Recognition: no theorem link
When to Trust Tools? Adaptive Tool Trust Calibration For Tool-Integrated Math Reasoning
Pith reviewed 2026-05-10 18:35 UTC · model grok-4.3
The pith
A calibration method based on code confidence helps models know when to trust tool results during math reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
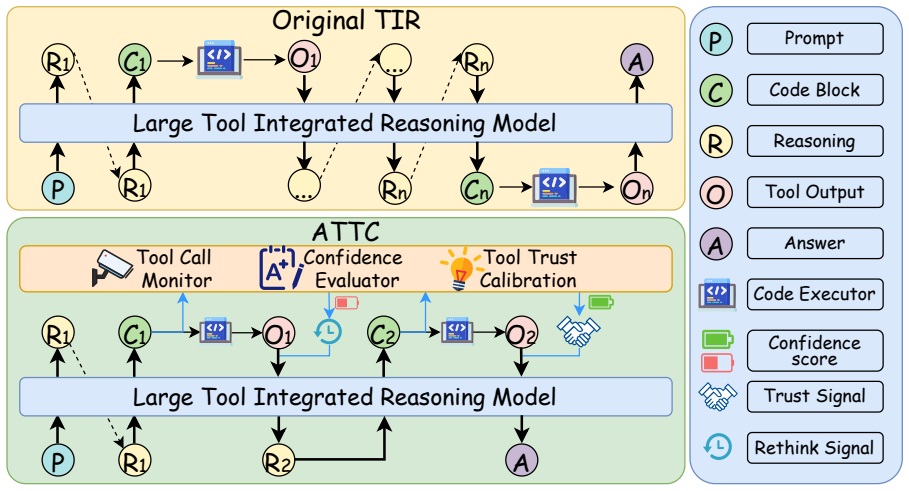
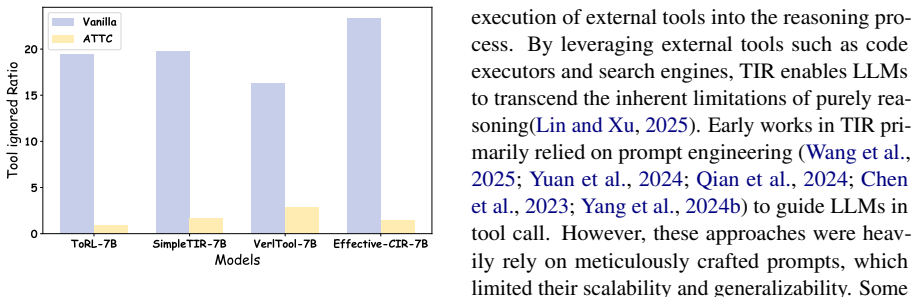
When reasoning models use tools for math, they frequently disregard accurate tool results in favor of their internal reasoning, creating the Tool Ignored problem. The authors propose Adaptive Tool Trust Calibration, a framework that lets the model adaptively trust or ignore tool results according to the confidence score assigned to its generated code blocks. Tests across different model sizes and multiple datasets show that this method cuts down on Tool Ignored cases and raises performance by 4.1 to 7.5 percent.
What carries the argument
The Adaptive Tool Trust Calibration (ATTC) framework, which uses confidence scores from generated code blocks to determine whether to trust tool execution results or the model's reasoning.
If this is right
- Models equipped with ATTC exhibit fewer cases of ignoring correct tool results.
- Accuracy on math reasoning benchmarks improves by 4.1% to 7.5%.
- The benefits hold for TIR models of varying sizes on several datasets.
- It enables better calibration of trust between model reasoning and external tools.
Where Pith is reading between the lines
- If confidence scores prove consistent, the method could extend to non-math tool uses like data analysis.
- Similar calibration techniques might use other model signals such as entropy or verification steps.
- Integrating this into training could create more reliable tool-using AI systems overall.
