Recognition: no theorem link
OmniJigsaw: Enhancing Omni-Modal Reasoning via Modality-Orchestrated Reordering
Pith reviewed 2026-05-10 17:41 UTC · model grok-4.3
The pith
Reordering shuffled audio-visual clips with orchestrated modality strategies improves omni-modal reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
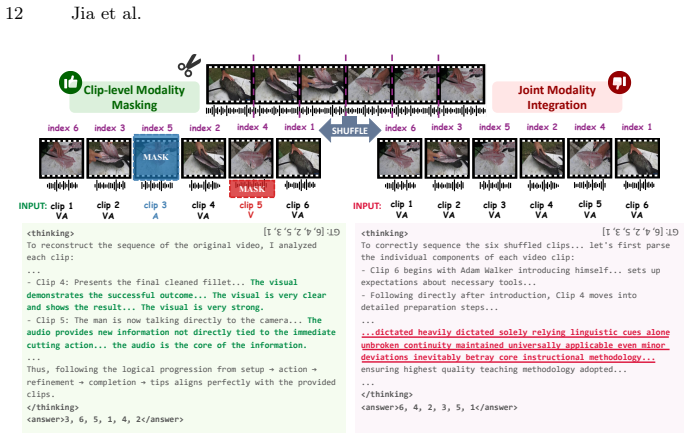
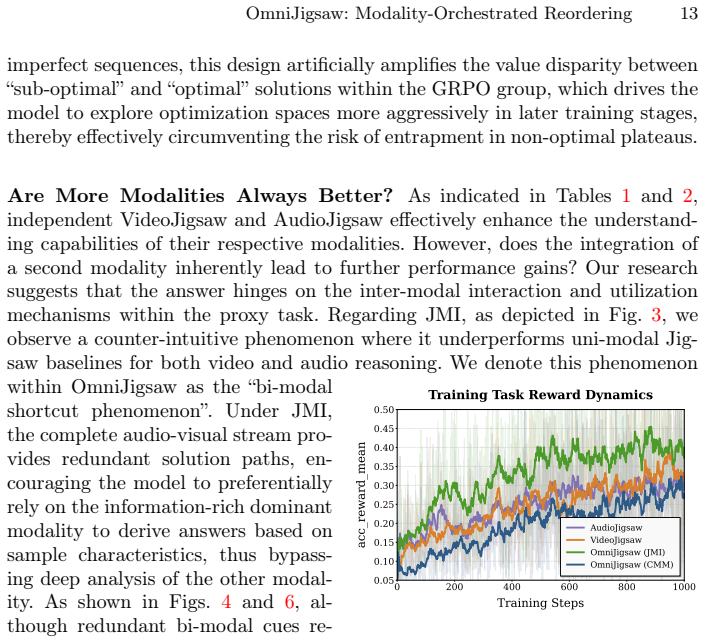
Centered on the chronological reconstruction of shuffled audio-visual clips, OmniJigsaw employs three distinct strategies—Joint Modality Integration, Sample-level Modality Selection, and Clip-level Modality Masking—to compel cross-modal integration. The approach includes a two-stage coarse-to-fine data filtering pipeline to handle massive unannotated omni-modal data efficiently. Analysis reveals a bi-modal shortcut phenomenon in joint integration that clip-level masking mitigates, producing substantial gains on 15 benchmarks for video, audio, and collaborative reasoning.
What carries the argument
The chronological reconstruction proxy task orchestrated through Joint Modality Integration, Sample-level Modality Selection, and Clip-level Modality Masking, which compels models to combine audio and visual cues to recover original clip order.
Load-bearing premise
That the reordering task with the three modality strategies forces genuine cross-modal integration instead of letting models exploit single-modality shortcuts.
What would settle it
If models trained via OmniJigsaw show no gains over baselines on the 15 video, audio, and collaborative reasoning benchmarks, or if they continue to solve the task using only one modality despite the masking strategy.
