Recognition: 2 theorem links
· Lean TheoremComponent-Adaptive and Lesion-Level Supervision for Improved Small Structure Segmentation in Brain MRI
Pith reviewed 2026-05-10 18:30 UTC · model grok-4.3
The pith
A unified loss combining component-adaptive reweighting and lesion-level supervision improves small lesion segmentation in brain MRI.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
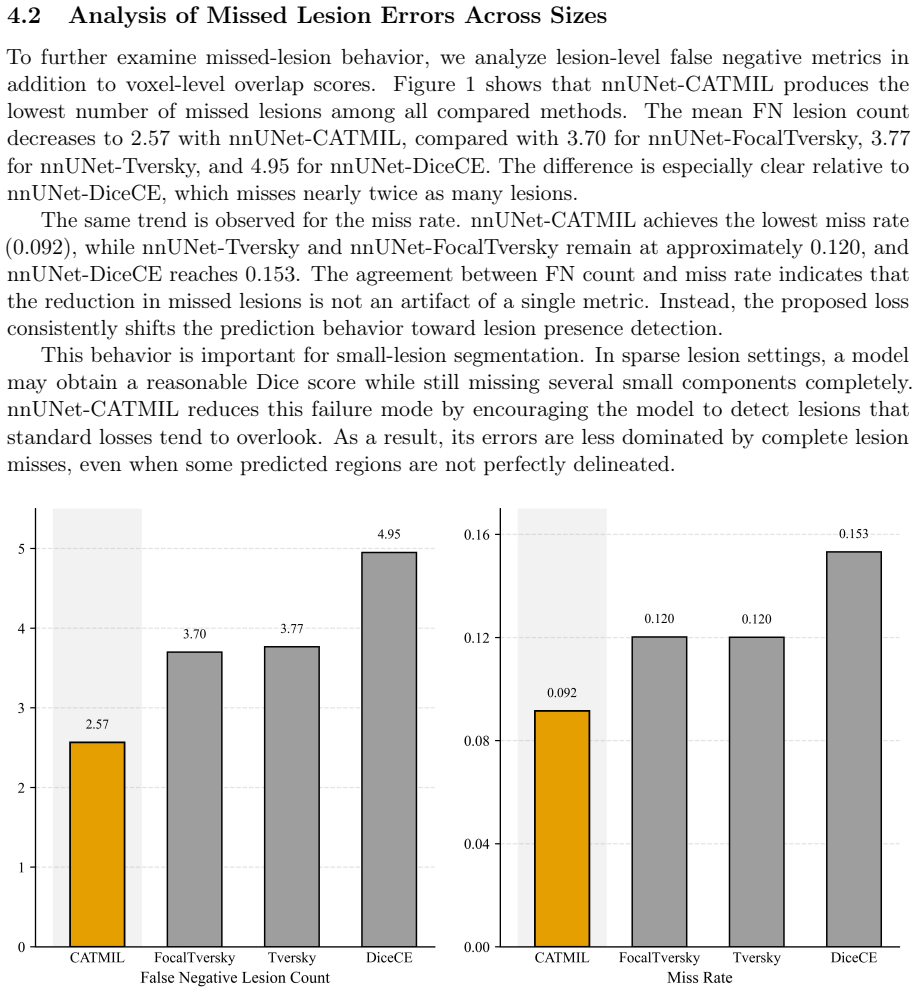
