Recognition: no theorem link
Pruning Extensions and Efficiency Trade-Offs for Sustainable Time Series Classification
Pith reviewed 2026-05-10 18:11 UTC · model grok-4.3
The pith
A theoretically bounded pruning method applied to hybrid time series classifiers cuts energy use by up to 80 percent with under 5 percent accuracy loss.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
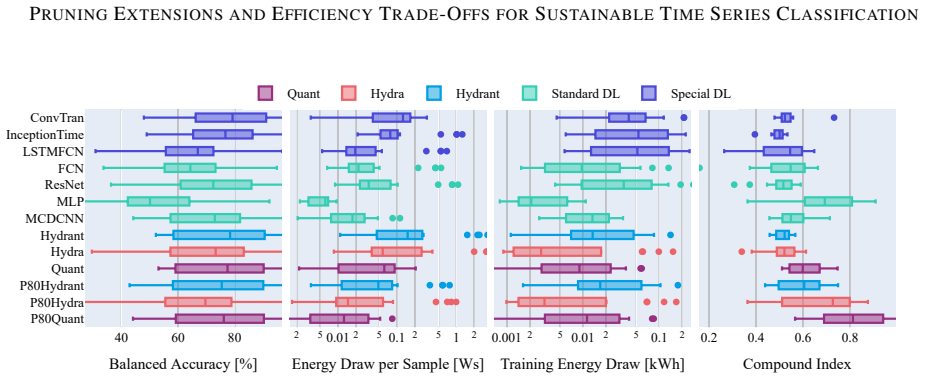
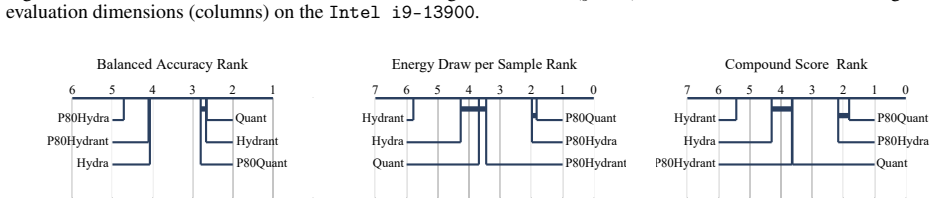
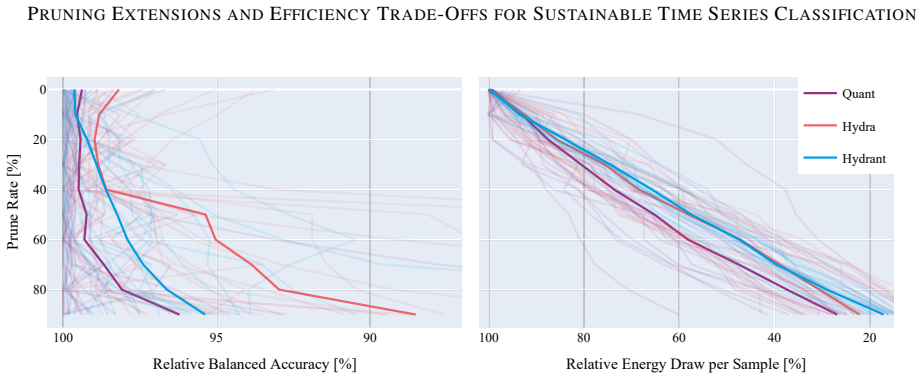
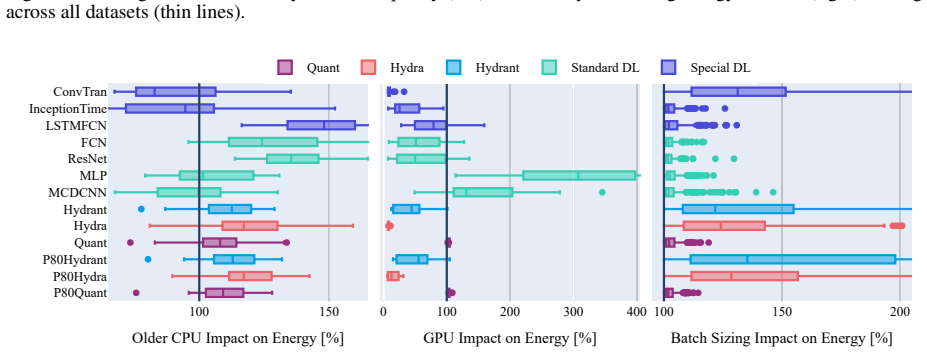
A theoretically bounded pruning strategy can be extended to leading hybrid time series classifiers including Hydra and Quant, as well as to the new combined model Hydrant. When applied across 20 MONSTER datasets and three hardware platforms, the approach reduces energy consumption by up to 80 percent while incurring less than 5 percent accuracy loss in most cases, advancing reproducible and energy-aware practice in time series classification.
