Recognition: unknown
HEX: Humanoid-Aligned Experts for Cross-Embodiment Whole-Body Manipulation
Pith reviewed 2026-05-10 17:36 UTC · model grok-4.3
The pith
HEX achieves state-of-the-art whole-body manipulation on humanoid robots by aligning states across embodiments and modeling coordination with a mixture-of-experts predictor.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
HEX is a state-centric framework for coordinated manipulation on full-sized bipedal humanoid robots. It introduces a humanoid-aligned universal state representation for scalable learning across heterogeneous embodiments, and incorporates a Mixture-of-Experts Unified Proprioceptive Predictor to model whole-body coordination and temporal motion dynamics from large-scale multi-embodiment trajectory data. To efficiently capture temporal visual context, HEX uses lightweight history tokens to summarize past observations. It further employs a residual-gated fusion mechanism with a flow-matching action head to adaptively integrate visual-language cues with proprioceptive dynamics for action生成. Real‑
What carries the argument
A humanoid-aligned universal state representation that normalizes data from varied robot morphologies into one common format, paired with a Mixture-of-Experts Unified Proprioceptive Predictor that learns whole-body coordination and temporal dynamics from pooled multi-embodiment trajectories.
Load-bearing premise
The humanoid-aligned universal state representation combined with the Mixture-of-Experts Unified Proprioceptive Predictor can reliably capture and generalize whole-body coordination and temporal dynamics across heterogeneous embodiments from large-scale multi-embodiment trajectory data.
What would settle it
Running HEX on a new humanoid embodiment whose limb lengths, mass distribution, or joint dynamics differ markedly from the training set and observing loss of whole-body coordination or task failure in long-horizon trials would falsify the generalization claim.
Figures







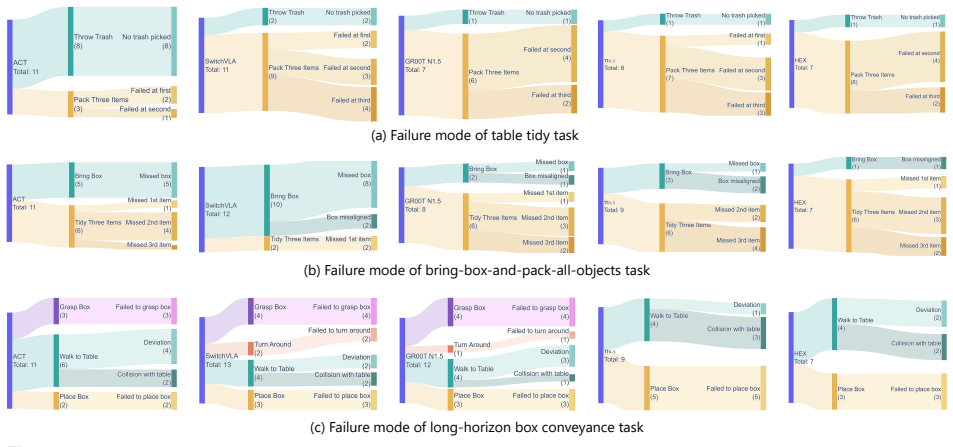
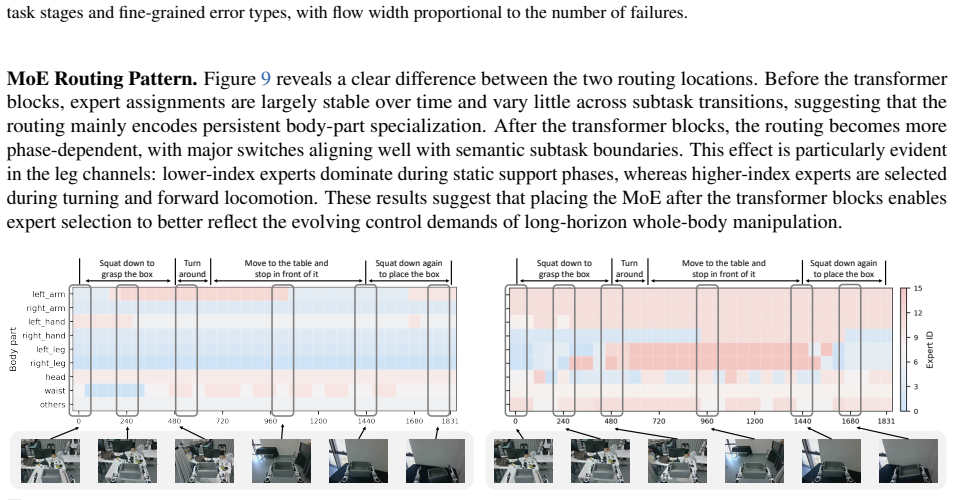

read the original abstract
Humans achieve complex manipulation through coordinated whole-body control, whereas most Vision-Language-Action (VLA) models treat robot body parts largely independently, making high-DoF humanoid control challenging and often unstable. We present HEX, a state-centric framework for coordinated manipulation on full-sized bipedal humanoid robots. HEX introduces a humanoid-aligned universal state representation for scalable learning across heterogeneous embodiments, and incorporates a Mixture-of-Experts Unified Proprioceptive Predictor to model whole-body coordination and temporal motion dynamics from large-scale multi-embodiment trajectory data. To efficiently capture temporal visual context, HEX uses lightweight history tokens to summarize past observations, avoiding repeated encoding of historical images during inference. It further employs a residual-gated fusion mechanism with a flow-matching action head to adaptively integrate visual-language cues with proprioceptive dynamics for action generation. Experiments on real-world humanoid manipulation tasks show that HEX achieves state-of-the-art performance in task success rate and generalization, particularly in fast-reaction and long-horizon scenarios.