Recognition: unknown
A Full-Stack Performance Evaluation Infrastructure for 3D-DRAM-based LLM Accelerators
Pith reviewed 2026-05-10 17:22 UTC · model grok-4.3
The pith
ATLAS accurately simulates 3D-DRAM-based LLM accelerators with at most 8.57% error versus real silicon.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that ATLAS constitutes a reusable, full-stack performance evaluation infrastructure for 3D-DRAM-based LLM accelerators. Built on deployed multi-layer 3D-DRAM, it employs unified abstractions for system architecture and programming primitives to support arbitrary inference scenarios. Silicon validation establishes a maximum simulation error of 8.57 percent together with performance correlations of 97.26 to 99.96 percent. Design space exploration performed with ATLAS produces concrete guidance for both the 3D-DRAM memory subsystem and the accelerator microarchitecture.
What carries the argument
Unified abstractions for the 3D-Accelerator system architecture and its programming primitives, which carry the generality needed to model diverse LLM inference workloads.
Load-bearing premise
The unified abstractions for 3D-Accelerator system architecture and programming primitives are general enough to accurately model arbitrary LLM inference scenarios without missing critical behaviors or needing custom changes.
What would settle it
A direct comparison of ATLAS predictions against hardware measurements for an LLM inference scenario outside the validation set; if the error rate substantially exceeds 8.57 percent, the claim of general applicability would be falsified.
Figures











read the original abstract
Large language models (LLMs) exhibit memory-intensive behavior during decoding, making it a key bottleneck in LLM inference. To accelerate decoding execution, hybrid-bonding-based 3D-DRAM has been adopted in LLM accelerators. While this emerging technology provides strong performance gains over existing hardware, current 3D-DRAM accelerators (3D-Accelerators) rely on closed-source evaluation tools, limiting access to publicly available performance analysis methods. Moreover, existing designs are highly customized for specific scenarios, lacking a general and reusable full-stack modeling for 3D-Accelerators across diverse usecases. To bridge this fundamental gap, we present ATLAS, the first silicon-proven Architectural Three-dimesional-DRAM-based LLM Accelerator Simulation framework. Built on commercially deployed multi-layer 3D-DRAM technology, ATLAS introduces unified abstractions for both 3D-Accelerator system architecture and programming primitives to support arbitrary LLM inference scenarios. Validation against real silicon shows that ATLAS achieves $\le$8.57% simulation error and 97.26-99.96\% correlation with measured performance. Through design space exploration with ATLAS, we demonstrate its ability to guide architecture design and distill key takeaways for both 3D-DRAM memory system and 3D-Accelerator microarchitecture across scenarios. ATLAS will be open-sourced upon publication, enabling further research on 3D-Accelerators.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces ATLAS, the first silicon-proven full-stack simulation framework for 3D-DRAM-based LLM accelerators. It provides unified abstractions for the 3D-accelerator system architecture and programming primitives to support arbitrary LLM inference scenarios. Validation against real silicon shows ≤8.57% simulation error and 97.26-99.96% correlation with measured performance. The authors perform design space exploration (DSE) with ATLAS to guide architecture design and distill key takeaways for both 3D-DRAM memory systems and 3D-accelerator microarchitectures across scenarios. The framework is planned to be open-sourced.
Significance. If the abstractions prove accurate beyond the validated baselines, ATLAS would provide a valuable public tool for performance evaluation of emerging 3D-DRAM accelerators, addressing the current reliance on closed-source tools. The reported silicon correlation and the DSE results could enable reproducible research and informed design decisions in memory-intensive LLM inference hardware.
major comments (3)
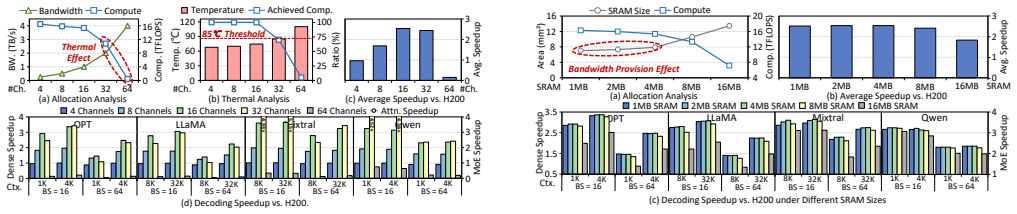
- [§4] §4 (Validation results): The reported ≤8.57% error and 97.26-99.96% correlation are measured against existing 3D-Accelerator implementations. No evidence is provided that the same accuracy holds for the novel microarchitecture and 3D-DRAM parameter variations explored in the DSE, which is load-bearing for the claim that ATLAS can reliably guide architecture design.
- [§5] §5 (Design space exploration): The distilled takeaways for 3D-DRAM scheduling and accelerator microarchitecture (e.g., attention-specific access patterns, thermal effects in stacking) rest on the assumption that the unified abstractions capture all critical behaviors without scenario-specific adjustments. No sensitivity analysis or additional validation cases are shown for these altered configurations.
