions for zero-shot referring image segmentation. Pattern Recognition p. 112549 (2025)
2025
-
[18]
SAM3-I: Segment Anything with Instructions
Li, J., Feng, Y., Guo, Y., Huang, J., Piao, Y., Bi, Q., Zhang, M., Zhao, X., Chen, Q., Zou, S., Ji, W., Lu, H., Cheng, L.: Sam3-i: Segment anything with instructions. ArXivabs/2512.04585(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition
Li, R., Li, K., Kuo, Y.C., Shu, M., Qi, X., Shen, X., Jia, J.: Referring image segmen- tation via recurrent refinement networks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 5745–5753 (2018)
2018
-
[20]
IEEE Transactions on Pattern Analysis and Machine Intelligence45(8), 10055–10069 (2023)
Liang, C., Wang, W., Zhou, T., Miao, J., Luo, Y., Yang, Y.: Local-global context aware transformer for language-guided video segmentation. IEEE Transactions on Pattern Analysis and Machine Intelligence45(8), 10055–10069 (2023)
2023
-
[21]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition
Liang, F., Wu, B., Dai, X., Li, K., Zhao, Y., Zhang, H., Zhang, P., Vajda, P., Mar- culescu, D.: Open-vocabulary semantic segmentation with mask-adapted clip. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition. pp. 7061–7070 (2023)
2023
-
[22]
In: Proceedings of the IEEE international conference on computer vision
Liu, C., Lin, Z., Shen, X., Yang, J., Lu, X., Yuille, A.: Recurrent multimodal inter- action for referring image segmentation. In: Proceedings of the IEEE international conference on computer vision. pp. 1271–1280 (2017)
2017
-
[23]
IEEE Transactions on Pattern Analysis and Machine Intelligence44(9), 4761–4775 (2021)
Liu, S., Hui, T., Huang, S., Wei, Y., Li, B., Li, G.: Cross-modal progressive com- prehension for referring segmentation. IEEE Transactions on Pattern Analysis and Machine Intelligence44(9), 4761–4775 (2021)
2021
-
[24]
In: Proceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition
Liu, T., Li, S.: Hybrid global-local representation with augmented spatial guidance for zero-shot referring image segmentation. In: Proceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition. pp. 29634–29643 (2025)
2025
-
[25]
Liu, Y., Ma, M., Yu, X., Ding, P., Zhao, H., Sun, M., Huang, S., Wang, D.: Ssr: Enhancing depth perception in vision-language models via rationale-guided spatial reasoning. arXiv preprint arXiv:2505.12448 (2025)
-
[26]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Liu, Y., Zhang, C., Wang, Y., Wang, J., Yang, Y., Tang, Y.: Universal segmen- tation at arbitrary granularity with language instruction. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 3459– 3469 (2024)
2024
-
[27]
Liu, Y., Peng, B., Zhong, Z., Yue, Z., Lu, F., Yu, B., Jia, J.: Seg-zero: Reasoning-chain guided segmentation via cognitive reinforcement. arXiv preprint arXiv:2503.06520 (2025)
-
[28]
In: International Conference on Learning Repre- sentations (2023)
Lu, P., Bansal, H., Xia, T., Liu, J., yue Li, C., Hajishirzi, H., Cheng, H., Chang, K.W., Galley, M., Gao, J.: Mathvista: Evaluating mathematical reasoning of foun- dation models in visual contexts. In: International Conference on Learning Repre- sentations (2023)
2023
-
[29]
Tarot-SAM3 17 In: Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)
Lu, Y., Cao, J., Wu, Y., Li, B., Tang, L., Ji, Y., Wu, C., Wu, J., Zhu, W.: Rsvp: Reasoning segmentation via visual prompting and multi-modal chain-of-thought. Tarot-SAM3 17 In: Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 14699–14716 (2025)
2025
-
[30]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Mao, J., Huang, J., Toshev, A., Camburu, O., Yuille, A.L., Murphy, K.: Generation and comprehension of unambiguous object descriptions. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 11–20 (2016)
2016
-
[31]
Ni, M., Zhang, Y., Feng, K., Li, X., Guo, Y., Zuo, W.: Ref-diff: Zero-shot refer- ring image segmentation with generative models. arXiv preprint arXiv:2308.16777 (2023)
-
[32]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Qian, R., Yin, X., Dou, D.: Reasoning to attend: Try to understand how< seg> token works. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 24722–24731 (2025)
2025
-
[33]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Rasheed, H., Maaz, M., Shaji, S., Shaker, A., Khan, S., Cholakkal, H., Anwer, R.M., Xing, E., Yang, M.H., Khan, F.S.: Glamm: Pixel grounding large multimodal model. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 13009–13018 (2024)
2024
-
[34]
Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks