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes HEX, a state-centric framework for coordinated whole-body manipulation on full-sized bipedal humanoid robots. It introduces a humanoid-aligned universal state representation for cross-embodiment scalability, a Mixture-of-Experts Unified Proprioceptive Predictor to model coordination and temporal dynamics from multi-embodiment trajectory data, lightweight history tokens for visual context, a residual-gated fusion mechanism, and a flow-matching action head. The central empirical claim is that HEX achieves state-of-the-art task success rates and generalization on real-world humanoid tasks, especially in fast-reaction and long-horizon scenarios.
Significance. If the quantitative results hold with proper controls, the work could advance cross-embodiment VLA models by tackling whole-body coordination and stability in high-DoF humanoids, a known challenge. The universal state representation and MoE proprioceptive predictor represent a concrete architectural approach to leveraging heterogeneous data without per-embodiment retraining.
major comments (2)
- [Abstract and Experiments] Abstract and Experiments section: The manuscript asserts SOTA performance in task success rate and generalization on real robots but supplies no quantitative metrics (e.g., success percentages), baseline comparisons, trial counts, data splits, statistical tests, or failure-mode analysis. This is load-bearing for the central claim that the humanoid-aligned state representation plus MoE predictor produce measurable gains in cross-embodiment whole-body coordination and long-horizon stability.
- [Method] Method section (description of Mixture-of-Experts Unified Proprioceptive Predictor): No ablation results or analysis are referenced showing that the MoE avoids mode collapse on heterogeneous dynamics or that the universal state representation transfers without embodiment-specific retraining, which directly supports the generalization claims.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and commit to revisions that strengthen the empirical presentation and analysis without altering the core contributions.
read point-by-point responses
-
Referee: [Abstract and Experiments] Abstract and Experiments section: The manuscript asserts SOTA performance in task success rate and generalization on real robots but supplies no quantitative metrics (e.g., success percentages), baseline comparisons, trial counts, data splits, statistical tests, or failure-mode analysis. This is load-bearing for the central claim that the humanoid-aligned state representation plus MoE predictor produce measurable gains in cross-embodiment whole-body coordination and long-horizon stability.
Authors: We agree that the submitted manuscript presents the SOTA claim in the abstract and experiments section without sufficient quantitative detail. We will revise the abstract to include key success rate metrics and expand the experiments section with explicit tables reporting success percentages, baseline comparisons, trial counts, data splits, statistical tests, and failure-mode analysis. This will make the evidence for the benefits of the humanoid-aligned state representation and MoE predictor fully transparent and verifiable. revision: yes
-
Referee: [Method] Method section (description of Mixture-of-Experts Unified Proprioceptive Predictor): No ablation results or analysis are referenced showing that the MoE avoids mode collapse on heterogeneous dynamics or that the universal state representation transfers without embodiment-specific retraining, which directly supports the generalization claims.