- [§3] §3 (Framework abstractions): The assertion that the unified abstractions for system architecture and programming primitives are general enough for arbitrary LLM inference scenarios is not supported by concrete tests demonstrating that no critical interactions are missed when microarchitecture or memory parameters change.
minor comments (2)
- [Abstract] Abstract: 'Three-dimesional' is a typographical error and should read 'Three-dimensional'.
- [Throughout] Ensure that all DSE parameters, validation configurations, and correlation metrics are fully tabulated with explicit definitions to allow independent reproduction.
Simulated Author's Rebuttal
We thank the referee for the insightful comments. We have prepared point-by-point responses and revised the manuscript to address the concerns raised.
read point-by-point responses
-
Referee: [§4] §4 (Validation results): The reported ≤8.57% error and 97.26-99.96% correlation are measured against existing 3D-Accelerator implementations. No evidence is provided that the same accuracy holds for the novel microarchitecture and 3D-DRAM parameter variations explored in the DSE, which is load-bearing for the claim that ATLAS can reliably guide architecture design.
Authors: We agree with the referee that the accuracy is demonstrated for the validated baselines. The DSE results are intended to provide relative comparisons and insights rather than absolute performance numbers for unbuilt designs. To strengthen this, we have revised §4 to explicitly note this limitation and added a sensitivity analysis for key microarchitecture and DRAM parameters. This allows readers to assess the robustness. revision: partial
-
Referee: [§5] §5 (Design space exploration): The distilled takeaways for 3D-DRAM scheduling and accelerator microarchitecture (e.g., attention-specific access patterns, thermal effects in stacking) rest on the assumption that the unified abstractions capture all critical behaviors without scenario-specific adjustments. No sensitivity analysis or additional validation cases are shown for these altered configurations.
Authors: The takeaways in §5 are derived from the DSE using the validated abstractions. We have now included sensitivity analysis in the revised §5 for the mentioned aspects such as attention-specific patterns and thermal effects. Additional validation cases for altered configurations have been added using cross-checks with analytical models to confirm the behaviors captured. revision: yes
-
Referee: [§3] §3 (Framework abstractions): The assertion that the unified abstractions for system architecture and programming primitives are general enough for arbitrary LLM inference scenarios is not supported by concrete tests demonstrating that no critical interactions are missed when microarchitecture or memory parameters change.
Authors: The unified abstractions are tested across multiple LLM inference scenarios in the paper, including different models and hardware configs. To address the request for concrete tests on parameter changes, we have expanded §3 with additional experiments varying microarchitecture and memory parameters, showing that critical interactions are captured without scenario-specific adjustments. revision: yes
Circularity Check
No circularity; externally validated simulation framework with independent validation data
full rationale
The paper presents ATLAS as a modeling infrastructure built on commercially deployed 3D-DRAM hardware. Its central claims rest on direct comparison to real silicon measurements (≤8.57% error, 97.26-99.96% correlation) rather than any fitted parameter renamed as prediction or self-referential definition. Design-space takeaways are outputs of the simulator applied to new configurations; they do not reduce to the validation set by construction. No equations, uniqueness theorems, or self-citations are invoked as load-bearing premises. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
The groq software-defined scale-out tensor streaming multiprocessor: From chips- to-systems architectural overview
Dennis Abts, John Kim, Garrin Kimmell, Matthew Boyd, Kris Kang, Sahil Par- mar, Andrew Ling, Andrew Bitar, Ibrahim Ahmed, and Jonathan Ross. The groq software-defined scale-out tensor streaming multiprocessor: From chips- to-systems architectural overview. In2022 IEEE Hot Chips 34 Symposium (HCS), pages 1–69. IEEE, 2022
2022
-
[2]
Deepseek
DeepSeek AI. Deepseek. https://chat.deepseek.com/, 2026
2026
-
[3]
GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints
Joshua Ainslie, James Lee-Thorp, Michiel de Jong, Yury Zemlyanskiy, Federico Lebrón, and Sumit Sanghai. Gqa: Training generalized multi-query transformer models from multi-head checkpoints.arXiv preprint arXiv:2305.13245, 2023
work page internal anchor Pith review arXiv 2023
-
[4]
Iris: First-class multi-gpu programming experience in triton
AMD. Iris: First-class multi-gpu programming experience in triton. https: //github.com/ROCm/iris, 2026
2026
-
[5]
Anthropic. Claude. https://www.anthropic.com/claude, 2026
2026
-
[6]
Characterizing cloud-native llm inference at bytedance and exposing opti- mization challenges and opportunities for future ai accelerators
Jingwei Cai, Dehao Kong, Hantao Huang, Zishan Jiang, Zixuan Ma, Qingyu Guo, Zhenxing Zhang, Guiming Shi, Mingyu Gao, Kaisheng Ma, and Minghui Yu. Characterizing cloud-native llm inference at bytedance and exposing opti- mization challenges and opportunities for future ai accelerators. In2026 IEEE International Symposium on High Performance Computer Archit...