Ren, T., Liu, S., Zeng, A., Lin, J., Li, K., Cao, H., Chen, J., Huang, X., Chen, Y., Yan, F., et al.: Grounded sam: Assembling open-world models for diverse visual tasks. arXiv preprint arXiv:2401.14159 (2024)
work page Pith review arXiv 2024
-
[35]
Available at SSRN 5233953 (2025)
Sapkota, R., Karkee, M.: Object detection with multimodal large vision-language models: An in-depth review. Available at SSRN 5233953 (2025)
2025
-
[36]
Sim’eoni, O., Vo, H.V., Seitzer, M., Baldassarre, F., Oquab, M., Jose, C., Khalidov, V., Szafraniec, M., Yi, S., Ramamonjisoa, M., Massa, F., Haziza, D., Wehrstedt, L., Wang, J., Darcet, T., Moutakanni, T., Sentana, L., Roberts, C., Vedaldi, A., Tolan, J., Brandt, J., Couprie, C., Mairal, J., J’egou, H., Labatut, P., Bojanowski, P.: Dinov3 (2025)
2025
-
[37]
Companion Proceed- ings of the ACM on Web Conference 2025 (2025)
Song, J., Hua, Z., Zan, H., Han, Y., Peng, M.: Optimizing discriminative vision- language models for efficient multimodal intent recognition. Companion Proceed- ings of the ACM on Web Conference 2025 (2025)
2025
-
[38]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Sun, S., Li, R., Torr, P., Gu, X., Li, S.: Clip as rnn: Segment countless visual concepts without training endeavor. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 13171–13182 (2024)
2024
-
[39]
In: Findings of the Association for Computational Linguistics: EMNLP 2023
Suo, Y., Zhu, L., Yang, Y.: Text augmented spatial aware zero-shot referring im- age segmentation. In: Findings of the Association for Computational Linguistics: EMNLP 2023. pp. 1032–1043 (2023)
2023
-
[40]
arXiv preprint arXiv:2508.04655 (2025)
Wang, H., Qiao, L., Jie, Z., Huang, Z., Feng, C., Zheng, Q., Ma, L., Lan, X., Liang, X.: X-sam: From segment anything to any segmentation. arXiv preprint arXiv:2508.04655 (2025)
-
[41]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Wang, J., Ke, L.: Llm-seg: Bridging image segmentation and large language model reasoning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 1765–1774 (2024)
2024
-
[42]
In: 2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)
Wang, S., Kim, D., Taalimi, A., Sun, C., Kuo, W.: Learning visual grounding from generative vision and language model. In: 2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV). pp. 8057–8067. IEEE (2025)
2025
-
[43]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Wang, W., Yue, T., Zhang, Y., Guo, L., He, X., Wang, X., Liu, J.: Unveiling parts beyond objects: Towards finer-granularity referring expression segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 12998–13008 (2024)
2024
-
[44]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Wang, Y., Ni, J., Liu, Y., Yuan, C., Tang, Y.: Iterprime: Zero-shot referring image segmentation with iterative grad-cam refinement and primary word emphasis. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 39, pp. 8159– 8168 (2025) 18 Zhang. Author et al
2025
-
[45]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Wang, Z., Lu, Y., Li, Q., Tao, X., Guo, Y., Gong, M., Liu, T.: Cris: Clip-driven referring image segmentation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 11686–11695 (2022)
2022
-
[46]
Wei, C., Zhong, Y., Tan, H., Liu, Y., Zhao, Z., Hu, J., Yang, Y.: Hyperseg: To- wards universal visual segmentation with large language model. arXiv preprint arXiv:2411.17606 (2024)
-
[47]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Wu, J., Jiang, Y., Liu, Q., Yuan, Z., Bai, X., Bai, S.: General object foundation model for images and videos at scale. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 3783–3795 (2024)
2024
-
[48]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Xia, Z., Han, D., Han, Y., Pan, X., Song, S., Huang, G.: Gsva: Generalized segmen- tation via multimodal large language models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 3858–3869 (2024)
2024
-
[49]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Xie, Y., Yang, K., An, X., Wu, K., Zhao, Y., Deng, W., Ran, Z., Wang, Y., Feng, Z., Miles, R., et al.: Region-based cluster discrimination for visual representation learning. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 1793–1803 (2025)
2025
-
[50]
Xiong, X., Wu, Z., Lu, L., Xia, Y.: Sam3-unet: Simplified adaptation of segment anything model 3. ArXivabs/2512.01789(2025)
-
[51]
In: Proceedings of the IEEE/CVF international conference on computer vision
