Recognition: 2 theorem links
· Lean TheoremInside-Out: Measuring Generalization in Vision Transformers Through Inner Workings
Pith reviewed 2026-05-10 18:21 UTC · model grok-4.3
The pith
Extracting causal circuits from vision transformers yields stronger label-free metrics for predicting generalization under distribution shifts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
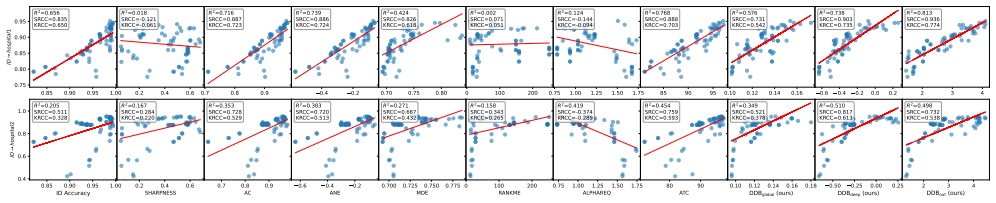
Leveraging circuit discovery on vision transformers, the work extracts circuits as causal interactions between internal representations and proposes Dependency Depth Bias for pre-deployment model selection and Circuit Shift Score for post-deployment monitoring, demonstrating superior correlation with generalization performance compared to existing output-based proxies.
What carries the argument
Circuits as causal interactions between internal representations of the vision transformer, extracted via circuit discovery to compute dependency depth bias and circuit shift scores.
If this is right
- Dependency Depth Bias ranks candidate models by expected generalization capability on unlabeled target data before deployment.
- Circuit Shift Score quantifies how distribution shifts alter the model's internal causal interactions to forecast performance drops.
- Both metrics achieve higher average correlations with true generalization than prior proxies across the evaluated tasks.
- The internal focus enables label-free model selection and ongoing monitoring in applications where target labels are scarce.
Where Pith is reading between the lines
- Circuit-based evaluation could be extended to other architectures to check whether similar internal patterns predict generalization in non-vision settings.
- The scores might help isolate which internal dependencies cause poor generalization, suggesting targeted fixes to model layers.
- If the correlations hold, the metrics could be incorporated into training objectives to encourage circuits that support robust generalization.
Load-bearing premise
The circuits identified by the discovery method must accurately reflect the internal mechanisms that control generalization behavior under distribution shifts.
What would settle it
A test on additional vision tasks and models where the new metrics show no higher or lower correlation with held-out generalization accuracy than output-based proxies like model confidence.
Figures













read the original abstract
Reliable generalization metrics are fundamental to the evaluation of machine learning models. Especially in high-stakes applications where labeled target data are scarce, evaluation of models' generalization performance under distribution shift is a pressing need. We focus on two practical scenarios: (1) Before deployment, how to select the best model for unlabeled target data? (2) After deployment, how to monitor model performance under distribution shift? The central need in both cases is a reliable and label-free proxy metric. Yet existing proxy metrics, such as model confidence or accuracy-on-the-line, are often unreliable as they only assess model output while ignoring the internal mechanisms that produce them. We address this limitation by introducing a new perspective: using the inner workings of a model, i.e., circuits, as a predictive metric of generalization performance. Leveraging circuit discovery, we extract the causal interactions between internal representations as a circuit, from which we derive two metrics tailored to the two practical scenarios. (1) Before deployment, we introduce Dependency Depth Bias, which measures different models' generalization capability on target data. (2) After deployment, we propose Circuit Shift Score, which predicts a model's generalization under different distribution shifts. Across various tasks, both metrics demonstrate significantly improved correlation with generalization performance, outperforming existing proxies by an average of 13.4\% and 34.1\%, respectively. Our code is available at https://github.com/deep-real/GenCircuit.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Dependency Depth Bias and Circuit Shift Score, two metrics derived from circuits extracted via circuit discovery in Vision Transformers. These are positioned as label-free proxies for generalization under distribution shift: the former for pre-deployment model selection on unlabeled target data, the latter for post-deployment monitoring. The central empirical claim is that both metrics achieve substantially higher correlation with true generalization performance than existing output-based proxies, with average gains of 13.4% and 34.1% across tasks.
