Recognition: unknown
SAT: Selective Aggregation Transformer for Image Super-Resolution
Pith reviewed 2026-05-10 17:00 UTC · model grok-4.3
The pith
The Selective Aggregation Transformer reduces key-value tokens by 97 percent while improving image super-resolution performance over prior methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
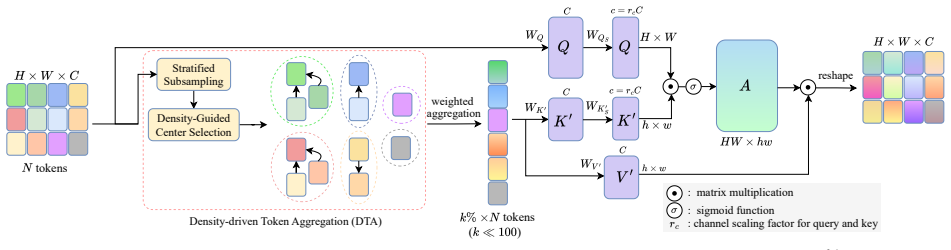
SAT efficiently captures long-range dependencies by selectively aggregating key-value matrices, reducing the number of tokens by 97 percent via the Density-driven Token Aggregation algorithm while maintaining the full resolution of the query matrix. This enlarges the receptive field, lowers complexity, and enables scalable global interactions without compromising reconstruction fidelity. Each cluster is represented by a single aggregation token selected using density and isolation metrics to preserve critical high-frequency details.
What carries the argument
Density-driven Token Aggregation algorithm, which identifies clusters of key-value tokens and replaces each cluster with one representative token using density and isolation metrics.
If this is right
- SAT reaches up to 0.22 dB higher PSNR than the prior PFT method on standard super-resolution benchmarks.
- Total FLOPs drop by up to 27 percent while reconstruction quality stays equal or better.
- The receptive field grows because global interactions remain possible at reduced token count.
- The same token reduction can be applied at different scales without quadratic blow-up in cost.
Where Pith is reading between the lines
- The same density-based merging could be tested on other vision transformers for tasks such as denoising or detection.
- If the metrics prove robust, they might guide adaptive token selection in video or 3-D reconstruction pipelines.
- Combining SAT with existing quantization or pruning methods could yield further efficiency gains on edge devices.
Load-bearing premise
That density and isolation metrics can safely aggregate 97 percent of key-value tokens without losing any high-frequency details required for faithful image reconstruction.
What would settle it
A side-by-side comparison on a high-frequency test set showing that SAT produces more blurring or artifacts than a full-attention baseline at the same upscaling factor.
Figures





read the original abstract
Transformer-based approaches have revolutionized image super-resolution by modeling long-range dependencies. However, the quadratic computational complexity of vanilla self-attention mechanisms poses significant challenges, often leading to compromises between efficiency and global context exploitation. Recent window-based attention methods mitigate this by localizing computations, but they often yield restricted receptive fields. To mitigate these limitations, we propose Selective Aggregation Transformer (SAT). This novel transformer efficiently captures long-range dependencies, leading to an enlarged model receptive field by selectively aggregating key-value matrices (reducing the number of tokens by 97\%) via our Density-driven Token Aggregation algorithm while maintaining the full resolution of the query matrix. This design significantly reduces computational costs, resulting in lower complexity and enabling scalable global interactions without compromising reconstruction fidelity. SAT identifies and represents each cluster with a single aggregation token, utilizing density and isolation metrics to ensure that critical high-frequency details are preserved. Experimental results demonstrate that SAT outperforms the state-of-the-art method PFT by up to 0.22dB, while the total number of FLOPs can be reduced by up to 27\%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes the Selective Aggregation Transformer (SAT) for image super-resolution. It introduces a Density-driven Token Aggregation algorithm that selectively aggregates 97% of key-value tokens (using density and isolation metrics) while retaining full-resolution queries. This is claimed to enlarge the receptive field, reduce quadratic complexity, and yield better reconstruction than prior window-based or global attention methods. The central empirical claim is that SAT outperforms the state-of-the-art PFT method by up to 0.22 dB PSNR while cutting total FLOPs by up to 27%.
