Recognition: 2 theorem links
· Lean TheoremMONETA: Multimodal Industry Classification through Geographic Information with Multi Agent Systems
Pith reviewed 2026-05-10 18:25 UTC · model grok-4.3
The pith
Multimodal models assign NACE industry labels to companies using websites, maps, and satellite images without training data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MONETA is the first multimodal benchmark for industry classification that pairs text sources (company websites, Wikipedia, Wikidata) with geospatial sources (OpenStreetMap, satellite imagery) across 1,000 European businesses and 20 NACE labels. A training-free baseline using multimodal large language models achieves 62.10 percent accuracy with open-source models and 74.10 percent with closed-source models. Accuracy rises by up to 22.80 percent when multi-turn design, context enrichment, and classification explanations are combined.
What carries the argument
The MONETA benchmark dataset together with multi-turn prompting of multimodal large language models that jointly process text and image inputs to predict NACE codes.
If this is right
- Existing public text and geospatial data can substitute for manual expert verification on industry classification tasks.
- Performance gains come from interaction design rather than model retraining or new labels.
- The released dataset and guidelines support testing of future multimodal models on the same task.
- The approach scales to updates in classification schemes without repeating large data collection efforts.
- Geospatial signals complement text when company descriptions are sparse or ambiguous.
Where Pith is reading between the lines
- If the same signals work outside Europe, public registers could adopt automated labeling at lower cost.
- The same multimodal setup could extend to product or risk classification where location data is available.
- Satellite imagery may add value mainly for companies whose websites or Wikipedia entries are minimal.
- Errors that persist after multi-turn prompting would point to gaps in current open geospatial data coverage.
Load-bearing premise
Readily available multimodal resources already contain enough accurate signals to match expert NACE labels without new labeled data collection.
What would settle it
A manual re-audit of the 1,000 companies in which expert NACE labels diverge from the best multi-turn model outputs on more than 30 percent of cases.
Figures











read the original abstract
Industry classification schemes are integral parts of public and corporate databases as they classify businesses based on economic activity. Due to the size of the company registers, manual annotation is costly, and fine-tuning models with every update in industry classification schemes requires significant data collection. We replicate the manual expert verification by using existing or easily retrievable multimodal resources for industry classification. We present MONETA, the first multimodal industry classification benchmark with text (Website, Wikipedia, Wikidata) and geospatial sources (OpenStreetMap and satellite imagery). Our dataset enlists 1,000 businesses in Europe with 20 economic activity labels according to EU guidelines (NACE). Our training-free baseline reaches 62.10% and 74.10% with open and closed-source Multimodal Large Language Models (MLLM). We observe an increase of up to 22.80% with the combination of multi-turn design, context enrichment, and classification explanations. We will release our dataset and the enhanced guidelines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces MONETA, the first multimodal benchmark for NACE industry classification comprising 1,000 European businesses annotated with 20 economic activity classes. It uses text sources (company websites, Wikipedia, Wikidata) and geospatial data (OpenStreetMap, satellite imagery) in a training-free setting with open- and closed-source MLLMs, reporting baseline accuracies of 62.10% and 74.10% respectively, and relative gains of up to 22.80% from multi-turn design, context enrichment, and explanatory prompts. The central claim is that these readily available multimodal resources suffice to replicate manual expert verification without new labeled data collection.
Significance. If validated, MONETA would supply a reusable benchmark and scalable, annotation-light approach to industry classification, directly addressing the cost of maintaining large company registers under evolving NACE schemes. The planned release of the dataset and enhanced guidelines strengthens its utility for the community. The work's empirical focus on real-world multimodal signals is timely for applied AI in economics, though its impact hinges on demonstrating that performance derives from genuine multimodal integration rather than text alone.
major comments (3)
- [Dataset Construction] Dataset section: The 1,000 NACE labels are presented as expert annotations replicating manual verification, yet no details are given on label provenance, annotation protocol, or inter-annotator agreement. This information is required to substantiate the claim that the multimodal pipeline matches expert performance.