Significance. If the central claim holds after proper validation, the work would offer a useful inner-workings perspective on generalization proxies, addressing a practical need in high-stakes settings where target labels are unavailable. The public code release is a clear strength that supports reproducibility and further scrutiny.
major comments (2)
- [Abstract and §3] Abstract and §3 (Methods): The claim that the extracted circuits capture causal interactions relevant to generalization is load-bearing for both metrics, yet the manuscript provides no intervention-based validation (e.g., activation patching or ablation on the discovered circuits) to rule out spurious correlations. Without such checks, the reported correlation improvements cannot be confidently attributed to the inner-workings perspective rather than model capacity or other confounders.
- [§4] §4 (Experiments): The average improvements of 13.4% and 34.1% are presented without accompanying details on the number of tasks/models, variance across random seeds, statistical significance, or explicit comparison to strong baselines that also use internal representations. This makes it impossible to assess whether the gains are robust or task-specific.
minor comments (2)
- [§3] Notation for Dependency Depth Bias and Circuit Shift Score should be introduced with explicit formulas (including any hyperparameters) rather than descriptive text only, to allow direct reproduction.
- [§4] Figure captions and axis labels in the results section would benefit from clearer indication of which metric corresponds to which practical scenario (pre- vs. post-deployment).
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment point by point below and will incorporate revisions to strengthen the causal validation of the circuits and the reporting of experimental results.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (Methods): The claim that the extracted circuits capture causal interactions relevant to generalization is load-bearing for both metrics, yet the manuscript provides no intervention-based validation (e.g., activation patching or ablation on the discovered circuits) to rule out spurious correlations. Without such checks, the reported correlation improvements cannot be confidently attributed to the inner-workings perspective rather than model capacity or other confounders.
Authors: We agree that explicit intervention-based validation would provide stronger support for attributing the improved correlations to the causal structure of the circuits rather than confounders. Our circuit discovery procedure follows established mechanistic interpretability methods that rely on interventions (such as activation patching during discovery), but the current manuscript does not include additional post-discovery experiments that directly ablate or patch the extracted circuits and measure the resulting impact on generalization performance under distribution shift. We will add such analyses in the revised version, for example by performing targeted ablations on circuit components and reporting changes in the correlation of Dependency Depth Bias and Circuit Shift Score with true generalization error. This will help substantiate the causal relevance claim. revision: yes
-
Referee: [§4] §4 (Experiments): The average improvements of 13.4% and 34.1% are presented without accompanying details on the number of tasks/models, variance across random seeds, statistical significance, or explicit comparison to strong baselines that also use internal representations. This makes it impossible to assess whether the gains are robust or task-specific.
Authors: We appreciate this observation and will substantially expand the experimental reporting in §4. The revised manuscript will specify the exact number of tasks and models evaluated, include variance or standard deviations across random seeds, report statistical significance (e.g., p-values from appropriate tests on the correlation differences), and add explicit comparisons against strong internal-representation baselines such as layer-wise activation statistics, attention pattern metrics, and other circuit-agnostic internal probes. These additions will allow a clearer assessment of robustness across tasks. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper proposes Dependency Depth Bias and Circuit Shift Score by applying an external circuit discovery technique to extract causal interactions in ViTs, then evaluates these metrics empirically via correlation with observed generalization under distribution shift. No equations, definitions, or self-citations are presented that reduce either metric or the reported performance gains (13.4% and 34.1%) to the input data or target variable by construction. The central claims rest on experimental comparisons against existing proxies rather than tautological derivations or fitted parameters renamed as predictions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Circuit discovery can extract meaningful causal interactions from model internals.
