Recognition: unknown
DiffVC: A Non-autoregressive Framework Based on Diffusion Model for Video Captioning
Pith reviewed 2026-05-10 17:11 UTC · model grok-4.3
The pith
A diffusion model lets non-autoregressive video captioning match autoregressive quality while running faster.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
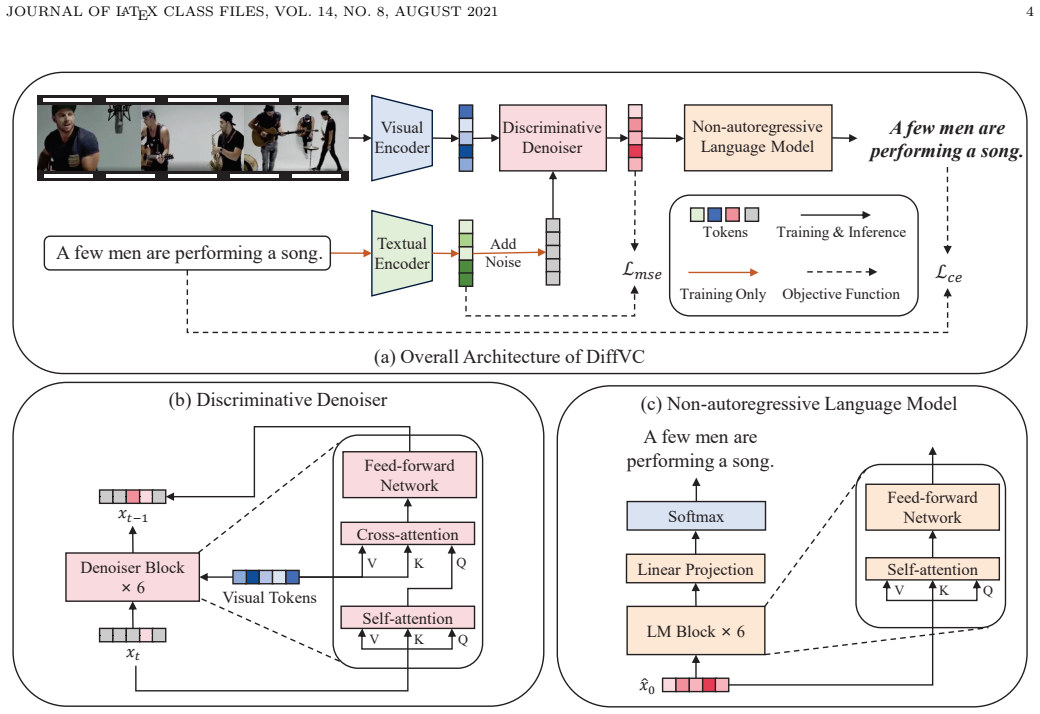
By training a discriminative conditional diffusion model to recover clean textual representations from noisy ones using video visual features as conditioning, the method produces high-quality embeddings that a non-autoregressive decoder can turn into accurate captions. This removes the sequential dependency and cumulative error of autoregressive generation while preserving the multimodal interaction that earlier non-autoregressive methods lacked.
What carries the argument
Discriminative conditional Diffusion Model: a denoiser that iteratively reconstructs textual embeddings from Gaussian noise, guided at each step by encoded video features as conditioning information.
If this is right
- The method outperforms earlier non-autoregressive video captioning systems on MSVD, MSR-VTT, and VATEX.
- It reaches CIDEr and BLEU-4 scores comparable to or better than autoregressive baselines, with gains up to 9.9 CIDEr points.
- Generation proceeds in parallel, eliminating cumulative token errors and yielding faster inference than sequential autoregressive decoding.
Where Pith is reading between the lines
- The same conditioning-plus-denoising pattern could be applied to other multimodal sequence tasks such as video question answering or dense video captioning.
- Because sampling starts from noise rather than a prompt, the framework may naturally support diverse caption outputs by varying the initial noise draw.
- Real-time applications such as live video description for accessibility become more feasible once per-video latency drops below autoregressive levels.
