Recognition: no theorem link
Unified Supervision for Walmart's Sponsored Search Retrieval via Joint Semantic Relevance and Behavioral Engagement Modeling
Pith reviewed 2026-05-10 18:10 UTC · model grok-4.3
The pith
A bi-encoder for sponsored search retrieval improves when trained primarily on semantic relevance labels from cross-encoders, using engagement only to rank among relevant items.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
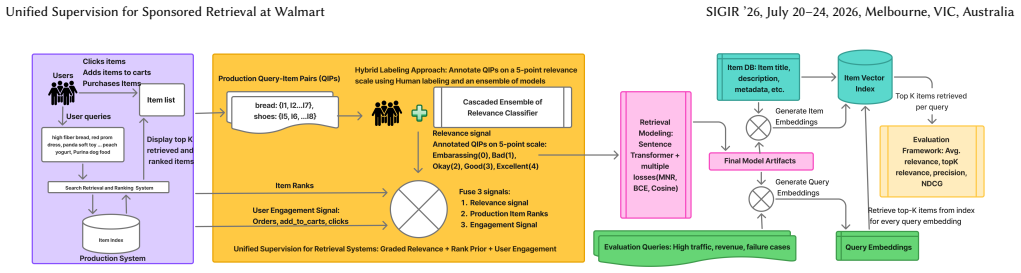
The central discovery is that a bi-encoder retriever trained using a combined supervision signal of graded semantic relevance from cross-encoder cascades, production-derived prior scores based on rank positions and cross-channel agreement, and user engagement restricted to semantically relevant items achieves better retrieval quality than the current production system, with gains in average relevance and NDCG.
What carries the argument
The mechanism of constructing a context-rich training target that prioritizes semantic relevance labels while applying engagement only as a preference signal among relevant items.
If this is right
- The new training leads to higher average relevance scores in offline evaluations.
- NDCG metrics improve consistently compared to the production retriever.
- Online A/B tests confirm gains in real traffic conditions.
- The approach mitigates issues from sparse engagement due to ad impression limitations.
Where Pith is reading between the lines
- This selective use of engagement could apply to other domains with biased interaction data.
- It suggests potential for reducing popularity bias in retrieval results.
- Extensions might involve experimenting with different ways to weight the prior scores.
Load-bearing premise
Graded relevance labels from the cascade of cross-encoder teacher models accurately capture the true semantic relevance between queries and items.
What would settle it
A comparison of human-annotated relevance scores for top results from the new model versus the production model on a diverse set of queries; failure to show improvement would challenge the central claim.
Figures


read the original abstract
Modern search systems rely on a fast first stage retriever to fetch relevant items from a massive catalog of items. Deployed search systems often use user engagement signals to supervise bi-encoder retriever training at scale, because these signals are continuously logged from real traffic and require no additional annotation effort. However, engagement is an imperfect proxy for semantic relevance. Items may receive interactions due to popularity, promotion, attractive visuals, titles, or price, despite weak query-item relevance. These limitations are further accentuated in Walmart's e-commerce sponsored search. User engagement on ad items is often structurally sparse because the frequency with which an ad is shown depends on factors beyond relevance such as whether the advertiser is currently running that ad, the outcome of the auction for available ad slots, bid competitiveness, and advertiser budget. Thus, even highly relevant query ad pairs can have limited engagement signals simply due to limited impressions. We propose a bi-encoder training framework for Walmart's sponsored search retrieval in e-commerce that uses semantic relevance as the primary supervision signal, with engagement used only as a preference signal among relevant items. Concretely, we construct a context-rich training target by combining 1. graded relevance labels from a cascade of cross-encoder teacher models, 2. a multichannel retrieval prior score derived from the rank positions and cross-channel agreement of retrieval systems running in production, and 3. user engagement applied only to semantically relevant items to refine preferences. Our approach outperforms the current production system in both offline evaluation and online AB tests, yielding consistent gains in average relevance and NDCG.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a bi-encoder training framework for Walmart's sponsored search retrieval that uses semantic relevance labels from a cascade of cross-encoder teacher models as the primary supervision signal, combines it with a multichannel retrieval prior derived from production rank positions and cross-channel agreement, and applies user engagement only as a preference signal among semantically relevant items. It claims consistent outperformance over the current production system in offline metrics such as average relevance and NDCG, as well as in online A/B tests.