invented entities (2)
-
Dependency Depth Bias
no independent evidence
-
Circuit Shift Score
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Definition 1 (Circuit as edge weight mapping): c_M^D_X(e) := E_{x~D_X} [KL(M_{e}(x), M(x))]
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Dependency Depth Bias (DDB) as log-ratio of deep vs shallow layer weights; Circuit Shift Score as distance from ID circuit
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
In search of the successful in- terpolation: On the role of sharpness in clip generalization
Alireza Abdollahpoorrostam. In search of the successful in- terpolation: On the role of sharpness in clip generalization. arXiv preprint arXiv:2410.16476, 2024. 8
-
[2]
4, 5, 7, 8
Kumar K Agrawal, Arnab Kumar Mondal, Arna Ghosh, and Blake Richards.α-req: Assessing representation quality in self-supervised learning by measuring eigenspectrum de- cay.Advances in Neural Information Processing Systems, 35:17626–17638, 2022. 4, 5, 7, 8
2022
-
[3]
Maksym Andriushchenko, Francesco Croce, Maximilian M¨uller, Matthias Hein, and Nicolas Flammarion. A modern look at the relationship between sharpness and generaliza- tion.arXiv preprint arXiv:2302.07011, 2023. 4, 5, 8
-
[4]
Recognition in terra incognita
Sara Beery, Grant Van Horn, and Pietro Perona. Recognition in terra incognita. InProceedings of the European confer- ence on computer vision (ECCV), pages 456–473, 2018. 4, 1
2018
-
[5]
arXiv preprint arXiv:2404.14082 (2024)
Leonard Bereska and Efstratios Gavves. Mechanistic interpretability for ai safety–a review.arXiv preprint arXiv:2404.14082, 2024. 2
-
[6]
Finding transformer circuits with edge prun- ing.Advances in Neural Information Processing Systems, 37:18506–18534, 2024
Adithya Bhaskar, Alexander Wettig, Dan Friedman, and Danqi Chen. Finding transformer circuits with edge prun- ing.Advances in Neural Information Processing Systems, 37:18506–18534, 2024. 3, 8
2024
-
[7]
Invariance and stability of deep convolutional representations.Advances in neural in- formation processing systems, 30, 2017
Alberto Bietti and Julien Mairal. Invariance and stability of deep convolutional representations.Advances in neural in- formation processing systems, 30, 2017. 8
2017
-
[8]
Bilal Chughtai, Alan Cooney, and Neel Nanda. Summing up the facts: Additive mechanisms behind factual recall in llms. arXiv preprint arXiv:2402.07321, 2024. 8
-
[9]
Towards automated circuit discovery for mechanistic interpretability
Arthur Conmy, Augustine Mavor-Parker, Aengus Lynch, Stefan Heimersheim, and Adri `a Garriga-Alonso. Towards automated circuit discovery for mechanistic interpretability. Advances in Neural Information Processing Systems, 36: 16318–16352, 2023. 3, 8
2023
-
[10]
Xinnan Dai, Chung-Hsiang Lo, Kai Guo, Shenglai Zeng, Dongsheng Luo, and Jiliang Tang. Uncovering graph reason- ing in decoder-only transformers with circuit tracing.arXiv preprint arXiv:2509.20336, 2025. 8
-
[11]
A D’Amour, KA Heller, DI Moldovan, B Adlam, B Ali- panahi, A Beutel, C Chen, J Deaton, J Eisenstein, MD Hoff- man, et al. Underspecification presents challenges for credi- bility in modern machine learning. arxiv 2011.03395.arXiv preprint arXiv:2011.03395 [cs, stat], 2020. 2
-
[12]
Disparities in dermatology ai performance on a di- verse, curated clinical image set.Science advances, 8(31): eabq6147, 2022
Roxana Daneshjou, Kailas V odrahalli, Roberto A Novoa, Melissa Jenkins, Weixin Liang, Veronica Rotemberg, Justin Ko, Susan M Swetter, Elizabeth E Bailey, Olivier Gevaert, et al. Disparities in dermatology ai performance on a di- verse, curated clinical image set.Science advances, 8(31): eabq6147, 2022. 2
2022
-