What carries the argument
The theoretically bounded pruning strategy, which removes parts of hybrid classifier architectures while preserving most predictive performance.
If this is right
- Hybrid TSC models can be made substantially more energy efficient through bounded pruning without major performance penalties.
- A single pruning technique works across multiple related classifier families and compute environments.
- Sustainable TSC practice requires joint reporting of accuracy and energy metrics rather than accuracy alone.
- The Hydrant architecture provides a flexible base for further efficiency improvements in time series tasks.
Where Pith is reading between the lines
- Similar pruning ideas could be tested on non-hybrid time series models or other sequential data tasks to check wider applicability.
- Energy measurements on additional hardware types might reveal whether the 80 percent savings hold under different power constraints.
- Integrating the pruning step into automated model selection pipelines could help practitioners balance accuracy and power use more easily.
Load-bearing premise
The pruning method transfers to the tested hybrid models and hardware without hidden costs or dataset-specific biases that would change the reported energy-accuracy trade-offs.
What would settle it
Running the same pruned models on a fresh set of time series datasets or hardware where energy savings exceed 5 percent accuracy drop or produce unexpected runtime overheads would falsify the main result.
Figures

read the original abstract
Time series classification (TSC) enables important use cases, however lacks a unified understanding of performance trade-offs across models, datasets, and hardware. While resource awareness has grown in the field, TSC methods have not yet been rigorously evaluated for energy efficiency. This paper introduces a holistic evaluation framework that explicitly explores the balance of predictive performance and resource consumption in TSC. To boost efficiency, we apply a theoretically bounded pruning strategy to leading hybrid classifiers - Hydra and Quant - and present Hydrant, a novel, prunable combination of both. With over 4000 experimental configurations across 20 MONSTER datasets, 13 methods, and three compute setups, we systematically analyze how model design, hyperparameters, and hardware choices affect practical TSC performance. Our results showcase that pruning can significantly reduce energy consumption by up to 80% while maintaining competitive predictive quality, usually costing the model less than 5% of accuracy. The proposed methodology, experimental results, and accompanying software advance TSC toward sustainable and reproducible practice.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a holistic evaluation framework for time series classification (TSC) that balances predictive performance against energy consumption across models, datasets, and hardware. It applies a theoretically bounded pruning strategy to the hybrid classifiers Hydra and Quant, introduces the new prunable model Hydrant as their combination, and reports results from over 4000 experimental configurations on 20 MONSTER datasets using 13 methods and three compute setups. The central empirical claim is that this pruning reduces energy consumption by up to 80% while incurring less than 5% accuracy loss in most cases, supported by accompanying open software for reproducibility.
Significance. If the energy-accuracy trade-offs hold under rigorous measurement, the work provides a valuable empirical foundation for sustainable TSC practice, including a new hybrid architecture and extensive cross-hardware comparisons that go beyond typical accuracy-only benchmarks. The scale of the experimental campaign (4000+ configurations) and release of software are clear strengths that could enable follow-on reproducible research in resource-aware time series methods.
major comments (2)
- [§4 and §5] §4 (Experimental Setup) and §5 (Results): The claim that pruning transfers to Hydra, Quant, and Hydrant without hidden overheads requires explicit confirmation that wall-clock energy measurements on the three hardware platforms account for any additional runtime costs introduced by the pruning implementation itself; if the theoretical bound only constrains parameter count or FLOPs (rather than measured joules), the reported 80% savings may not generalize.
- [Table 2] Table 2 (or equivalent accuracy-energy summary table): The statement that accuracy cost is 'usually less than 5%' across 4000+ configurations needs accompanying statistical tests (e.g., paired t-tests or confidence intervals per dataset/hardware) rather than aggregate reporting, as dataset-specific biases could undermine the cross-setup generalization.
minor comments (2)
- [§3] The abstract and §3 should clarify the exact definition of the 'theoretically bounded pruning strategy' (e.g., which norm or sparsity constraint is used) to allow readers to assess its applicability to the hybrid architectures without re-deriving it.