Significance. If the empirical gains are reproducible and the aggregation step demonstrably preserves high-frequency content, the work would be a useful contribution to efficient vision transformers for super-resolution. The selective token reduction strategy offers a concrete way to trade off compute for global context without the usual window-size restrictions, and the density/isolation scoring is a novel heuristic in this domain.
major comments (2)
- Abstract and experimental results: The headline performance numbers (0.22 dB gain over PFT, 27% FLOP reduction) are stated without any description of the datasets, training protocol, baseline re-implementations, number of runs, or statistical significance tests. This absence makes the central claim unverifiable and is load-bearing for acceptance.
- Method section (Density-driven Token Aggregation): The assertion that density and isolation metrics preserve all critical high-frequency details after collapsing 97% of KV tokens is presented without supporting analysis (e.g., frequency-domain spectra, edge-gradient histograms, or failure-case inspection on textured regions). Because the reconstruction-fidelity guarantee rests on this untested modeling assumption, the claim that global interactions occur “without compromising reconstruction fidelity” cannot be evaluated.
minor comments (2)
- Abstract: The phrases “up to 0.22 dB” and “up to 27%” are not tied to specific scales or datasets; adding this information would improve clarity.
- Notation: The manuscript introduces “aggregation token” and “cluster token” without an explicit definition or diagram showing how they replace the original KV pairs inside the attention computation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and will incorporate revisions to improve the verifiability and support for our claims.
read point-by-point responses
-
Referee: Abstract and experimental results: The headline performance numbers (0.22 dB gain over PFT, 27% FLOP reduction) are stated without any description of the datasets, training protocol, baseline re-implementations, number of runs, or statistical significance tests. This absence makes the central claim unverifiable and is load-bearing for acceptance.
Authors: We agree that the abstract would benefit from additional context to make the performance claims more immediately verifiable. Although Section 4 of the manuscript details the experimental setup (training on DIV2K, evaluation on Set5/Set14/BSD100/Urban100/Manga109, and identical protocols for PFT re-implementation), we will revise the abstract to briefly include these elements: datasets used, confirmation that baselines follow the same training protocol, and a note that results follow the single-run reporting convention standard in super-resolution literature. We will also add a sentence on result consistency across seeds where space permits. This addresses the verifiability concern directly. revision: yes
-
Referee: Method section (Density-driven Token Aggregation): The assertion that density and isolation metrics preserve all critical high-frequency details after collapsing 97% of KV tokens is presented without supporting analysis (e.g., frequency-domain spectra, edge-gradient histograms, or failure-case inspection on textured regions). Because the reconstruction-fidelity guarantee rests on this untested modeling assumption, the claim that global interactions occur “without compromising reconstruction fidelity” cannot be evaluated.
Authors: We acknowledge that the current version lacks explicit empirical validation for high-frequency preservation under the 97% KV token reduction. In the revised manuscript, we will add supporting analyses in the method or experiments section, including frequency-domain spectra comparisons of features before and after aggregation, edge-gradient histograms on textured patches, and qualitative failure-case examination on regions with fine details. These additions will substantiate that the density and isolation metrics maintain critical information, allowing readers to evaluate the fidelity claim. revision: yes
Circularity Check
No significant circularity in SAT's algorithmic design or empirical claims
full rationale