Load-bearing premise
The diffusion process, when conditioned on video features, can capture enough cross-modal structure to produce text representations that a non-autoregressive decoder turns into accurate captions.
What would settle it
On the MSVD test set, measure whether CIDEr scores drop below those of strong autoregressive baselines or whether wall-clock inference time per video fails to decrease relative to autoregressive decoding.
Figures




read the original abstract
Current video captioning methods usually use an encoder-decoder structure to generate text autoregressively. However, autoregressive methods have inherent limitations such as slow generation speed and large cumulative error. Furthermore, the few non-autoregressive counterparts suffer from deficiencies in generation quality due to the lack of sufficient multimodal interaction modeling. Therefore, we propose a non-autoregressive framework based on Diffusion model for Video Captioning (DiffVC) to address these issues. Its parallel decoding can effectively solve the problems of generation speed and cumulative error. At the same time, our proposed discriminative conditional Diffusion Model can generate higher-quality textual descriptions. Specifically, we first encode the video into a visual representation. During training, Gaussian noise is added to the textual representation of the ground-truth caption. Then, a new textual representation is generated via the discriminative denoiser with the visual representation as a conditional constraint. Finally, we input the new textual representation into a non-autoregressive language model to generate captions. During inference, we directly sample noise from the Gaussian distribution for generation. Experiments on MSVD, MSR-VTT, and VATEX show that our method can outperform previous non-autoregressive methods and achieve comparable performance to autoregressive methods, e.g., it achieved a maximum improvement of 9.9 on the CIDEr and improvement of 2.6 on the B@4, while having faster generation speed. The source code will be available soon.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes DiffVC, a non-autoregressive video captioning framework based on a discriminative conditional diffusion model. Video is encoded into visual representations; during training, Gaussian noise is added to ground-truth text representations, which are then denoised by a visual-conditioned denoiser to produce improved textual representations fed to a non-autoregressive language model for parallel caption generation. At inference, noise is sampled directly from a Gaussian distribution. Experiments on MSVD, MSR-VTT, and VATEX are reported to show outperformance over prior non-autoregressive methods (up to +9.9 CIDEr and +2.6 B@4) while remaining faster than autoregressive baselines.
Significance. If the reported gains are robustly attributable to the diffusion component, the work would offer a meaningful advance in efficient video captioning by mitigating quality issues in non-autoregressive decoding through explicit multimodal interaction modeling. The planned release of source code is noted as a reproducibility strength.
major comments (2)
- [Experiments] Experiments section: The headline performance claims (maximum +9.9 CIDEr and +2.6 B@4 over prior NAR methods) are presented without ablation studies or matched controls that isolate the contribution of the discriminative conditional diffusion model (noise addition, visual-conditioned denoising) from confounding factors such as visual backbone choice, NAR decoder architecture, training schedule, or feature extraction details. This directly undermines attribution of the gains to the proposed mechanism, which is load-bearing for the central claim in the abstract.
- [Method] Method section (diffusion model description): Key hyperparameters required to reproduce the multimodal interaction modeling are omitted, including the number of diffusion timesteps at inference, the precise architecture of the discriminative denoiser, and how the visual representation is injected as conditioning. Without these, it is impossible to verify whether the diffusion process sufficiently models the claimed interactions or to assess the assumption that it enables higher-quality textual representations than prior NAR approaches.
minor comments (1)
- [Abstract] Abstract: The statement that the method has 'faster generation speed' is qualitative; a quantitative comparison (e.g., wall-clock inference time or number of forward passes versus the AR baselines) would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review of our manuscript. We appreciate the acknowledgment of the potential contribution of DiffVC to non-autoregressive video captioning and the note on code release for reproducibility. We address each major comment below and will revise the manuscript to incorporate the suggested improvements.
read point-by-point responses
-
Referee: [Experiments] Experiments section: The headline performance claims (maximum +9.9 CIDEr and +2.6 B@4 over prior NAR methods) are presented without ablation studies or matched controls that isolate the contribution of the discriminative conditional diffusion model (noise addition, visual-conditioned denoising) from confounding factors such as visual backbone choice, NAR decoder architecture, training schedule, or feature extraction details. This directly undermines attribution of the gains to the proposed mechanism, which is load-bearing for the central claim in the abstract.