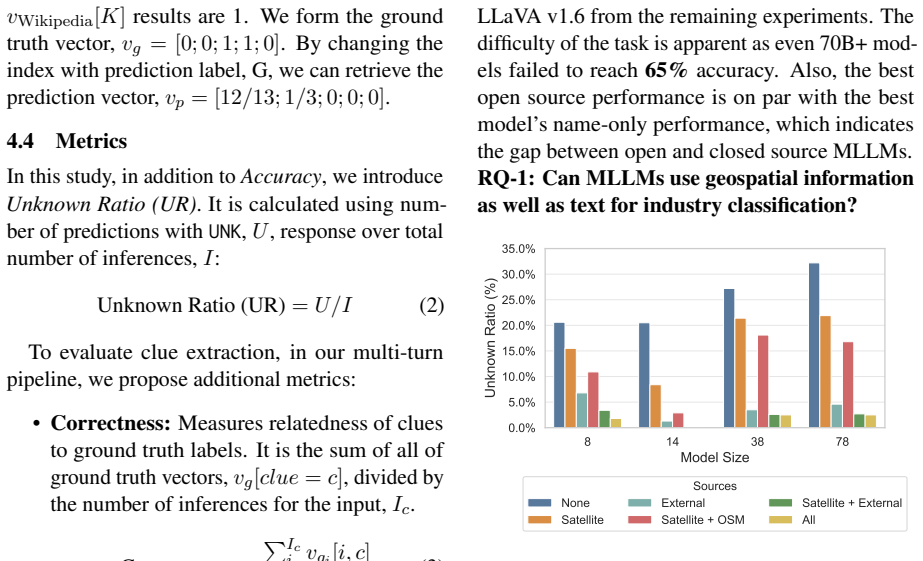
- [Results] Results and Experiments sections: The 22.80% lift from multi-turn, context enrichment, and explanations is reported without modality ablations or per-source contribution analysis. It remains unclear whether geospatial inputs (OSM and satellite imagery) add discriminative power beyond textual mentions of industry activity, which is load-bearing for the multimodal premise.
- [Experiments] Evaluation Methodology: No data splits, statistical significance tests for accuracy differences, or controls for prompt sensitivity are described. These omissions prevent assessment of whether the reported baselines and gains are robust or sensitive to implementation choices.
minor comments (3)
- [Introduction] The abstract and introduction should explicitly cite prior work on automated NACE or SIC classification to better position the novelty of the multimodal benchmark.
- [Method] Figure captions and the multi-agent system diagram would benefit from clearer indication of which agents handle which modalities and how outputs are aggregated.
- Minor inconsistencies in terminology (e.g., 'multi-turn' vs. 'multi-turn design') and occasional missing units in accuracy tables should be standardized.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments on our manuscript. We address each major point below and commit to revisions that will strengthen the presentation of MONETA while preserving the core contributions of the work.
read point-by-point responses
-
Referee: [Dataset Construction] Dataset section: The 1,000 NACE labels are presented as expert annotations replicating manual verification, yet no details are given on label provenance, annotation protocol, or inter-annotator agreement. This information is required to substantiate the claim that the multimodal pipeline matches expert performance.
Authors: We agree that explicit details on label provenance and protocol are needed to support the claim. The NACE labels were obtained directly from official European business registries (cross-referenced with public company databases) to replicate standard expert verification without new annotation. We will add a subsection in the Dataset section describing the exact sources, the alignment protocol with NACE Rev. 2 guidelines, and clarification that traditional inter-annotator agreement does not apply because labels derive from authoritative registers rather than multiple independent annotators. These changes will appear in the revised manuscript. revision: yes
-
Referee: [Results] Results and Experiments sections: The 22.80% lift from multi-turn, context enrichment, and explanations is reported without modality ablations or per-source contribution analysis. It remains unclear whether geospatial inputs (OSM and satellite imagery) add discriminative power beyond textual mentions of industry activity, which is load-bearing for the multimodal premise.