The paper proposes an algorithmic architecture (Density-driven Token Aggregation) that selectively collapses 97% of KV tokens using density and isolation metrics while retaining full-resolution queries. This is a design choice whose effectiveness is validated through direct empirical comparison to baselines such as PFT, not a first-principles derivation that reduces to its own inputs by construction. No equations, fitted parameters, or self-citations are presented as load-bearing steps that would force the reported 0.22 dB gain or 27% FLOP reduction; those outcomes are external experimental results. The method therefore remains self-contained against independent benchmarks.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Density-driven Token Aggregation algorithm
no independent evidence
Reference graph
Works this paper leans on
-
[1]
On the surprising behavior of distance metrics in high dimensional space
Charu C Aggarwal, Alexander Hinneburg, and Daniel A Keim. On the surprising behavior of distance metrics in high dimensional space. InInternational conference on database theory, pages 420–434. Springer, 2001. 4
2001
-
[2]
Fast, accurate, and lightweight super-resolution with cascading residual network
Namhyuk Ahn, Byungkon Kang, and Kyung-Ah Sohn. Fast, accurate, and lightweight super-resolution with cascading residual network. InProceedings of the European confer- ence on computer vision (ECCV), pages 252–268, 2018. 7
2018
-
[3]
Xcit: Cross-covariance image transformers.Advances in neural information processing systems, 34:20014–20027, 2021
Alaaeldin Ali, Hugo Touvron, Mathilde Caron, Piotr Bo- janowski, Matthijs Douze, Armand Joulin, Ivan Laptev, Na- talia Neverova, Gabriel Synnaeve, Jakob Verbeek, et al. Xcit: Cross-covariance image transformers.Advances in neural information processing systems, 34:20014–20027, 2021. 2
2021
-
[4]
Contour detection and hierarchical image seg- mentation.IEEE transactions on pattern analysis and ma- chine intelligence, 33(5):898–916, 2010
Pablo Arbelaez, Michael Maire, Charless Fowlkes, and Ji- tendra Malik. Contour detection and hierarchical image seg- mentation.IEEE transactions on pattern analysis and ma- chine intelligence, 33(5):898–916, 2010. 6
2010
-
[5]
Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E Hin- ton. Layer normalization.arXiv preprint arXiv:1607.06450,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Low-complexity single-image super-resolution based on nonnegative neighbor embedding
Marco Bevilacqua, Aline Roumy, Christine Guillemot, and Marie Line Alberi-Morel. Low-complexity single-image super-resolution based on nonnegative neighbor embedding
-
[7]
nearest neighbor
Kevin Beyer, Jonathan Goldstein, Raghu Ramakrishnan, and Uri Shaft. When is “nearest neighbor” meaningful? InIn- ternational conference on database theory, pages 217–235. Springer, 1999. 4
1999
-
[8]
Token Merging: Your ViT But Faster
Daniel Bolya, Cheng-Yang Fu, Xiaoliang Dai, Peizhao Zhang, Christoph Feichtenhofer, and Judy Hoffman. To- ken merging: Your vit but faster.arXiv preprint arXiv:2210.09461, 2022. 2, 4
work page internal anchor Pith review arXiv 2022
-
[9]
Emerg- ing properties in self-supervised vision transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Herv ´e J´egou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerg- ing properties in self-supervised vision transformers. InPro- ceedings of the IEEE/CVF international conference on com- puter vision, pages 9650–9660, 2021. 4
2021
-
[10]
Re- gionvit: Regional-to-local attention for vision transformers
Chun-Fu Chen, Rameswar Panda, and Quanfu Fan. Re- gionvit: Regional-to-local attention for vision transformers. arXiv preprint arXiv:2106.02689, 2021. 2
-
[11]
Pre-trained image processing transformer
Hanting Chen, Yunhe Wang, Tianyu Guo, Chang Xu, Yip- ing Deng, Zhenhua Liu, Siwei Ma, Chunjing Xu, Chao Xu, and Wen Gao. Pre-trained image processing transformer. In Proceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 12299–12310, 2021. 1, 2, 6, 7
2021
-
[12]
Activating more pixels in image super- resolution transformer
Xiangyu Chen, Xintao Wang, Jiantao Zhou, Yu Qiao, and Chao Dong. Activating more pixels in image super- resolution transformer. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 22367–22377, 2023. 1, 2, 6, 7, 8