Load-bearing premise
The confidence score of the generated code blocks serves as a dependable indicator for choosing to trust the tool result over the model's reasoning.
What would settle it
A test set of problems where the tool provides the correct answer but the code confidence score leads the model to reject it, resulting in no performance gain or loss.
Figures












read the original abstract
Large reasoning models (LRMs) have achieved strong performance enhancement through scaling test time computation, but due to the inherent limitations of the underlying language models, they still have shortcomings in tasks that require precise computation and extensive knowledge reserves. Tool-Integrated Reasoning (TIR) has emerged as a promising paradigm that incorporates tool call and execution within the reasoning trajectory. Although recent works have released some powerful open-source TIR models, our analysis reveals that these models still suffer from critical deficiencies. We find that when the reasoning of the model conflicts with the tool results, the model tends to believe in its own reasoning. And there are cases where the tool results are correct but are ignored by the model, resulting in incorrect answers, which we define as "Tool Ignored''. This indicates that the model does not know when to trust or ignore the tool. To overcome these limitations, We introduce Adaptive Tool Trust Calibration (ATTC), a novel framework that guides the model to adaptively choose to trust or ignore the tool results based on the confidence score of generated code blocks. The experimental results from various open-source TIR models of different sizes and across multiple datasets demonstrate that ATTC effectively reduces the "Tool Ignored" issue, resulting in a performance increase of 4.1% to 7.5%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper identifies the 'Tool Ignored' problem in Tool-Integrated Reasoning (TIR) models for math tasks, where models favor their own reasoning over correct tool outputs. It introduces Adaptive Tool Trust Calibration (ATTC), a framework that uses confidence scores computed on generated code blocks to adaptively decide whether to trust or ignore tool results, and reports empirical performance gains of 4.1% to 7.5% across open-source TIR models of varying sizes and multiple datasets.
Significance. If the central claim holds, the work would be significant as a practical contribution to improving reliability in tool-augmented LLM reasoning. By providing a mechanism to calibrate trust when model reasoning conflicts with tool outputs, ATTC addresses a recurring failure mode in TIR for precise computation tasks, with the reported gains indicating potential applicability to existing open-source models without requiring retraining.
major comments (2)
- [Abstract] Abstract: the claim of 4.1%–7.5% performance gains is presented without any description of the confidence-score computation procedure, the exact baselines, the definition or measurement of 'Tool Ignored' cases, or statistical significance testing; these details are load-bearing for evaluating whether ATTC provides a reliable, non-circular signal.
- [Method] Method section (inferred from framework description): the paper does not specify how the confidence score is derived from generated code blocks (e.g., token probabilities, self-consistency, or external verifier) or how it is thresholded to override tool results, leaving open the possibility that the decision rule is circular or post-hoc fitted.
minor comments (1)
- [Introduction] The introduction could include a concrete example of a 'Tool Ignored' case with model output, tool result, and final answer to make the problem statement more precise.
Simulated Author's Rebuttal
Thank you for the referee's constructive feedback on our work. We address each major comment point by point below, clarifying aspects of ATTC and committing to revisions where the manuscript can be strengthened for clarity.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of 4.1%–7.5% performance gains is presented without any description of the confidence-score computation procedure, the exact baselines, the definition or measurement of 'Tool Ignored' cases, or statistical significance testing; these details are load-bearing for evaluating whether ATTC provides a reliable, non-circular signal.
Authors: We agree the abstract is concise and omits key procedural details. In the full manuscript, 'Tool Ignored' is defined in Section 3 as cases where the model disregards correct tool outputs in favor of its own (incorrect) reasoning, quantified by comparing model answers against ground truth with tool execution enabled. Baselines are unmodified open-source TIR models. Confidence scores and thresholding appear in Section 4, with statistical significance via paired t-tests reported in Table 2. We will revise the abstract to briefly reference these elements without exceeding length limits. revision: yes
-
Referee: [Method] Method section (inferred from framework description): the paper does not specify how the confidence score is derived from generated code blocks (e.g., token probabilities, self-consistency, or external verifier) or how it is thresholded to override tool results, leaving open the possibility that the decision rule is circular or post-hoc fitted.