Authors: We acknowledge that modality-specific ablations are required to isolate the contribution of geospatial data. Although the reported gains reflect the full multimodal pipeline, we will add ablation experiments that systematically remove OpenStreetMap and satellite imagery while retaining text sources, together with a per-source contribution breakdown. These results will be inserted into the Results and Experiments sections to demonstrate that geospatial inputs provide measurable discriminative value beyond text alone. revision: yes
-
Referee: [Experiments] Evaluation Methodology: No data splits, statistical significance tests for accuracy differences, or controls for prompt sensitivity are described. These omissions prevent assessment of whether the reported baselines and gains are robust or sensitive to implementation choices.
Authors: Because the approach is training-free and evaluates the full set of 1,000 samples in a zero-shot regime, conventional data splits are not applicable. To improve methodological rigor, we will incorporate statistical significance tests (McNemar’s test) for all reported accuracy differences and add a prompt-sensitivity analysis that varies phrasing of the classification and explanation prompts while reporting result variance. These elements will be added to the Evaluation Methodology subsection of the revised manuscript. revision: yes
Circularity Check
No circularity: empirical benchmark with independent evaluation results
full rationale
The paper introduces a new multimodal benchmark dataset (MONETA) of 1,000 European businesses labeled with NACE codes and reports direct accuracy numbers from training-free MLLM evaluations on text and geospatial inputs. No equations, derivations, fitted parameters, or self-citation chains are present that would reduce the reported accuracies (62.10%, 74.10%, or the 22.80% gains) to quantities defined inside the study by construction. The central claims rest on the assembled dataset and the observed model outputs rather than any self-referential step; this is a standard empirical benchmark paper whose results are falsifiable against the released data.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose, MONETA, a multimodal industry classification benchmark... Zero-Shot and Multi-Turn pipelines... frequency vectors... Correctness and Effectiveness metrics.
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
NACE to OSM mapping... satellite imagery via ESRI REST API... 20 NACE sections.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Carole A Ambler and James E Kristoff. 1998. https://doi.org/10.1016/S0740-624X(98)90003-X Introducing the North American industry classification system . Government Information Quarterly, 15(3):263--273
-
[2]
Matteo Ambrois, Vincenzo Butticè, Federico Caviggioli, Giovanni Cerulli, Annalisa Croce, Antonio De Marco, Andrea Giordano, Giuliano Resce, Laura Toschi, Elisa Ughetto, and Antonio Zinilli. 2023. https://EconPapers.repec.org/RePEc:zbw:eifwps:202391 Using machine learning to map the european cleantech sector . EIF Working Paper Series 2023/91, European Inv...
2023
-
[3]
Freeman, J
Madeline Loui Anderson, Miriam Cha, William T. Freeman, J. Taylor Perron, Nathaniel Maidel, and Kerri Cahoy. 2025. https://openreview.net/forum?id=fEMTiazivQ Measuring and mitigating hallucinations in vision-language dataset generation for remote sensing . In Workshop on Preparing Good Data for Generative AI: Challenges and Approaches
2025
-
[4]
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. 2023. Qwen-vl: A versatile vision-language model for understanding, localization, text reading, and beyond. arXiv preprint arXiv:2308.12966
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, and 8 others. 2025. Qwen2.5-vl technical report. arXiv preprint arXiv:2502.13923
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Hannah Béchara, Ran Zhang, Shuzhou Yuan, and Slava Jankin. 2022. https://doi.org/10.1109/BigData55660.2022.10020787 Applying NLP Techniques to Classify Businesses by their International Standard Industrial Classification ( ISIC ) Code . In 2022 IEEE International Conference on Big Data ( Big Data ) , pages 3472--3477
-
[7]
Wei Chen, Xixuan Hao, Yuankai Wu, and Yuxuan Liang. 2024 a . https://doi.org/10.52202/079017-2121 Terra: A multimodal spatio-temporal dataset spanning the earth . In Advances in Neural Information Processing Systems, volume 37, pages 66329--66356. Curran Associates, Inc
-
[8]
Yuzhou Chen, Jiue-An Yang, Hugo Kyo Lee, Calvin Tribby, Tarik Benmarhnia, Marta Jankowska, and Yulia R. Gel. 2025. https://doi.org/10.1109/ICASSP49660.2025.10889624 Fusing Multimodality of Large Language Models and Satellite Imagery via Simplicial Contrastive Learning for Latent Urban Feature Identification and Environmental Application . In ICASSP 2025 -...