Authors: We agree that the current experiments do not include dedicated ablations to isolate the diffusion component's contribution from other design choices. While the manuscript reports comparisons against prior NAR baselines, it lacks internal controls such as a non-diffusion variant with matched backbone, decoder, and training settings. We will add a new ablation subsection in the revised experiments, including: (i) full DiffVC vs. a baseline without the diffusion process (using direct noisy or ground-truth text representations), (ii) variants with ablated conditioning, and (iii) controls for backbone and decoder architecture. These will strengthen the attribution of performance gains to the discriminative conditional diffusion model. revision: yes
-
Referee: [Method] Method section (diffusion model description): Key hyperparameters required to reproduce the multimodal interaction modeling are omitted, including the number of diffusion timesteps at inference, the precise architecture of the discriminative denoiser, and how the visual representation is injected as conditioning. Without these, it is impossible to verify whether the diffusion process sufficiently models the claimed interactions or to assess the assumption that it enables higher-quality textual representations than prior NAR approaches.
Authors: We acknowledge that these implementation details were insufficiently specified in the method section, limiting reproducibility and verification of the multimodal interaction modeling. In the revised manuscript, we will expand the diffusion model description to explicitly state the number of timesteps used at inference, provide the full architecture details of the discriminative denoiser (layers, dimensions, and attention mechanisms), and clarify the conditioning injection mechanism for the visual representation. We will also include a diagram of the overall diffusion process to aid clarity. revision: yes
Circularity Check
No significant circularity; diffusion-based NAR framework with independent empirical validation.
full rationale
The paper's derivation chain introduces a new architecture: video encoding to visual representations, Gaussian noise addition to ground-truth text representations during training, conditional denoising via a discriminative denoiser, followed by a non-autoregressive LM for caption generation, with inference via direct Gaussian sampling. This process is described as a forward modeling step without reducing to self-definition (e.g., no Y defined in terms of Y), fitted inputs renamed as predictions, or load-bearing self-citations. No uniqueness theorems, ansatzes smuggled via prior work, or renaming of known results are invoked. Experimental claims rest on standard benchmarks (MSVD, MSR-VTT, VATEX) rather than internal tautologies, making the framework self-contained against external validation.
Axiom & Free-Parameter Ledger
free parameters (2)
- noise schedule parameters
- denoiser architecture hyperparameters
axioms (1)
- domain assumption Gaussian noise addition and removal can model the distribution of textual representations conditioned on visual features.
Reference graph
Works this paper leans on
-
[1]
Translating videos to natural language using deep recurrent neural networks,
S. Venugopalan, H. Xu, J. Donahue, M. Rohrbach, R. Mooney, and K. Saenko, “Translating videos to natural language using deep recurrent neural networks,” in Proceedings of the 2015 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 2015, pp. 1494–1504
2015
-
[2]
Videotrm: Pre-training for video captioning challenge 2020,
J. Chen and H. Chao, “Videotrm: Pre-training for video captioning challenge 2020,” in Proceedings of the 28th ACM international conference on multimedia, 2020, pp. 4605–4609
2020
-
[3]
Sibnet: Sibling convolutional encoder for video captioning,
S. Liu, Z. Ren, and J. Yuan, “Sibnet: Sibling convolutional encoder for video captioning,” in Proceedings of the 26th ACM international conference on Multimedia, 2018, pp. 1425–1434
2018
-
[4]
