Recognition: 2 theorem links
· Lean TheoremPolySLGen: Online Multimodal Speaking-Listening Reaction Generation in Polyadic Interaction
Pith reviewed 2026-05-10 18:23 UTC · model grok-4.3
The pith
PolySLGen generates contextually appropriate multimodal reactions including speech, body motion, and speaking state for a target participant in group interactions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
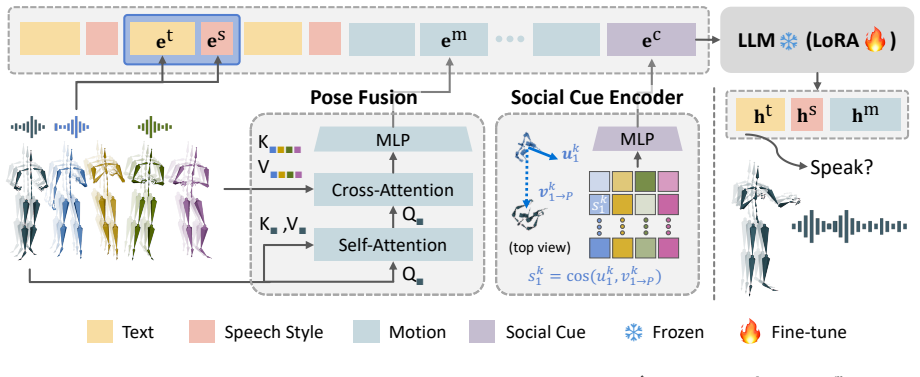
Given past conversation and motion from all participants, PolySLGen generates a future speaking or listening reaction for a target participant that includes speech, body motion, and a speaking state score. The framework uses a pose fusion module and a social cue encoder to jointly aggregate motion and social signals from the entire group, yielding reactions that are more contextually appropriate and temporally coherent than those from adapted and state-of-the-art baselines on measures of motion quality, motion-speech alignment, speaking state prediction, and human-perceived realism.
What carries the argument
The pose fusion module and social cue encoder, which together aggregate motion and social signals from the full group to drive the target participant's multimodal reaction.
If this is right
- Real-time multimodal reaction generation becomes feasible for polyadic rather than only dyadic interactions.
- Generated body motion aligns more closely with accompanying speech than in prior single-modality or two-person systems.
- Speaking state prediction improves, allowing the system to decide when the target should speak or listen.
- Human observers rate the resulting reactions as more realistic than those from adapted baselines.
Where Pith is reading between the lines
- The same fusion approach could be applied to virtual meeting avatars that must respond to multiple remote participants at once.
- Extending the encoder to include facial micro-expressions or gaze direction would likely tighten the temporal coherence further.
- Testing the model in live human-AI group games would reveal whether the online constraint still holds under unpredictable turn-taking.
Load-bearing premise
The pose fusion module and social cue encoder can combine motion and social signals from the whole group to produce coherent reactions without overfitting to particular datasets or interaction styles.
What would settle it
Running the model on a held-out dataset with different group sizes, cultural interaction norms, or speaking rates and checking whether motion-speech alignment and human realism scores drop below the reported baselines.
Figures





read the original abstract
Human-like multimodal reaction generation is essential for natural group interactions between humans and embodied AI. However, existing approaches are limited to single-modality or speaking-only responses in dyadic interactions, making them unsuitable for realistic social scenarios. Many also overlook nonverbal cues and complex dynamics of polyadic interactions, both critical for engagement and conversational coherence. In this work, we present PolySLGen, an online framework for Polyadic multimodal Speaking and Listening reaction Generation. Given past conversation and motion from all participants, PolySLGen generates a future speaking or listening reaction for a target participant, including speech, body motion, and speaking state score. To model group interactions effectively, we propose a pose fusion module and a social cue encoder that jointly aggregate motion and social signals from the group. Extensive experiments, along with quantitative and qualitative evaluations, show that PolySLGen produces contextually appropriate and temporally coherent multi-modal reactions, outperforming several adapted and state-of-the-art baselines in motion quality, motion-speech alignment, speaking state prediction, and human-perceived realism.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PolySLGen, an online framework for generating multimodal (speech, body motion, speaking state) speaking and listening reactions for a target participant in polyadic group interactions. It takes past conversation and motion from all participants as input and proposes a pose fusion module together with a social cue encoder to jointly aggregate motion and social signals across the group. The central claim, supported by asserted extensive experiments, is that the model produces contextually appropriate and temporally coherent reactions that outperform adapted and state-of-the-art baselines on motion quality, motion-speech alignment, speaking-state prediction, and human-perceived realism.