Authors: We acknowledge that the initial submission did not include explicit ablations or transfer analysis for the MoE and universal state representation. The method section describes their design for handling heterogeneous multi-embodiment data and cross-embodiment scalability, with generalization supported by the overall experimental outcomes. In revision, we will add ablation studies comparing the MoE to non-MoE baselines to demonstrate avoidance of mode collapse, along with analysis and results confirming transfer of the state representation across embodiments without per-embodiment retraining. revision: yes
Circularity Check
No circularity in derivation chain; claims rest on empirical evaluation
full rationale
The paper presents HEX as an architectural framework for humanoid manipulation, introducing components such as a humanoid-aligned universal state representation, Mixture-of-Experts Unified Proprioceptive Predictor, lightweight history tokens, and residual-gated fusion with flow-matching action head. These are motivated by design choices for cross-embodiment coordination and temporal dynamics, trained on multi-embodiment trajectory data. The central claims concern state-of-the-art task success rates and generalization in real-world experiments. No equations, first-principles derivations, or predictions are described that reduce by construction to fitted parameters, self-definitions, or self-citation chains. Performance assertions are tied to experimental outcomes rather than analytical steps that could be tautological. This is a standard empirical ML robotics paper with no load-bearing circular reductions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Large-scale multi-embodiment trajectory data contains sufficient signal to learn generalizable whole-body coordination and temporal dynamics.
invented entities (2)
-
Humanoid-aligned universal state representation
no independent evidence
-
Mixture-of-Experts Unified Proprioceptive Predictor
no independent evidence
Forward citations
Cited by 2 Pith papers
-
CapVector: Learning Transferable Capability Vectors in Parametric Space for Vision-Language-Action Models
Capability vectors extracted from parameter differences between standard and auxiliary-finetuned VLA models can be merged into pretrained weights to match auxiliary-training performance while reducing computational ov...
-
RoboMemArena: A Comprehensive and Challenging Robotic Memory Benchmark
RoboMemArena is a new large-scale robotic memory benchmark with real-world tasks, and PrediMem is a dual VLA system that outperforms baselines by managing memory buffers with predictive coding.
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Latent Reasoning VLA: Latent Thinking and Prediction for Vision-Language-Action Models
Shuanghao Bai, Jing Lyu, Wanqi Zhou, Zhe Li, Dakai Wang, Lei Xing, Xiaoguang Zhao, Pengwei Wang, Zhongyuan Wang, Cheng Chi, et al. Latent reasoning vla: Latent thinking and prediction for vision-language-action models.arXiv preprint arXiv:2602.01166, 2026
work page internal anchor Pith review arXiv 2026
-
[3]
arXiv preprint arXiv:2512.22983 , year=
Shuanghao Bai, Wenxuan Song, Jiayi Chen, Yuheng Ji, Zhide Zhong, Jin Yang, Han Zhao, Wanqi Zhou, Zhe Li, Pengxiang Ding, et al. Embodied robot manipulation in the era of foundation models: Planning and learning perspectives.arXiv preprint arXiv:2512.22983, 2025
-
[4]
Towards a unified understanding of robot ma- nipulation: A comprehensive survey,