Reconstruction network for video captioning,
B. Wang, L. Ma, W. Zhang, and W. Liu, “Reconstruction network for video captioning,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 7622–7631
2018
-
[5]
M3: Multimodal memory modelling for video captioning,
J. Wang, W. Wang, Y. Huang, L. Wang, and T. Tan, “M3: Multimodal memory modelling for video captioning,” in Pro- ceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 7512–7520
2018
-
[6]
Fully exploring object relation interaction and hidden state attention for video captioning,
F. Yuan, S. Gu, X. Zhang, and Z. Fang, “Fully exploring object relation interaction and hidden state attention for video captioning,” Pattern Recognition, vol. 159, p. 111138, 2025
2025
-
[7]
Spatio- temporal dynamics and semantic attribute enriched visual en- coding for video captioning,
N. Aafaq, N. Akhtar, W. Liu, S. Z. Gilani, and A. Mian, “Spatio- temporal dynamics and semantic attribute enriched visual en- coding for video captioning,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 12 487–12 496
2019
-
[8]
Motion guided spatial attention for video captioning,
S. Chen and Y.-G. Jiang, “Motion guided spatial attention for video captioning,” in Proceedings of the AAAI conference on artificial intelligence, vol. 33, no. 01, 2019, pp. 8191–8198
2019
-
[9]
Retrieval augmented convolutional encoder-decoder networks for video captioning,
J. Chen, Y. Pan, Y. Li, T. Yao, H. Chao, and T. Mei, “Retrieval augmented convolutional encoder-decoder networks for video captioning,” ACM Transactions on Multimedia Computing, Communications and Applications, vol. 19, no. 1s, pp. 1–24, 2023
2023
-
[10]
Long short-term relation transformer with global gating for video captioning,
L. Li, X. Gao, J. Deng, Y. Tu, Z.-J. Zha, and Q. Huang, “Long short-term relation transformer with global gating for video captioning,” IEEE Transactions on Image Processing, vol. 31, pp. 2726–2738, 2022
2022
-
[11]
Syntax-guided hierarchical attention network for video cap- tioning,
J. Deng, L. Li, B. Zhang, S. Wang, Z. Zha, and Q. Huang, “Syntax-guided hierarchical attention network for video cap- tioning,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 32, no. 2, pp. 880–892, 2021
2021
-
[12]
Non-autoregressive coarse-to-fine video captioning,
B. Yang, Y. Zou, F. Liu, and C. Zhang, “Non-autoregressive coarse-to-fine video captioning,” in Proceedings of the AAAI conference on artificial intelligence, vol. 35, no. 4, 2021, pp. 3119–3127
2021
-
[13]
Action-aware linguistic skeleton optimization net- work for non-autoregressive video captioning,
S. Chen, X. Zhong, Y. Zhang, L. Zhu, P. Li, X. Yang, and B. Sheng, “Action-aware linguistic skeleton optimization net- work for non-autoregressive video captioning,” ACM Transac- tions on Multimedia Computing, Communications and Appli- cations, vol. 20, no. 10, pp. 1–24, 2024
2024
-
[14]
Generative adversarial networks,
I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde- Farley, S. Ozair, A. Courville, and Y. Bengio, “Generative adversarial networks,” Communications of the ACM, vol. 63, no. 11, pp. 139–144, 2020
2020
-
[15]
Auto-encoding variational bayes,
D. P. Kingma, M. Welling et al., “Auto-encoding variational bayes,” 2013
2013
-
[16]
Denoising diffusion probabilistic models,
J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,” NeurIPS, vol. 33, pp. 6840–6851, 2020
2020
-
[17]
High-resolution image synthesis with latent diffusion models,
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer, “High-resolution image synthesis with latent diffusion models,” in CVPR, 2022, pp. 10 684–10 695
2022
-
[18]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
D. Podell, Z. English, K. Lacey, A. Blattmann, T. Dockhorn, J. Müller, J. Penna, and R. Rombach, “Sdxl: Improving latent diffusion models for high-resolution image synthesis,” arXiv preprint arXiv:2307.01952, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
Ad- versarial diffusion distillation,
A. Sauer, D. Lorenz, A. Blattmann, and R. Rombach, “Ad- versarial diffusion distillation,” in ECCV. Springer, 2025, pp. 87–103