-
[9]
Zhe Chen, Weiyun Wang, Yue Cao, Yangzhou Liu, Zhangwei Gao, Erfei Cui, Jinguo Zhu, Shenglong Ye, Hao Tian, Zhaoyang Liu, and 1 others. 2024 b . Expanding performance boundaries of open-source multimodal models with model, data, and test-time scaling. arXiv preprint arXiv:2412.05271
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
Annalisa Croce, Laura Toschi, Elisa Ughetto, and Sara Zanni. 2024. https://doi.org/10.1016/j.enpol.2024.114006 Cleantech and policy framework in Europe : A machine learning approach . Energy Policy, 186:114006
-
[11]
Michael Han Daniel Han and Unsloth team. 2023. http://github.com/unslothai/unsloth Unsloth
2023
-
[12]
Guy Stephane Waffo Dzuyo, Gaël Guibon, Christophe Cerisara, and Luis Belmar-Letelier. 2025. https://doi.org/10.1609/aaai.v39i16.33806 Linking Industry Sectors and Financial Statements : A Hybrid Approach for Company Classification . Proceedings of the AAAI Conference on Artificial Intelligence, 39(16):16444--16452. Number: 16
-
[13]
European Commission , editor. 2008. NACE Rev . 2: statistical classification of economic activities in the European Community . Publications Office, Luxembourg
2008
-
[14]
Thomas Faria and Tom Seimandi. 2023. Classifying companies in france using machine learning
2023
-
[15]
Gemini 2.5 Team . 2025. https://arxiv.org/abs/2507.06261 Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities . Preprint, arXiv:2507.06261
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Sucharita Gopal and Josh Pitts. 2024. https://doi.org/10.1007/978-3-031-74418-1_6 Geospatial Finance: Foundations and Applications , pages 225--273. Springer Nature Switzerland, Cham
-
[17]
Yanming Guo, Xiao Qian, Kevin Credit, and Jin Ma. 2025. https://doi.org/10.48550/arXiv.2502.06874 Group Reasoning Emission Estimation Networks . arXiv preprint. ArXiv:2502.06874 [cs]
-
[18]
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2022. https://openreview.net/forum?id=nZeVKeeFYf9 Lo RA : Low-rank adaptation of large language models . In International Conference on Learning Representations
2022
-
[19]
Timotej Jagrič and Aljaž Herman. 2024. https://doi.org/10.3390/info15020089 AI Model for Industry Classification Based on Website Data . Information, 15(2):89. Number: 2 Publisher: Multidisciplinary Digital Publishing Institute
-
[20]
Pu Jin, Gui-Song Xia, Fan Hu, Qikai Lu, and Liangpei Zhang. 2018. https://doi.org/10.1109/IGARSS.2018.8518882 AID ++: An Updated Version of AID on Scene Classification . In IGARSS 2018 - 2018 IEEE International Geoscience and Remote Sensing Symposium , pages 4721--4724. ISSN: 2153-7003
-
[21]
Sohail Ahmed Khan, Laurence Dierickx, Jan-Gunnar Furuly, Henrik Brattli Vold, Rano Tahseen, Carl-Gustav Linden, and Duc-Tien Dang-Nguyen. 2025. https://doi.org/10.1002/asi.24970 Debunking war information disorder: A case study in assessing the use of multimedia verification tools . Journal of the Association for Information Science and Technology, 76(5):752--769
-
[22]
Heidi Kühnemann, Arnout van Delden, and Dick Windmeijer. 2020. https://doi.org/10.3233/SJI-200675 Exploring a knowledge-based approach to predicting nace codes of enterprises based on web page texts . Statistical Journal of the IAOS, 36(3):807--821
-
[23]
Haifeng Li, Hao Jiang, Xin Gu, Jian Peng, Wenbo Li, Liang Hong, and Chao Tao. 2020. https://doi.org/10.3390/s20041226 CLRS : Continual Learning Benchmark for Remote Sensing Image Scene Classification . Sensors, 20(4):1226. Number: 4 Publisher: Multidisciplinary Digital Publishing Institute
-
[24]
Chu, Lujun Li, and Porawit Kamnoedboon
Qiang Li, Mingkun Tan, Xun Zhao, Dan Zhang, Daoan Zhang, Shengzhao Lei, Anderson S. Chu, Lujun Li, and Porawit Kamnoedboon. 2025. https://doi.org/10.18653/v1/2025.naacl-industry.4 How LLM s react to industrial spatio-temporal data? assessing hallucination with a novel traffic incident benchmark dataset . In Proceedings of the 2025 Conference of the Nation...