Figures








read the original abstract
To extend the reinforcement learning post-training paradigm to omni-modal models for concurrently bolstering video-audio understanding and collaborative reasoning, we propose OmniJigsaw, a generic self-supervised framework built upon a temporal reordering proxy task. Centered on the chronological reconstruction of shuffled audio-visual clips, this paradigm strategically orchestrates visual and auditory signals to compel cross-modal integration through three distinct strategies: Joint Modality Integration, Sample-level Modality Selection, and Clip-level Modality Masking. Recognizing that the efficacy of such proxy tasks is fundamentally tied to puzzle quality, we design a two-stage coarse-to-fine data filtering pipeline, which facilitates the efficient adaptation of OmniJigsaw to massive unannotated omni-modal data. Our analysis reveals a ``bi-modal shortcut phenomenon'' in joint modality integration and demonstrates that fine-grained clip-level modality masking mitigates this issue while outperforming sample-level modality selection. Extensive evaluations on 15 benchmarks show substantial gains in video, audio, and collaborative reasoning, validating OmniJigsaw as a scalable paradigm for self-supervised omni-modal learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes OmniJigsaw, a self-supervised framework for omni-modal (video-audio) models that centers on a temporal reordering proxy task: reconstructing the chronological order of shuffled audio-visual clips. It introduces three modality orchestration strategies—Joint Modality Integration, Sample-level Modality Selection, and Clip-level Modality Masking—along with a two-stage coarse-to-fine data filtering pipeline to generate high-quality puzzles from unannotated data. The authors identify a 'bi-modal shortcut phenomenon' in joint integration and claim that clip-level masking mitigates it while outperforming sample-level selection. Extensive evaluations on 15 benchmarks are reported to show substantial gains in video understanding, audio understanding, and collaborative reasoning, positioning the method as a scalable paradigm for self-supervised omni-modal learning that extends reinforcement learning post-training.
Significance. If the central claims hold with robust evidence, the work would offer a practical, data-efficient approach to self-supervised omni-modal pretraining that explicitly targets cross-modal integration rather than relying on joint embedding alone. The two-stage filtering pipeline and the explicit handling of shortcuts could be broadly useful for scaling to large unannotated corpora. The reported gains across 15 benchmarks, if reproducible and properly controlled, would strengthen the case for proxy-task-based post-training in multi-modal settings.
major comments (3)
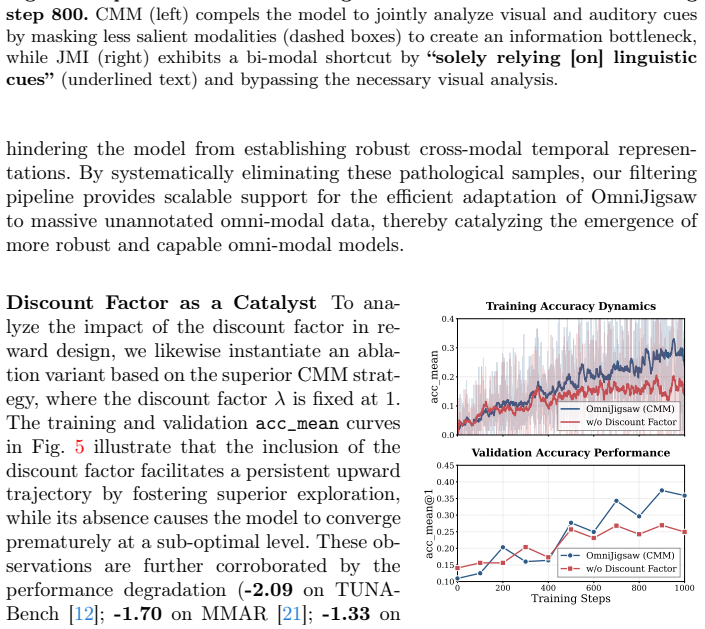
- [§4] §4 (Analysis of bi-modal shortcut): The claim that clip-level modality masking mitigates the bi-modal shortcut phenomenon and forces genuine cross-modal integration is load-bearing for the central contribution, yet the manuscript provides no quantitative ablation showing reconstruction accuracy when intra-modality temporal cues are removed (e.g., via additional masking or cue-disruption controls). Without such evidence, it remains possible that performance gains derive from improved within-modality modeling rather than the intended omni-modal reasoning.
- [§5] §5 (Experiments): The reported 'substantial gains' on 15 benchmarks are central to validating the framework, but the manuscript lacks details on baseline models, exact metrics, error bars, statistical significance, and whether the same backbone and training compute are used across comparisons. This makes it difficult to assess whether the improvements are attributable to the proxy task or to other factors such as data scale or filtering.
- [§3.2] §3.2 (Clip-level Modality Masking): The description of how clip-level masking is implemented during the reordering task does not specify the masking ratio, whether masking is applied independently per modality or jointly, or how the model is trained to handle missing modalities. These details are necessary to evaluate whether the strategy truly eliminates shortcuts or merely shifts them.
minor comments (2)
- [Abstract] The abstract and introduction use the term 'omni-modal' without a precise definition of the modalities involved beyond video and audio; a short clarification would improve readability.