2025
-
[20]
Refined semantic enhancement towards frequency diffusion for video captioning,
X. Zhong, Z. Li, S. Chen, K. Jiang, C. Chen, and M. Ye, “Refined semantic enhancement towards frequency diffusion for video captioning,” in Proceedings of the AAAI conference on artificial intelligence, vol. 37, no. 3, 2023, pp. 3724–3732
2023
-
[21]
Denoising Diffusion Implicit Models
J. Song, C. Meng, and S. Ermon, “Denoising diffusion implicit models,” arXiv preprint arXiv:2010.02502, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[22]
Hierarchical lstms with adaptive attention for visual captioning,
L. Gao, X. Li, J. Song, and H. T. Shen, “Hierarchical lstms with adaptive attention for visual captioning,” IEEE transactions on pattern analysis and machine intelligence, vol. 42, no. 5, pp. 1112–1131, 2019
2019
-
[23]
Stat: Spatial-temporal attention mechanism for video captioning,
C. Yan, Y. Tu, X. Wang, Y. Zhang, X. Hao, Y. Zhang, and Q. Dai, “Stat: Spatial-temporal attention mechanism for video captioning,” IEEE transactions on multimedia, vol. 22, no. 1, pp. 229–241, 2019
2019
-
[24]
Spatio-temporal graph for video captioning with knowledge distillation,
B. Pan, H. Cai, D.-A. Huang, K.-H. Lee, A. Gaidon, E. Adeli, and J. C. Niebles, “Spatio-temporal graph for video captioning with knowledge distillation,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 10 870–10 879
2020
-
[25]
Syntax-aware action tar- geting for video captioning,
Q. Zheng, C. Wang, and D. Tao, “Syntax-aware action tar- geting for video captioning,” in Proceedings of the IEEE/CVF JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 9 conference on computer vision and pattern recognition, 2020, pp. 13 096–13 105
2021
-
[26]
Learning modality interaction for temporal sentence localization and event caption- ing in videos,
S. Chen, W. Jiang, W. Liu, and Y.-G. Jiang, “Learning modality interaction for temporal sentence localization and event caption- ing in videos,” in European Conference on Computer Vision. Springer, 2020, pp. 333–351
2020
-
[27]
Object relational graph with teacher-recommended learning for video captioning,
Z. Zhang, Y. Shi, C. Yuan, B. Li, P. Wang, W. Hu, and Z.-J. Zha, “Object relational graph with teacher-recommended learning for video captioning,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 13 278– 13 288
2020
-
[28]
Sbat: Video captioning with sparse boundary-aware transformer,
T. Jin, S. Huang, M. Chen, Y. Li, and Z. Zhang, “Sbat: Video captioning with sparse boundary-aware transformer,” arXiv preprint arXiv:2007.11888, 2020
-
[29]
Enhancing the alignment between target words and corresponding frames for video captioning,
Y. Tu, C. Zhou, J. Guo, S. Gao, and Z. Yu, “Enhancing the alignment between target words and corresponding frames for video captioning,” Pattern Recognition, vol. 111, p. 107702, 2021
2021
-
[30]
Semantic grouping network for video captioning,
H. Ryu, S. Kang, H. Kang, and C. D. Yoo, “Semantic grouping network for video captioning,” in proceedings of the AAAI Conference on Artificial Intelligence, vol. 35, no. 3, 2021, pp. 2514–2522
2021
-
[31]
Motion guided region message passing for video captioning,
S. Chen and Y.-G. Jiang, “Motion guided region message passing for video captioning,” in Proceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 1543– 1552
2021
-
[32]
Adaptive spatial location with balanced loss for video captioning,
L. Li, Y. Zhang, S. Tang, L. Xie, X. Li, and Q. Tian, “Adaptive spatial location with balanced loss for video captioning,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 32, no. 1, pp. 17–30, 2020
2020
-
[33]
Towards knowledge-aware video captioning via transitive visual relation- ship detection,
B. Wu, G. Niu, J. Yu, X. Xiao, J. Zhang, and H. Wu, “Towards knowledge-aware video captioning via transitive visual relation- ship detection,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 32, no. 10, pp. 6753–6765, 2022
2022
-
[34]