Significance. If the central claims hold, the work would address a clear gap in existing dyadic or single-modality reaction-generation methods and could enable more realistic embodied AI for group conversations. The proposed group-aggregation modules represent a potentially useful technical direction, but the absence of verifiable experimental details, ablations, or generalization tests in the manuscript prevents a firm assessment of whether the gains truly stem from the proposed components rather than capacity or training choices.
major comments (2)
- [Abstract] Abstract: the claim that PolySLGen 'outperforms several adapted and state-of-the-art baselines' in multiple metrics is load-bearing for the paper's contribution, yet the abstract (and the provided manuscript excerpt) supplies no quantitative tables, data splits, ablation studies, or cross-dataset results. Without these, it is impossible to verify that the pose fusion module and social cue encoder are responsible for the reported coherence and generalization rather than other factors.
- [Abstract] The central modeling assumption—that the pose fusion module and social cue encoder jointly capture general polyadic interaction dynamics—remains untested in the presented material. No evidence of held-out interaction styles, cross-dataset evaluation, or module-specific ablations isolating their contribution to temporal coherence or motion-speech alignment is supplied, leaving open the possibility that reported gains are dataset-specific.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the need for clearer experimental details and validation of the proposed modules. We address each major comment below. The full manuscript contains quantitative results, ablations, and generalization tests, but we have revised the abstract and expanded relevant sections to make these more immediately verifiable.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that PolySLGen 'outperforms several adapted and state-of-the-art baselines' in multiple metrics is load-bearing for the paper's contribution, yet the abstract (and the provided manuscript excerpt) supplies no quantitative tables, data splits, ablation studies, or cross-dataset results. Without these, it is impossible to verify that the pose fusion module and social cue encoder are responsible for the reported coherence and generalization rather than other factors.
Authors: Abstracts are length-constrained and conventionally omit tables or specific numbers; these appear in the manuscript body. Section 4 reports quantitative comparisons to baselines on motion quality, motion-speech alignment, speaking-state prediction, and human realism. Data splits are described in Section 3.1. Module ablations isolating the pose fusion and social cue encoder contributions appear in Section 4.4. We have revised the abstract to summarize key gains and added explicit cross-references to tables and sections for easier verification. revision: partial
-
Referee: [Abstract] The central modeling assumption—that the pose fusion module and social cue encoder jointly capture general polyadic interaction dynamics—remains untested in the presented material. No evidence of held-out interaction styles, cross-dataset evaluation, or module-specific ablations isolating their contribution to temporal coherence or motion-speech alignment is supplied, leaving open the possibility that reported gains are dataset-specific.
Authors: The manuscript already contains module-specific ablations (Section 4.4) that isolate the pose fusion module and social cue encoder, showing their impact on temporal coherence and motion-speech alignment metrics. Held-out evaluation on interaction styles is performed via splits by group size and conversation context within the dataset. Cross-dataset testing is limited by the lack of comparable public polyadic multimodal datasets; we have added explicit discussion of this limitation and the within-dataset generalization results. We have expanded the ablation and generalization subsections to make the evidence more prominent. revision: partial
Circularity Check
No circularity: derivation relies on standard ML training and evaluation without self-referential reduction
full rationale