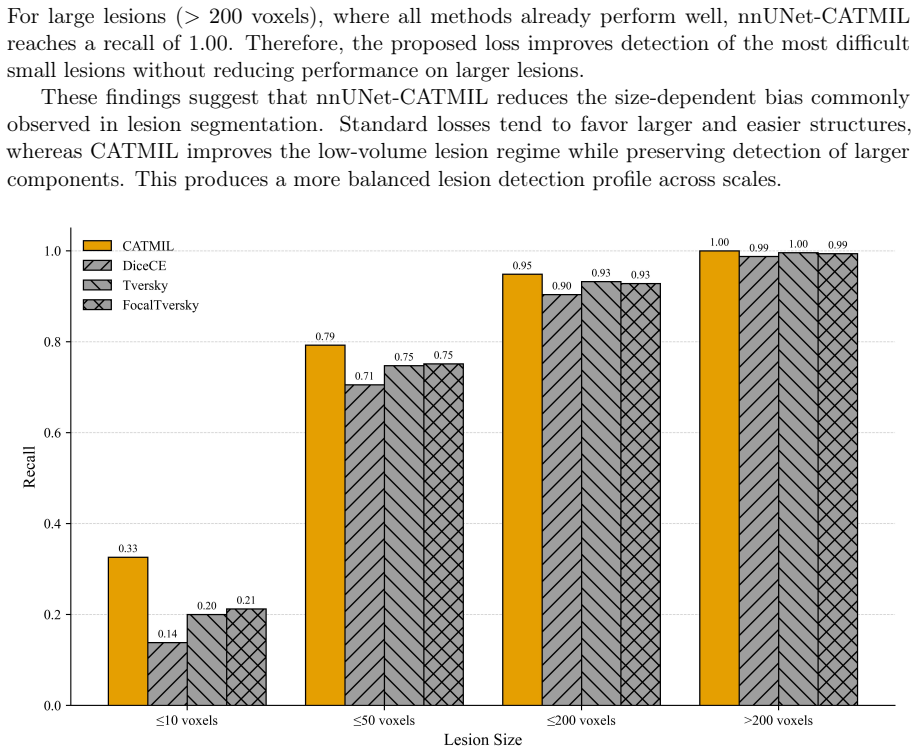
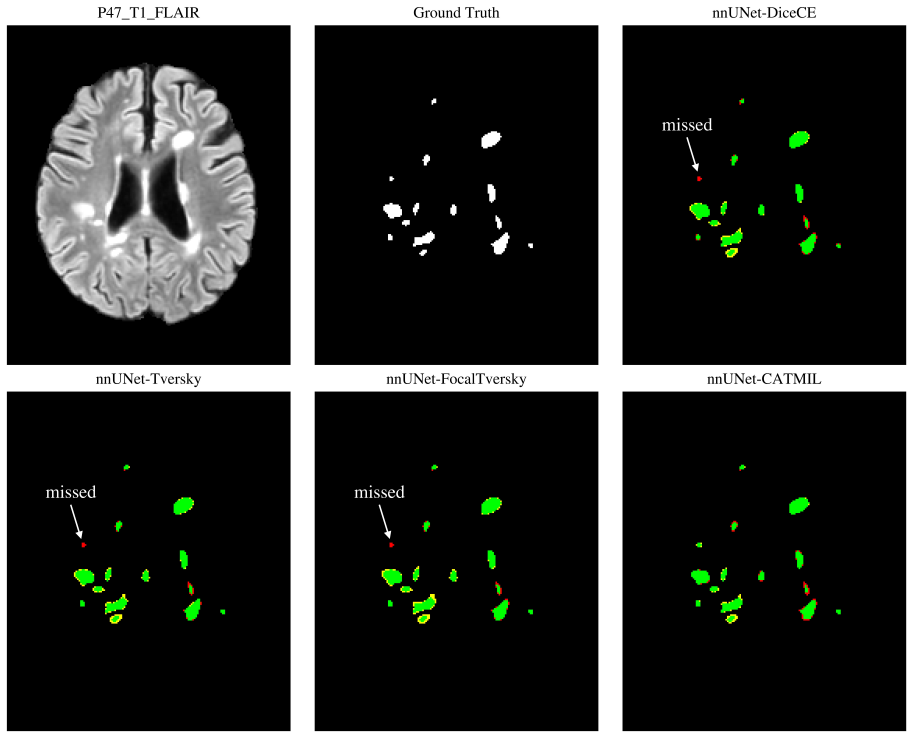
The paper claims that integrating component-level size balancing and lesion-instance detection into one training objective yields more balanced performance than standard losses alone, with concrete gains in Dice score, boundary accuracy, small-lesion recall, and false-positive control on the MSLesSeg dataset under a fixed nnU-Net backbone and five-fold cross-validation.