Authors: The confidence score is the average per-token probability extracted from the model's logits over the generated code block (detailed in Section 4.1). Thresholding uses a validation-set grid search to select the cutoff that maximizes downstream accuracy, applied only at inference time on held-out test data. This is non-circular because the score is an intrinsic model output and the threshold is fixed prior to evaluation. We will expand the Method section with explicit equations, pseudocode for the trust decision, and an ablation confirming the threshold is not fitted on test data. revision: yes
Circularity Check
Empirical framework with no derivation chain
full rationale
The paper presents an empirical method (ATTC) that uses confidence scores on generated code blocks to decide tool trust in TIR models, evaluated via experiments on open-source models and math datasets showing 4.1-7.5% gains. No equations, first-principles derivations, fitted parameters renamed as predictions, or self-citation load-bearing steps appear in the provided text or abstract. The central claim rests on observable performance improvements rather than any reduction to inputs by construction, making the work self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2505.24480 , year=
To- wards effective code-integrated reasoning.Preprint, arXiv:2505.24480. Sijia Chen, Yibo Wang, Yi-Feng Wu, Qing-Guo Chen, Zhao Xu, Weihua Luo, Kaifu Zhang, and Lijun Zhang
-
[2]
Wenhu Chen, Xueguang Ma, Xinyi Wang, and William W
Advancing tool-augmented large lan- guage models: Integrating insights from errors in inference trees.Preprint, arXiv:2406.07115. Wenhu Chen, Xueguang Ma, Xinyi Wang, and William W. Cohen
-
[3]
Program of thoughts prompting: Disentangling computation from rea- soning for numerical reasoning tasks.Preprint, arXiv:2211.12588. Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Mar- cel Blistein, Ori Ram, Dan Zhang, Evan Rosen, and 1 others
work page internal anchor Pith review arXiv
-
[4]
Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.Preprint, arXiv:2507.06261. DeepSeek-AI, Daya Guo, Dejian Yang, Haowei Zhang, Jun-Mei Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiaoling Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, Z. F. Wu, Zhibin Gou, Zhihong ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
ReTool: Reinforcement Learning for Strategic Tool Use in LLMs
Retool: Reinforce- ment learning for strategic tool use in llms.Preprint, arXiv:2504.11536. Zhibin Gou, Zhihong Shao, Yeyun Gong, Yelong Shen, Yujiu Yang, Minlie Huang, Nan Duan, and Weizhu Chen
work page internal anchor Pith review arXiv
-
[6]
Tora: A tool-integrated reasoning agent for mathematical problem solving
Tora: A tool-integrated reasoning agent for mathematical problem solving.Preprint, arXiv:2309.17452. Chaoqun He, Renjie Luo, Yuzhuo Bai, Shengding Hu, Zhen Leng Thai, Junhao Shen, Jinyi Hu, Xu Han, Yu- jie Huang, Yuxiang Zhang, Jie Liu, Lei Qi, Zhiyuan Liu, and Maosong Sun
-
[7]
Olympiadbench: A challenging benchmark for promoting agi with olympiad-level bilingual multimodal scientific prob- lems.Preprint, arXiv:2402.14008. Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt
work page internal anchor Pith review arXiv
-
[8]
Measuring Mathematical Problem Solving With the MATH Dataset
Measuring mathematical problem solving with the math dataset.Preprint, arXiv:2103.03874. Yixin Ji, Juntao Li, Yang Xiang, Hai Ye, Kaixin Wu, Kai Yao, Jia Xu, Linjian Mo, and Min Zhang