Shuanghao Bai, Wenxuan Song, Jiayi Chen, Yuheng Ji, Zhide Zhong, Jin Yang, Han Zhao, Wanqi Zhou, Wei Zhao, Zhe Li, et al. Towards a unified understanding of robot manipulation: A comprehensive survey.arXiv preprint arXiv:2510.10903, 2025
-
[5]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
Johan Bjorck, Fernando Castañeda, Nikita Cherniadev, Xingye Da, Runyu Ding, Linxi Fan, Yu Fang, Dieter Fox, Fengyuan Hu, Spencer Huang, et al. Gr00t n1: An open foundation model for generalist humanoid robots.arXiv preprint arXiv:2503.14734, 2025
work page internal anchor Pith review arXiv 2025
-
[6]
Agibot world colosseo: A large-scale manipulation platform for scalable and intelligent embodied systems
Qingwen Bu, Jisong Cai, Li Chen, Xiuqi Cui, Yan Ding, Siyuan Feng, Shenyuan Gao, Xindong He, Xuan Hu, Xu Huang, et al. Agibot world colosseo: A large-scale manipulation platform for scalable and intelligent embodied systems. In2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 3549–3556, 2025
2025
-
[7]
Univla: Learning to act anywhere with task-centric latent actions
Qingwen Bu, Yanting Yang, Jisong Cai, Shenyuan Gao, Guanghui Ren, Maoqing Yao, Ping Luo, and Hongyang Li. Univla: Learning to act anywhere with task-centric latent actions. InRobotics: Science and Systems, 2025
2025
-
[8]
Hand-eye autonomous delivery: Learning humanoid navigation, locomotion and reaching
Sirui Chen, Yufei Ye, Zi-ang Cao, Pei Xu, Jennifer Lew, and Karen Liu. Hand-eye autonomous delivery: Learning humanoid navigation, locomotion and reaching. InConference on Robot Learning, pages 4058–4073. PMLR, 2025. 14
2025
-
[9]
Gmt: General motion tracking for humanoid whole-body control,
Zixuan Chen, Mazeyu Ji, Xuxin Cheng, Xuanbin Peng, Xue Bin Peng, and Xiaolong Wang. Gmt: General motion tracking for humanoid whole-body control.arXiv preprint arXiv:2506.14770, 2025
-
[10]
Can Cui, Pengxiang Ding, Wenxuan Song, Shuanghao Bai, Xinyang Tong, Zirui Ge, Runze Suo, Wanqi Zhou, Yang Liu, Bofang Jia, et al. Openhelix: A short survey, empirical analysis, and open-source dual-system vla model for robotic manipulation.arXiv preprint arXiv:2505.03912, 2025
-
[11]
Pengxiang Ding, Jianfei Ma, Xinyang Tong, Binghong Zou, Xinxin Luo, Yiguo Fan, Ting Wang, Hongchao Lu, Panzhong Mo, Jinxin Liu, et al. Humanoid-vla: Towards universal humanoid control with visual integration.arXiv preprint arXiv:2502.14795, 2025
-
[12]
Scaling cross-embodied learning: One policy for manipulation, navigation, locomotion and aviation
Ria Doshi, Homer Rich Walke, Oier Mees, Sudeep Dasari, and Sergey Levine. Scaling cross-embodied learning: One policy for manipulation, navigation, locomotion and aviation. InConference on Robot Learning, pages 496–512. PMLR, 2025
2025
-
[13]
Zhiying Du, Bei Liu, Yaobo Liang, Yichao Shen, Haidong Cao, Xiangyu Zheng, Zhiyuan Feng, Zuxuan Wu, Jiaolong Yang, and Yu-Gang Jiang. Himoe-vla: Hierarchical mixture-of-experts for generalist vision-language-action policies.arXiv preprint arXiv:2512.05693, 2025
-
[14]
Long-vla: Unleashing long-horizon capability of vision language action model for robot manipulation
Yiguo Fan, Shuanghao Bai, Xinyang Tong, Pengxiang Ding, Yuyang Zhu, Hongchao Lu, Fengqi Dai, Wei Zhao, Yang Liu, Siteng Huang, et al. Long-vla: Unleashing long-horizon capability of vision language action model for robot manipulation. In Conference on Robot Learning, pages 2018–2037. PMLR, 2025
2018
-
[15]
Humanplus: Humanoid shadowing and imitation from humans
Zipeng Fu, Qingqing Zhao, Qi Wu, Gordon Wetzstein, and Chelsea Finn. Humanplus: Humanoid shadowing and imitation from humans. InConference on Robot Learning, pages 2828–2844. PMLR, 2025
2025