-
[25]
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. 2023 a . Improved baselines with visual instruction tuning
2023
-
[26]
Haotian Liu, Chunyuan Li, Yuheng Li, Bo Li, Yuanhan Zhang, Sheng Shen, and Yong Jae Lee. 2024. https://llava-vl.github.io/blog/2024-01-30-llava-next/ Llava-next: Improved reasoning, ocr, and world knowledge
2024
-
[27]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. 2023 b . Visual instruction tuning
2023
-
[28]
Ivan Malashin, Igor Masich, Vadim Tynchenko, Vladimir Nelyub, Aleksei Borodulin, and Andrei Gantimurov. 2024. https://doi.org/10.3390/bdcc8060068 Application of Natural Language Processing and Genetic Algorithm to Fine - Tune Hyperparameters of Classifiers for Economic Activities Analysis . Big Data and Cognitive Computing, 8(6):68. Number: 6 Publisher: M...
-
[29]
Ali Mansourian and Rachid Oucheikh. 2024. https://doi.org/10.3390/ijgi13100348 ChatGeoAI : Enabling Geospatial Analysis for Public through Natural Language , with Large Language Models . ISPRS International Journal of Geo-Information, 13(10):348
-
[30]
Ethan Mendes, Yang Chen, James Hays, Sauvik Das, Wei Xu, and Alan Ritter. 2024. https://doi.org/10.18653/v1/2024.emnlp-main.957 Granular Privacy Control for Geolocation with Vision Language Models . In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages 17240--17292, Miami, Florida, USA. Association for Computati...
-
[31]
Hibiki Nakatani, Hiroki Teranishi, Shohei Higashiyama, Yuya Sawada, Hiroki Ouchi, and Taro Watanabe. 2025. https://aclanthology.org/2025.coling-main.486/ A Text Embedding Model with Contrastive Example Mining for Point -of- Interest Geocoding . In Proceedings of the 31st International Conference on Computational Linguistics , pages 7279--7291, Abu Dhabi, ...
2025
-
[32]
Sanaz Saki Norouzi and Pascal Hitzler. 2025. https://doi.org/10.1609/aaaiss.v5i1.35609 Knowledge- Enhanced Geospatial QA : Integrating Wikidata Fact Verification with LLMs . Proceedings of the AAAI Symposium Series, 5(1):334--339
-
[33]
OpenAI . 2025. Gpt-5. https://openai.com. Large language model
2025
-
[34]
Maryan Rizinski, Andrej Jankov, Vignesh Sankaradas, Eugene Pinsky, Igor Miskovski, and Dimitar Trajanov. 2023. https://doi.org/10.48550/arXiv.2305.01028 Company classification using zero-shot learning . arXiv preprint. ArXiv:2305.01028 [cs] version: 2
-
[35]
Mohamad Hakam Shams Eddin and J\" u rgen Gall. 2024. https://proceedings.neurips.cc/paper_files/paper/2024/file/aa7259c82d642e47d5661f3218cdcad2-Paper-Conference.pdf Identifying spatio-temporal drivers of extreme events . In Advances in Neural Information Processing Systems, volume 37, pages 93714--93766. Curran Associates, Inc
2024
-
[36]
Zirui Song, Jingpu Yang, Yuan Huang, Jonathan Tonglet, Zeyu Zhang, Tao Cheng, Meng Fang, Iryna Gurevych, and Xiuying Chen. 2025. https://doi.org/10.48550/arXiv.2502.13759 Geolocation with Real Human Gameplay Data : A Large - Scale Dataset and Human - Like Reasoning Framework . arXiv preprint. ArXiv:2502.13759 [cs]
-
[37]
Yuan Tao, Wanzeng Liu, Jun Chen, Jingxiang Gao, Ran Li, Xinpeng Wang, Ye Zhang, Jiaxin Ren, Shunxi Yin, Xiuli Zhu, Tingting Zhao, Xi Zhai, and Yunlu Peng. 2025. https://doi.org/10.1016/j.jag.2024.104353 A graph-based multimodal data fusion framework for identifying urban functional zone . International Journal of Applied Earth Observation and Geoinformati...