- [Figure 3] Figure 3 (energy vs. accuracy plots): Axis scales and legend clarity could be improved to distinguish the three hardware setups more distinctly, especially when overlaying pruned vs. unpruned variants.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which has helped us improve the clarity and rigor of our work. We provide detailed responses to each major comment below.
read point-by-point responses
-
Referee: [§4 and §5] §4 (Experimental Setup) and §5 (Results): The claim that pruning transfers to Hydra, Quant, and Hydrant without hidden overheads requires explicit confirmation that wall-clock energy measurements on the three hardware platforms account for any additional runtime costs introduced by the pruning implementation itself; if the theoretical bound only constrains parameter count or FLOPs (rather than measured joules), the reported 80% savings may not generalize.
Authors: We appreciate this point. Our energy consumption figures are derived from direct measurements of wall-clock execution time multiplied by the hardware's power consumption on each of the three platforms. These real-world measurements necessarily incorporate any additional runtime costs associated with the pruning implementation. The theoretical bounds on pruning are used to determine safe pruning ratios, but the savings claims are based on empirical joule estimates, not theoretical proxies. We will add an explicit statement in Section 4 to confirm this and describe the measurement methodology in more detail. revision: yes
-
Referee: [Table 2] Table 2 (or equivalent accuracy-energy summary table): The statement that accuracy cost is 'usually less than 5%' across 4000+ configurations needs accompanying statistical tests (e.g., paired t-tests or confidence intervals per dataset/hardware) rather than aggregate reporting, as dataset-specific biases could undermine the cross-setup generalization.
Authors: The referee is correct that aggregate statistics can obscure important variations. To address this, we will revise the presentation of results to include statistical tests. Specifically, we plan to report 95% confidence intervals for the accuracy loss per dataset and hardware configuration, along with paired t-test results comparing pruned and unpruned models. This will provide stronger evidence that the accuracy cost is generally below 5% and help identify any outlier cases. The revision will be incorporated in the updated manuscript. revision: yes
Circularity Check
No circularity: claims rest on empirical measurements, not self-referential derivations
full rationale
The paper presents a holistic experimental framework evaluating pruning on hybrid TSC models (Hydra, Quant, Hydrant) across 4000+ configurations on 20 datasets and three hardware setups. Central results (up to 80% energy reduction with <5% accuracy cost) are reported as direct experimental outcomes rather than predictions derived from equations or parameters fitted within the same study. No self-definitional steps, fitted-input predictions, or load-bearing self-citation chains appear in the derivation of the main claims; the theoretically bounded pruning is applied as an external strategy and validated empirically. The work is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Negar Alizadeh and Fernando Castor. “Green AI: a Preliminary Empirical Study on Energy Consumption in DL Models Across Different Runtime Infrastructures”. In:International Conference on AI Engineering - Software Engineering for AI. Lisbon, Portugal, 2024, pp. 134–139.ISBN: 9798400705915.DOI: 10.1145/3644815. 3644967
-
[2]
Joint Leaf-Refinement and Ensemble Pruning through L1 Regu- larization