Significance. If the results hold under rigorous validation, this work could advance practical retrieval systems in e-commerce by addressing the imperfections of engagement signals (e.g., sparsity due to auctions and promotions) through joint modeling with semantic relevance. The approach is notable for its focus on real-world deployment challenges in sponsored search. However, the significance depends on resolving concerns about label accuracy and independence of the prior.
major comments (3)
- Abstract and Methods: The abstract states outperformance in offline and online tests but supplies no implementation details on the exact combination formula for the context-rich training target, weighting of the three components, baseline comparisons, statistical tests, or handling of potential confounds such as data selection biases. A full methods section with these details is required to assess whether the math and data support the claims.
- Retrieval Prior: The multichannel retrieval prior score is derived directly from the rank positions of production retrieval systems. This creates a dependence on the system being improved, as the central claim rests partly on quantities generated by the current deployed model rather than fully independent external benchmarks. An ablation study removing or replacing this prior would clarify its contribution.
- Semantic Relevance Labels: Graded relevance labels from the cascade of cross-encoder teacher models are used as the primary supervision for semantic relevance, with engagement filtered to only relevant items. No human validation, inter-annotator agreement, error analysis, or correlation with true semantic judgments is reported. If these labels contain systematic noise (common in e-commerce due to visual, price, and promotional factors), the offline gains may result from distillation alone, and the engagement application inherits the same errors.
minor comments (1)
- The abstract could benefit from a brief mention of the scale of the catalog or dataset sizes to contextualize the claims.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below, indicating where revisions have been made to the manuscript.
read point-by-point responses
-
Referee: Abstract and Methods: The abstract states outperformance in offline and online tests but supplies no implementation details on the exact combination formula for the context-rich training target, weighting of the three components, baseline comparisons, statistical tests, or handling of potential confounds such as data selection biases. A full methods section with these details is required to assess whether the math and data support the claims.
Authors: We agree that additional implementation details are needed for full assessment. In the revised manuscript we have expanded the Methods section to describe the exact combination formula for the context-rich training target, the weighting approach for the three components, the baseline systems used for comparison, the statistical tests applied to the offline and online results, and our handling of potential data selection biases. revision: yes
-
Referee: Retrieval Prior: The multichannel retrieval prior score is derived directly from the rank positions of production retrieval systems. This creates a dependence on the system being improved, as the central claim rests partly on quantities generated by the current deployed model rather than fully independent external benchmarks. An ablation study removing or replacing this prior would clarify its contribution.
Authors: We acknowledge the dependence concern. The revised manuscript now includes an ablation that removes the retrieval prior component to quantify its contribution. We also clarify that the prior aggregates rank positions and agreement across multiple production channels rather than relying on a single system, though we recognize that fully external benchmarks are difficult to obtain in a proprietary e-commerce setting and discuss this limitation. revision: partial
-
Referee: Semantic Relevance Labels: Graded relevance labels from the cascade of cross-encoder teacher models are used as the primary supervision for semantic relevance, with engagement filtered to only relevant items. No human validation, inter-annotator agreement, error analysis, or correlation with true semantic judgments is reported. If these labels contain systematic noise (common in e-commerce due to visual, price, and promotional factors), the offline gains may result from distillation alone, and the engagement application inherits the same errors.
Authors: We agree that the original manuscript did not report human validation or inter-annotator agreement. The revision adds a discussion of potential label noise sources and how the joint modeling with engagement mitigates their effects, along with an ablation showing that the engagement preference signal provides gains beyond the relevance labels alone. A full human validation study was not performed. revision: partial
- Comprehensive human validation, inter-annotator agreement, and large-scale error analysis for the graded semantic relevance labels produced by the teacher models.
Circularity Check
No significant circularity detected
full rationale
The paper's training target combines graded relevance labels from cross-encoder teachers, a production-derived multichannel prior, and restricted engagement signals, then evaluates the resulting bi-encoder via independent offline NDCG/relevance metrics and online AB tests against the production baseline. No equation or derivation step reduces a claimed prediction or result to its inputs by construction, nor does any load-bearing premise collapse to a self-citation chain, fitted parameter renamed as output, or ansatz imported without external justification. The production prior functions as an auxiliary input rather than forcing equivalence between the final model and the baseline; external benchmarks remain independent of the training construction itself.