The paper describes a standard encoder-decoder style architecture with proposed pose fusion and social cue encoder modules trained end-to-end on interaction data to generate reactions. No equations or claims reduce a prediction or uniqueness result to a fitted parameter or self-citation by construction. The abstract and available description frame the work as building on conventional aggregation techniques for multimodal signals, with performance claims resting on empirical comparisons to baselines rather than definitional equivalence. No load-bearing self-citation chains, ansatz smuggling, or renaming of known results appear in the provided text. The central claims remain falsifiable via held-out data and human evaluations, satisfying the criteria for a self-contained derivation.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we propose a pose fusion module and a social cue encoder that jointly aggregate motion and social signals from the group... sk_i = cos(u^k_i, v^k_i→P)
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Ltotal = λ_text·Ltext + λ_style·Lstyle + λ_state·Lstate + Lmotion
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ah- mad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Furhat: a back-projected human-like robot head for multiparty human-machine interaction
Samer Al Moubayed, Jonas Beskow, Gabriel Skantze, and Bj¨orn Granstr¨om. Furhat: a back-projected human-like robot head for multiparty human-machine interaction. InCogni- tive behavioural systems: COST 2102 international training school, dresden, Germany, february 21-26, 2011, revised se- lected papers, pages 114–130. Springer, 2012. 1, 2
2011
-
[3]
Exploring the differential effects of trust vi- olations in human-human and human-robot interactions.Ap- plied Ergonomics, 93:103350, 2021
Gene M Alarcon, Anthony M Gibson, Sarah A Jessup, and August Capiola. Exploring the differential effects of trust vi- olations in human-human and human-robot interactions.Ap- plied Ergonomics, 93:103350, 2021. 1
2021
-
[4]
Flamingo: a visual language model for few-shot learning.Advances in neural information processing systems, 35:23716–23736,
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Men- sch, Katherine Millican, Malcolm Reynolds, et al. Flamingo: a visual language model for few-shot learning.Advances in neural information processing systems, 35:23716–23736,
-
[5]
Talking turns: Benchmarking audio foundation models on turn-taking dynamics.ICLR,
Siddhant Arora, Zhiyun Lu, Chung-Cheng Chiu, Ruoming Pang, and Shinji Watanabe. Talking turns: Benchmarking audio foundation models on turn-taking dynamics.ICLR,
-
[6]
Motor contagion during human-human and human-robot in- teraction.PloS one, 9(8):e106172, 2014
Ambra Bisio, Alessandra Sciutti, Francesco Nori, Giorgio Metta, Luciano Fadiga, Giulio Sandini, and Thierry Pozzo. Motor contagion during human-human and human-robot in- teraction.PloS one, 9(8):e106172, 2014. 1
2014
-
[7]
Herv ´e Bredin and Antoine Laurent. End-to-end speaker seg- mentation for overlap-aware resegmentation.arXiv preprint arXiv:2104.04045, 2021. 4, 1
-
[8]
Digital life project: Autonomous 3d characters with social intelligence
Zhongang Cai, Jianping Jiang, Zhongfei Qing, Xinying Guo, Mingyuan Zhang, Zhengyu Lin, Haiyi Mei, Chen Wei, Ruisi Wang, Wanqi Yin, et al. Digital life project: Autonomous 3d characters with social intelligence. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 582–592, 2024. 3
2024
-
[9]
Zhi Cen, Huaijin Pi, Sida Peng, Qing Shuai, Yujun Shen, Hujun Bao, Xiaowei Zhou, and Ruizhen Hu. Ready-to-react: Online reaction policy for two-character interaction genera- tion.arXiv preprint arXiv:2502.20370, 2025. 2
-
[10]
The language of motion: Unifying verbal and non-verbal language of 3d human motion
Changan Chen, Juze Zhang, Shrinidhi K Lakshmikanth, Yusu Fang, Ruizhi Shao, Gordon Wetzstein, Li Fei-Fei, and Ehsan Adeli. The language of motion: Unifying verbal and non-verbal language of 3d human motion. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 6200–6211, 2025. 2
2025
-
[11]
Wavlm: Large-scale self- supervised pre-training for full stack speech processing
Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen, Jinyu Li, Naoyuki Kanda, Takuya Yoshioka, Xiong Xiao, et al. Wavlm: Large-scale self- supervised pre-training for full stack speech processing. IEEE Journal of Selected Topics in Signal Processing, 16 (6):1505–1518, 2022. 5
2022
-
[12]
Aroyo, Kerstin Dautenhahn, and Stephen L
Abhinav Dahiya, Alexander M. Aroyo, Kerstin Dautenhahn, and Stephen L. Smith. A survey of multi-agent human–robot interaction systems.Robotics and Autonomous Systems, 161: 104335, 2023. 2
2023
-
[13]
Chatpose: Chatting about 3d human pose
Yao Feng, Jing Lin, Sai Kumar Dwivedi, Yu Sun, Priyanka Patel, and Michael J Black. Chatpose: Chatting about 3d human pose. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2093–2103,
2093
-
[14]
Remos: 3d motion- conditioned reaction synthesis for two-person interactions
Anindita Ghosh, Rishabh Dabral, Vladislav Golyanik, Chris- tian Theobalt, and Philipp Slusallek. Remos: 3d motion- conditioned reaction synthesis for two-person interactions. InEuropean Conference on Computer Vision (ECCV), 2024. 2
2024
-
[15]
Tm2d: Bimodality driven 3d dance generation via music-text integration
Kehong Gong, Dongze Lian, Heng Chang, Chuan Guo, Zi- hang Jiang, Xinxin Zuo, Michael Bi Mi, and Xinchao Wang. Tm2d: Bimodality driven 3d dance generation via music-text integration. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 9942–9952, 2023. 2
2023
-
[16]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Ab- hinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024. 3, 5, 4
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
Generating diverse and natural 3d human motions from text
Chuan Guo, Shihao Zou, Xinxin Zuo, Sen Wang, Wei Ji, Xingyu Li, and Li Cheng. Generating diverse and natural 3d human motions from text. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5152–5161, 2022. 2
2022
-
[18]
Tm2t: Stochastic and tokenized modeling for the reciprocal genera- tion of 3d human motions and texts
Chuan Guo, Xinxin Zuo, Sen Wang, and Li Cheng. Tm2t: Stochastic and tokenized modeling for the reciprocal genera- tion of 3d human motions and texts. InEuropean Conference on Computer Vision, pages 580–597. Springer, 2022. 2
2022
-
[19]
Onellm: One framework to align all modalities with language
Jiaming Han, Kaixiong Gong, Yiyuan Zhang, Jiaqi Wang, Kaipeng Zhang, Dahua Lin, Yu Qiao, Peng Gao, and Xi- angyu Yue. Onellm: One framework to align all modalities with language. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 26584– 26595, 2024. 3
2024
-
[20]
Salad: Skeleton-aware latent diffusion for text-driven motion generation and editing
Seokhyeon Hong, Chaelin Kim, Serin Yoon, Junghyun Nam, Sihun Cha, and Junyong Noh. Salad: Skeleton-aware latent diffusion for text-driven motion generation and editing. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 7158–7168, 2025. 2
2025
-
[21]
Lora: Low-rank adaptation of large language models.ICLR, 1(2):3, 2022
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.ICLR, 1(2):3, 2022. 5
2022
-
[22]
Trimodal prediction of speaking and lis- tening willingness to help improve turn-changing modeling
Ryo Ishii, Xutong Ren, Michal Muszynski, and Louis- Philippe Morency. Trimodal prediction of speaking and lis- tening willingness to help improve turn-changing modeling. Frontiers in Psychology, 13:774547, 2022. 2
2022
-
[23]
Mo- tion puzzle: Arbitrary motion style transfer by body part
Deok-Kyeong Jang, Soomin Park, and Sung-Hee Lee. Mo- tion puzzle: Arbitrary motion style transfer by body part. ACM Transactions on Graphics (TOG), 41(3):1–16, 2022. 5
2022
-
[24]
Multi-agent long-term 3d human pose forecasting via interaction-aware trajectory conditioning
Jaewoo Jeong, Daehee Park, and Kuk-Jin Yoon. Multi-agent long-term 3d human pose forecasting via interaction-aware trajectory conditioning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1617–1628, 2024. 2
2024
-
[25]
Jianping Jiang, Weiye Xiao, Zhengyu Lin, Huaizhong Zhang, Tianxiang Ren, Yang Gao, Zhiqian Lin, Zhongang Cai, Lei Yang, and Ziwei Liu. Solami: Social vision- language-action modeling for immersive interaction with 3d autonomous characters.arXiv preprint arXiv:2412.00174,
-
[26]
1, 2, 3, 5, 6, 7, 8, 4
-
[27]
Coherent reconstruction of multiple humans from a single image