- [Figures/Tables] Figure captions and table headers should explicitly state the evaluation metrics (e.g., accuracy, mAP) and the number of runs used for reported numbers.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. The comments have identified important areas where the manuscript can be strengthened for clarity and rigor. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [§4] §4 (Analysis of bi-modal shortcut): The claim that clip-level modality masking mitigates the bi-modal shortcut phenomenon and forces genuine cross-modal integration is load-bearing for the central contribution, yet the manuscript provides no quantitative ablation showing reconstruction accuracy when intra-modality temporal cues are removed (e.g., via additional masking or cue-disruption controls). Without such evidence, it remains possible that performance gains derive from improved within-modality modeling rather than the intended omni-modal reasoning.
Authors: We agree that the current analysis in §4, while showing performance differences across orchestration strategies, does not include a direct quantitative control that isolates intra-modality temporal cues. To address this, we will add a new ablation in the revised §4 that reports reconstruction accuracy after explicitly disrupting within-modality cues (via additional per-modality shuffling or masking) while preserving the cross-modal setup. This will provide evidence on whether gains derive from enforced omni-modal integration. The revision will include updated text, results, and discussion. revision: yes
-
Referee: [§5] §5 (Experiments): The reported 'substantial gains' on 15 benchmarks are central to validating the framework, but the manuscript lacks details on baseline models, exact metrics, error bars, statistical significance, and whether the same backbone and training compute are used across comparisons. This makes it difficult to assess whether the improvements are attributable to the proxy task or to other factors such as data scale or filtering.
Authors: We acknowledge that these experimental details are necessary for proper evaluation and reproducibility. In the revised manuscript we will expand §5 with: full specifications of all baseline models and their training setups, the precise metrics and protocols for each benchmark, error bars from multiple runs with standard deviations, statistical significance tests, and explicit confirmation that all comparisons use identical backbones and matched compute budgets. We will also clarify the contribution of the data filtering pipeline relative to the proxy task. revision: yes
-
Referee: [§3.2] §3.2 (Clip-level Modality Masking): The description of how clip-level masking is implemented during the reordering task does not specify the masking ratio, whether masking is applied independently per modality or jointly, or how the model is trained to handle missing modalities. These details are necessary to evaluate whether the strategy truly eliminates shortcuts or merely shifts them.
Authors: We thank the referee for noting these missing implementation specifics. In the revised §3.2 we will add: the exact masking ratio used, whether masking decisions are made independently per modality or jointly, and the precise training procedure for missing modalities (including how the reordering objective is computed on available signals). These clarifications will be accompanied by pseudocode or an expanded figure to ensure the strategy can be fully understood and reproduced. revision: yes
Circularity Check
No circularity detected in method proposal or empirical claims
full rationale
The paper introduces OmniJigsaw as a self-supervised framework centered on a temporal reordering proxy task with three modality orchestration strategies and a two-stage data filtering pipeline, supported by analysis of bi-modal shortcuts and evaluations across 15 benchmarks. No mathematical derivations, equations, fitted parameters renamed as predictions, or self-referential definitions appear in the provided text. Claims rest on empirical outcomes and design choices rather than reductions to inputs by construction, rendering the chain self-contained with no load-bearing self-citations or ansatzes that collapse into prior results.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., Zhong, H., Zhu, Y., Yang, M., Li, Z., Wan, J., Wang, P., Ding, W., Fu, Z., Xu, Y., Ye, J., Zhang, X., Xie, T., Cheng, Z., Zhang, H., Yang, Z., Xu, H., Lin, J.: Qwen2.5-vl technical report (2025),https://arxiv.org/abs/2502.13923