-
[16]
Omnih2o: Universal and dexterous human-to-humanoid whole-body teleoperation and learning
Tairan He, Zhengyi Luo, Xialin He, Wenli Xiao, Chong Zhang, Weinan Zhang, Kris M Kitani, Changliu Liu, and Guanya Shi. Omnih2o: Universal and dexterous human-to-humanoid whole-body teleoperation and learning. InConference on Robot Learning, pages 1516–1540. PMLR, 2025
2025
-
[17]
Viral: Visual sim-to-real at scale for humanoid loco-manipulation.arXiv preprint arXiv: 2511.15200,
Tairan He, Zi Wang, Haoru Xue, Qingwei Ben, Zhengyi Luo, Wenli Xiao, Ye Yuan, Xingye Da, Fernando Castañeda, Shankar Sastry, et al. Viral: Visual sim-to-real at scale for humanoid loco-manipulation.arXiv preprint arXiv:2511.15200, 2025
-
[18]
Chengkai Hou, Kun Wu, Jiaming Liu, Zhengping Che, Di Wu, Fei Liao, Guangrun Li, Jingyang He, Qiuxuan Feng, Zhao Jin, et al. Robomind 2.0: A multimodal, bimanual mobile manipulation dataset for generalizable embodied intelligence.arXiv preprint arXiv:2512.24653, 2025
-
[19]
Slac: Simulation-pretrained latent action space for whole-body real-world rl
Jiaheng Hu, Peter Stone, and Roberto Martín-Martín. Slac: Simulation-pretrained latent action space for whole-body real-world rl. InConference on Robot Learning, pages 2966–2982. PMLR, 2025
2025
-
[20]
π0.5: A vision-language-action model with open-world generalization
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, et al. π0.5: A vision-language-action model with open-world generalization. InConference on Robot Learning, 2025
2025
-
[21]
Wholebodyvla: Towards unified latent vla for whole-body loco-manipulation control
Haoran Jiang, Jin Chen, Qingwen Bu, Li Chen, Modi Shi, Yanjie Zhang, Delong Li, Chuanzhe Suo, Chuang Wang, Zhihui Peng, et al. Wholebodyvla: Towards unified latent vla for whole-body loco-manipulation control. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[22]
Openvla: An open-source vision-language-action model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan P Foster, Pannag R Sanketi, Quan Vuong, et al. Openvla: An open-source vision-language-action model. InConference on Robot Learning, pages 2679–2713. PMLR, 2025
2025
-
[23]
Okami: Teaching humanoid robots manipulation skills through single video imitation
Jinhan Li, Yifeng Zhu, Yuqi Xie, Zhenyu Jiang, Mingyo Seo, Georgios Pavlakos, and Yuke Zhu. Okami: Teaching humanoid robots manipulation skills through single video imitation. InConference on Robot Learning, pages 299–317. PMLR, 2025
2025
-
[24]
Meng Li, Zhen Zhao, Zhengping Che, Fei Liao, Kun Wu, Zhiyuan Xu, Pei Ren, Zhao Jin, Ning Liu, and Jian Tang. Switchvla: Execution-aware task switching for vision-language-action models.arXiv preprint arXiv:2506.03574, 2025
-
[25]
Beyondmimic: From mo- tion tracking to versatile humanoid control via guided diffusion,
Qiayuan Liao, Takara E Truong, Xiaoyu Huang, Yuman Gao, Guy Tevet, Koushil Sreenath, and C Karen Liu. Beyondmimic: From motion tracking to versatile humanoid control via guided diffusion.arXiv preprint arXiv:2508.08241, 2025
-
[26]
Yunfeng Lin, Minghuan Liu, Yufei Xue, Ming Zhou, Yong Yu, Jiangmiao Pang, and Weinan Zhang. H-zero: Cross-humanoid locomotion pretraining enables few-shot novel embodiment transfer.arXiv preprint arXiv:2512.00971, 2025
-
[27]
Trajbooster: Boosting humanoid whole-body manipulation via trajectory-centric learning
Jiacheng Liu, Pengxiang Ding, Qihang Zhou, Yuxuan Wu, Da Huang, Zimian Peng, Wei Xiao, Weinan Zhang, Lixin Yang, Cewu Lu, et al. Trajbooster: Boosting humanoid whole-body manipulation via trajectory-centric learning. In2026 IEEE International Conference on Robotics and Automation (ICRA), 2026. 15