Wen Jiang, Nikos Kolotouros, Georgios Pavlakos, Xiaowei Zhou, and Kostas Daniilidis. Coherent reconstruction of multiple humans from a single image. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5579–5588, 2020. 5
2020
-
[28]
Gaze and turn-taking behavior in casual conversational interactions.ACM Transactions on In- teractive Intelligent Systems (TiiS), 3(2):1–30, 2013
Kristiina Jokinen, Hirohisa Furukawa, Masafumi Nishida, and Seiichi Yamamoto. Gaze and turn-taking behavior in casual conversational interactions.ACM Transactions on In- teractive Intelligent Systems (TiiS), 3(2):1–30, 2013. 4
2013
-
[29]
Let’s face it: Probabilistic multi-modal interlocutor-aware generation of facial gestures in dyadic set- tings
Patrik Jonell, Taras Kucherenko, Gustav Eje Henter, and Jonas Beskow. Let’s face it: Probabilistic multi-modal interlocutor-aware generation of facial gestures in dyadic set- tings. InProceedings of the 20th ACM International Confer- ence on Intelligent Virtual Agents, pages 1–8, 2020. 2
2020
-
[30]
Towards social artificial intelligence: Nonverbal social signal prediction in a triadic interaction
Hanbyul Joo, Tomas Simon, Mina Cikara, and Yaser Sheikh. Towards social artificial intelligence: Nonverbal social signal prediction in a triadic interaction. InCVPR, 2019. 5
2019
-
[31]
Virtual real- ity social cognition training for young adults with high- functioning autism.Journal of autism and developmental disorders, 43:34–44, 2013
Michelle R Kandalaft, Nyaz Didehbani, Daniel C Krawczyk, Tandra T Allen, and Sandra B Chapman. Virtual real- ity social cognition training for young adults with high- functioning autism.Journal of autism and developmental disorders, 43:34–44, 2013. 2
2013
-
[32]
Kobin H Kendrick, Judith Holler, and Stephen C Levinson. Turn-taking in human face-to-face interaction is multimodal: gaze direction and manual gestures aid the coordination of turn transitions.Philosophical transactions of the royal so- ciety B, 378(1875):20210473, 2023. 4
2023
-
[33]
Most: Motion style transformer between diverse ac- tion contents
Boeun Kim, Jungho Kim, Hyung Jin Chang, and Jin Young Choi. Most: Motion style transformer between diverse ac- tion contents. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1705– 1714, 2024. 5
2024
-
[34]
Talking with hands 16.2 m: A large-scale dataset of synchronized body- finger motion and audio for conversational motion analy- sis and synthesis
Gilwoo Lee, Zhiwei Deng, Shugao Ma, Takaaki Shiratori, Siddhartha S Srinivasa, and Yaser Sheikh. Talking with hands 16.2 m: A large-scale dataset of synchronized body- finger motion and audio for conversational motion analy- sis and synthesis. InProceedings of the IEEE/CVF Inter- national Conference on Computer Vision, pages 763–772,
-
[35]
Modeling multimodal social interactions: new challenges and baselines with densely aligned repre- sentations
Sangmin Lee, Bolin Lai, Fiona Ryan, Bikram Boote, and James M Rehg. Modeling multimodal social interactions: new challenges and baselines with densely aligned repre- sentations. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14585– 14595, 2024. 1
2024
-
[36]
Sangmin Lee, Bolin Lai, Fiona Ryan, Bikram Boote, and James M. Rehg. Modeling multimodal social interactions: New challenges and baselines with densely aligned represen- tations. In2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 14585–14595, 2024. 1
2024
-
[37]
Computer-assisted ther- apy for medication-resistant auditory hallucinations: proof- of-concept study.The British Journal of Psychiatry, 202(6): 428–433, 2013
Julian Leff, Geoffrey Williams, Mark A Huckvale, Mau- rice Arbuthnot, and Alex P Leff. Computer-assisted ther- apy for medication-resistant auditory hallucinations: proof- of-concept study.The British Journal of Psychiatry, 202(6): 428–433, 2013. 2
2013
-
[38]
Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InIn- ternational conference on machine learning, pages 19730– 19742. PMLR, 2023. 3
2023
-
[39]
Towards online multi-modal social interaction understanding.arXiv preprint arXiv:2503.19851, 2025
Xinpeng Li, Shijian Deng, Bolin Lai, Weiguo Pian, James M Rehg, and Yapeng Tian. Towards online multi-modal social interaction understanding.arXiv preprint arXiv:2503.19851,
-
[40]