Semantic embedding guided attention with explicit visual feature fusion for video captioning,
S. Dong, T. Niu, X. Luo, W. Liu, and X. Xu, “Semantic embedding guided attention with explicit visual feature fusion for video captioning,” ACM Transactions on Multimedia Com- puting, Communications and Applications, vol. 19, no. 2, pp. 1–18, 2023
2023
-
[35]
Msr-vtt: A large video description dataset for bridging video and language,
J. Xu, T. Mei, T. Yao, and Y. Rui, “Msr-vtt: A large video description dataset for bridging video and language,” in Pro- ceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 5288–5296
2016
-
[36]
Youtube2text: Recognizing and describing arbitrary activities using semantic hierarchies and zero-shot recognition,
S. Guadarrama, N. Krishnamoorthy, G. Malkarnenkar, S. Venu- gopalan, R. Mooney, T. Darrell, and K. Saenko, “Youtube2text: Recognizing and describing arbitrary activities using semantic hierarchies and zero-shot recognition,” in Proceedings of the IEEE international conference on computer vision, 2013, pp. 2712–2719
2013
-
[37]
Vatex: A large-scale, high-quality multilingual dataset for video-and-language research,
X. Wang, J. Wu, J. Chen, L. Li, Y.-F. Wang, and W. Y. Wang, “Vatex: A large-scale, high-quality multilingual dataset for video-and-language research,” in Proceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 4581– 4591
2019
-
[38]
Bleu: a method for automatic evaluation of machine translation,
K. Papineni, S. Roukos, T. Ward, and W.-J. Zhu, “Bleu: a method for automatic evaluation of machine translation,” in Proceedings of the 40th annual meeting of the Association for Computational Linguistics, 2002, pp. 311–318
2002
-
[39]
Meteor: An automatic metric for mt evaluation with improved correlation with human judgments,
S. Banerjee and A. Lavie, “Meteor: An automatic metric for mt evaluation with improved correlation with human judgments,” in Proceedings of the acl workshop on intrinsic and extrinsic evaluation measures for machine translation and/or summariza- tion, 2005, pp. 65–72
2005
-
[40]
Rouge: A package for automatic evaluation of summaries,
C.-Y. Lin, “Rouge: A package for automatic evaluation of summaries,” in Text summarization branches out, 2004, pp. 74– 81
2004
-
[41]
Cider: Consensus-based image description evaluation,
R. Vedantam, C. Lawrence Zitnick, and D. Parikh, “Cider: Consensus-based image description evaluation,” in Proceedings of the IEEE conference on computer vision and pattern recog- nition, 2015, pp. 4566–4575
2015
-
[42]
Microsoft coco: Common objects in context,
T.-Y. Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ra- manan, P. Dollár, and C. L. Zitnick, “Microsoft coco: Common objects in context,” in European conference on computer vision. Springer, 2014, pp. 740–755
2014
-
[43]
Memory-attended recurrent network for video captioning,
W. Pei, J. Zhang, X. Wang, L. Ke, X. Shen, and Y.-W. Tai, “Memory-attended recurrent network for video captioning,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 8347–8356
2019
-
[44]
Imagenet: A large-scale hierarchical image database,
J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “Imagenet: A large-scale hierarchical image database,” in 2009 IEEE conference on computer vision and pattern recognition. Ieee, 2009, pp. 248–255
2009
-
[45]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 770–778
2016
-
[46]
The Kinetics Human Action Video Dataset
W. Kay, J. Carreira, K. Simonyan, B. Zhang, C. Hillier, S. Vijayanarasimhan, F. Viola, T. Green, T. Back, P. Natsev et al., “The kinetics human action video dataset,” arXiv preprint arXiv:1705.06950, 2017
work page internal anchor Pith review arXiv 2017
-
[47]
Can spatiotemporal 3d cnns retrace the history of 2d cnns and imagenet?
K. Hara, H. Kataoka, and Y. Satoh, “Can spatiotemporal 3d cnns retrace the history of 2d cnns and imagenet?” in Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, 2018, pp. 6546–6555
2018
-
[48]
Adam: A Method for Stochastic Optimization
D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.