2026
-
[7]
A 1.2 ghz 12.77 gb/s/mm 2 3d two-dram-one-logic process-near-memory chip for edge llm applications
Yue Cao, Jinghao Jiang, Haijun Jiang, Qian Zhang, Xuanzhi Liu, Jinhui Cheng, Zhongze Han, Xiping Jiang, Fengguo Zuo, Song Wang, Fujun Bai, Yixin Guo, Chunmeng Dou, Jianguo Yang, Hangbing Lv, Qi Liu, and Ming Liu. A 1.2 ghz 12.77 gb/s/mm 2 3d two-dram-one-logic process-near-memory chip for edge llm applications. In2026 IEEE International Solid-State Circui...
2026
-
[8]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[9]
Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebas- tian Gehrmann, Parker Schuh, Kensen Shi, Sasha Tsvyashchenko, Joshua Maynez, Abhishek Rao, Parker Barnes, Yi Tay, Noam Shazeer, Vinodkumar Prabhakaran, Emily Reif, Nan Du, Ben Hutchinson, Reiner Pope, James Bra...
work page internal anchor Pith review arXiv 2022
-
[10]
Compute express link specification revision 3.0
CXL Consortium. Compute express link specification revision 3.0. https://www. computeexpresslink.org/download-the-specification, 2026
2026
-
[11]
Flash-decoding for long-context inference
Tri Dao, Daniel Haziza, Francisco Massa, and Grigory Sizov. Flash-decoding for long-context inference. https://crfm.stanford.edu/2023/10/12/flashdecoding.html, 2023
2023
-
[12]
Deepseek-v3 technical report, 2024
DeepSeek-AI. Deepseek-v3 technical report, 2024
2024
-
[13]
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ah- mad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, Anirudh Goyal, Anthony Hartshorn, Aobo Yang, Archi Mitra, Archie Sra- vankumar, Artem Korenev, Arthur Hinsvark, Arun Rao, Aston Zhang, Aurelien Rodriguez, Austen Gregerson, Ava Spataru, Baptiste Roziere, Bet...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
Yuanning Feng, Sinan Wang, Zhengxiang Cheng, Yao Wan, and Dongping Chen
Zane Durante, Qiuyuan Huang, Naoki Wake, Ran Gong, Jae Sung Park, Bidipta Sarkar, Rohan Taori, Yusuke Noda, Demetri Terzopoulos, Yejin Choi, Katsushi Ikeuchi, Hoi Vo, Li Fei-Fei, and Jianfeng Gao. Agent ai: Surveying the horizons of multimodal interaction.arXiv preprint arXiv:2401.03568, 2024
-
[15]
A stacked embedded dram array for lpddr4/4x using hybrid bonding 3d integration with 34gb/s/1gb 0.88 pj/b logic-to-memory interface
Bai Fujun, Jiang Xiping, Wang Song, Yu Bing, Tan Jie, Zuo Fengguo, Wang Chunjuan, Wang Fan, Long Xiaodong, Yu Guoqing, Fu Ni, Li Qiannan, Li Hua, Wang Kexin, Duan Huifu, Bai Liang, Jia Xuerong, Li Jin, Li Mei, Wang Zhengwen, Hu Sheng, Zhou Jun, Zhan Qiong, Sun Peng, Yang Daohong, Cheichan Kau, David Yang, Ching-Sung Ho, Sun Hongbin, Lv Hangbing, Liu Ming,...
2020
-
[16]
Rdma over ethernet for distributed training at meta scale
Adithya Gangidi, Rui Miao, Shengbao Zheng, Sai Jayesh Bondu, Guilherme Goes, Hany Morsy, Rohit Puri, Mohammad Riftadi, Ashmitha Jeevaraj Shetty, Jingyi Yang, Shuqiang Zhang, Mikel Jimenez Fernandez, Shashidhar Gandham, and Hongyi Zeng. Rdma over ethernet for distributed training at meta scale. In Proceedings of the ACM SIGCOMM 2024 Conference, pages 57–70, 2024
2024
-
[17]
Google. Gemini. https://gemini.google.com/app, 2026
2026
-
[18]
Pim is all you need: A cxl-enabled gpu- free system for large language model inference
Yufeng Gu, Alireza Khadem, Sumanth Umesh, Ning Liang, Xavier Servot, Onur Mutlu, Ravi Iyer, and Reetuparna Das. Pim is all you need: A cxl-enabled gpu- free system for large language model inference. InProceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2, pages 862–881, 2025
2025
-
[19]
From 2.5 d to 3d chiplet systems: Investigation of thermal implications with hotspot 7.0
Jun-Han Han, Xinfei Guo, Kevin Skadron, and Mircea R Stan. From 2.5 d to 3d chiplet systems: Investigation of thermal implications with hotspot 7.0. In2022 21st IEEE Intersociety Conference on Thermal and Thermomechanical Phenomena in Electronic Systems (iTherm), pages 1–6. IEEE, 2022
2022
-
[20]
Newton: A dram-maker’s accelerator- in-memory (aim) architecture for machine learning
Mingxuan He, Choungki Song, Ilkon Kim, Chunseok Jeong, Seho Kim, Il Park, Mithuna Thottethodi, and TN Vijaykumar. Newton: A dram-maker’s accelerator- in-memory (aim) architecture for machine learning. In2020 53rd Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), pages 372–385. IEEE, 2020
2020
-
[21]
Papi: Exploit- ing dynamic parallelism in large language model decoding with a processing-in- memory-enabled computing system
Yintao He, Haiyu Mao, Christina Giannoula, Mohammad Sadrosadati, Juan Gómez-Luna, Huawei Li, Xiaowei Li, Ying Wang, and Onur Mutlu. Papi: Exploit- ing dynamic parallelism in large language model decoding with a processing-in- memory-enabled computing system. InProceedings of the 30th ACM International Conference on Architectural Support for Programming La...