Sebastian Buschjäger and Katharina Morik. “Joint Leaf-Refinement and Ensemble Pruning through L1 Regu- larization”. In:Data Mining and Knowledge Discovery37.3 (2023), pp. 1230–1261.ISSN: 1573-756X.DOI: 10.1007/s10618-023-00921-z
-
[3]
Realization of Random Forest for Real-Time Evaluation through Tree Framing
Sebastian Buschjäger et al. “Realization of Random Forest for Real-Time Evaluation through Tree Framing”. In: International Conference on Data Mining. 2018.DOI:10.1109/ICDM.2018.00017
-
[4]
Bottom-up and top-down: Predicting personality with psycholinguistic and language model features,
Nestor Cabello et al. “Fast and Accurate Time Series Classification Through Supervised Interval Search”. In: International Conference on Data Mining. 2020, pp. 948–953.DOI:10.1109/ICDM50108.2020.00107
-
[5]
Shaowu Chen, Weize Sun, Lei Huang, et al. “POCKET: Pruning Random Convolution Kernels for Time Series Classification from a Feature Selection Perspective”. In:Knowledge-Based Systems300 (2024).DOI: 10.1016/j.knosys.2024.112253
-
[6]
MONSTER: Monash Scalable Time Series Evaluation Repository
Angus Dempster, Navid Mohammadi Foumani, Chang Wei Tan, et al. “MONSTER: Monash Scalable Time Series Evaluation Repository”. In:Journal of Data-Centric Machine Learning Research2 (15 2025).URL: https://openreview.net/forum?id=XauSqSfZfc
2025
-
[7]
Angus Dempster, François Petitjean, and Geoffrey I. Webb. “ROCKET: exceptionally fast and accurate time series classification using random convolutional kernels”. In:Data Mining and Knowledge Discovery34.5 (2020), pp. 1454–1495.ISSN: 1573-756X.DOI:10.1007/s10618-020-00701-z
-
[8]
Hydra: competing convolutional kernels for fast and accurate time series classification
Angus Dempster, Daniel F. Schmidt, and Geoffrey I. Webb. “Hydra: competing convolutional kernels for fast and accurate time series classification”. In:Data Mining and Knowledge Discovery37.5 (2023), pp. 1779–1805. ISSN: 1573-756X.DOI:10.1007/s10618-023-00939-3
-
[9]
MiniRocket: A Very Fast (Almost) Deterministic Transform for Time Series Classification
Angus Dempster, Daniel F. Schmidt, and Geoffrey I. Webb. “MiniRocket: A Very Fast (Almost) Deterministic Transform for Time Series Classification”. In:Conference on Knowledge Discovery & Data Mining. 2021, pp. 248–257.ISBN: 978-1-4503-8332-5.DOI:10.1145/3447548.3467231
-
[10]
quant: a minimalist interval method for time series classification
Angus Dempster, Daniel F. Schmidt, and Geoffrey I. Webb. “quant: a minimalist interval method for time series classification”. In:Data Mining and Knowledge Discovery38.4 (2024), pp. 2377–2402.ISSN: 1573-756X.DOI: 10.1007/s10618-024-01036-9
-
[11]
Highly Scalable Time Series Classification for Very Large Datasets
Angus Dempster, Chang Wei Tan, Lynn Miller, et al. “Highly Scalable Time Series Classification for Very Large Datasets”. In:Advanced Analytics and Learning on Temporal Data. 2025, pp. 80–95.ISBN: 978-3-031-77066-1. DOI:10.1007/978-3-031-77066-1_5
-
[12]
Statistical Comparisons of Classifiers over Multiple Data Sets
Janez Demšar. “Statistical Comparisons of Classifiers over Multiple Data Sets”. In:Journal of Machine Learning Research7.1 (2006), pp. 1–30.URL:http://jmlr.org/papers/v7/demsar06a.html
2006
-
[13]
Beyond Sleep Staging: Advancing End-to-End Event Scoring in Sleep Medicine
Sarah Dietz-Terjung, Matthias Jakobs, Chiara Labeit, et al. “Beyond Sleep Staging: Advancing End-to-End Event Scoring in Sleep Medicine”. DE. In:Pneumologie79.S 01 (2025).ISSN: 0934-8387.DOI: 10.1055/s- 0045-1804722
work page doi:10.1055/s- 2025
-
[14]
Time Series Classification: A review of Algorithms and Implementations
Johann Faouzi. “Time Series Classification: A review of Algorithms and Implementations”. In:Time Series Analysis - Recent Advances, New Perspectives and Applications. IntechOpen, 2024, p. 298.DOI: 10.5772/ intechopen.1004810. (Visited on 01/26/2026)