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
arXiv preprint arXiv:2602.05847 (2026)
Chen, Z., Tao, J., Li, R., Hu, Y., Chen, R., Yang, Z., Yu, X., Jing, H., Zhang, M., Shao, S., et al.: Omnivideo-r1: Reinforcing audio-visual reasoning with query intention and modality attention. arXiv preprint arXiv:2602.05847 (2026)
- [3]
-
[4]
arXiv preprint arXiv:2406.04615 (2024)
Çoban, E.B., Mandel, M.I., Devaney, J.: What do mllms hear? examining reason- ing with text and sound components in multimodal large language models. arXiv preprint arXiv:2406.04615 (2024)
-
[5]
Farré, M., Marafioti, A., Tunstall, L., Von Werra, L., Wolf, T.: Finevideo.https: //huggingface.co/datasets/HuggingFaceFV/finevideo(2024)
2024
-
[6]
Video-R1: Reinforcing Video Reasoning in MLLMs
Feng, K., Gong, K., Li, B., Guo, Z., Wang, Y., Peng, T., Wu, J., Zhang, X., Wang, B., Yue, X.: Video-r1: Reinforcing video reasoning in mllms. arXiv preprint arXiv:2503.21776 (2025)
work page internal anchor Pith review arXiv 2025
-
[7]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Fu, C., Dai, Y., Luo, Y., Li, L., Ren, S., Zhang, R., Wang, Z., Zhou, C., Shen, Y., Zhang, M., et al.: Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 24108–24118 (2025)
2025
-
[8]
Grattafiori, A., Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Let- man, A., Mathur, A., Schelten, A., Vaughan, A., et al.: The llama 3 herd of models. arXiv preprint arXiv:2407.21783 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [9]
-
[10]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Guo, D., Yang, D., Zhang, H., Song, J., Wang, P., Zhu, Q., Xu, R., Zhang, R., Ma, S., Bi, X., et al.: Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
VIDEOP2R: Video Understanding from Perception to Reasoning
Jiang, Y., Wang, Y., Zhao, R., Parag, T., Chen, Z., Liao, Z., Unnikrishnan, J.: Videop2r: Video understanding from perception to reasoning. arXiv preprint arXiv:2511.11113 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
In: Proceedings of the 63rd Annual Meeting of the Asso- ciation for Computational Linguistics (Volume 1: Long Papers)
Kong, F., Zhang, J., Zhang, H., Feng, S., Wang, D., Yu, L., Ji, X., Tian, Y., Zhang, F., et al.: Tuna: Comprehensive fine-grained temporal understanding evaluation on dense dynamic videos. In: Proceedings of the 63rd Annual Meeting of the Asso- ciation for Computational Linguistics (Volume 1: Long Papers). pp. 1810–1839 (2025)
2025
-
[13]
Kumar, S., Sedláček, Š., Lokegaonkar, V., López, F., Yu, W., Anand, N., Ryu, H., Chen, L., Plička, M., Hlaváček, M., et al.: Mmau-pro: A challenging and com- prehensive benchmark for holistic evaluation of audio general intelligence. arXiv preprint arXiv:2508.13992 (2025)
-
[14]
Tulu 3: Pushing Frontiers in Open Language Model Post-Training
Lambert, N., Morrison, J., Pyatkin, V., Huang, S., Ivison, H., Brahman, F., Mi- randa, L.J.V., Liu, A., Dziri, N., Lyu, S., et al.: Tulu 3: Pushing frontiers in open language model post-training. arXiv preprint arXiv:2411.15124 (2024)
work page internal anchor Pith review arXiv 2024
-
[15]
Omnivideobench: Towards audio-visual understanding evaluation for omni mllms, 2025
Li, C., Chen, Y., Ji, Y., Xu, J., Cui, Z., Li, S., Zhang, Y., Wang, W., Song, Z., Zhang, D., et al.: Omnivideobench: Towards audio-visual understanding evaluation for omni mllms. arXiv preprint arXiv:2510.10689 (2025) 16 Jia et al
-
[16]
Videochat-r1: Enhancing spatio-temporal perception via reinforcement fine-tuning,
Li,X.,Yan,Z.,Meng,D.,Dong,L.,Zeng,X.,He,Y.,Wang,Y.,Qiao,Y.,Wang,Y., Wang, L.: Videochat-r1: Enhancing spatio-temporal perception via reinforcement fine-tuning. arXiv preprint arXiv:2504.06958 (2025)
-
[17]
A comprehensive survey on world models for embodied AI.arXiv preprintarXiv:2510.16732, 2025