Xu, Z., Chen, Z., Zhang, Y., Song, Y., Wan, X., Li, G.: Bridging vision and lan- guage encoders: Parameter-efficient tuning for referring image segmentation. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 17503–17512 (2023)
2023
-
[52]
arXiv preprint arXiv:2312.17240 (2023)
Yang, S., Qu, T., Lai, X., Tian, Z., Peng, B., Liu, S., Jia, J.: Lisa++: An improved baseline for reasoning segmentation with large language model. arXiv preprint arXiv:2312.17240 (2023)
-
[53]
IEEE Transactions on Multimedia24, 3611–3623 (2021)
Yang, S., Wang, Y., Chen, K., Zeng, W., Fei, Z.: Attribute-aware feature encoding for object recognition and segmentation. IEEE Transactions on Multimedia24, 3611–3623 (2021)
2021
-
[54]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Yang, Z., Wang, J., Tang, Y., Chen, K., Zhao, H., Torr, P.H.: Lavt: Language- aware vision transformer for referring image segmentation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 18155– 18165 (2022)
2022
-
[55]
MM-REACT: Prompting ChatGPT for Multimodal Reasoning and Action
Yang, Z., Li, L., Wang, J., Lin, K., Azarnasab, E., Ahmed, F., Liu, Z., Liu, C., Zeng, M., Wang, L.: Mm-react: Prompting chatgpt for multimodal reasoning and action. ArXivabs/2303.11381(2023)
work page internal anchor Pith review arXiv 2023
-
[56]
Ye, K., You, X., Lin, J., Ji, J., Dai, P., Cao, L.: Evolving, not training: Zero- shot reasoning segmentation via evolutionary prompting. ArXivabs/2512.24702 (2025)
-
[57]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Ye, L., Rochan, M., Liu, Z., Wang, Y.: Cross-modal self-attention network for referring image segmentation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10502–10511 (2019)
2019
-
[58]
ACM Computing Surveys (2024)
Yi, Z., Ouyang, J., Xu, Z., Liu, Y., Liao, T., Luo, H., Shen, Y.: A survey on re- cent advances in llm-based multi-turn dialogue systems. ACM Computing Surveys (2024)
2024
-
[59]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Yu, L., Lin, Z., Shen, X., Yang, J., Lu, X., Bansal, M., Berg, T.L.: Mattnet: Mod- ular attention network for referring expression comprehension. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 1307–1315 (2018)
2018
-
[60]
In: European conference on computer vision
Yu, L., Poirson, P., Yang, S., Berg, A.C., Berg, T.L.: Modeling context in refer- ring expressions. In: European conference on computer vision. pp. 69–85. Springer (2016) Tarot-SAM3 19
2016
-
[61]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Yu, S., Seo, P.H., Son, J.: Zero-shot referring image segmentation with global-local context features. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 19456–19465 (2023)
2023
-
[62]
In: European Conference on Computer Vision
Yu, S., Seo, P.H., Son, J.: Pseudo-ris: Distinctive pseudo-supervision generation for referring image segmentation. In: European Conference on Computer Vision. pp. 18–36. Springer (2024)
2024
-
[63]
arXiv preprint arXiv:2406.20076 (2024)
Zhang, Y., Cheng, T., Zhu, L., Hu, R., Liu, L., Liu, H., Ran, L., Chen, X., Liu, W., Wang, X.: Evf-sam: Early vision-language fusion for text-prompted segment anything model. arXiv preprint arXiv:2406.20076 (2024)
-
[64]
In: European Conference on Computer Vision
Zhang, Z., Ma, Y., Zhang, E., Bai, X.: Psalm: Pixelwise segmentation with large multi-modal model. In: European Conference on Computer Vision. pp. 74–91. Springer (2024)
2024
-
[65]
2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp
Zheng, D., Huang, S., Zhao, L., Zhong, Y., Wang, L.: Towards learning a generalist model for embodied navigation. 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp. 13624–13634 (2023)
2024
-
[66]
arXiv preprint arXiv:2508.14153 (2025)
Zhu, L., Ouyang, B., Zhang, Y., Cheng, T., Hu, R., Shen, H., Ran, L., Chen, X., Yu, L., Liu, W., et al.: Lens: Learning to segment anything with unified reinforced reasoning. arXiv preprint arXiv:2508.14153 (2025)
-
[67]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Zhu, M., Tian, Y., Chen, H., Zhou, C., Guo, Q., Liu, Y., Yang, M., Shen, C.: Segagent: Exploring pixel understanding capabilities in mllms by imitating hu- man annotator trajectories. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 3686–3696 (2025)
2025
-
[68]
Advances in neural information processing systems36, 19769–19782 (2023)
Zou, X., Yang, J., Zhang, H., Li, F., Li, L., Wang, J., Wang, L., Gao, J., Lee, Y.J.: Segment everything everywhere all at once. Advances in neural information processing systems36, 19769–19782 (2023)
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.