What carries the argument
CATMIL objective: nnU-Net base loss plus Component-Adaptive Tversky term that reweights voxel contributions by connected-component size and a Multiple Instance Learning term that supplies lesion-level supervision for each instance.
If this is right
- Dice score reaches 0.7834 with reduced boundary error relative to baselines.
- Small-lesion recall rises substantially and false negatives fall.
- False-positive volume remains the lowest among the compared methods.
- The approach supplies a practical route to handle extreme class imbalance without altering network architecture.
Where Pith is reading between the lines
- The same two-term supervision pattern could be applied to other medical imaging tasks that involve sparse small targets such as micro-calcifications or small tumors.
- An ablation that removes only the component-adaptive term or only the MIL term would isolate which supervision level drives most of the recall improvement.
- The method assumes connected-component extraction is computationally affordable during every training step, which may limit scaling to extremely high-resolution volumes.
Load-bearing premise
The measured gains in Dice, recall and false-positive volume are produced by the two added supervision terms rather than by dataset-specific tuning or the nnU-Net backbone itself.
What would settle it
Train the identical nnU-Net architecture on the same MSLesSeg five-fold splits using only the standard loss and verify whether small-lesion recall and overall Dice drop below the reported CATMIL values.
Figures


read the original abstract
We propose a unified objective function, termed CATMIL, that augments the base segmentation loss with two auxiliary supervision terms operating at different levels. The first term, Component-Adaptive Tversky, reweights voxel contributions based on connected components to balance the influence of lesions of different sizes. The second term, based on Multiple Instance Learning, introduces lesion-level supervision by encouraging the detection of each lesion instance. These terms are combined with the standard nnU-Net loss to jointly optimize voxel-level segmentation accuracy and lesion-level detection. We evaluate the proposed objective on the MSLesSeg dataset using a consistent nnU-Net framework and 5-fold cross-validation. The results show that CATMIL achieves the most balanced performance across segmentation accuracy, lesion detection, and error control. It improves Dice score (0.7834) and reduces boundary error compared to standard losses. More importantly, it substantially increases small lesion recall and reduces false negatives, while maintaining the lowest false positive volume among compared methods. These findings demonstrate that integrating component-level and lesion-level supervision within a unified objective provides an effective and practical approach for improving small lesion segmentation in highly imbalanced settings. All code and pretrained models are available at https://github.com/luumsk/SmallLesionMRI.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CATMIL, a unified loss augmenting standard nnU-Net segmentation with a Component-Adaptive Tversky term (reweighting voxels by connected-component size) and an MIL-based lesion-level supervision term. On the MSLesSeg dataset with 5-fold cross-validation, it reports a Dice score of 0.7834, improved small-lesion recall, reduced boundary error, and the lowest false-positive volume among compared methods, claiming that the dual supervision terms provide an effective approach for small-structure segmentation under class imbalance. Code and models are released.
Significance. If the attribution holds, the work supplies a practical, plug-in objective for handling extreme size imbalance in medical segmentation without changing the backbone. The public release of code, pretrained models, and the consistent nnU-Net 5-fold protocol is a clear strength that enables direct verification and extension.
major comments (2)
- [Experiments and Results] The central claim attributes the reported gains (Dice 0.7834, small-lesion recall, lowest FP volume) to the two auxiliary terms, yet the manuscript provides no ablation numbers isolating the Component-Adaptive Tversky term or the MIL term, nor any description of how the auxiliary loss weights were chosen or tuned. Without these, it remains unclear whether the improvements exceed what could be obtained by hyper-parameter search on the base nnU-Net loss alone.