Li, X., He, X., Zhang, L., Wu, M., Li, X., Liu, Y.: A comprehensive survey on world models for embodied ai. arXiv preprint arXiv:2510.16732 (2025)
-
[18]
Li, Y., Liu, Z., Li, Z., Zhang, X., Xu, Z., Chen, X., Shi, H., Jiang, S., Wang, X., Wang, J., et al.: Perception, reason, think, and plan: A survey on large multimodal reasoning models. arXiv preprint arXiv:2505.04921 (2025)
-
[19]
Liu, Y., Li, S., Liu, Y., Wang, Y., Ren, S., Li, L., Chen, S., Sun, X., Hou, L.: Tem- pcompass: Do video llms really understand videos? In: Findings of the Association for Computational Linguistics: ACL 2024. pp. 8731–8772 (2024)
2024
-
[20]
In: Proceedings of the IEEE/CVF Interna- tional Conference on Computer Vision
Liu, Z., Sun, Z., Zang, Y., Dong, X., Cao, Y., Duan, H., Lin, D., Wang, J.: Visual- rft: Visual reinforcement fine-tuning. In: Proceedings of the IEEE/CVF Interna- tional Conference on Computer Vision. pp. 2034–2044 (2025)
2034
-
[21]
Mmar: A challenging benchmark for deep reasoning in speech, audio, music, and their mix,
Ma, Z., Ma, Y., Zhu, Y., Yang, C., Chao, Y.W., Xu, R., Chen, W., Chen, Y., Chen, Z., Cong, J., et al.: Mmar: A challenging benchmark for deep reasoning in speech, audio, music, and their mix. arXiv preprint arXiv:2505.13032 (2025)
-
[22]
In: European conference on computer vision
Misra, I., Zitnick, C.L., Hebert, M.: Shuffle and learn: unsupervised learning using temporal order verification. In: European conference on computer vision. pp. 527–
-
[23]
In: European conference on computer vision
Noroozi, M., Favaro, P.: Unsupervised learning of visual representations by solving jigsaw puzzles. In: European conference on computer vision. pp. 69–84. Springer (2016)
2016
-
[24]
Advances in neural information processing sys- tems35, 27730–27744 (2022)
Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C., Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A., et al.: Training language models to follow instructions with human feedback. Advances in neural information processing sys- tems35, 27730–27744 (2022)
2022
-
[25]
Advances in neural information processing systems36, 53728–53741 (2023)
Rafailov, R., Sharma, A., Mitchell, E., Manning, C.D., Ermon, S., Finn, C.: Direct preference optimization: Your language model is secretly a reward model. Advances in neural information processing systems36, 53728–53741 (2023)
2023
-
[26]
arXiv preprint arXiv:2602.10102 (2026) 4
Ren, Z., Wei, Y., Yu, X., Luo, G., Zhao, Y., Kang, B., Feng, J., Jin, X.: Videoworld 2: Learning transferable knowledge from real-world videos (2026),https://arxiv. org/abs/2602.10102
-
[27]
Code Llama: Open Foundation Models for Code
Roziere, B., Gehring, J., Gloeckle, F., Sootla, S., Gat, I., Tan, X.E., Adi, Y., Liu, J., Sauvestre, R., Remez, T., et al.: Code llama: Open foundation models for code. arXiv preprint arXiv:2308.12950 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[28]
MMAU: A Massive Multi-Task Audio Understanding and Reasoning Benchmark
Sakshi, S., Tyagi, U., Kumar, S., Seth, A., Selvakumar, R., Nieto, O., Duraiswami, R., Ghosh, S., Manocha, D.: Mmau: A massive multi-task audio understanding and reasoning benchmark. arXiv preprint arXiv:2410.19168 (2024)
work page internal anchor Pith review arXiv 2024
-
[29]
Advances in neural information processing systems32(2019)
Sauder, J., Sievers, B.: Self-supervised deep learning on point clouds by recon- structing space. Advances in neural information processing systems32(2019)
2019
-
[30]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y., Wu, Y., et al.: Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
In: Proceedings of the Twentieth European Conference on Computer Systems
Sheng, G., Zhang, C., Ye, Z., Wu, X., Zhang, W., Zhang, R., Peng, Y., Lin, H., Wu, C.: Hybridflow: A flexible and efficient rlhf framework. In: Proceedings of the Twentieth European Conference on Computer Systems. pp. 1279–1297 (2025)
2025
-
[32]
In: International conference on information processing in medical imaging
Taleb, A., Lippert, C., Klein, T., Nabi, M.: Multimodal self-supervised learning for medical image analysis. In: International conference on information processing in medical imaging. pp. 661–673. Springer (2021) OmniJigsaw: Modality-Orchestrated Reordering 17