2025
-
[22]
Large language models in textual analysis for gesture selection
Laura Birka Hensel, Nutchanon Yongsatianchot, Parisa Torshizi, Elena Minucci, and Stacy Marsella. Large language models in textual analysis for gesture selection. InProceedings of the 25th International Conference on Multimodal Interaction, pages 378–387, 2023
2023
-
[23]
Neupims: Npu-pim heterogeneous acceleration for batched llm inferencing
Guseul Heo, Sangyeop Lee, Jaehong Cho, Hyunmin Choi, Sanghyeon Lee, Hyungkyu Ham, Gwangsun Kim, Divya Mahajan, and Jongse Park. Neupims: Npu-pim heterogeneous acceleration for batched llm inferencing. InProceedings of the 29th ACM International Conference on Architectural Support for Program- ming Languages and Operating Systems, Volume 3, pages 722–737, 2024
2024
-
[24]
Language models as zero-shot planners: Extracting actionable knowledge for embodied agents
Wenlong Huang, Pieter Abbeel, Deepak Pathak, and Igor Mordatch. Language models as zero-shot planners: Extracting actionable knowledge for embodied agents. InInternational conference on machine learning, pages 9118–9147. PMLR, 2022
2022
-
[25]
Inner Monologue: Embodied Reasoning through Planning with Language Models
Wenlong Huang, Fei Xia, Ted Xiao, Harris Chan, Jacky Liang, Pete Florence, Andy Zeng, Jonathan Tompson, Igor Mordatch, Yevgen Chebotar, Pierre Sermanet, Tomas Jackson, Noah Brown, Linda Luu, Sergey Levine, Karol Hausman, and Brian Ichter. Inner monologue: Embodied reasoning through planning with language models.arXiv preprint arXiv:2207.05608, 2022
work page internal anchor Pith review arXiv 2022
-
[26]
First demonstration of three- dimensional thermal conductivity distribution measurements of interconnect stacks down to 3nm process nodes
Zifeng Huang, Kaiqi Yang, Yiyun He, Zuoyuan Dong, Zixuan Sun, Xiyuan Tang, Ming Li, Runsheng Wang, and Zhe Cheng. First demonstration of three- dimensional thermal conductivity distribution measurements of interconnect stacks down to 3nm process nodes. In2025 IEEE International Electron Devices Meeting (IEDM), pages 1–4. IEEE, 2025
2025
-
[27]
Pathfinding future pim architectures by demystifying a commercial pim technology
Bongjoon Hyun, Taehun Kim, Dongjae Lee, and Minsoo Rhu. Pathfinding future pim architectures by demystifying a commercial pim technology. In2024 IEEE International Symposium on High-Performance Computer Architecture (HPCA), pages 263–279. IEEE, 2024
2024
-
[28]
Scanning electron microscopy (sem) and transmission electron microscopy (tem) for materials characterization
Beverley J Inkson. Scanning electron microscopy (sem) and transmission electron microscopy (tem) for materials characterization. InMaterials characterization using nondestructive evaluation (NDE) methods, pages 17–43. Elsevier, 2016
2016
-
[29]
Albert Q. Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanche Savary, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Emma Bou Hanna, Florian Bressand, Gianna Lengyel, Guillaume Bour, Guillaume Lample, Lélio Renard Lavaud, Lucile Saulnier, Marie-Anne Lachaux, Pierre Stock, Sandeep Subramanian, Sophia Yang, Szymon Antoniak, Teven...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
A detailed and flexible cycle-accurate network-on-chip simulator
Nan Jiang, Daniel U Becker, George Michelogiannakis, James Balfour, Brian Towles, David E Shaw, John Kim, and William J Dally. A detailed and flexible cycle-accurate network-on-chip simulator. In2013 IEEE international symposium on performance analysis of systems and software (ISPASS), pages 86–96. IEEE, 2013