- [Evaluation on MSLesSeg] No statistical significance tests, confidence intervals, or paired comparisons across the 5 folds are reported for the metric differences. This weakens the assertion that CATMIL achieves the 'most balanced performance' relative to the baselines.
minor comments (1)
- [Abstract] The abstract refers to 'boundary error' without naming the metric (e.g., 95th-percentile Hausdorff distance or average surface distance); the main text should define it explicitly and report the corresponding numbers.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and the recommendation of minor revision. We address each major comment below and will update the manuscript accordingly.
read point-by-point responses
-
Referee: [Experiments and Results] The central claim attributes the reported gains (Dice 0.7834, small-lesion recall, lowest FP volume) to the two auxiliary terms, yet the manuscript provides no ablation numbers isolating the Component-Adaptive Tversky term or the MIL term, nor any description of how the auxiliary loss weights were chosen or tuned. Without these, it remains unclear whether the improvements exceed what could be obtained by hyper-parameter search on the base nnU-Net loss alone.
Authors: We agree that explicit ablations and loss-weight details are needed to strengthen attribution. In the revised manuscript we will add an ablation study isolating the Component-Adaptive Tversky term, the MIL term, and their combination, together with a description of the grid-search procedure used to select the auxiliary weights on a validation subset. These additions will clarify that the observed gains exceed those obtainable by tuning the base nnU-Net loss alone. revision: yes
-
Referee: [Evaluation on MSLesSeg] No statistical significance tests, confidence intervals, or paired comparisons across the 5 folds are reported for the metric differences. This weakens the assertion that CATMIL achieves the 'most balanced performance' relative to the baselines.
Authors: We acknowledge the absence of statistical analysis. The revised version will report 95 % confidence intervals (mean ± std across folds) for all metrics and will include paired statistical tests (t-test or Wilcoxon signed-rank) between CATMIL and each baseline. These results will provide quantitative support for the claim of most balanced performance. revision: yes
Circularity Check
No significant circularity
full rationale
The manuscript is a purely empirical contribution that defines a composite loss (CATMIL) by combining a standard nnU-Net segmentation loss with two explicitly stated auxiliary terms (component-adaptive Tversky reweighting and MIL lesion-level supervision). No derivation, uniqueness theorem, or first-principles prediction is claimed; performance numbers are obtained from 5-fold cross-validation on a held-out dataset and are not asserted to follow from the loss by algebraic identity. No self-citations appear in the provided text, and the method does not rename or smuggle in prior fitted quantities as new predictions. The central claim therefore remains independent of its own inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- auxiliary loss weights
axioms (1)
- domain assumption nnU-Net provides a stable, high-performing baseline segmentation architecture
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose a unified objective function, termed CATMIL, that augments the base segmentation loss with two auxiliary supervision terms... Component-Adaptive Tversky... Multiple Instance Learning
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
U-Net: Convolutional Networks for Biomedical Image Segmentation
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Nassir Navab, Joachim Hornegger, William M. Wells, and Alejandro F. Frangi, editors,Medical Image Computing and Computer-Assisted Intervention – MICCAI 2015, volume 9351, pages 234–241. Springer International Publishing, Cham,