2021
-
[33]
arXiv preprint arXiv:2503.14935 (2025)
Tu, C., Zhang, L., Chen, P., Ye, P., Zeng, X., Cheng, W., Yu, G., Chen, T.: Favor- bench: A comprehensive benchmark for fine-grained video motion understanding. arXiv preprint arXiv:2503.14935 (2025)
-
[34]
Zephyr: Direct distillation of lm alignment.arXiv preprint arXiv:2310.16944, 2023
Tunstall, L., Beeching, E., Lambert, N., Rajani, N., Rasul, K., Belkada, Y., Huang, S., Von Werra, L., Fourrier, C., Habib, N., et al.: Zephyr: Direct distillation of lm alignment. arXiv preprint arXiv:2310.16944 (2023)
-
[35]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Wallace, B., Dang, M., Rafailov, R., Zhou, L., Lou, A., Purushwalkam, S., Ermon, S., Xiong, C., Joty, S., Naik, N.: Diffusion model alignment using direct preference optimization. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 8228–8238 (2024)
2024
-
[36]
Mmsu: A massive multi-task spoken language understanding and reasoning benchmark,
Wang, D., Wu, J., Li, J., Yang, D., Chen, X., Zhang, T., Meng, H.: Mmsu: A mas- sive multi-task spoken language understanding and reasoning benchmark. arXiv preprint arXiv:2506.04779 (2025)
-
[37]
arXiv preprint arXiv:2511.17945 (2025)
Wang, K., Lin, M.: Test-time temporal sampling for efficient mllm video under- standing. arXiv preprint arXiv:2511.17945 (2025)
-
[38]
arXiv preprint arXiv:2507.13609 (2025)
Wang, Y., Vizcarra, J., Li, Z., Niu, H., Kurokawa, M.: Cotasks: Chain-of-thought based video instruction tuning tasks. arXiv preprint arXiv:2507.13609 (2025)
-
[39]
Chen Wang, Lai Wei, Yanzhi Zhang, Chenyang Shao, Zedong Dan, Weiran Huang, Yuzhi Zhang, and Yue Wang
Wang, Y., Yang, Q., Zeng, Z., Ren, L., Liu, L., Peng, B., Cheng, H., He, X., Wang, K., Gao, J., et al.: Reinforcement learning for reasoning in large language models with one training example. arXiv preprint arXiv:2504.20571 (2025)
-
[40]
Visual jigsaw post-training improves mllms
Wu, P., Zhang, Y., Diao, H., Li, B., Lu, L., Liu, Z.: Visual jigsaw post-training improves mllms. arXiv preprint arXiv:2509.25190 (2025)
-
[41]
Xu, J., Guo, Z., He, J., Hu, H., He, T., Bai, S., Chen, K., Wang, J., Fan, Y., Dang, K., Zhang, B., Wang, X., Chu, Y., Lin, J.: Qwen2.5-omni technical report (2025), https://arxiv.org/abs/2503.20215
work page internal anchor Pith review arXiv 2025
-
[42]
Xu, J., Guo, Z., Hu, H., Chu, Y., Wang, X., He, J., Wang, Y., Shi, X., He, T., Zhu, X., et al.: Qwen3-omni technical report. arXiv preprint arXiv:2509.17765 (2025)
work page internal anchor Pith review arXiv 2025
-
[43]
Seeing the arrow of time in large multimodal models.arXiv preprint arXiv:2506.03340, 2025
Xue, Z., Luo, M., Grauman, K.: Seeing the arrow of time in large multimodal models. arXiv preprint arXiv:2506.03340 (2025)
-
[44]
Qwen2.5-Math Technical Report: Toward Mathematical Expert Model via Self-Improvement
Yang, A., Zhang, B., Hui, B., Gao, B., Yu, B., Li, C., Liu, D., Tu, J., Zhou, J., Lin, J., et al.: Qwen2. 5-math technical report: Toward mathematical expert model via self-improvement. arXiv preprint arXiv:2409.12122 (2024)
work page internal anchor Pith review arXiv 2024
-
[45]
arXiv preprint arXiv:2601.07850 (2026)
Yang, J., Zhang, P., Hill, S.: Mllm-vadstory: Domain knowledge-driven multimodal llms for video ad storyline insights. arXiv preprint arXiv:2601.07850 (2026)
-
[46]
arXiv preprint arXiv:2501.09502 (2025)
Yang, Q., Bai, D., Peng, Y.X., Wei, X.: Omni-emotion: Extending video mllm with detailed face and audio modeling for multimodal emotion analysis. arXiv preprint arXiv:2501.09502 (2025)
-
[47]
Yang, Q., Yao, S., Chen, W., Fu, S., Bai, D., Zhao, J., Sun, B., Yin, B., Wei, X., Zhou, J.: Humanomniv2: From understanding to omni-modal reasoning with context. arXiv preprint arXiv:2506.21277 (2025)
- [48]
-
[49]
Advances in neural information processing systems32(2019)
Yang, Z., Dai, Z., Yang, Y., Carbonell, J., Salakhutdinov, R.R., Le, Q.V.: Xlnet: Generalized autoregressive pretraining for language understanding. Advances in neural information processing systems32(2019)
2019
-