2026
-
[28]
Mobile-television: Predictive motion priors for humanoid whole-body control
Chenhao Lu, Xuxin Cheng, Jialong Li, Shiqi Yang, Mazeyu Ji, Chengjing Yuan, Ge Yang, Sha Yi, and Xiaolong Wang. Mobile-television: Predictive motion priors for humanoid whole-body control. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 5364–5371. IEEE, 2025
2025
-
[29]
Being-h0.5: Scaling human-centric robot learning for cross-embodiment generalization
Hao Luo, Ye Wang, Wanpeng Zhang, Sipeng Zheng, Ziheng Xi, Chaoyi Xu, Haiweng Xu, Haoqi Yuan, Chi Zhang, Yiqing Wang, et al. Being-h0. 5: Scaling human-centric robot learning for cross-embodiment generalization.arXiv preprint arXiv:2601.12993, 2026
-
[30]
Guoqing Ma, Siheng Wang, Zeyu Zhang, Shan Yu, and Hao Tang
Zhengyi Luo, Ye Yuan, Tingwu Wang, Chenran Li, Sirui Chen, Fernando Castaneda, Zi-Ang Cao, Jiefeng Li, David Minor, Qingwei Ben, et al. Sonic: Supersizing motion tracking for natural humanoid whole-body control.arXiv preprint arXiv:2511.07820, 2025
-
[31]
Learning from massive human videos for universal humanoid pose control
Jiageng Mao, Siheng Zhao, Siqi Song, Tianheng Shi, Junjie Ye, Mingtong Zhang, Haoran Geng, Jitendra Malik, Vitor Guizilini, and Yue Wang. Learning from massive human videos for universal humanoid pose control. InInternational Conference on Humanoid Robots, 2025
2025
-
[32]
Learning from demonstration and adaptation of biped locomotion.Robotics and autonomous systems, 47(2-3):79–91, 2004
Jun Nakanishi, Jun Morimoto, Gen Endo, Gordon Cheng, Stefan Schaal, and Mitsuo Kawato. Learning from demonstration and adaptation of biped locomotion.Robotics and autonomous systems, 47(2-3):79–91, 2004
2004
-
[33]
Quanquan Peng, Yunfeng Lin, Yufei Xue, Jiangmiao Pang, and Weinan Zhang. Embodiment-aware generalist specialist distillation for unified humanoid whole-body control.arXiv preprint arXiv:2602.02960, 2026
-
[34]
Deepmimic: Example-guided deep reinforcement learning of physics-based character skills.ACM Transactions On Graphics (TOG), 37(4):1–14, 2018
Xue Bin Peng, Pieter Abbeel, Sergey Levine, and Michiel Van de Panne. Deepmimic: Example-guided deep reinforcement learning of physics-based character skills.ACM Transactions On Graphics (TOG), 37(4):1–14, 2018
2018
-
[35]
Amp: Adversarial motion priors for stylized physics-based character control.ACM Transactions on Graphics (ToG), 40(4):1–20, 2021
Xue Bin Peng, Ze Ma, Pieter Abbeel, Sergey Levine, and Angjoo Kanazawa. Amp: Adversarial motion priors for stylized physics-based character control.ACM Transactions on Graphics (ToG), 40(4):1–20, 2021
2021
-
[36]
Egobridge: Domain adaptation for generalizable imitation from egocentric human data
Ryan Punamiya, Dhruv Patel, Patcharapong Aphiwetsa, Pranav Kuppili, Lawrence Y Zhu, Simar Kareer, Judy Hoffman, and Danfei Xu. Egobridge: Domain adaptation for generalizable imitation from egocentric human data. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[37]
Humanoid policy human policy
Ri-Zhao Qiu, Shiqi Yang, Xuxin Cheng, Chaitanya Chawla, Jialong Li, Tairan He, Ge Yan, David J Yoon, Ryan Hoque, Lars Paulsen, et al. Humanoid policy human policy. InConference on Robot Learning, pages 2888–2906. PMLR, 2025
2025
-
[38]
Real-world humanoid locomotion with reinforcement learning.Science Robotics, 9(89):eadi9579, 2024
Ilija Radosavovic, Tete Xiao, Bike Zhang, Trevor Darrell, Jitendra Malik, and Koushil Sreenath. Real-world humanoid locomotion with reinforcement learning.Science Robotics, 9(89):eadi9579, 2024