[13]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee, 2009. 7, 1, 4
2009
-
[14]
On the strong correlation between model invariance and generaliza- tion.Advances in Neural Information Processing Systems, 35:28052–28067, 2022
Weijian Deng, Stephen Gould, and Liang Zheng. On the strong correlation between model invariance and generaliza- tion.Advances in Neural Information Processing Systems, 35:28052–28067, 2022. 8
2022
-
[15]
A mathemati- cal framework for transformer circuits.Transformer Circuits Thread, 1(1):12, 2021
Nelson Elhage, Neel Nanda, Catherine Olsson, Tom Henighan, Nicholas Joseph, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, et al. A mathemati- cal framework for transformer circuits.Transformer Circuits Thread, 1(1):12, 2021. 3, 8
2021
-
[16]
Fine-tuning language models with just forward passes.NeurIPS, 2023
Malladi et al. Fine-tuning language models with just forward passes.NeurIPS, 2023. 8
2023
-
[17]
Assessing the accuracy of diagnostic tests.Shanghai archives of psychiatry, 30(3):207, 2018
LI Fangyu and HE Hua. Assessing the accuracy of diagnostic tests.Shanghai archives of psychiatry, 30(3):207, 2018. 7
2018
-
[18]
arXiv preprint arXiv:2403.00824 , year=
Javier Ferrando and Elena V oita. Information flow routes: Automatically interpreting language models at scale.arXiv preprint arXiv:2403.00824, 2024. 4
-
[19]
Saurabh Garg, Sivaraman Balakrishnan, Zachary C Lipton, Behnam Neyshabur, and Hanie Sedghi. Leveraging unla- beled data to predict out-of-distribution performance.arXiv preprint arXiv:2201.04234, 2022. 2, 4, 5, 7, 8
-
[20]
Rankme: Assessing the downstream perfor- mance of pretrained self-supervised representations by their rank
Quentin Garrido, Randall Balestriero, Laurent Najman, and Yann Lecun. Rankme: Assessing the downstream perfor- mance of pretrained self-supervised representations by their rank. InInternational conference on machine learning, pages 10929–10974. PMLR, 2023. 4, 5, 7, 8
2023
-
[21]
A survey of uncertainty in deep neural networks.Arti- ficial Intelligence Review, 56(Suppl 1):1513–1589, 2023
Jakob Gawlikowski, Cedrique Rovile Njieutcheu Tassi, Mohsin Ali, Jongseok Lee, Matthias Humt, Jianxiang Feng, Anna Kruspe, Rudolph Triebel, Peter Jung, Ribana Roscher, et al. A survey of uncertainty in deep neural networks.Arti- ficial Intelligence Review, 56(Suppl 1):1513–1589, 2023. 2
2023
-
[22]
Shortcut learning in deep neural networks
Robert Geirhos, J ¨orn-Henrik Jacobsen, Claudio Michaelis, Richard Zemel, Wieland Brendel, Matthias Bethge, and Fe- lix A Wichmann. Shortcut learning in deep neural networks. Nature Machine Intelligence, 2(11):665–673, 2020. 5
2020
-
[23]
Mldemon: Deployment monitoring for machine learning systems
Tony Ginart, Martin Jinye Zhang, and James Zou. Mldemon: Deployment monitoring for machine learning systems. In International conference on artificial intelligence and statis- tics, pages 3962–3997. PMLR, 2022. 2
2022
-
[24]
Generalization—a key challenge for respon- sible ai in patient-facing clinical applications.NPJ Digital Medicine, 7(1):126, 2024
Lea Goetz, Nabeel Seedat, Robert Vandersluis, and Mihaela van der Schaar. Generalization—a key challenge for respon- sible ai in patient-facing clinical applications.NPJ Digital Medicine, 7(1):126, 2024. 1
2024
-
[25]
Predicting with confidence on unseen distributions
Devin Guillory, Vaishaal Shankar, Sayna Ebrahimi, Trevor Darrell, and Ludwig Schmidt. Predicting with confidence on unseen distributions. InProceedings of the IEEE/CVF international conference on computer vision, pages 1134– 1144, 2021. 2
2021
-
[26]
Interpbench: Semi-synthetic trans- formers for evaluating mechanistic interpretability tech- niques.Advances in Neural Information Processing Systems, 37:92922–92951, 2024