[50]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Yu, T., Yao, Y., Zhang, H., He, T., Han, Y., Cui, G., Hu, J., Liu, Z., Zheng, H.T., Sun, M., et al.: Rlhf-v: Towards trustworthy mllms via behavior alignment from fine-grained correctional human feedback. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 13807–13816 (2024) 18 Jia et al
2024
-
[51]
arXiv preprint arXiv:2511.08585 (2025)
Yue, J., Huang, Z., Chen, Z., Wang, X., Wan, P., Liu, Z.: Simulating the vi- sual world with artificial intelligence: A roadmap. arXiv preprint arXiv:2511.08585 (2025)
-
[52]
In: Proceedings of the 33rd ACM International Confer- ence on Multimedia
Zhang, S., Hao, X., Tang, Y., Zhang, L., Wang, P., Wang, Z., Ma, H., Zhang, S.: Video-cot: A comprehensive dataset for spatiotemporal understanding of videos based on chain-of-thought. In: Proceedings of the 33rd ACM International Confer- ence on Multimedia. pp. 12745–12752 (2025)
2025
-
[53]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Zhang, Y., Chew, Y., Dong, Y., Leo, A., Hu, B., Liu, Z.: Towards video thinking test: A holistic benchmark for advanced video reasoning and understanding. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 20626–20636 (2025)
2025
-
[54]
LLaVA-Video: Video Instruction Tuning With Synthetic Data
Zhang, Y., Wu, J., Li, W., Li, B., Ma, Z., Liu, Z., Li, C.: Llava-video: Video instruction tuning with synthetic data. arXiv preprint arXiv:2410.02713 (2024)
work page internal anchor Pith review arXiv 2024
-
[55]
Zhao, S., Zhang, X., Guo, J., Hu, J., Duan, L., Fu, M., Chng, Y.X., Wang, G.H., Chen, Q.G., Xu, Z., et al.: Unified multimodal understanding and generation models: Advances, challenges, and opportunities. arXiv preprint arXiv:2505.02567 (2025)
-
[56]
Zhong, H., Zhu, M., Du, Z., Huang, Z., Zhao, C., Liu, M., Wang, W., Chen, H., Shen, C.: Omni-r1: Reinforcement learning for omnimodal reasoning via two- system collaboration. arXiv preprint arXiv:2505.20256 (2025)
-
[57]
arXiv preprint arXiv:2504.21277 , year=
Zhou, G., Qiu, P., Chen, C., Wang, J., Yang, Z., Xu, J., Qiu, M.: Reinforced mllm: A survey on rl-based reasoning in multimodal large language models. arXiv preprint arXiv:2504.21277 (2025)
-
[58]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Zhou, J., Shu, Y., Zhao, B., Wu, B., Liang, Z., Xiao, S., Qin, M., Yang, X., Xiong, Y., Zhang, B., et al.: Mlvu: Benchmarking multi-task long video understanding. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 13691–13701 (2025)
2025
-
[59]
In: Proceedings of the AAAI conference on artificial intelligence
Zhou, L., Xu, C., Corso, J.: Towards automatic learning of procedures from web in- structional videos. In: Proceedings of the AAAI conference on artificial intelligence. vol. 32 (2018)
2018
-
[60]
Zhou, Z., Wang, R., Wu, Z.: Daily-omni: Towards audio-visual reasoning with temporal alignment across modalities. arXiv preprint arXiv:2505.17862 (2025)
-
[61]
Zhu, Q., Guo, D., Shao, Z., Yang, D., Wang, P., Xu, R., Wu, Y., Li, Y., Gao, H., Ma, S., et al.: Deepseek-coder-v2: Breaking the barrier of closed-source models in code intelligence. arXiv preprint arXiv:2406.11931 (2024) OmniJigsaw: Modality-Orchestrated Reordering 19 A Appendix Overview.The appendix is organized as follows: ▶Section A.1: Uni-Modal Jigsa...
-
[62]
The individual moves around the space, gesturing expressively while singing
The video features a person singing into a microphone in what appears to be a temple-like setting. The individual moves around the space, gesturing expressively while singing. The background remains consistent throughout, showcasing golden statues and ornate decorations, which suggests a single location with no significant environmental changes
-
[63]
- Visual State Changes: There are no significant visual state changes; the setting and background remain constant
The Evaluation Criteria: - Causal Progression: The person's actions (singing and gesturing) are continuous and directed towards the microphone, indicating a logical sequence. - Visual State Changes: There are no significant visual state changes; the setting and background remain constant. - Logical Narrative: The person's movements and gestures suggest a ...