2013
-
[31]
Tutorial: Time-domain thermore- flectance (tdtr) for thermal property characterization of bulk and thin film mate- rials.Journal of Applied Physics, 124(16), 2018
Puqing Jiang, Xin Qian, and Ronggui Yang. Tutorial: Time-domain thermore- flectance (tdtr) for thermal property characterization of bulk and thin film mate- rials.Journal of Applied Physics, 124(16), 2018
2018
-
[32]
Ssa-over-array (ssoa): A stacked dram ar- chitecture for near-memory computing.Journal of Semiconductors, 45(10):102201, 2024
Xiping Jiang, Fujun Bai, Song Wang, Yixin Guo, Fengguo Zuo, Wenwu Xiao, Yub- ing Wang, Jianguo Yang, and Ming Liu. Ssa-over-array (ssoa): A stacked dram ar- chitecture for near-memory computing.Journal of Semiconductors, 45(10):102201, 2024
2024
-
[33]
Cooling of server electronics: A design review of existing technology.Applied Thermal Engineering, 105:622–638, 2016
Ali C Kheirabadi and Dominic Groulx. Cooling of server electronics: A design review of existing technology.Applied Thermal Engineering, 105:622–638, 2016
2016
-
[34]
The breakthrough memory solutions for improved performance on llm inference.IEEE Micro, 44(3):40–48, 2024
Byeongho Kim, Sanghoon Cha, Sangsoo Park, Jieun Lee, Sukhan Lee, Shinhaeng Kang, Jinin So, Kyungsoo Kim, Jin Jung, Jong-Geon Lee, Sunjung Lee, Yoonah Paik, Hyeonsu Kim, Jin-Seong Kim, Won-Jo Lee, Yuhwan Ro, Yeongon Cho, Jin Hyun Kim, Joon-Ho Song, Jaehoon Yu, Seungwon Lee, Jeonghyeon Cho, and Kyomin Sohn. The breakthrough memory solutions for improved per...
2024
-
[35]
Sk hynix ai-specific comput- ing memory solution: From aim device to heterogeneous aimx-xpu system for comprehensive llm inference
Guhyun Kim, Jinkwon Kim, Nahsung Kim, Woojae Shin, Jongsoon Won, Hyunha Joo, Haerang Choi, Byeongju An, Gyeongcheol Shin, Dayeon Yun, Jeongbin Kim, Changhyun Kim, Ilkon Kim, Jaehan Park, Yosub Song, Byeongsu Yang, Hyeongdeok Lee, Seungyeong Park, Wonjun Lee, Seonghun Kim, Yonghoon Park, Yousub Jung, Gi-Ho Park, and Euicheol Lim. Sk hynix ai-specific compu...
2024
-
[36]
Samsung pim/pnm for transfmer based ai: Energy efficiency on pim/pnm cluster
Jin Hyun Kim, Yuhwan Ro, Jinin So, Sukhan Lee, Shinhaeng Kang, YeonGon Cho, Hyeonsu Kim, Byeongho Kim, Kyungsoo Kim, Sangsoo Park, Jin-Seong Kim, Sanghoon Cha, Won-Jo Lee, Jin Jung, Jonggeon Lee, Jieun Lee, Joon-Ho Song, Seungwon Lee, Jeonghyeon Cho, Jaehoon Yu, and Kyomin Sohn. Samsung pim/pnm for transfmer based ai: Energy efficiency on pim/pnm cluster....
2023
-
[37]
Efficient mem- ory management for large language model serving with pagedattention
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. Efficient mem- ory management for large language model serving with pagedattention. In Proceedings of the 29th Symposium on Operating Systems Principles, pages 611– 626, 2023
2023
-
[38]
Text generation webui
Jeston AI Lab. Text generation webui. https://www.jetson-ai-lab.com/archive/ tutorial_text-generation.html, 2026
2026
-
[39]
A 1ynm 1.25 v 8gb, 16gb/s/pin gddr6-based accelerator-in-memory supporting 1tflops 13 mac operation and various activation functions for deep-learning applications
Seong Ju Lee, Kyu-Young Kim, Sanghoon Oh, Joonhong Park, Gimoon Hong, Dong Yoon Ka, Kyu-Dong Hwang, Jeongje Park, Kyeong Pil Kang, Jungyeon Kim, Junyeol Jeon, Nahsung Kim, Yongkee Kwon, Kornijcuk Vladimir, Woojae Shin, Jongsoon Won, Minkyu Lee, Hyunha Joo, Haerang Choi, Jaewook Lee, Donguc Ko, Younggun Jun, Keewon Cho, Ilwoong Kim, Choungki Song, Chunseok...