Rohan Gupta, Iv ´an Arcuschin Moreno, Thomas Kwa, and Adri`a Garriga-Alonso. Interpbench: Semi-synthetic trans- formers for evaluating mechanistic interpretability tech- niques.Advances in Neural Information Processing Systems, 37:92922–92951, 2024. 8
2024
-
[27]
arXiv preprint arXiv:2403.17806 (2024) 3, 5, 9, 19
Michael Hanna, Sandro Pezzelle, and Yonatan Belinkov. Have faith in faithfulness: Going beyond circuit over- lap when finding model mechanisms.arXiv preprint arXiv:2403.17806, 2024. 2, 3, 8, 4, 7
-
[28]
Benchmarking Neural Network Robustness to Common Corruptions and Perturbations
Dan Hendrycks and Thomas Dietterich. Benchmarking neu- ral network robustness to common corruptions and perturba- tions.arXiv preprint arXiv:1903.12261, 2019. 6, 7, 1
work page internal anchor Pith review arXiv 1903
-
[29]
A Baseline for Detecting Misclassified and Out-of-Distribution Examples in Neural Networks
Dan Hendrycks and Kevin Gimpel. A baseline for detecting misclassified and out-of-distribution examples in neural net- works.arXiv preprint arXiv:1610.02136, 2016. 2, 4, 5, 7, 8
work page internal anchor Pith review arXiv 2016
-
[30]
How transform- ers solve propositional logic problems: A mechanistic anal- ysis
Guan Zhe Hong, Nishanth Dikkala, Enming Luo, Cyrus Rashtchian, Xin Wang, and Rina Panigrahy. How transform- ers solve propositional logic problems: A mechanistic anal- ysis. 2024. 8
2024
-
[31]
Relations between two sets of variates
Harold Hotelling. Relations between two sets of variates. In Breakthroughs in statistics: methodology and distribution, pages 162–190. Springer, 1992. 4
1992
-
[32]
Evalua- tion gaps in machine learning practice
Ben Hutchinson, Negar Rostamzadeh, Christina Greer, Katherine Heller, and Vinodkumar Prabhakaran. Evalua- tion gaps in machine learning practice. InProceedings of the 2022 ACM conference on fairness, accountability, and transparency, pages 1859–1876, 2022. 1
2022
-
[33]
Cheng Jin, Zhengrui Guo, Yi Lin, Luyang Luo, and Hao Chen. Label-efficient deep learning in medical image anal- ysis: Challenges and future directions.arXiv preprint arXiv:2303.12484, 2023. 1
-
[34]
Wilds: A benchmark of in-the- wild distribution shifts
Pang Wei Koh, Shiori Sagawa, Henrik Marklund, Sang Michael Xie, Marvin Zhang, Akshay Balsubra- mani, Weihua Hu, Michihiro Yasunaga, Richard Lanas Phillips, Irena Gao, et al. Wilds: A benchmark of in-the- wild distribution shifts. InInternational conference on machine learning, pages 5637–5664. PMLR, 2021. 4, 7, 1
2021
-
[35]
Active testing: Sample-efficient model evalu- ation
Jannik Kossen, Sebastian Farquhar, Yarin Gal, and Tom Rainforth. Active testing: Sample-efficient model evalu- ation. InInternational Conference on Machine Learning, pages 5753–5763. PMLR, 2021. 1
2021
-
[36]
Michael Lan, Philip Torr, and Fazl Barez. Towards inter- pretable sequence continuation: Analyzing shared circuits in large language models.arXiv preprint arXiv:2311.04131,
-
[37]
Mnist hand- written digit database.ATT Labs [Online]
Yann LeCun, Corinna Cortes, and CJ Burges. Mnist hand- written digit database.ATT Labs [Online]. Available: http://yann.lecun.com/exdb/mnist, 2, 2010. 4
2010
-
[38]
Deeper, broader and artier domain generaliza- tion
Da Li, Yongxin Yang, Yi-Zhe Song, and Timothy M Hospedales. Deeper, broader and artier domain generaliza- tion. InProceedings of the IEEE international conference on computer vision, pages 5542–5550, 2017. 4, 7, 1
2017
-
[39]
Optimal ablation for in- terpretability.Advances in Neural Information Processing Systems, 37:109233–109282, 2024
Maximilian Li and Lucas Janson. Optimal ablation for in- terpretability.Advances in Neural Information Processing Systems, 37:109233–109282, 2024. 4