Styletts 2: Towards human-level text-to-speech through style diffusion and adversarial train- ing with large speech language models.NeurIPS, 36:19594– 19621, 2023
Yinghao Aaron Li, Cong Han, Vinay Raghavan, Gavin Mis- chler, and Nima Mesgarani. Styletts 2: Towards human-level text-to-speech through style diffusion and adversarial train- ing with large speech language models.NeurIPS, 36:19594– 19621, 2023. 4, 1
2023
-
[41]
Beat: A large-scale semantic and emotional multi-modal dataset for conversational gestures synthesis
Haiyang Liu, Zihao Zhu, Naoya Iwamoto, Yichen Peng, Zhengqing Li, You Zhou, Elif Bozkurt, and Bo Zheng. Beat: A large-scale semantic and emotional multi-modal dataset for conversational gestures synthesis. InEuropean confer- ence on computer vision, pages 612–630. Springer, 2022. 5
2022
-
[42]
Visual instruction tuning
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. InNeurIPS, 2023. 1, 3
2023
-
[43]
Towards variable and coordinated holistic co-speech motion generation
Yifei Liu, Qiong Cao, Yandong Wen, Huaiguang Jiang, and Changxing Ding. Towards variable and coordinated holistic co-speech motion generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1566–1576, 2024. 2
2024
-
[44]
Decoupled weight de- cay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight de- cay regularization. InInternational Conference on Learning Representations, 2018. 5
2018
-
[45]
M 3 gpt: An ad- vanced multimodal, multitask framework for motion com- prehension and generation.Advances in Neural Information Processing Systems, 37:28051–28077, 2024
Mingshuang Luo, Ruibing Hou, Zhuo Li, Hong Chang, Zimo Liu, Yaowei Wang, and Shiguang Shan. M 3 gpt: An ad- vanced multimodal, multitask framework for motion com- prehension and generation.Advances in Neural Information Processing Systems, 37:28051–28077, 2024. 2
2024
-
[46]
Embody 3d: A large-scale multimodal motion and behavior dataset, 2025
Claire McLean, Makenzie Meendering, Tristan Swartz, Orri Gabbay, Alexandra Olsen, Rachel Jacobs, Nicholas Rosen, Philippe de Bree, Tony Garcia, Gadsden Merrill, Jake San- dakly, Julia Buffalini, Neham Jain, Steven Krenn, Moneish Kumar, Dejan Markovic, Evonne Ng, Fabian Prada, Andrew Saba, Siwei Zhang, Vasu Agrawal, Tim Godisart, Alexander Richard, and Mic...
2025
-
[47]
From wer and ril to mer and wil: improved evaluation mea- sures for connected speech recognition
Andrew Cameron Morris, Viktoria Maier, and Phil D Green. From wer and ril to mer and wil: improved evaluation mea- sures for connected speech recognition. InInterspeech, pages 2765–2768, 2004. 5
2004
-
[48]
Convofusion: Multi-modal conversational diffu- sion for co-speech gesture synthesis
Muhammad Hamza Mughal, Rishabh Dabral, Ikhsanul Habibie, Lucia Donatelli, Marc Habermann, and Christian Theobalt. Convofusion: Multi-modal conversational diffu- sion for co-speech gesture synthesis. InCVPR, pages 1388– 1398, 2024. 2, 5, 6, 1, 3, 4
2024
-
[49]
Learning to listen: Modeling non-deterministic dyadic facial motion
Evonne Ng, Hanbyul Joo, Liwen Hu, Hao Li, Trevor Darrell, Angjoo Kanazawa, and Shiry Ginosar. Learning to listen: Modeling non-deterministic dyadic facial motion. InCVPR, pages 20395–20405, 2022. 2
2022
-
[50]
It takes two: Learning to plan for human-robot cooperative carrying
Eley Ng, Ziang Liu, and Monroe Kennedy. It takes two: Learning to plan for human-robot cooperative carrying. In 2023 IEEE International Conference on Robotics and Au- tomation (ICRA), pages 7526–7532. IEEE, 2023. 2
2023
-
[51]
Can language models learn to listen? InICCV, 2023
Evonne Ng, Sanjay Subramanian, Dan Klein, Angjoo Kanazawa, Trevor Darrell, and Shiry Ginosar. Can language models learn to listen? InICCV, 2023. 1, 2, 5, 6, 3, 4
2023
-
[52]
From audio to photoreal embodiment: Synthesizing humans in conversations
Evonne Ng, Javier Romero, Timur Bagautdinov, Shaojie Bai, Trevor Darrell, Angjoo Kanazawa, and Alexander Richard. From audio to photoreal embodiment: Synthesizing humans in conversations. InCVPR, pages 1001–1010, 2024. 2, 4
2024
-
[53]
Egocom: A multi-person multi-modal egocentric communications dataset.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(6):6783– 6793, 2020
Curtis G Northcutt, Shengxin Zha, Steven Lovegrove, and Richard Newcombe. Egocom: A multi-person multi-modal egocentric communications dataset.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(6):6783– 6793, 2020. 5