2022
-
[40]
Hardware architecture and software stack for pim based on commercial dram technology: Industrial product
Sukhan Lee, Shinhaeng Kang, Jaehoon Lee, Hyeonsu Kim, Eojin Lee, Seungwoo Seo, Hosang Yoon, Seungwon Lee, Kyounghwan Lim, Hyunsung Shin, Jinhyun Kim, Seongil O, Anand Iyer, David Wang, Kyomin Sohn, and Nam Sung Kim. Hardware architecture and software stack for pim based on commercial dram technology: Industrial product. In2021 ACM/IEEE 48th Annual Interna...
2021
-
[41]
H2-llm: Hardware- dataflow co-exploration for heterogeneous hybrid-bonding-based low-batch llm inference
Cong Li, Yihan Yin, Xintong Wu, Jingchen Zhu, Zhutianya Gao, Dimin Niu, Qiang Wu, Xin Si, Yuan Xie, Chen Zhang, and Guangyu Sun. H2-llm: Hardware- dataflow co-exploration for heterogeneous hybrid-bonding-based low-batch llm inference. InProceedings of the 52nd Annual International Symposium on Computer Architecture, pages 194–210, 2025
2025
-
[42]
Specpim: Accelerating speculative inference on pim-enabled system via architecture-dataflow co-exploration
Cong Li, Zhe Zhou, Size Zheng, Jiaxi Zhang, Yun Liang, and Guangyu Sun. Specpim: Accelerating speculative inference on pim-enabled system via architecture-dataflow co-exploration. InProceedings of the 29th ACM Inter- national Conference on Architectural Support for Programming Languages and Operating Systems, Volume 3, pages 950–965, 2024
2024
-
[43]
Dram- sim3: A cycle-accurate, thermal-capable dram simulator.IEEE Computer Archi- tecture Letters, 19(2):106–109, 2020
Shang Li, Zhiyuan Yang, Dhiraj Reddy, Ankur Srivastava, and Bruce Jacob. Dram- sim3: A cycle-accurate, thermal-capable dram simulator.IEEE Computer Archi- tecture Letters, 19(2):106–109, 2020
2020
-
[44]
Cerebras architecture deep dive: First look inside the hw/sw co-design for deep learning: Cerebras systems
Sean Lie. Cerebras architecture deep dive: First look inside the hw/sw co-design for deep learning: Cerebras systems. In2022 IEEE Hot Chips 34 Symposium (HCS), pages 1–34. IEEE, 2022
2022
-
[45]
Tidalmesh: Topology-driven allreduce collective communication for mesh topology
Dongkyun Lim and John Kim. Tidalmesh: Topology-driven allreduce collective communication for mesh topology. InIEEE International Symposium on High Performance Computer Architecture, HPCA 2025, Las Vegas, NV, USA, March 1-5, 2025, pages 1526–1540. IEEE, 2025
2025
-
[46]
Ramulator 2.0: A modern, modular, and extensible dram simulator
Haocong Luo, Yahya Can Tu, F Nisa Bostancı, Ataberk Olgun, A Giray Ya, and Onur Mutlu. Ramulator 2.0: A modern, modular, and extensible dram simulator. IEEE Computer Architecture Letters, 2023
2023
-
[47]
Aios: Llm agent operating system.arXiv e-prints, pp
Kai Mei, Zelong Li, Shuyuan Xu, Ruosong Ye, Yingqiang Ge, and Yongfeng Zhang. Aios: Llm agent operating system.arXiv e-prints, pp. arXiv–2403, 2024
2024
-
[48]
CodeGen: An Open Large Language Model for Code with Multi-Turn Program Synthesis
Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, and Caiming Xiong. Codegen: An open large language model for code with multi-turn program synthesis.arXiv preprint arXiv:2203.13474, 2022
work page internal anchor Pith review arXiv 2022
-
[49]
184qps/w 64mb/mm 2 3d logic-to-dram hybrid bonding with process- near-memory engine for recommendation system
Dimin Niu, Shuangchen Li, Yuhao Wang, Wei Han, Zhe Zhang, Yijin Guan, Tianchan Guan, Fei Sun, Fei Xue, Lide Duan, Yuanwei Fang, Hongzhong Zheng, Xiping Jiang, Song Wang, Fengguo Zuo, Yubing Wang, Bing Yu, Qiwei Ren, and Yuan Xie. 184qps/w 64mb/mm 2 3d logic-to-dram hybrid bonding with process- near-memory engine for recommendation system. In2022 IEEE Inte...