2015
-
[2]
In: Medical Image Compu ting and Computer-Assisted Intervention – MICCAI 2015
ISBN 978-3-319-24573-7 978-3-319-24574-4. doi: 10.1007/978-3-319-24574-4_28. URL http://link.springer.com/10.1007/978-3-319-24574-4_28. Series Title: Lecture Notes in Computer Science
-
[3]
Jaeger, Simon A
Fabian Isensee, Paul F. Jaeger, Simon A. A. Kohl, Jens Petersen, and Klaus H. Maier-Hein. nnU-Net: a self-configuring method for deep learning-based biomedical image segmentation. Nature Methods, 18(2):203–211, February 2021. ISSN 1548-7091, 1548-7105. doi: 10.1038/ s41592-020-01008-z. URLhttps://www.nature.com/articles/s41592-020-01008-z. 14
2021
-
[4]
UNETR: Transformers for 3D Medical Image Segmentation, 2021
Ali Hatamizadeh, Yucheng Tang, Vishwesh Nath, Dong Yang, Andriy Myronenko, Bennett Landman, Holger Roth, and Daguang Xu. UNETR: Transformers for 3D Medical Image Segmentation, 2021. URLhttps://arxiv.org/abs/2103.10504. Version Number: 3
-
[5]
arXiv preprint arXiv:2201.01266 , year=
Ali Hatamizadeh, Vishwesh Nath, Yucheng Tang, Dong Yang, Holger Roth, and Daguang Xu. Swin UNETR: Swin Transformers for Semantic Segmentation of Brain Tumors in MRI Images, 2022. URLhttps://arxiv.org/abs/2201.01266. Version Number: 1
-
[6]
Tverskylossfunctionforimagesegmentationusing3dfullyconvolutionaldeepnetworks
Seyed Sadegh Mohseni Salehi, Deniz Erdogmus, and Ali Gholipour. Tversky loss function for image segmentation using 3D fully convolutional deep networks, 2017. URLhttps: //arxiv.org/abs/1706.05721. Version Number: 1
-
[7]
Focal Loss for Dense Object Detection
Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Dollár. Focal Loss for Dense Object Detection, 2017. URL https://arxiv.org/abs/1708.02002. Version Number: 2
work page Pith review arXiv 2017
-
[8]
A Novel Focal Tversky Loss Function With Improved Attention U-Net for Lesion Segmentation
Nabila Abraham and Naimul Mefraz Khan. A Novel Focal Tversky Loss Function With Improved Attention U-Net for Lesion Segmentation. In2019 IEEE 16th International Symposium on Biomedical Imaging (ISBI 2019), pages 683–687, Venice, Italy, April 2019. IEEE. ISBN978-1-5386-3641-1. doi: 10.1109/ISBI.2019.8759329. URLhttps://ieeexplore. ieee.org/document/8759329/
-
[9]
Michael Yeung, Leonardo Rundo, Yang Nan, Evis Sala, Carola-Bibiane Schönlieb, and Guang Yang. Calibrating the Dice Loss to Handle Neural Network Overconfidence for Biomedical Image Segmentation.Journal of Digital Imaging, 36(2):739–752, April 2023. ISSN 1618-727X. doi: 10.1007/s10278-022-00735-3
-
[10]
Tun Wiltgen, Julian McGinnis, Sarah Schlaeger, Florian Kofler, CuiCi Voon, Achim Berthele, Daria Bischl, Lioba Grundl, Nikolaus Will, Marie Metz, David Schinz, Dominik Sepp, Philipp Prucker, Benita Schmitz-Koep, Claus Zimmer, Bjoern Menze, Daniel Rueckert, Bernhard Hemmer, Jan Kirschke, Mark Mühlau, and Benedikt Wiestler. LST-AI: A deep learning ensemble ...
-
[11]
Mullins, Pietro Maggi, Sarah Levy, Kamso Onyemeh, Batuhan Ayci, Andrew J
Emma Dereskewicz, Francesco La Rosa, Jonadab Dos Santos Silva, Edward Sizer, Amit Kohli, Maxence Wynen, William A. Mullins, Pietro Maggi, Sarah Levy, Kamso Onyemeh, Batuhan Ayci, Andrew J. Solomon, Jakob Assländer, Omar Al-Louzi, Daniel S. Reich, James Sumowski, and Erin S. Beck. FLAMeS: A Robust Deep Learning Model for Automated Multiple Sclerosis Lesion...
-
[12]
Seyed Raein Hashemi, Seyed Sadegh Mohseni Salehi, Deniz Erdogmus, Sanjay P. Prabhu, Simon K. Warfield, and Ali Gholipour. Asymmetric Loss Functions and Deep Densely- Connected Networks for Highly-Imbalanced Medical Image Segmentation: Application to Multiple Sclerosis Lesion Detection.IEEE Access, 7:1721–1735, 2019. ISSN 2169-3536. doi: 10.1109/ACCESS.201...