2020
-
[54]
Engagement in human-agent inter- action: An overview.Frontiers in Robotics and AI, V olume 7 - 2020, 2020
Catharine Oertel, Ginevra Castellano, Mohamed Chetouani, Jauwairia Nasir, Mohammad Obaid, Catherine Pelachaud, and Christopher Peters. Engagement in human-agent inter- action: An overview.Frontiers in Robotics and AI, V olume 7 - 2020, 2020. 2
2020
-
[55]
ChatGPT (May 6 version).https://chat
OpenAI. ChatGPT (May 6 version).https://chat. openai.com/, 2025. 3
2025
-
[56]
A unified framework for motion reasoning and generation in human interaction
Jeongeun Park, Sungjoon Choi, and Sangdoo Yun. A unified framework for motion reasoning and generation in human interaction. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 10698–10707, 2025. 2
2025
-
[57]
Trajectory- aware body interaction transformer for multi-person pose forecasting
Xiaogang Peng, Siyuan Mao, and Zizhao Wu. Trajectory- aware body interaction transformer for multi-person pose forecasting. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 17121– 17130, 2023. 2
2023
-
[58]
Robust speech recognition via large-scale weak supervision
Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, and Ilya Sutskever. Robust speech recognition via large-scale weak supervision. InInter- national Conference on Machine Learning, pages 28492– 28518. PMLR, 2023. 4
2023
-
[59]
Chirag Raman, Jose Vargas Quiros, Stephanie Tan, Ashraful Islam, Ekin Gedik, and Hayley Hung. Conflab: A data col- lection concept, dataset, and benchmark for machine analy- sis of free-standing social interactions in the wild.Advances in Neural Information Processing Systems, 35:23701–23715,
-
[60]
The multimodal nature of communicative ef- ficiency in social interaction.Scientific Reports, 12, 2022
Marlou Rasenberg, Wim Pouw, Asli ¨Ozy¨urek, and Mark Dingemanse. The multimodal nature of communicative ef- ficiency in social interaction.Scientific Reports, 12, 2022. 1
2022
-
[61]
Contact and human dynamics from monocular video
Davis Rempe, Leonidas J Guibas, Aaron Hertzmann, Bryan Russell, Ruben Villegas, and Jimei Yang. Contact and human dynamics from monocular video. InComputer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23– 28, 2020, Proceedings, Part V 16, pages 71–87. Springer,
2020
-
[62]
Mo- tiongpt: Human motion synthesis with improved diversity and realism via gpt-3 prompting
Jose Ribeiro-Gomes, Tianhui Cai, Zolt ´an A Milacski, Chen Wu, Aayush Prakash, Shingo Takagi, Amaury Aubel, Daeil Kim, Alexandre Bernardino, and Fernando De La Torre. Mo- tiongpt: Human motion synthesis with improved diversity and realism via gpt-3 prompting. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 5070–50...
2024
-
[63]
Visual cues en- hance predictive turn-taking for two-party human interac- tion
Sam O’Connor Russell and Naomi Harte. Visual cues en- hance predictive turn-taking for two-party human interac- tion. InFindings of the Association for Computational Lin- guistics: ACL 2025, pages 209–221, 2025. 1
2025
-
[64]
Ditailis- tener: Controllable high fidelity listener video generation with diffusion
Maksim Siniukov, Di Chang, Minh Tran, Hongkun Gong, Ashutosh Chaubey, and Mohammad Soleymani. Ditailis- tener: Controllable high fidelity listener video generation with diffusion. InProceedings of the IEEE/CVF Interna- tional Conference on Computer Vision, pages 11991–12001,
-
[65]
Duolando: Follower gpt with off-policy reinforcement learn- ing for dance accompaniment
Li Siyao, Tianpei Gu, Zhitao Yang, Zhengyu Lin, Ziwei Liu, Henghui Ding, Lei Yang, and Chen Change Loy. Duolando: Follower gpt with off-policy reinforcement learn- ing for dance accompaniment. InICLR, 2024. 1, 2
2024
-
[66]
Err@hri 2024 challenge: Multimodal detection of errors and failures in human-robot interactions
Micol Spitale, Maria Teresa Parreira, Maia Stiber, Minja Ax- elsson, Neval Kara, Garima Kankariya, Chien-Ming Huang, Malte Jung, Wendy Ju, and Hatice Gunes. Err@hri 2024 challenge: Multimodal detection of errors and failures in human-robot interactions. InProceedings of the 26th In- ternational Conference on Multimodal Interaction, page 652–656, New York,...