2022
-
[50]
Build semi-custom ai infrastructure | nvidia nvlink fusion
NVIDIA. Build semi-custom ai infrastructure | nvidia nvlink fusion. https: //www.nvidia.com/en-us/data-center/nvlink-fusion/, 2026
2026
-
[51]
cutile python
NVIDIA. cutile python. https://github.com/NVIDIA/cutile-python, 2026
2026
-
[52]
Nvidia h200 gpu
NVIDIA. Nvidia h200 gpu. https://www.nvidia.com/en-us/data-center/h200/, 2026
2026
-
[53]
Nvidia quantum infiniband networking solutions
NVIDIA. Nvidia quantum infiniband networking solutions. https://www.nvidia. com/en-us/networking/products/infiniband/, 2026
2026
-
[54]
Optimized primitives for collective multi-gpu communicatio resources
NVIDIA. Optimized primitives for collective multi-gpu communicatio resources. https://github.com/NVIDIA/nccl, 2026
2026
-
[55]
OpenAI. Chatgpt. https://chatgpt.com/, 2026
2026
-
[56]
Stratum: System-hardware co-design with tiered monolithic 3d-stackable dram for efficient moe serving
Yue Pan, Zihan Xia, Po-Kai Hsu, Lanxiang Hu, Hyungyo Kim, Janak Sharda, Minxuan Zhou, Nam Sung Kim, Shimeng Yu, Tajana Rosing, and Mingu Kang. Stratum: System-hardware co-design with tiered monolithic 3d-stackable dram for efficient moe serving. InProceedings of the 58th IEEE/ACM International Symposium on Microarchitecture®, pages 1–17, 2025
2025
-
[57]
Attacc! unleashing the power of pim for batched transformer-based generative model inference
Jaehyun Park, Jaewan Choi, Kwanhee Kyung, Michael Jaemin Kim, Yongsuk Kwon, Nam Sung Kim, and Jung Ho Ahn. Attacc! unleashing the power of pim for batched transformer-based generative model inference. InProceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2, pages 103–119, 2024
2024
-
[58]
Splitwise: Efficient generative llm inference using phase splitting
Pratyush Patel, Esha Choukse, Chaojie Zhang, Aashaka Shah, Íñigo Goiri, Saeed Maleki, and Ricardo Bianchini. Splitwise: Efficient generative llm inference using phase splitting. In2024 ACM/IEEE 51st Annual International Symposium on Computer Architecture (ISCA), pages 118–132. IEEE, 2024
2024
-
[59]
Efficiently scaling transformer inference.Proceedings of machine learning and systems, 5:606–624, 2023
Reiner Pope, Sholto Douglas, Aakanksha Chowdhery, Jacob Devlin, James Brad- bury, Jonathan Heek, Kefan Xiao, Shivani Agrawal, and Jeff Dean. Efficiently scaling transformer inference.Proceedings of machine learning and systems, 5:606–624, 2023
2023
-
[60]
Sambanova sn40l rdu: Breaking the barrier of trillion+ param- eter scale gen ai computing
Raghu Prabhakar. Sambanova sn40l rdu: Breaking the barrier of trillion+ param- eter scale gen ai computing. In2024 IEEE Hot Chips 36 Symposium (HCS), pages 1–24. IEEE, 2024
2024
-
[61]
Mooncake: Trading more storage for less computation—a {KVCache-centric} architecture for serving {LLM} chatbot
Ruoyu Qin, Zheming Li, Weiran He, Jialei Cui, Feng Ren, Mingxing Zhang, Yongwei Wu, Weimin Zheng, and Xinran Xu. Mooncake: Trading more storage for less computation—a {KVCache-centric} architecture for serving {LLM} chatbot. In23rd USENIX Conference on File and Storage Technologies (FAST 25), pages 155–170, 2025
2025
-
[62]
GLU Variants Improve Transformer
Noam Shazeer. Glu variants improve transformer.arXiv preprint arXiv:2002.05202, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2002
-
[63]
Llmsimulator
Juhwan Cho Sungmin Yun, Kwanhee Kyung. Llmsimulator. https://github.com/ scale-snu/LLMSimulator/, 2025
2025
-
[64]
Dojo: The microarchitec- ture of tesla’s exa-scale computer
Emil Talpes, Douglas Williams, and Debjit Das Sarma. Dojo: The microarchitec- ture of tesla’s exa-scale computer. In2022 IEEE Hot Chips 34 Symposium (HCS), pages 1–28. IEEE, 2022
2022
-
[65]
Distributed communication package - torch.distributed
Pytorch Team. Distributed communication package - torch.distributed. https: //docs.pytorch.org/docs/stable/distributed.html, 2026
2026
-
[66]
Triton: an intermediate lan- guage and compiler for tiled neural network computations
Philippe Tillet, Hsiang-Tsung Kung, and David Cox. Triton: an intermediate lan- guage and compiler for tiled neural network computations. InProceedings of the 3rd ACM SIGPLAN International Workshop on Machine Learning and Programming Languages, pages 10–19, 2019
2019
-
[67]
Ultra Accelerator Link Consortium
Inc. Ultra Accelerator Link Consortium. Ualink 200 rev 1.0 specification. https: //ualinkconsortium.org/specifications/, 2026
2026
-
[68]
Gomez, Lukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in Neural Information Processing Systems, 2017
2017
-
[69]
arXiv preprint arXiv:2504.17577 , year=
Lei Wang, Yu Cheng, Yining Shi, Zhengju Tang, Zhiwen Mo, Wenhao Xie, Lingx- iao Ma, Yuqing Xia, Jilong Xue, Fan Yang, and Zhi Yang. Tilelang: A composable tiled programming model for ai systems.arXiv preprint arXiv:2504.17577, 2025
-
[70]
A 3d unified analysis method (3d-uam) for wafer-on-wafer stacked near-memory structure.IEEE Transactions on Very Large Scale Integration (VLSI) Systems, 2025
Song Wang, Yixin Guo, Wei Tao, Xuerong Jia, Fujun Bai, Jie Tan, Yubing Wang, Liang Bai, Fuzhi Guo, Qi Liu, Jin Li, Peng Yin, Fenning Liu, Jing Liu, Xiaodong Long, Yanwu Han, Zhongcheng Yu, Mengzi Cheng, Song Chen, and Xiping Jiang. A 3d unified analysis method (3d-uam) for wafer-on-wafer stacked near-memory structure.IEEE Transactions on Very Large Scale ...