-
[38]
UN . 2008. https://doi.org/10.18356/8722852c-en International Standard Industrial Classification of All Economic Activities ( ISIC ), Rev .4 . Statistical Papers ( Ser . M ). United Nations, s.l
-
[39]
Dimitrios Vamvourellis, Máté Tóth, Snigdha Bhagat, Dhruv Desai, Dhagash Mehta, and Stefano Pasquali. 2024. https://doi.org/10.1109/CIFEr62890.2024.10772990 Company similarity using large language models . In 2024 IEEE Symposium on Computational Intelligence for Financial Engineering and Economics (CIFEr), pages 1--9
-
[40]
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Yang Fan, Kai Dang, Mengfei Du, Xuancheng Ren, Rui Men, Dayiheng Liu, Chang Zhou, Jingren Zhou, and Junyang Lin. 2024 a . Qwen2-vl: Enhancing vision-language model's perception of the world at any resolution. arXiv preprint arXiv:2409.12191
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [41]
-
[42]
Gabriela Alves Werb, Patrick Felka, Lisa Reichenbach, Susanne Walter, and Ece Yalcin-Roder. 2024. https://doi.org/10.1109/BigData62323.2024.10825029 Geospatial Data and Multimodal Fact - Checking for Validating Company Data . In 2024 IEEE International Conference on Big Data ( BigData ) , pages 3329--3332. ISSN: 2573-2978
-
[43]
Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Rémi Louf, Morgan Funtowicz, Joe Davison, Sam Shleifer, Patrick von Platen, Clara Ma, Yacine Jernite, Julien Plu, Canwen Xu, Teven Le Scao, Sylvain Gugger, and 3 others. 2020. https://www.aclweb.org/anthology/2020.emnlp-demos.6 Transformers...
2020
-
[44]
Gui-Song Xia, Jingwen Hu, Fan Hu, Baoguang Shi, Xiang Bai, Yanfei Zhong, Liangpei Zhang, and Xiaoqiang Lu. 2017. https://doi.org/10.1109/TGRS.2017.2685945 AID : A Benchmark Data Set for Performance Evaluation of Aerial Scene Classification . IEEE Transactions on Geoscience and Remote Sensing, 55(7):3965--3981
-
[45]
Wenjia Xu, Zijian Yu, Yixu Wang, Jiuniu Wang, and Mugen Peng. 2024. https://doi.org/10.48550/arXiv.2406.07089 RS - Agent : Automating Remote Sensing Tasks through Intelligent Agents . arXiv preprint. ArXiv:2406.07089 [cs]
-
[46]
Jeasurk Yang, Sumin Lee, Sungwon Park, Minjun Lee, and Meeyoung Cha. 2024. https://doi.org/10.48550/arXiv.2410.09522 Poverty mapping in Mongolia with AI -based Ger detection reveals urban slums persist after the COVID -19 pandemic . arXiv preprint. ArXiv:2410.09522
-
[47]
Yi Yang and Shawn Newsam. 2010. https://doi.org/10.1145/1869790.1869829 Bag-of-visual-words and spatial extensions for land-use classification . In Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems , GIS '10, pages 270--279, New York, NY, USA. Association for Computing Machinery
-
[48]
Shuai Yuan, Guancong Lin, Lixian Zhang, Runmin Dong, Jinxiao Zhang, Shuang Chen, Juepeng Zheng, Jie Wang, and Haohuan Fu. 2024. Fusu: a multi-temporal-source land use change segmentation dataset for fine-grained urban semantic understanding. In Proceedings of the 38th International Conference on Neural Information Processing Systems, NIPS '24, Red Hook, N...
2024
-
[49]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[50]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.