Recognition: no theorem link
Lishu: A Real-Source Research Workbench for Elite Business Journal Search, Analysis, and Writing Support
Pith reviewed 2026-05-10 17:56 UTC · model grok-4.3
The pith
Lishu integrates UTD-24 and FT50 journal pools with public data sources to support search, analysis, and writing tasks in business research.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Lishu is both a functioning design artifact and an extensible architectural pattern for journal-pool-specific scholarly discovery and writing support. The system integrates the UTD-24 and Financial Times 50 journal pools with multiple data sources to support a broader workflow than article retrieval alone, including sensemaking tasks like identifying recent work, surfacing topical concentration, comparing themes, and converting outputs into review drafts and grant narratives.
What carries the argument
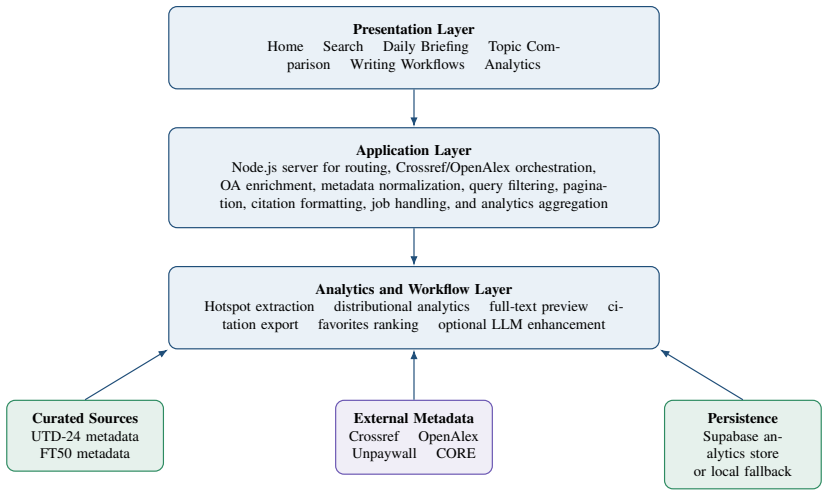
The Lishu web artifact: a modular Node.js service layer with multi-page client interface that scopes searches to the UTD-24 and FT50 pools and layers external data sources to enable extended tasks such as virtual peer review and narrative assembly.
If this is right
- Researchers can inspect topic and affiliation structures and preview open full-text excerpts directly within scoped journal searches.
- Search results convert into usable outputs such as citations, review drafts, and grant-oriented narratives.
- The lightweight Node.js design supports public deployment and optional LLM enhancement for writing assistance.
- Source transparency is preserved by combining Crossref, OpenAlex, Unpaywall, and optional CORE enrichment.
- The pattern provides a focused alternative to static directories or broad search engines for elite business scholarship.
Where Pith is reading between the lines
- The same modular pattern could be reused to build comparable workbenches for other fields that maintain curated journal lists.
- Free-tier persistence options may enable shared use within research labs for tracking literature over time.
- Emphasis on converting searches into narratives suggests the system could help address information overload in high-volume publication areas.
- Widespread use might shift how domain-specific digital infrastructure is designed in information systems and business scholarship.
Load-bearing premise
The described combination of data sources, modular architecture, and workflow features will deliver practical sensemaking value to researchers even without reported testing or comparisons to existing tools.
What would settle it
A side-by-side comparison measuring whether researchers using Lishu complete tasks like producing review drafts or grant narratives faster or with higher quality than they do with general academic search engines or journal websites.
Figures







read the original abstract
This paper presents Lishu, a deployable web artifact for searching, monitoring, and interpreting literature from elite business and management journals. The system integrates the UTD-24 and Financial Times 50 (FT50) journal pools and combines Crossref, OpenAlex, Unpaywall, and optional CORE enrichment to support a broader research workflow than article retrieval alone. In the current implementation, users can search across curated journal pools, apply multi-journal filters, preview open full-text excerpts when available, generate citations and exports, inspect topic and affiliation structure, produce review drafts, simulate virtual peer review, and assemble grant-oriented research narratives. Unlike static journal directories or general-purpose academic search engines, the artifact is explicitly scoped to high-status management outlets and is designed to support sensemaking tasks that matter to researchers, doctoral students, and lab managers: identifying recent work, surfacing topical concentration, comparing themes, and converting search output into actionable research material. Architecturally, the system emphasizes source transparency, modularity, and low-cost public deployability through a lightweight Node.js service layer, a multi-page client interface, optional large-language-model enhancement for interpretation and writing support, and a free-tier persistence path through Supabase. The paper contributes both a functioning design artifact and an extensible architectural pattern for journal-pool-specific scholarly discovery and writing support, with implications for digital research infrastructure in information systems and business scholarship.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Lishu, a deployable web-based research workbench for searching, monitoring, and interpreting literature from elite business and management journals (UTD-24 and FT50 pools). It integrates data sources including Crossref, OpenAlex, Unpaywall, and optional CORE to enable features beyond retrieval, such as multi-journal filtering, open full-text previews, citation exports, topic/affiliation analysis, review draft generation, virtual peer review simulation, and grant narrative assembly. The architecture is described as a lightweight Node.js service layer with multi-page client interface, optional LLM enhancement, source transparency, modularity, and free-tier Supabase persistence. The central contribution is framed as both a functioning design artifact and an extensible architectural pattern for journal-pool-specific scholarly discovery and writing support.