2025
-
[71]
A 135 gbps/gbit 0.66 pj/bit stacked embedded dram with multilayer arrays by fine pitch hybrid bonding and mini-tsv
Song Wang, Bing Yu, Wenwu Xiao, Fujun Bai, Xiaodong Long, Liang Bai, Xuerong Jia, Fengguo Zuo, Jie Tan, Yixin Guo, Peng Sun, Jun Zhou, Qiong Zhan, Sheng Hu, Yu Zhou, Yi Kang, Qiwei Ren, and Xiping Jiang. A 135 gbps/gbit 0.66 pj/bit stacked embedded dram with multilayer arrays by fine pitch hybrid bonding and mini-tsv. In2023 IEEE Symposium on VLSI Technol...
2023
-
[72]
Emergent Abilities of Large Language Models
Jason Wei, Yi Tay, Rishi Bommasani, Colin Raffel, Barret Zoph, Sebastian Borgeaud, Dani Yogatama, Maarten Bosma, Denny Zhou, Donald Metzler, Ed H. Chi, Tatsunori Hashimoto, Oriol Vinyals, Percy Liang, Jeff Dean, and William Fe- dus. Emergent abilities of large language models.arXiv preprint arXiv:2206.07682, 2022
work page internal anchor Pith review arXiv 2022
-
[73]
Chain-of-thought prompting elicits reasoning in large language models.Advances in neural information processing systems, 35:24824–24837, 2022
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models.Advances in neural information processing systems, 35:24824–24837, 2022
2022
-
[74]
YAML. Yaml. https://yaml.org/, 2026
2026
-
[75]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[76]
Cramming a data center into one cabinet, a co-exploration of computing and hardware architecture of waferscale chip
Xingmao Yu, Dingcheng Jiang, Jinyi Deng, Jingyao Liu, Chao Li, Shouyi Yin, and Yang Hu. Cramming a data center into one cabinet, a co-exploration of computing and hardware architecture of waferscale chip. InProceedings of the 52nd Annual International Symposium on Computer Architecture, pages 631–645, 2025
2025
-
[77]
Exploiting similarity opportunities of emerging vision ai models on hybrid bonding architecture
Zhiheng Yue, Huizheng Wang, Jiahao Fang, Jinyi Deng, Guangyang Lu, Fengbin Tu, Ruiqi Guo, Yuxuan Li, Yubin Qin, Yang Wang, Chao Li, Huiming Han, Shaojun Wei, Yang Hu, and Shouyi Yin. Exploiting similarity opportunities of emerging vision ai models on hybrid bonding architecture. In2024 ACM/IEEE 51st Annual International Symposium on Computer Architecture ...
2024
-
[78]
3d- path: A hierarchy lut processing-in-memory accelerator with thermal-aware hybrid bonding integration
Zhiheng Yue, Yang Wang, Chao Li, Shaojun Wei, Yang Hu, and Shouyi Yin. 3d- path: A hierarchy lut processing-in-memory accelerator with thermal-aware hybrid bonding integration. InProceedings of the 58th IEEE/ACM International Symposium on Microarchitecture, pages 78–93, 2025
2025
-
[79]
Duplex: A device for large language models with mixture of experts, grouped query attention, and continuous batching
Sungmin Yun, Kwanhee Kyung, Juhwan Cho, Jaewan Choi, Jongmin Kim, Byeongho Kim, Sukhan Lee, Kyomin Sohn, and Jung Ho Ahn. Duplex: A device for large language models with mixture of experts, grouped query attention, and continuous batching. In2024 57th IEEE/ACM International Symposium on Microarchitecture (MICRO), pages 1429–1443. IEEE, 2024
2024
-
[80]
Llmcompass: Enabling efficient hardware design for large language model in- ference
Hengrui Zhang, August Ning, Rohan Baskar Prabhakar, and David Wentzlaff. Llmcompass: Enabling efficient hardware design for large language model in- ference. In2024 ACM/IEEE 51st Annual International Symposium on Computer 14 Architecture (ISCA), pages 1080–1096. IEEE, 2024
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.