2023
-
[13]
Cross aggregation transformer for image restora- tion.Advances in Neural Information Processing Systems, 35:25478–25490, 2022
Zheng Chen, Yulun Zhang, Jinjin Gu, Linghe Kong, Xin Yuan, et al. Cross aggregation transformer for image restora- tion.Advances in Neural Information Processing Systems, 35:25478–25490, 2022. 1, 2, 4, 6, 7
2022
-
[14]
Zheng Chen, Yulun Zhang, Jinjin Gu, Linghe Kong, and Xiaokang Yang. Recursive generalization transformer for image super-resolution.arXiv preprint arXiv:2303.06373,
-
[15]
Ntire 2024 challenge on image super-resolution (x4): Methods and results
Zheng Chen, Zongwei Wu, Eduard Zamfir, Kai Zhang, Yu- lun Zhang, Radu Timofte, Xiaokang Yang, Hongyuan Yu, Cheng Wan, Yuxin Hong, et al. Ntire 2024 challenge on image super-resolution (x4): Methods and results. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6108–6132, 2024. 2
2024
-
[16]
Reference-based post-ocr processing with llm for precise di- acritic text in historical document recognition
Thao Do, Dinh Phu Tran, An V o, and Daeyoung Kim. Reference-based post-ocr processing with llm for precise di- acritic text in historical document recognition. InProceed- ings of the AAAI Conference on Artificial Intelligence, pages 27951–27959, 2025. 2
2025
-
[17]
Image super-resolution using deep convolutional net- works.IEEE transactions on pattern analysis and machine intelligence, 38(2):295–307, 2015
Chao Dong, Chen Change Loy, Kaiming He, and Xiaoou Tang. Image super-resolution using deep convolutional net- works.IEEE transactions on pattern analysis and machine intelligence, 38(2):295–307, 2015. 1, 2
2015
-
[18]
An image is worth 16x16 words: Transformers for image recognition at scale.ICLR, 2021
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Syl- vain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale.ICLR, 2021. 1
2021
-
[19]
Which tokens to use? investi- gating token reduction in vision transformers
Joakim Bruslund Haurum, Sergio Escalera, Graham W Tay- lor, and Thomas B Moeslund. Which tokens to use? investi- gating token reduction in vision transformers. InProceed- ings of the IEEE/CVF International Conference on Com- puter Vision, pages 773–783, 2023. 3
2023
-
[20]
Contrastive learning with adversarial examples.Advances in Neural Information Processing Systems, 33:17081–17093, 2020
Chih-Hui Ho and Nuno Nvasconcelos. Contrastive learning with adversarial examples.Advances in Neural Information Processing Systems, 33:17081–17093, 2020. 2, 5
2020
-
[21]
Probability inequalities for sums of bounded random variables.Journal of the American statisti- cal association, 58(301):13–30, 1963
Wassily Hoeffding. Probability inequalities for sums of bounded random variables.Journal of the American statisti- cal association, 58(301):13–30, 1963. 5
1963
-
[22]
Single image super-resolution from transformed self-exemplars
Jia-Bin Huang, Abhishek Singh, and Narendra Ahuja. Single image super-resolution from transformed self-exemplars. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 5197–5206, 2015. 6
2015
-
[23]
Lightweight image super-resolution with information multi- distillation network
Zheng Hui, Xinbo Gao, Yunchu Yang, and Xiumei Wang. Lightweight image super-resolution with information multi- distillation network. InProceedings of the 27th acm inter- national conference on multimedia, pages 2024–2032, 2019. 7
2024
-
[24]
Accurate image super-resolution using very deep convolutional net- works
Jiwon Kim, Jung Kwon Lee, and Kyoung Mu Lee. Accurate image super-resolution using very deep convolutional net- works. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 1646–1654, 2016. 1
2016
-
[25]
Deeply- recursive convolutional network for image super-resolution
Jiwon Kim, Jung Kwon Lee, and Kyoung Mu Lee. Deeply- recursive convolutional network for image super-resolution. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 1637–1645, 2016. 1
2016
-
[26]
Swinir: Image restoration us- ing swin transformer
Jingyun Liang, Jiezhang Cao, Guolei Sun, Kai Zhang, Luc Van Gool, and Radu Timofte. Swinir: Image restoration us- ing swin transformer. InProceedings of the IEEE/CVF inter- national conference on computer vision, pages 1833–1844,
-
[27]
Enhanced deep residual networks for single image super-resolution