-
[13]
Yizheng Chen, Lequan Yu, Jen-Yeu Wang, Neil Panjwani, Jean-Pierre Obeid, Wu Liu, Lianli Liu, Nataliya Kovalchuk, Michael Francis Gensheimer, Lucas Kas Vitzthum, Beth M. Beadle, Daniel T. Chang, Quynh-Thu Le, Bin Han, and Lei Xing. Adaptive Region-Specific Loss for Improved Medical Image Segmentation.IEEE transactions on pattern analysis and machine intell...
-
[14]
Region-wise loss for biomedical image segmentation
Juan Miguel Valverde and Jussi Tohka. Region-wise loss for biomedical image segmentation. Pattern Recognition, 136:109208, April 2023. ISSN 00313203. doi: 10.1016/j.patcog.2022. 109208. URLhttps://linkinghub.elsevier.com/retrieve/pii/S0031320322006872
-
[15]
Sweeney, Pascal Spincemaille, Thanh D
Hang Zhang, Jinwei Zhang, Chao Li, Elizabeth M. Sweeney, Pascal Spincemaille, Thanh D. Nguyen, Susan A. Gauthier, Yi Wang, and Melanie Marcille. ALL-Net: Anatomical informa- tion lesion-wise loss function integrated into neural network for multiple sclerosis lesion seg- mentation.NeuroImage: Clinical, 32:102854, 2021. ISSN 22131582. doi: 10.1016/j.nicl.20...
-
[16]
Muhammad Aqib Javed, Muhammad Khuram Shahzad, and Hafiz Syed Muhammad Bilal Ali. A novel regularization approach for loss functions to reduce instance imbalance in biomedical image segmentation.Computational Biology and Chemistry, 119:108555, December 2025. ISSN 14769271. doi: 10.1016/j.compbiolchem.2025.108555. URL https://linkinghub. elsevier.com/retrie...
-
[17]
Haofeng Liu, Shuiping Gou, Yanyan Zhou, Changzhe Jiao, Wenbo Liu, Mei Shi, and Zhonghua Luo. Object knowledge-aware multiple instance learning for small tumor segmen- tation.Biomedical Signal Processing and Control, 115:109400, April 2026. ISSN 17468094. doi: 10.1016/j.bspc.2025.109400. URL https://linkinghub.elsevier.com/retrieve/ pii/S1746809425019111
-
[18]
Chenshen Huang, Haoyun Xia, Xi Xiao, Hong Chen, Yiqing Jiang, Yahui Lyu, Zhizhan Ni, Tianyang Wang, Ning Wang, and Qi Huang. Geometric multi-instance learning for weakly supervised gastric cancer segmentation.npj Digital Medicine, 9(1):101, January 2026. ISSN 2398-6352. doi: 10.1038/s41746-025-02287-6. URL https://www.nature.com/articles/ s41746-025-02287-6
-
[19]
Rodney Long, Mark Schiffman, and Sameer Antani
Anabik Pal, Zhiyun Xue, Kanan Desai, Adekunbiola Aina F Banjo, Clement Akinfolarin Adepiti, L. Rodney Long, Mark Schiffman, and Sameer Antani. Deep multiple-instance learning for abnormal cell detection in cervical histopathology images.Computers in Biology and Medicine, 138:104890, November 2021. ISSN 00104825. doi: 10.1016/j.compbiomed.2021. 104890. URL...
-
[20]
Francesco Guarnera, Alessia Rondinella, Elena Crispino, Giulia Russo, Clara Di Lorenzo, Davide Maimone, Francesco Pappalardo, and Sebastiano Battiato. MSLesSeg: baseline and benchmarking of a new Multiple Sclerosis Lesion Segmentation dataset.Scientific Data, 12(1):920, May 2025. ISSN 2052-4463. doi: 10.1038/s41597-025-05250-y. URL https://www.nature.com/...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.