Significance. If the system exists and functions as described, it would provide a domain-specific tool that addresses a gap in business scholarship by supporting end-to-end sensemaking and writing workflows rather than isolated search. The modular, low-cost deployment pattern could serve as a template for similar specialized tools in other fields. However, the absence of any implementation artifacts, validation, or comparison data means the claimed practical value remains unverified and the significance is currently aspirational rather than demonstrated.
major comments (4)
- [Abstract] Abstract and overall manuscript: The central claim that Lishu constitutes a 'functioning design artifact' whose integrations 'support a broader research workflow' is not supported by any code, deployment URL, API handling details, or runtime evidence. Without these, the described features (e.g., open full-text preview, virtual peer review, grant narrative assembly) cannot be assessed for correctness or reliability.
- [No evaluation section present] The manuscript provides no evaluation section, usage data, usability testing, or comparison against existing tools (e.g., Google Scholar, journal-specific databases). This omission is load-bearing because the contribution explicitly rests on delivering 'practical sensemaking value' for researchers, doctoral students, and lab managers.
- [Architecture description] Architecture description (Node.js service layer, Supabase persistence, external API integrations): No details are given on handling of rate limits, data freshness, error recovery, or paywall bypass for the claimed open full-text excerpts. These are critical for the workflow features to operate as stated and constitute a gap in substantiating the 'real-source' and 'deployable' aspects.
- [Optional LLM enhancement description] The optional LLM enhancement for interpretation and writing support is mentioned but without any specification of prompts, models, safeguards against hallucination, or how it interfaces with the core data sources, leaving the 'writing support' claim unsubstantiated.
minor comments (2)
- [Abstract] The abstract and introduction could more clearly distinguish between implemented features and planned extensions to avoid overstatement of current capabilities.
- [Introduction/Features description] Terminology such as 'virtual peer review' and 'grant-oriented research narratives' would benefit from a brief operational definition or example workflow to improve clarity for readers unfamiliar with the intended use cases.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback, which identifies important gaps in substantiation. We address each major comment below and will revise the manuscript accordingly to strengthen the presentation of Lishu as a functioning design artifact.
read point-by-point responses
-
Referee: [Abstract] Abstract and overall manuscript: The central claim that Lishu constitutes a 'functioning design artifact' whose integrations 'support a broader research workflow' is not supported by any code, deployment URL, API handling details, or runtime evidence. Without these, the described features (e.g., open full-text preview, virtual peer review, grant narrative assembly) cannot be assessed for correctness or reliability.
Authors: We agree that the manuscript would benefit from direct evidence of the implementation to support the claims. In the revised version, we will add a public GitHub repository link containing the full source code along with a live deployment URL. We will also introduce a new implementation subsection that provides concrete details on the API integrations and runtime behavior, enabling readers to verify the described features including full-text previews and workflow support. revision: yes
-
Referee: [No evaluation section present] The manuscript provides no evaluation section, usage data, usability testing, or comparison against existing tools (e.g., Google Scholar, journal-specific databases). This omission is load-bearing because the contribution explicitly rests on delivering 'practical sensemaking value' for researchers, doctoral students, and lab managers.
Authors: We acknowledge that the absence of an evaluation section limits the ability to demonstrate practical sensemaking value. We will add a dedicated evaluation section that reports usage metrics from the deployed system, presents concrete example workflows for tasks such as topic analysis and grant narrative assembly, and includes a qualitative comparison against general-purpose tools like Google Scholar and journal databases. This addition will directly address the load-bearing nature of the practical contribution. revision: yes
-
Referee: [Architecture description] Architecture description (Node.js service layer, Supabase persistence, external API integrations): No details are given on handling of rate limits, data freshness, error recovery, or paywall bypass for the claimed open full-text excerpts. These are critical for the workflow features to operate as stated and constitute a gap in substantiating the 'real-source' and 'deployable' aspects.