Bee Lim, Sanghyun Son, Heewon Kim, Seungjun Nah, and Kyoung Mu Lee. Enhanced deep residual networks for single image super-resolution. InProceedings of the IEEE confer- ence on computer vision and pattern recognition workshops, pages 136–144, 2017. 1, 2, 6, 7
2017
-
[28]
Progressive focused transformer for single image super- resolution
Wei Long, Xingyu Zhou, Leheng Zhang, and Shuhang Gu. Progressive focused transformer for single image super- resolution. InProceedings of the Computer Vision and Pat- tern Recognition Conference, pages 2279–2288, 2025. 1, 2, 6, 7, 8
2025
-
[29]
Latticenet: Towards lightweight image super-resolution with lattice block
Xiaotong Luo, Yuan Xie, Yulun Zhang, Yanyun Qu, Cui- hua Li, and Yun Fu. Latticenet: Towards lightweight image super-resolution with lattice block. InEuropean conference on computer vision, pages 272–289. Springer, 2020. 7
2020
-
[30]
Sketch-based manga retrieval using manga109 dataset.Mul- timedia tools and applications, 76:21811–21838, 2017
Yusuke Matsui, Kota Ito, Yuji Aramaki, Azuma Fujimoto, Toru Ogawa, Toshihiko Yamasaki, and Kiyoharu Aizawa. Sketch-based manga retrieval using manga109 dataset.Mul- timedia tools and applications, 76:21811–21838, 2017. 6
2017
-
[31]
Some methods of classification and anal- ysis of multivariate observations
James B McQueen. Some methods of classification and anal- ysis of multivariate observations. InProc. of 5th Berkeley Symposium on Math. Stat. and Prob., pages 281–297, 1967. 6, 7
1967
-
[32]
Single image super-resolution via a holistic attention network
Ben Niu, Weilei Wen, Wenqi Ren, Xiangde Zhang, Lianping Yang, Shuzhen Wang, Kaihao Zhang, Xiaochun Cao, and Haifeng Shen. Single image super-resolution via a holistic attention network. InEuropean conference on computer vi- sion, pages 191–207. Springer, 2020. 2
2020
-
[33]
Dynamicvit: Efficient vision transformers with dynamic token sparsification.Advances in neural information processing systems, 34:13937–13949,
Yongming Rao, Wenliang Zhao, Benlin Liu, Jiwen Lu, Jie Zhou, and Cho-Jui Hsieh. Dynamicvit: Efficient vision transformers with dynamic token sparsification.Advances in neural information processing systems, 34:13937–13949,
-
[34]
Clustering by fast search and find of density peaks.science, 344(6191):1492– 1496, 2014
Alex Rodriguez and Alessandro Laio. Clustering by fast search and find of density peaks.science, 344(6191):1492– 1496, 2014. 3, 4, 6, 7
2014
-
[35]
Image processing gnn: Breaking rigidity in super-resolution
Yuchuan Tian, Hanting Chen, Chao Xu, and Yunhe Wang. Image processing gnn: Breaking rigidity in super-resolution. InProceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 24108–24117, 2024. 1, 2, 6, 7, 8
2024
-
[36]
Ntire 2017 challenge on single image super-resolution: Methods and results
Radu Timofte, Eirikur Agustsson, Luc Van Gool, Ming- Hsuan Yang, and Lei Zhang. Ntire 2017 challenge on single image super-resolution: Methods and results. InProceed- ings of the IEEE conference on computer vision and pattern recognition workshops, pages 114–125, 2017. 6
2017
-
[37]
Ntire 2018 challenge on single image super-resolution: Methods and results
Radu Timofte, Shuhang Gu, Jiqing Wu, and Luc Van Gool. Ntire 2018 challenge on single image super-resolution: Methods and results. InProceedings of the IEEE confer- ence on computer vision and pattern recognition workshops, pages 852–863, 2018. 2
2018
-
[38]
Trans2unet: Neural fusion for nuclei se- mantic segmentation
Dinh-Phu Tran, Quoc-Anh Nguyen, Van-Truong Pham, and Thi-Thao Tran. Trans2unet: Neural fusion for nuclei se- mantic segmentation. In2022 11th international conference on control, automation and information sciences (ICCAIS), pages 583–588. IEEE, 2022. 2
2022
-
[39]
Channel-partitioned windowed attention and frequency learning for single image super-resolution
Dinh Phu Tran, Dao Duy Hung, and Daeyoung Kim. Channel-partitioned windowed attention and frequency learning for single image super-resolution. In35th British Machine Vision Conference, BMVC 2024. BMV A Press,
2024
-
[40]
Vsrm: A robust mamba-based framework for video super- resolution
Dinh Phu Tran, Dao Duy Hung, and Daeyoung Kim. Vsrm: A robust mamba-based framework for video super- resolution. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 14711–14721, 2025. 1