Axiom & Free-Parameter Ledger
free parameters (1)
- weights or thresholds for combining relevance labels, prior score, and engagement
axioms (2)
- domain assumption Graded relevance labels from cross-encoder cascade accurately reflect semantic relevance
- domain assumption User engagement is a valid preference signal only among semantically relevant items
Reference graph
Works this paper leans on
-
[1]
Miao Fan, Jiacheng Guo, Shuai Zhu, Shuo Miao, Mingming Sun, and Ping Li
-
[2]
InProceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining
MOBIUS: towards the next generation of query-ad matching in baidu’s sponsored search. InProceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2509–2517
-
[3]
Zhibo Fan, Hongtao Lin, Haoyu Chen, Bowen Deng, Hedi Xia, Yuke Yan, and James Li. 2025. Synergizing Implicit and Explicit User Interests: A Multi- Embedding Retrieval Framework at Pinterest. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2. 4396–4405
2025
- [4]
-
[5]
Yunzhong He, Yuxin Tian, Mengjiao Wang, Feier Chen, Licheng Yu, Mao- long Tang, Congcong Chen, Ning Zhang, Bin Kuang, and Arul Prakash. 2023. Que2engage: Embedding-based retrieval for relevant and engaging products at facebook marketplace. InCompanion Proceedings of the ACM Web Conference
2023
-
[6]
Matthew Henderson, Rami Al-Rfou, Brian Strope, Yun-Hsuan Sung, László Lukács, Ruiqi Guo, Sanjiv Kumar, Balint Miklos, and Ray Kurzweil. 2017. Ef- ficient natural language response suggestion for smart reply.arXiv preprint arXiv:1705.00652(2017)
work page Pith review arXiv 2017
- [7]
- [8]
-
[9]
Rishikesh Jha, Siddharth Subramaniyam, Ethan Benjamin, and Thrivikrama Taula
-
[10]
In2024 IEEE International Conference on Future Machine Learning and Data Science (FMLDS)
Unified Embedding Based Personalized Retrieval in Etsy Search. In2024 IEEE International Conference on Future Machine Learning and Data Science (FMLDS). IEEE, 258–264
-
[11]
Jeff Johnson, Matthijs Douze, and Hervé Jégou. 2019. Billion-scale similarity search with GPUs.IEEE Transactions on Big Data7, 3 (2019), 535–547
2019
- [12]
-
[13]
Sen Li, Fuyu Lv, Taiwei Jin, Guli Lin, Keping Yang, Xiaoyi Zeng, Xiao-Ming Wu, and Qianli Ma. 2021. Embedding-based product retrieval in taobao search. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining. 3181–3189
2021
-
[14]
Juexin Lin, Sachin Yadav, Feng Liu, Nicholas Rossi, Praveen R Suram, Satya Chem- bolu, Prijith Chandran, Hrushikesh Mohapatra, Tony Lee, Alessandro Magnani, et al. 2024. Enhancing Relevance of Embedding-based Retrieval at Walmart. In Proceedings of the 33rd ACM International Conference on Information and Knowl- edge Management. 4694–4701
2024
- [15]
-
[16]
Yuxiang Lu, Yiding Liu, Jiaxiang Liu, Yunsheng Shi, Zhengjie Huang, Shikun Feng Yu Sun, Hao Tian, Hua Wu, Shuaiqiang Wang, Dawei Yin, et al. 2022. Ernie- search: Bridging cross-encoder with dual-encoder via self on-the-fly distillation for dense passage retrieval.arXiv preprint arXiv:2205.09153(2022)
-
[17]
Ming Pang, Chunyuan Yuan, Xiaoyu He, Zheng Fang, Donghao Xie, Fanyi Qu, Xue Jiang, Changping Peng, Zhangang Lin, Zheng Luo, et al. 2025. Generative Retrieval and Alignment Model: A New Paradigm for E-commerce Retrieval. In Companion Proceedings of the ACM on Web Conference 2025. 413–421
2025
-
[18]
Nils Reimers and Iryna Gurevych. 2019. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. InProceedings of the 2019 Conference on Em- pirical Methods in Natural Language Processing. Association for Computational Linguistics. http://arxiv.org/abs/1908.10084
work page internal anchor Pith review Pith/arXiv arXiv 2019
- [19]
-
[20]
Hui Shi, Yupeng Gu, Yitong Zhou, Bo Zhao, Sicun Gao, and Jishen Zhao. 2023. Everyone’s preference changes differently: A weighted multi-interest model for retrieval. InInternational Conference on Machine Learning. PMLR, 31228–31242
2023
-
[21]
Wenhao Yu et al. 2023. Progressive Distillation for Dense Retrieval. InProceedings of the ACM Web Conference (WWW/TheWebConf)
2023
-
[22]
Jianjin Zhang, Zheng Liu, Weihao Han, Shitao Xiao, Ruicheng Zheng, Yingxia Shao, Hao Sun, Hanqing Zhu, Premkumar Srinivasan, Weiwei Deng, et al. 2022. Uni-retriever: Towards learning the unified embedding based retriever in bing sponsored search. InProceedings of the 28th ACM SIGKDD Conference on Knowl- edge Discovery and Data Mining. 4493–4501. SIGIR ’26...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.