Authors: We will expand the architecture section to include the requested operational details. The revision will describe rate-limit handling via exponential backoff and request queuing, data freshness through scheduled daily synchronization jobs, error recovery with retry logic and graceful degradation, and clarification that open full-text excerpts are sourced exclusively from legal open-access providers (Unpaywall and CORE) without any paywall bypass mechanisms. These additions will better substantiate the real-source and deployable claims. revision: yes
-
Referee: [Optional LLM enhancement description] The optional LLM enhancement for interpretation and writing support is mentioned but without any specification of prompts, models, safeguards against hallucination, or how it interfaces with the core data sources, leaving the 'writing support' claim unsubstantiated.
Authors: We agree that the LLM component requires more precise specification. In the revised manuscript, we will name the models used (e.g., GPT-4o), provide representative prompts in a new appendix, explain the interface layer that grounds LLM outputs in retrieved literature data, and detail safeguards such as explicit grounding instructions, user confirmation steps, and hallucination-mitigation prompts. This will substantiate the writing-support functionality. revision: yes
Circularity Check
No circularity: purely descriptive system design with no derivations or predictions
full rationale
The paper presents a descriptive account of a web-based research workbench artifact, its features, data integrations, and Node.js/Supabase architecture. It contains no equations, quantitative predictions, fitted parameters, first-principles derivations, or load-bearing self-citations that reduce to the paper's own inputs. Claims about functionality are asserted at the level of design description rather than derived results, so no circular reduction is possible or present.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Crossref. 2026. ``REST API Documentation.'' Available at https://www.crossref.org/documentation/retrieve-metadata/rest-api/
2026
-
[2]
CORE. 2026. ``CORE API Documentation.'' Available at https://core.ac.uk/documentation/api
2026
-
[3]
Bakkalbasi, N., Bauer, K., Glover, J., and Wang, L. 2006. ``Three Options for Citation Tracking: Google Scholar, Scopus and Web of Science,'' Biomedical Digital Libraries (3:1), Article 7
2006
-
[4]
Chen, C. 2006. ``CiteSpace II: Detecting and Visualizing Emerging Trends and Transient Patterns in Scientific Literature,'' Journal of the American Society for Information Science and Technology (57:3), pp. 359--377
2006
-
[5]
Financial Times 50 journal source page used in the current artifact. 2026. Available at https://gsb.hse.ru/en/financialtimesfifty
2026
-
[6]
E., Pitsouni, E
Falagas, M. E., Pitsouni, E. I., Malietzis, G. A., and Pappas, G. 2008. ``Comparison of PubMed, Scopus, Web of Science, and Google Scholar: Strengths and Weaknesses,'' The FASEB Journal (22:2), pp. 338--342
2008
-
[7]
Gregor, S., and Hevner, A. R. 2013. ``Positioning and Presenting Design Science Research for Maximum Impact,'' MIS Quarterly (37:2), pp. 337--355
2013
-
[8]
Gusenbauer, M. 2022. ``Search Where You Will Find Most: Comparing the Disciplinary Coverage of 56 Bibliographic Databases,'' Scientometrics (127:5), pp. 2683--2745
2022
-
[9]
Harzing, A.-W., and Alakangas, S. 2016. ``Google Scholar, Scopus and the Web of Science: A Longitudinal and Cross-Disciplinary Comparison,'' Scientometrics (106:2), pp. 787--804
2016
-
[10]
R., March, S
Hevner, A. R., March, S. T., Park, J., and Ram, S. 2004. ``Design Science in Information Systems Research,'' MIS Quarterly (28:1), pp. 75--105
2004
-
[11]
T., and Smith, G
March, S. T., and Smith, G. F. 1995. ``Design and Natural Science Research on Information Technology,'' Decision Support Systems (15:4), pp. 251--266
1995
-
[12]
Martín-Martín, A., Orduna-Malea, E., Thelwall, M., and Delgado López-Cózar, E. 2018. ``Google Scholar, Web of Science, and Scopus: A Systematic Comparison of Citations in 252 Subject Categories,'' Journal of Informetrics (12:4), pp. 1160--1177
2018
-
[13]
OpenAlex. 2026. ``API Documentation.'' Available at https://docs.openalex.org/
2026
-
[14]
Render. 2026. ``Documentation.'' Available at https://render.com/docs
2026
-
[15]
Supabase. 2026. ``Documentation.'' Available at https://supabase.com/docs
2026
-
[16]
Unpaywall. 2026. ``Support and Integration Documentation.'' Available at https://support.unpaywall.org/support/solutions
2026
-
[17]
UTD Top 100 Business School Research Rankings. 2026. ``Journal List and Methodology Materials.'' Available at https://jsom.utdallas.edu/the-utd-top-100-business-school-research-rankings/
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.