2025
-
[41]
Maxvit: Multi-axis vision transformer
Zhengzhong Tu, Hossein Talebi, Han Zhang, Feng Yang, Peyman Milanfar, Alan Bovik, and Yinxiao Li. Maxvit: Multi-axis vision transformer. InEuropean conference on computer vision, pages 459–479. Springer, 2022. 2
2022
-
[42]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszko- reit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017. 2, 3, 6, 7
2017
-
[43]
Omni aggregation networks for lightweight im- age super-resolution
Hang Wang, Xuanhong Chen, Bingbing Ni, Yutian Liu, and Jinfan Liu. Omni aggregation networks for lightweight im- age super-resolution. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 22378–22387, 2023. 7
2023
-
[44]
Pyramid vision transformer: A versatile backbone for dense prediction without convolutions
Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, and Ling Shao. Pyramid vision transformer: A versatile backbone for dense prediction without convolutions. InProceedings of the IEEE/CVF international conference on computer vision, pages 568–578, 2021. 2, 6, 7
2021
-
[45]
Image quality assessment: from error visibility to structural similarity.IEEE transactions on image processing, 13(4):600–612, 2004
Zhou Wang, Alan C Bovik, Hamid R Sheikh, and Eero P Si- moncelli. Image quality assessment: from error visibility to structural similarity.IEEE transactions on image processing, 13(4):600–612, 2004. 6
2004
-
[46]
Evo-vit: Slow-fast token evolution for dynamic vision transformer
Yifan Xu, Zhijie Zhang, Mengdan Zhang, Kekai Sheng, Ke Li, Weiming Dong, Liqing Zhang, Changsheng Xu, and Xing Sun. Evo-vit: Slow-fast token evolution for dynamic vision transformer. InProceedings of the AAAI conference on artificial intelligence, pages 2964–2972, 2022. 2
2022
-
[47]
Scalablevit: Rethinking the context-oriented generalization of vision transformer
Rui Yang, Hailong Ma, Jie Wu, Yansong Tang, Xuefeng Xiao, Min Zheng, and Xiu Li. Scalablevit: Rethinking the context-oriented generalization of vision transformer. In European Conference on Computer Vision, pages 480–496. Springer, 2022. 2
2022
-
[48]
On sin- gle image scale-up using sparse-representations
Roman Zeyde, Michael Elad, and Matan Protter. On sin- gle image scale-up using sparse-representations. InInterna- tional conference on curves and surfaces, pages 711–730. Springer, 2010. 6
2010
-
[49]
Jiale Zhang, Yulun Zhang, Jinjin Gu, Yongbing Zhang, Linghe Kong, and Xin Yuan. Accurate image restora- tion with attention retractable transformer.arXiv preprint arXiv:2210.01427, 2022. 1
-
[50]
Transcending the limit of local window: Ad- vanced super-resolution transformer with adaptive token dic- tionary
Leheng Zhang, Yawei Li, Xingyu Zhou, Xiaorui Zhao, and Shuhang Gu. Transcending the limit of local window: Ad- vanced super-resolution transformer with adaptive token dic- tionary. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2856–2865,
-
[51]
Efficient long-range attention network for image super- resolution
Xindong Zhang, Hui Zeng, Shi Guo, and Lei Zhang. Efficient long-range attention network for image super- resolution. InEuropean conference on computer vision, pages 649–667. Springer, 2022. 7
2022
-
[52]
Image super-resolution using very deep residual channel attention networks
Yulun Zhang, Kunpeng Li, Kai Li, Lichen Wang, Bineng Zhong, and Yun Fu. Image super-resolution using very deep residual channel attention networks. InProceedings of the European conference on computer vision (ECCV), pages 286–301, 2018. 1, 2, 6, 7
2018
-
[53]
Residual dense network for image super-resolution
Yulun Zhang, Yapeng Tian, Yu Kong, Bineng Zhong, and Yun Fu. Residual dense network for image super-resolution. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 2472–2481, 2018. 1
2018
-
[54]
Ntire 2023 challenge on image super- resolution (x4): Methods and results
Yulun Zhang, Kai Zhang, Zheng Chen, Yawei Li, Radu Tim- ofte, Junpei Zhang, Kexin Zhang, Rui Peng, Yanbiao Ma, Licheng Jia, et al. Ntire 2023 challenge on image super- resolution (x4): Methods and results. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1865–1884, 2023. 2
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.