-
[64]
- Static/Low-Dynamic Content: While the background is static, the person's dynamic movements and expressions add dynamism to the scene
The Exclusion Criteria: - Repetitive Loops: The person does not perform repetitive actions; their movements are varied and expressive. - Static/Low-Dynamic Content: While the background is static, the person's dynamic movements and expressions add dynamism to the scene. - Parallel/Unrelated Clips: The video is a single, continuous shot with no unrelated h...
-
[65]
For example, the man is first seen reading outdoors, then in a bathtub surrounded by books, and later in a room filled with books and artwork
Causal Progression: The video does not follow a single, continuous causal progression but rather jumps between different activities and settings. For example, the man is first seen reading outdoors, then in a bathtub surrounded by books, and later in a room filled with books and artwork. Each scene change is abrupt and does not logically follow the previous one
-
[66]
Visual State Changes: There are clear visual state changes, such as
-
[67]
The transitions between scenes do not provide a clear sequence of events that build upon each other
Logical Narrative: The video lacks a coherent narrative flow. The transitions between scenes do not provide a clear sequence of events that build upon each other. Instead, they seem to be standalone clips that could be rearranged without losing their meaning
-
[68]
Temporal Markers: There are no significant temporal markers such as time-lapse photography, changes in lighting, or physical wear on objects that would indicate a passage of time or a sequence of events
-
[69]
Repetitive Loops: The video does not contain repetitive loops
-
[70]
Static/Low-Dynamic Content: While the video includes some dynamic elements like the man's gestures and the changing settings
-
[71]
The lack of a clear narrative thread suggests that these clips could be rearranged without losing their individual meanings
Parallel/Unrelated Clips: The video appears to be a compilation of unrelated clips, each capturing a different moment or activity. The lack of a clear narrative thread suggests that these clips could be rearranged without losing their individual meanings
-
[72]
Visual Ambiguity: The visual content is somewhat ambiguous due to the abrupt transitions and lack of a clear sequence. The different settings and activities do not provide enough context to infer a logical order. </think> <answer> NO </answer> Input: Output: Fig.9: Case 2: Disjointed Narrative. 30 Jia et al. in a low-level signal sense, it still lacks a d...
-
[73]
Briefly describe the key actions and state changes observed
-
[74]
Evaluate against the Evaluation and Exclusion criteria
-
[75]
Video Jigsaw
Conclude whether the video is suitable for the “Video Jigsaw” task. </think> <answer>YES or NO</answer> OmniJigsaw: Modality-Orchestrated Reordering 35 A.5.2 Training Prompts In practice, since Qwen3-Omni-30B-A3B-Instruct [42] does not reliably out- put<think>during generation, likely due to the tokenizer behavior or pre- training treatment associated wit...
-
[77]
Temporal Jigsaw Puzzle
Based on this content-driven analysis, reassemble the original video and output the indices in correct order, separated by commas. Answer format example: 2, 3, 1, 4, 6, 5 YouFIRSTthink about the reasoning process as an internal monologue andTHENpro- vide the final answer.Ensure your reasoning is strictly based on audio-visual facts and follows a logical p...
-
[78]
Evaluate Visual Suitability (For Video Jigsaw): *Look for:Clear physical actions (e.g., pouring water), scene transitions, camera move- ment, or object state changes (e.g., assembling a puzzle). *Penalty:Give low priority to “V” if the video is static (e.g., a person sitting still with minimal movement), repetitive (loops), mostly black/blurry, or shows m...
-
[79]
*Penalty:Give low priority to “A” if the audio is constant background noise, a repetitive music loop without progression, or silence
Evaluate Audio Suitability (For Audio Jigsaw): *Look for:Continuous Speech (e.g., narrative/dialogue with logical flow), Musical Pro- gression (e.g., verse -> chorus), or Sequential Sound Events (e.g., footsteps -> door open -> slam). *Penalty:Give low priority to “A” if the audio is constant background noise, a repetitive music loop without progression, ...
-
[80]
V”if the visual evolution provides a stricter, unambiguous timeline (e.g., a silent movie with clear plot actions). *Select “A
Comparison & Decision: *Select “V”if the visual evolution provides a stricter, unambiguous timeline (e.g., a silent movie with clear plot actions). *Select “A”if the auditory narrative provides the primary logical thread (e.g., a podcast, a speech, or a static shot of a narrator). *Tie-Breaker:If both are good, choose the one that requires less ambiguous ...
-
[81]
Analyze the temporal logic by comparing these features to determine how the story or action progresses from one segment to another
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.