2024
-
[67]
stable-ts.https://github.com/jianfch/ stable-ts
stable-ts. stable-ts.https://github.com/jianfch/ stable-ts. Accessed: 2025-05-15. 4, 1
2025
-
[68]
Humans in kitchens: a dataset for multi-person human motion forecasting with scene con- text.Advances in Neural Information Processing Systems, 36:10184–10196, 2023
Julian Tanke, Oh-Hun Kwon, Felix B Mueller, Andreas Do- ering, and Juergen Gall. Humans in kitchens: a dataset for multi-person human motion forecasting with scene con- text.Advances in Neural Information Processing Systems, 36:10184–10196, 2023. 5
2023
-
[69]
Social diffusion: Long-term multiple hu- man motion anticipation
Julian Tanke, Linguang Zhang, Amy Zhao, Chengcheng Tang, Yujun Cai, Lezi Wang, Po-Chen Wu, Juergen Gall, and Cem Keskin. Social diffusion: Long-term multiple hu- man motion anticipation. InICCV, pages 9601–9611, 2023. 2, 4
2023
-
[70]
Understanding the dynamics of social interactions: A multi-modal multi-view approach.ACM Trans
Rim Trabelsi, Jagannadan Varadarajan, Le Zhang, Issam Jabri, Yong Pei, Fethi Smach, Ammar Bouallegue, and Pierre Moulin. Understanding the dynamics of social interactions: A multi-modal multi-view approach.ACM Trans. Multime- dia Comput. Commun. Appl., 15(1s), 2019. 1
2019
-
[71]
Large language models know what to say but not when to speak
Muhammad Umair, Vasanth Sarathy, and JP de Ruiter. Large language models know what to say but not when to speak. arXiv preprint arXiv:2410.16044, 2024. 3
-
[72]
Nonverbal cues in human–robot interaction: A communication studies perspec- tive.J
Jacqueline Urakami and Katie Seaborn. Nonverbal cues in human–robot interaction: A communication studies perspec- tive.J. Hum.-Robot Interact., 12(2), 2023. 1
2023
-
[73]
Jrdb-pose: A large-scale dataset for multi- person pose estimation and tracking
Edward Vendrow, Duy Tho Le, Jianfei Cai, and Hamid Rezatofighi. Jrdb-pose: A large-scale dataset for multi- person pose estimation and tracking. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4811–4820, 2023. 5
2023
-
[74]
Verbal and non-verbal communication skills including empathy dur- ing history taking of undergraduate medical students.BMC Medical Education, 18, 2018
Daniela V ogel, Marco Meyer, and Sigrid Harendza. Verbal and non-verbal communication skills including empathy dur- ing history taking of undergraduate medical students.BMC Medical Education, 18, 2018. 1
2018
-
[75]
A systematic review of ai, vr, and llm applications in special education: Opportunities, challenges, and future directions.Education and Information Technologies, pages 1–41, 2025
Evdokia V oultsiou and Lefteris Moussiades. A systematic review of ai, vr, and llm applications in special education: Opportunities, challenges, and future directions.Education and Information Technologies, pages 1–41, 2025. 2
2025
-
[76]
Read- ing lies: Nonverbal communication and deception.Annual review of psychology, 70:295—317, 2019
Aldert Vrij, Maria Hartwig, and P ¨ar Anders Granhag. Read- ing lies: Nonverbal communication and deception.Annual review of psychology, 70:295—317, 2019. 1
2019
-
[77]
Move as you say interact as you can: Language-guided human motion generation with scene af- fordance
Zan Wang, Yixin Chen, Baoxiong Jia, Puhao Li, Jinlu Zhang, Jingze Zhang, Tengyu Liu, Yixin Zhu, Wei Liang, and Siyuan Huang. Move as you say interact as you can: Language-guided human motion generation with scene af- fordance. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 433–444, 2024. 2
2024
-
[78]
Turn-taking in con- versations.Communication theory, pages 226–245, 2017
John M Wiemann and Mark L Knapp. Turn-taking in con- versations.Communication theory, pages 226–245, 2017. 2
2017
-
[79]
Woodard and J.T
J.P. Woodard and J.T. Nelson. An information theoretic mea- sure of speech recognition performance.Workshop on stan- dardisation for speech I/O technology, 1982. 5
1982
-
[80]
Next-gpt: Any-to-any multimodal llm
Shengqiong Wu, Hao Fei, Leigang Qu, Wei Ji, and Tat-Seng Chua. Next-gpt: Any-to-any multimodal llm. InForty-first International Conference on Machine Learning, 2024. 1
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.