2024
-
[39]
Egohumanoid: Unlocking in-the-wild loco-manipulation with robot-free egocentric demonstration,
Modi Shi, Shijia Peng, Jin Chen, Haoran Jiang, Yinghui Li, Di Huang, Ping Luo, Hongyang Li, and Li Chen. Egohumanoid: Unlocking in-the-wild loco-manipulation with robot-free egocentric demonstration.arXiv preprint arXiv:2602.10106, 2026
-
[40]
Reconvla: Reconstructive vision-language-action model as effective robot perceiver
Wenxuan Song, Ziyang Zhou, Han Zhao, Jiayi Chen, Pengxiang Ding, Haodong Yan, Yuxin Huang, Feilong Tang, Donglin Wang, and Haoang Li. Reconvla: Reconstructive vision-language-action model as effective robot perceiver. InThe 40th Annual AAAI Conference on Artificial Intelligence, 2026
2026
-
[41]
Scaling proprioceptive-visual learning with heterogeneous pre-trained transformers
Lirui Wang, Xinlei Chen, Jialiang Zhao, and Kaiming He. Scaling proprioceptive-visual learning with heterogeneous pre-trained transformers. InAdvances in neural information processing systems, volume 37, pages 124420–124450, 2024
2024
-
[42]
Vla-adapter: An effective paradigm for tiny-scale vision-language-action model
Yihao Wang, Pengxiang Ding, Lingxiao Li, Can Cui, Zirui Ge, Xinyang Tong, Wenxuan Song, Han Zhao, Wei Zhao, Pengxu Hou, Siteng Huang, Yifan Tang, Wenhui Wang, Ru Zhang, Jianyi Liu, and Donglin Wang. Vla-adapter: An effective paradigm for tiny-scale vision-language-action model. InThe 40th Annual AAAI Conference on Artificial Intelligence, 2026
2026
-
[43]
ψ0: An open foundation model towards universal humanoid loco-manipulation, 2026
Songlin Wei, Hongyi Jing, Boqian Li, Zhenyu Zhao, Jiageng Mao, Zhenhao Ni, Sicheng He, Jie Liu, Xiawei Liu, Kaidi Kang, Sheng Zang, Weiduo Yuan, Marco Pavone, Di Huang, and Yue Wang. ψ0: An open foundation model towards universal humanoid loco-manipulation, 2026
2026
-
[44]
Hdmi: Learning interactive humanoid whole-body control from human videos,
Haoyang Weng, Yitang Li, Nikhil Sobanbabu, Zihan Wang, Zhengyi Luo, Tairan He, Deva Ramanan, and Guanya Shi. Hdmi: Learning interactive humanoid whole-body control from human videos.arXiv preprint arXiv:2509.16757, 2025
-
[45]
Robomind: Benchmark on multi-embodiment intelligence normative data for robot manipulation
Kun Wu, Chengkai Hou, Jiaming Liu, Zhengping Che, Xiaozhu Ju, Zhuqin Yang, Meng Li, Yinuo Zhao, Zhiyuan Xu, Guang Yang, et al. Robomind: Benchmark on multi-embodiment intelligence normative data for robot manipulation. InRobotics: Science and Systems (RSS), 2025
2025
-
[46]
RoboCOIN: An Open-Sourced Bimanual Robotic Data Collection for Integrated Manipulation
Shihan Wu, Xuecheng Liu, Shaoxuan Xie, Pengwei Wang, Xinghang Li, Bowen Yang, Zhe Li, Kai Zhu, Hongyu Wu, Yiheng Liu, et al. Robocoin: An open-sourced bimanual robotic data collection for integrated manipulation.arXiv preprint arXiv:2511.17441, 2025. 16
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[47]
Kungfubot: Physics-based humanoid whole-body control for learning highly-dynamic skills
Weiji Xie, Jinrui Han, Jiakun Zheng, Huanyu Li, Xinzhe Liu, Jiyuan Shi, Weinan Zhang, Chenjia Bai, and Xuelong Li. Kungfubot: Physics-based humanoid whole-body control for learning highly-dynamic skills. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[48]
Hierarchical planning and control for box loco-manipulation.Proceedings of the ACM on Computer Graphics and Interactive Techniques, 6(3):1–18, 2023
Zhaoming Xie, Jonathan Tseng, Sebastian Starke, Michiel Van De Panne, and C Karen Liu. Hierarchical planning and control for box loco-manipulation.Proceedings of the ACM on Computer Graphics and Interactive Techniques, 6(3):1–18, 2023