2024
-
[15]
Deep learning for time series classification: a review
Hassan Ismail Fawaz, Germain Forestier, Jonathan Weber, et al. “Deep learning for time series classification: a review”. In:Data Mining and Knowledge Discovery33.4 (2019), pp. 917–963.DOI: 10.1007/s10618-019- 00619-1
-
[16]
Raphael Fischer. “Advancing the Sustainability of Machine Learning and Artificial Intelligence via Labeling and Meta-Learning”. PhD thesis. TU Dortmund University, 2025.DOI:10.17877/DE290R-25716
-
[17]
Raphael Fischer.Ground-Truthing AI Energy Consumption: Validating CodeCarbon Against External Measure- ments. 2025.DOI:10.48550/arXiv.2509.22092. 10 PRUNINGEXTENSIONS ANDEFFICIENCYTRADE-OFFS FORSUSTAINABLETIMESERIESCLASSIFICATION
-
[18]
Towards More Sustainable and Trustworthy Reporting in Machine Learning
Raphael Fischer, Thomas Liebig, and Katharina Morik. “Towards More Sustainable and Trustworthy Reporting in Machine Learning”. In:Data Mining and Knowledge Discovery(2024).ISSN: 1573-756X.DOI: 10.1007/ s10618-024-01020-3
2024
-
[19]
AutoXPCR: Automated Multi-Objective Model Selection for Time Series Forecasting
Raphael Fischer and Amal Saadallah. “AutoXPCR: Automated Multi-Objective Model Selection for Time Series Forecasting”. In:Conference on Knowledge Discovery and Data Mining. 2024, pp. 806–815.ISBN: 979-8-4007-0490-1.DOI:10.1145/3637528.3672057
-
[20]
No Cloud on the Horizon: Probabilistic Gap Filling in Satellite Image Series
Raphael Fischer et al. “No Cloud on the Horizon: Probabilistic Gap Filling in Satellite Image Series”. In: International Conference on Data Science and Advanced Analytics (DSAA). 2020, pp. 546–555.DOI: 10.1109/ DSAA49011.2020.00069
-
[21]
Improving position encoding of transformers for multivariate time series classification
Navid Mohammadi Foumani et al. “Improving position encoding of transformers for multivariate time series classification”. In:Data Mining and Knowledge Discovery38.1 (2024), pp. 22–48.ISSN: 1573-756X.DOI: 10.1007/s10618-023-00948-2
-
[22]
InceptionTime: Finding AlexNet for time series classification
Hassan Ismail Fawaz, Benjamin Lucas, Germain Forestier, et al. “InceptionTime: Finding AlexNet for time series classification”. en. In:Data Mining and Knowledge Discovery34.6 (2020), pp. 1936–1962.ISSN: 1573-756X. DOI:10.1007/s10618-020-00710-y. (Visited on 01/26/2026)
-
[23]
LSTM Fully Convolutional Networks for Time Series Classification
Fazle Karim et al. “LSTM Fully Convolutional Networks for Time Series Classification”. In:IEEE Access6 (2018), pp. 1662–1669.ISSN: 2169-3536.DOI:10.1109/access.2017.2779939
-
[24]
Lift what you can: green online learning with heterogeneous ensembles
Kirsten Köbschall et al. “Lift what you can: green online learning with heterogeneous ensembles”. In:Data Mining and Knowledge Discovery40.3 (Mar. 2026), p. 32.ISSN: 1573-756X.DOI: 10.1007/s10618-026- 01200-3.URL:https://doi.org/10.1007/s10618-026-01200-3
-
[25]
Pruning vs Quantization: Which is Better?
Andrey Kuzmin et al. “Pruning vs Quantization: Which is Better?” In:Advances in Neural Information Processing Systems. V ol. 36. 2023, pp. 62414–62427.URL:https://dl.acm.org/doi/10.5555/3666122.3668847
-
[26]
2019.DOI:10.48550/arXiv.1909.07872
Markus Löning, Anthony Bagnall, Sajaysurya Ganesh, et al.sktime: A Unified Interface for Machine Learning with Time Series. 2019.DOI:10.48550/arXiv.1909.07872
-
[27]
2025.DOI:10.48550/arXiv.2512.06666
Urav Maniar.The Meta-Learning Gap: Combining Hydra and Quant for Large-Scale Time Series Classification. 2025.DOI:10.48550/arXiv.2512.06666
-
[28]
HIVE-COTE 2.0: A new meta ensemble for time series classification
Matthew Middlehurst, James Large, Michael Flynn, et al. “HIVE-COTE 2.0: A new meta ensemble for time series classification”. In:Machine Learning110.11–12 (2021), pp. 3211–3243.ISSN: 1573-0565.DOI: 10.1007/ s10994-021-06057-9