2024
-
[40]
Beyond accuracy: en- suring correct predictions with correct rationales.Advances in Neural Information Processing Systems, 37:43164–43188,
Tang Li, Mengmeng Ma, and Xi Peng. Beyond accuracy: en- suring correct predictions with correct rationales.Advances in Neural Information Processing Systems, 37:43164–43188,
-
[41]
Towards good practices for efficiently annotating large-scale image classification datasets
Yuan-Hong Liao, Amlan Kar, and Sanja Fidler. Towards good practices for efficiently annotating large-scale image classification datasets. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4350–4359, 2021. 1
2021
-
[42]
” why is there a tumor?”: Tell me the reason, show me the ev- idence
Mengmeng Ma, Tang Li, Yunxiang Peng, Lu Lin, V olkan Beylergil, Binsheng Zhao, Oguz Akin, and Xi Peng. ” why is there a tumor?”: Tell me the reason, show me the ev- idence. InForty-second International Conference on Ma- chine Learning. 1
-
[43]
Smil: Multimodal learning with severely missing modality
Mengmeng Ma, Jian Ren, Long Zhao, Sergey Tulyakov, Cathy Wu, and Xi Peng. Smil: Multimodal learning with severely missing modality. InProceedings of the AAAI con- ference on artificial intelligence, pages 2302–2310, 2021. 8
2021
-
[44]
Beyond the feder- ation: Topology-aware federated learning for generalization to unseen clients
Mengmeng Ma, Tang Li, and Xi Peng. Beyond the feder- ation: Topology-aware federated learning for generalization to unseen clients. InProceedings of the International Con- ference on Machine Learning (ICML), 2024. 8
2024
-
[45]
Sparse Feature Circuits: Discovering and Editing Interpretable Causal Graphs in Language Models
Samuel Marks, Can Rager, Eric J Michaud, Yonatan Be- linkov, David Bau, and Aaron Mueller. Sparse feature cir- cuits: Discovering and editing interpretable causal graphs in language models.arXiv preprint arXiv:2403.19647, 2024. 4
work page internal anchor Pith review arXiv 2024
-
[46]
Alexander Meinke, Julian Bitterwolf, and Matthias Hein. Provably robust detection of out-of-distribution data (almost) for free.arXiv preprint arXiv:2106.04260, 2021. 2
-
[47]
Locating and editing factual associations in gpt.Ad- vances in neural information processing systems, 35:17359– 17372, 2022
Kevin Meng, David Bau, Alex Andonian, and Yonatan Be- linkov. Locating and editing factual associations in gpt.Ad- vances in neural information processing systems, 35:17359– 17372, 2022. 3, 8, 4
2022
-
[48]
Jack Merullo, Carsten Eickhoff, and Ellie Pavlick. Circuit component reuse across tasks in transformer language mod- els.arXiv preprint arXiv:2310.08744, 2023. 8
-
[49]
Accuracy on the line: on the strong correlation between out-of-distribution and in- distribution generalization
John P Miller, Rohan Taori, Aditi Raghunathan, Shiori Sagawa, Pang Wei Koh, Vaishaal Shankar, Percy Liang, Yair Carmon, and Ludwig Schmidt. Accuracy on the line: on the strong correlation between out-of-distribution and in- distribution generalization. InInternational conference on machine learning, pages 7721–7735. PMLR, 2021. 2, 4, 5, 8
2021
-
[50]
Philipp Mondorf, Sondre Wold, and Barbara Plank. Circuit compositions: Exploring modular structures in transformer- based language models.arXiv preprint arXiv:2410.01434,
-
[51]
Mib: A mechanistic interpretability benchmark,
Aaron Mueller, Atticus Geiger, Sarah Wiegreffe, Dana Arad, Iv´an Arcuschin, Adam Belfki, Yik Siu Chan, Jaden Fiotto- Kaufman, Tal Haklay, Michael Hanna, Jing Huang, Rohan Gupta, Yaniv Nikankin, Hadas Orgad, Nikhil Prakash, Anja Reusch, Aruna Sankaranarayanan, Shun Shao, Alessandro Stolfo, Martin Tutek, Amir Zur, David Bau, and Yonatan Belinkov. Mib: A mec...