2023
-
[49]
Hacts: a human-as- copilot teleoperation system for robot learning
Zhiyuan Xu, Yinuo Zhao, Kun Wu, Ning Liu, Junjie Ji, Zhengping Che, Chi Harold Liu, and Jian Tang. Hacts: a human-as- copilot teleoperation system for robot learning. In2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 15475–15481. IEEE, 2025
2025
-
[50]
LeVERB: Humanoid whole-body control with latent vision-language instruction,
Haoru Xue, Xiaoyu Huang, Dantong Niu, Qiayuan Liao, Thomas Kragerud, Jan Tommy Gravdahl, Xue Bin Peng, Guanya Shi, Trevor Darrell, Koushil Sreenath, et al. Leverb: Humanoid whole-body control with latent vision-language instruction.arXiv preprint arXiv:2506.13751, 2025
-
[51]
Scalable and General Whole-Body Control for Cross-Humanoid Locomotion
Yufei Xue, YunFeng Lin, Wentao Dong, Yang Tang, Jingbo Wang, Jiangmiao Pang, Ming Zhou, Minghuan Liu, and Weinan Zhang. Scalable and general whole-body control for cross-humanoid locomotion.arXiv preprint arXiv:2602.05791, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[52]
Haoran Yang, Jiacheng Bao, Yucheng Xin, Haoming Song, Yuyang Tian, Bin Zhao, Dong Wang, and Xuelong Li. Zerowbc: Learning natural visuomotor humanoid control directly from human egocentric video.arXiv preprint arXiv:2603.09170, 2026
-
[53]
Pushing the limits of cross-embodiment learning for manipulation and navigation
Jonathan Yang, Catherine Glossop, Arjun Bhorkar, Dhruv Shah, Quan Vuong, Chelsea Finn, Dorsa Sadigh, and Sergey Levine. Pushing the limits of cross-embodiment learning for manipulation and navigation. InRobotics: Science and Systems, 2024
2024
-
[54]
Ruihan Yang, Qinxi Yu, Yecheng Wu, Rui Yan, Borui Li, An-Chieh Cheng, Xueyan Zou, Yunhao Fang, Xuxin Cheng, Ri-Zhao Qiu, et al. Egovla: Learning vision-language-action models from egocentric human videos.arXiv preprint arXiv:2507.12440, 2025
-
[55]
Twist: Teleoperated whole-body imitation system
Yanjie Ze, Zixuan Chen, Joao Pedro Araujo, Zi-ang Cao, Xue Bin Peng, Jiajun Wu, and Karen Liu. Twist: Teleoperated whole-body imitation system. InConference on Robot Learning, pages 2143–2154. PMLR, 2025
2025
-
[56]
Generalizable humanoid manipulation with 3d diffusion policies
Yanjie Ze, Zixuan Chen, Wenhao Wang, Tianyi Chen, Xialin He, Ying Yuan, Xue Bin Peng, and Jiajun Wu. Generalizable humanoid manipulation with 3d diffusion policies. In2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 2873–2880. IEEE, 2025
2025
-
[57]
Falcon: Learning force-adaptive humanoid loco-manipulation
Yuanhang Zhang, Yifu Yuan, Prajwal Gurunath, Ishita Gupta, Shayegan Omidshafiei, Ali-akbar Agha-mohammadi, Marcell Vazquez-Chanlatte, Liam Pedersen, Tairan He, and Guanya Shi. Falcon: Learning force-adaptive humanoid loco-manipulation. 8th Annual Learning for Dynamics\& Control Conference, 2026
2026
-
[58]
Learning fine-grained bimanual manipulation with low-cost hardware.Robotics: Science and Systems XIX, 2023
Tony Zhao, Vikash Kumar, Sergey Levine, and Chelsea Finn. Learning fine-grained bimanual manipulation with low-cost hardware.Robotics: Science and Systems XIX, 2023
2023
-
[59]
Humanoid everyday: A comprehensive robotic dataset for open-world humanoid manipulation, 2025
Zhenyu Zhao, Hongyi Jing, Xiawei Liu, Jiageng Mao, Abha Jha, Hanwen Yang, Rong Xue, Sergey Zakharor, Vitor Guizilini, and Yue Wang. Humanoid everyday: A comprehensive robotic dataset for open-world humanoid manipulation.arXiv preprint arXiv:2510.08807, 2025. 17
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.