2021
-
[29]
Scikit-learn: Machine Learning in Python
Fabian Pedregosa, Gaël Varoquaux, Alexandre Gramfort, et al. “Scikit-learn: Machine Learning in Python”. In:Journal of Machine Learning Research (JMLR)12.85 (2011), pp. 2825–2830.URL: http://jmlr.org/ papers/v12/pedregosa11a.html
2011
-
[30]
Temporal Convolutional Neural Network for the Classification of Satellite Image Time Series
Charlotte Pelletier, Geoffrey I. Webb, and François Petitjean. “Temporal Convolutional Neural Network for the Classification of Satellite Image Time Series”. In:Remote Sensing11.5 (2019), p. 523.ISSN: 2072-4292.DOI: 10.3390/rs11050523
-
[31]
2022.DOI:10.48550/arXiv.2203.03445
Hojjat Salehinejad, Yang Wang, Yuanhao Yu, et al.S-Rocket: Selective Random Convolution Kernels for Time Series Classification. 2022.DOI:10.48550/arXiv.2203.03445
-
[32]
Roy Schwartz et al. “Green AI”. In:Communications of the ACM63.12 (2020), pp. 54–63.ISSN: 0001-0782. DOI:10.1145/3381831
-
[33]
Chang Wei Tan et al. “MultiRocket: multiple pooling operators and transformations for fast and effective time series classification”. In:Data Mining and Knowledge Discovery36.5 (2022), pp. 1623–1646.ISSN: 1573-756X. DOI:10.1007/s10618-022-00844-1
-
[34]
Towards Green Automated Machine Learning: Status Quo and Future Directions
Tanja Tornede, Alexander Tornede, Jonas Hanselle, et al. “Towards Green Automated Machine Learning: Status Quo and Future Directions”. In:Journal of Artificial Intelligence Research77 (2023), pp. 427–457.DOI: 10.1613/JAIR.1.14340
-
[35]
Gonzalo Uribarri et al. “Detach-ROCKET: Sequential Feature Selection for Time Series Classification with Random Convolutional Kernels”. In:Data Mining and Knowledge Discovery38.6 (2024), pp. 3922–3947.DOI: 10.1007/s10618-024-01062-7
-
[36]
Hype, Sustainability, and the Price of the Bigger-is- Better Paradigm in AI
Gael Varoquaux, Sasha Luccioni, and Meredith Whittaker. “Hype, Sustainability, and the Price of the Bigger-is- Better Paradigm in AI”. In:Conference on Fairness, Accountability and Transparency. 2025, pp. 61–75.ISBN: 9798400714825.DOI:10.1145/3715275.3732006
-
[37]
2017 Time series classification from scratch with deep neural networks: A strong baseline
Zhiguang Wang, Weizhong Yan, and Tim Oates. “Time series classification from scratch with deep neural networks: A strong baseline”. In:International Joint Conference on Neural Networks. 2017, pp. 1578–1585. DOI:10.1109/IJCNN.2017.7966039. (Visited on 02/18/2026)
-
[38]
The Lack of A Priori Distinctions Between Learning Algorithms
David H. Wolpert. “The Lack of A Priori Distinctions Between Learning Algorithms”. In:Neural Computation 8.7 (1996), pp. 1341–1390.DOI:10.1162/neco.1996.8.7.1341. 11 PRUNINGEXTENSIONS ANDEFFICIENCYTRADE-OFFS FORSUSTAINABLETIMESERIESCLASSIFICATION
-
[39]
Sustainable AI: AI for Sustainability and the Sustainability of AI
Aimee van Wynsberghe. “Sustainable AI: AI for Sustainability and the Sustainability of AI”. In:AI and Ethics 1.3 (2021), pp. 213–218.ISSN: 2730-5961.DOI:10.1007/s43681-021-00043-6
-
[40]
Convolutional Neural Networks for Time Series Classification
Bendong Zhao, Huanzhang Lu, Shangfeng Chen, et al. “Convolutional Neural Networks for Time Series Classification”. In:Journal of Systems Engineering and Electronics28.1 (2017), pp. 162–169.DOI: 10.21629/ JSEE.2017.01.18
2017
-
[41]
Time Series Classification Using Multi-Channels Deep Convolutional Neural Networks
Yi Zheng, Qi Liu, Enhong Chen, et al. “Time Series Classification Using Multi-Channels Deep Convolutional Neural Networks”. en. In:Web-Age Information Management. 2014, pp. 298–310.ISBN: 978-3-319-08010-9. DOI:10.1007/978-3-319-08010-9_33. 12
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.