-
[52]
arXiv preprint arXiv:2411.16105 , year=
Jatin Nainani, Sankaran Vaidyanathan, AJ Yeung, Kartik Gupta, and David Jensen. Adaptive circuit behavior and generalization in mechanistic interpretability.arXiv preprint arXiv:2411.16105, 2024. 8
-
[53]
Yixin Ou, Yunzhi Yao, Ningyu Zhang, Hui Jin, Jiacheng Sun, Shumin Deng, Zhenguo Li, and Huajun Chen. How do llms acquire new knowledge? a knowledge circuits perspective on continual pre-training.arXiv preprint arXiv:2502.11196, 2025. 8
-
[54]
Energy-based automated model evaluation.arXiv preprint arXiv:2401.12689, 2024
Ru Peng, Heming Zou, Haobo Wang, Yawen Zeng, Zenan Huang, and Junbo Zhao. Energy-based automated model evaluation.arXiv preprint arXiv:2401.12689, 2024. 4, 5, 7, 8
-
[55]
Learning to learn single domain generalization
Fengchun Qiao, Long Zhao, and Xi Peng. Learning to learn single domain generalization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12556–12565, 2020. 2, 8
2020
-
[56]
Mit Press, 2022
Joaquin Qui ˜nonero-Candela, Masashi Sugiyama, Anton Schwaighofer, and Neil D Lawrence.Dataset shift in ma- chine learning. Mit Press, 2022. 2
2022
-
[57]
Failing loudly: an empirical study of methods for detecting dataset shift
S Rabanser, S G ¨unnemann, and ZC Lipton. Failing loudly: an empirical study of methods for detecting dataset shift. arxiv e-prints.arXiv preprint arXiv:1810.11953, 2018. 2
-
[58]
Daking Rai, Yilun Zhou, Shi Feng, Abulhair Saparov, and Ziyu Yao. A practical review of mechanistic interpretabil- ity for transformer-based language models.arXiv preprint arXiv:2407.02646, 2024. 2, 8
-
[59]
arXiv preprint arXiv:2404.14349 (2024) 2, 3
Achyuta Rajaram, Neil Chowdhury, Antonio Torralba, Jacob Andreas, and Sarah Schwettmann. Automatic discovery of visual circuits.arXiv preprint arXiv:2404.14349, 2024. 8
-
[60]
Do imagenet classifiers generalize to im- agenet? InInternational conference on machine learning, pages 5389–5400
Benjamin Recht, Rebecca Roelofs, Ludwig Schmidt, and Vaishaal Shankar. Do imagenet classifiers generalize to im- agenet? InInternational conference on machine learning, pages 5389–5400. PMLR, 2019. 7, 1
2019
-
[61]
Shiori Sagawa, Pang Wei Koh, Tatsunori B Hashimoto, and Percy Liang. Distributionally robust neural networks for group shifts: On the importance of regularization for worst- case generalization.arXiv preprint arXiv:1911.08731, 2019. 4
work page internal anchor Pith review arXiv 1911
-
[62]
Predicting the per- formance of foundation models via agreement-on-the-line
Rahul Saxena, Taeyoun Kim, Aman Mehra, Christina Baek, J Zico Kolter, and Aditi Raghunathan. Predicting the per- formance of foundation models via agreement-on-the-line. Advances in Neural Information Processing Systems, 37: 31854–31906, 2024. 8
2024
-
[63]
Samuel Schapiro and Han Zhao. Towards understand- ing the role of sharpness-aware minimization algorithms for out-of-distribution generalization.arXiv preprint arXiv:2412.05169, 2024. 8
-
[64]
Measures of diagnostic accuracy: ba- sic definitions.ejifcc, 19(4):203, 2009
Ana-Maria ˇSimundi´c. Measures of diagnostic accuracy: ba- sic definitions.ejifcc, 19(4):203, 2009. 7
2009
-
[65]
arXiv preprint arXiv:2310.10348 , year=
Aaquib Syed, Can Rager, and Arthur Conmy. Attribution patching outperforms automated circuit discovery.arXiv preprint arXiv:2310.10348, 2023. 8, 4
-
[66]
The problem with metrics is a big problem for ai
R Thomas. The problem with metrics is a big problem for ai. Retrieved December, 23:2019, 2019. 1
2019
-
[67]
Netlsd: hearing the shape of a graph
Anton Tsitsulin, Davide Mottin, Panagiotis Karras, Alexan- der Bronstein, and Emmanuel M ¨uller. Netlsd: hearing the shape of a graph. InProceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining, pages 2347–2356, 2018. 6, 2