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
arXiv preprint arXiv:2501.02497 , year=
A survey of test-time compute: From intuitive inference to deliberate reasoning.Preprint, arXiv:2501.02497. Dongfu Jiang, Yi Lu, Zhuofeng Li, Zhiheng Lyu, Ping Nie, Haozhe Wang, Alex Su, Hui Chen, Kai Zou, Chao Du, Tianyu Pang, and Wenhu Chen
-
[10]
Verl- tool: Towards holistic agentic reinforcement learning with tool use.Preprint, arXiv:2509.01055. Aitor Lewkowycz, Anders Andreassen, David Dohan, Ethan Dyer, Henryk Michalewski, Vinay Ramasesh, Ambrose Slone, Cem Anil, Imanol Schlag, Theo Gutman-Solo, Yuhuai Wu, Behnam Neyshabur, Guy Gur-Ari, and Vedant Misra
-
[11]
Solving Quantitative Reasoning Problems with Language Models
Solving quan- titative reasoning problems with language models. Preprint, arXiv:2206.14858. Xuefeng Li, Haoyang Zou, and Pengfei Liu
work page internal anchor Pith review arXiv
-
[12]
Torl: Scaling tool-integrated rl, 2025 b
Torl: Scaling tool-integrated rl.Preprint, arXiv:2503.23383. Minpeng Liao, Wei Luo, Chengxi Li, Jing Wu, and Kai Fan
-
[13]
arXiv preprint arXiv:2401.08190
Mario: Math reasoning with code interpreter output – a reproducible pipeline.Preprint, arXiv:2401.08190. Heng Lin and Zhongwen Xu
-
[14]
arXiv preprint arXiv:2508.19201 , year=
Understanding tool- integrated reasoning.Preprint, arXiv:2508.19201. Zichen Liu, Changyu Chen, Wenjun Li, Penghui Qi, Tianyu Pang, Chao Du, Wee Sun Lee, and Min Lin
-
[15]
Understanding r1-zero-like training: A critical perspective.Preprint, arXiv:2503.20783. OpenAI, :, Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, Alex Carney, Alex Iftimie, Alex Karpenko, Alex Tachard Passos, Alexander Neitz, Alexander Prokofiev, Alexander Wei, Allison Tam, and...
-
[16]
Openai o1 system card.Preprint, arXiv:2412.16720. Cheng Qian, Emre Can Acikgoz, Hongru Wang, Xiusi Chen, Avirup Sil, Dilek Hakkani-Tür, Gokhan Tur, and Heng Ji
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
SMART: Self-aware agent for tool overuse mitigation.arXiv preprint arXiv:2502.11435, 2025
Smart: Self-aware agent for tool overuse mitigation.Preprint, arXiv:2502.11435. Cheng Qian, Shihao Liang, Yujia Qin, Yining Ye, Xin Cong, Yankai Lin, Yesai Wu, Zhiyuan Liu, and Maosong Sun
-
[18]
Investigate-consolidate-exploit: A general strategy for inter-task agent self-evolution. Preprint, arXiv:2401.13996. Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom
-
[19]
Toolformer: Language Models Can Teach Themselves to Use Tools
Toolformer: Language models can teach themselves to use tools. Preprint, arXiv:2302.04761. Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y . K. Li, Y . Wu, and Daya Guo
work page internal anchor Pith review arXiv
-
[20]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Deepseekmath: Pushing the limits of mathemati- cal reasoning in open language models.Preprint, arXiv:2402.03300. Xiaoyu Tan, Tianchu Yao, Chao Qu, Bin Li, Minghao Yang, Dakuan Lu, Haozhe Wang, Xihe Qiu, Wei Chu, Yinghui Xu, and Yuan Qi
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Aurora:automated training framework of universal process reward mod- els via ensemble prompting and reverse verification. Preprint, arXiv:2502.11520. Kimi Team, Angang Du, Bofei Gao, Bowei Xing, Changjiu Jiang, Cheng Chen, Cheng Li, Chenjun Xiao, Chenzhuang Du, Chonghua Liao, Chuning Tang, Congcong Wang, Dehao Zhang, Enming Yuan, Enzhe Lu, Feng Tang, Floo...