2018
-
[68]
A tutorial on spectral clustering.Statis- tics and computing, 17(4):395–416, 2007
Ulrike V on Luxburg. A tutorial on spectral clustering.Statis- tics and computing, 17(4):395–416, 2007. 6, 2
2007
-
[69]
On calibration and out-of-domain generalization.Advances in neural information processing systems, 34:2215–2227,
Yoav Wald, Amir Feder, Daniel Greenfeld, and Uri Shalit. On calibration and out-of-domain generalization.Advances in neural information processing systems, 34:2215–2227,
-
[70]
Learning robust global representations by penalizing local predictive power
Haohan Wang, Songwei Ge, Zachary Lipton, and Eric P Xing. Learning robust global representations by penalizing local predictive power. InAdvances in Neural Information Processing Systems, pages 10506–10518, 2019. 7, 1
2019
-
[71]
Interpretability in the Wild: a Circuit for Indirect Object Identification in GPT-2 small
Kevin Wang, Alexandre Variengien, Arthur Conmy, Buck Shlegeris, and Jacob Steinhardt. Interpretability in the wild: a circuit for indirect object identification in gpt-2 small. arXiv preprint arXiv:2211.00593, 2022. 2, 3, 8
work page internal anchor Pith review arXiv 2022
-
[72]
Annotation-efficient deep learning for automatic medical image segmentation.Nature communica- tions, 12(1):5915, 2021
Shanshan Wang, Cheng Li, Rongpin Wang, Zaiyi Liu, Meiyun Wang, Hongna Tan, Yaping Wu, Xinfeng Liu, Hui Sun, Rui Yang, et al. Annotation-efficient deep learning for automatic medical image segmentation.Nature communica- tions, 12(1):5915, 2021. 1
2021
-
[73]
Assaying out-of-distribution generalization in transfer learning.Ad- vances in Neural Information Processing Systems, 35:7181– 7198, 2022
Florian Wenzel, Andrea Dittadi, Peter Gehler, Carl-Johann Simon-Gabriel, Max Horn, Dominik Zietlow, David Kernert, Chris Russell, Thomas Brox, Bernt Schiele, et al. Assaying out-of-distribution generalization in transfer learning.Ad- vances in Neural Information Processing Systems, 35:7181– 7198, 2022. 2
2022
-
[74]
PyTorch Image Models
Ross Wightman. PyTorch Image Models. 7, 2
-
[75]
Generalized out-of-distribution detection: A survey.Inter- national Journal of Computer Vision, 132(12):5635–5662,
Jingkang Yang, Kaiyang Zhou, Yixuan Li, and Ziwei Liu. Generalized out-of-distribution detection: A survey.Inter- national Journal of Computer Vision, 132(12):5635–5662,
-
[76]
Knowledge circuits in pretrained transformers.Advances in Neural Information Processing Systems, 37:118571–118602, 2024
Yunzhi Yao, Ningyu Zhang, Zekun Xi, Mengru Wang, Ziwen Xu, Shumin Deng, and Huajun Chen. Knowledge circuits in pretrained transformers.Advances in Neural Information Processing Systems, 37:118571–118602, 2024. 8
2024
-
[77]
Jason Yosinski, Jeff Clune, Anh Nguyen, Thomas Fuchs, and Hod Lipson. Understanding neural networks through deep visualization.arXiv preprint arXiv:1506.06579, 2015. 5
-
[78]
A survey on evaluation of out-of-distribution general- ization.arXiv preprint arXiv:2403.01874, 2024
Han Yu, Jiashuo Liu, Xingxuan Zhang, Jiayun Wu, and Peng Cui. A survey on evaluation of out-of-distribution general- ization.arXiv preprint arXiv:2403.01874, 2024. 1, 8
-
[79]
Qinan Yu, Jack Merullo, and Ellie Pavlick. Characterizing mechanisms for factual recall in language models.arXiv preprint arXiv:2310.15910, 2023. 8
-
[80]
and Fergus, Rob , month = nov, year =
Matthew D Zeiler and Rob Fergus. Visualizing and un- derstanding convolutional networks. arxiv.arXiv preprint arXiv:1311.2901, 2013. 5
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.