-
[22]
Kimi k1.5: Scaling Reinforcement Learning with LLMs
Kimi k1.5: Scaling reinforcement learning with llms.ArXiv, abs/2501.12599. Hongru Wang, Boyang Xue, Baohang Zhou, Tianhua Zhang, Cunxiang Wang, Huimin Wang, Guanhua Chen, and Kam fai Wong
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Self-dc: When to reason and when to act? self divide-and-conquer for compositional unknown questions
Self-dc: When to reason and when to act? self divide-and-conquer for compositional unknown questions.Preprint, arXiv:2402.13514. Ke Wang, Houxing Ren, Aojun Zhou, Zimu Lu, Sichun Luo, Weikang Shi, Renrui Zhang, Linqi Song, Mingjie Zhan, and Hongsheng Li
-
[24]
Zhenghai Xue, Longtao Zheng, Qian Liu, Yingru Li, Xiaosen Zheng, Zejun Ma, and Bo An
Mathcoder: Seamless code integration in llms for enhanced math- ematical reasoning.Preprint, arXiv:2310.03731. Zhenghai Xue, Longtao Zheng, Qian Liu, Yingru Li, Xiaosen Zheng, Zejun Ma, and Bo An
-
[25]
Simpletir: End-to-end reinforcement learning for multi-turn tool-integrated reasoning.Preprint, arXiv:2509.02479. An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Day- iheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, and 41 others
-
[26]
Qwen3 technical report.Preprint, arXiv:2505.09388. An Yang, Beichen Zhang, Binyuan Hui, Bofei Gao, Bowen Yu, Chengpeng Li, Dayiheng Liu, Jian- hong Tu, Jingren Zhou, Junyang Lin, Keming Lu, Mingfeng Xue, Runji Lin, Tianyu Liu, Xingzhang Ren, and Zhenru Zhang. 2024a. Qwen2.5-math tech- nical report: Toward mathematical expert model via self-improvement.Pre...
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
React: Synergizing reasoning and acting in language models.Preprint, arXiv:2210.03629. Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, Xin Liu, Haibin Lin, Zhiqi Lin, Bole Ma, Guangming Sheng, Yuxuan Tong, Chi Zhang, Mofan Zhang, Wang Zhang, and 16 others. 2025a. Dapo: An open-sour...
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
Craft: Customiz- ing llms by creating and retrieving from specialized toolsets.Preprint, arXiv:2309.17428. Yang Yue, Zhiqi Chen, Rui Lu, Andrew Zhao, Zhaokai Wang, Yang Yue, Shiji Song, and Gao Huang
-
[29]
Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?
Does reinforcement learning really incentivize rea- soning capacity in llms beyond the base model? Preprint, arXiv:2504.13837. Weihao Zeng, Yuzhen Huang, Qian Liu, Wei Liu, Ke- qing He, Zejun Ma, and Junxian He
work page internal anchor Pith review arXiv
-
[30]
Simplerl- zoo: Investigating and taming zero reinforcement learning for open base models in the wild.Preprint, arXiv:2503.18892. Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang, Junjie Zhang, Zican Dong, Yifan Du, Chen Yang, Yushuo Chen, Zhipeng Chen, Jinhao Jiang, Ruiyang Ren, Yifan Li, Xinyu Tang, Z...
work page internal anchor Pith review arXiv
-
[31]
A Survey of Large Language Models
A survey of large language models. Preprint, arXiv:2303.18223. A The Use of Large Language Models We use large language models to assist in analyz- ing the reasoning trajectories of a large number of TIR models. A large language model was used in writing this manuscript to assist with proofreading and improve the clarity of the text. All knowledge content...
work page internal anchor Pith review arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.