Recognition: 2 theorem links
· Lean TheoremTowards Identification and Intervention of Safety-Critical Parameters in Large Language Models
Pith reviewed 2026-05-10 17:53 UTC · model grok-4.3
The pith
Expected Safety Impact scores pinpoint which parameters control safety in LLMs, allowing updates to just 1 percent of weights that cut attack success rates by more than half while preserving performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
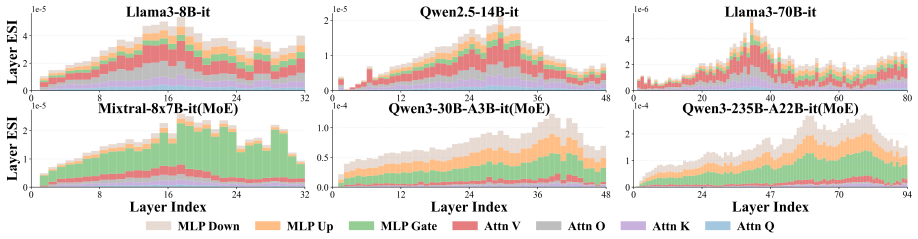
The Expected Safety Impact framework quantifies each parameter's contribution to safety by estimating the change in safety-related outputs when that parameter is perturbed. Safety-critical parameters concentrate in the value projection matrices and middle-layer MLPs of dense models but move to late-layer MLPs in MoE models. Safety Enhancement Tuning updates only the highest-ranked parameters to align unsafe models, while Safety Preserving Adaptation freezes those same parameters during instruction fine-tuning to limit safety loss.
What carries the argument
The Expected Safety Impact (ESI) score, which ranks parameters according to their estimated effect on the model's safety performance across a set of evaluation prompts.
If this is right
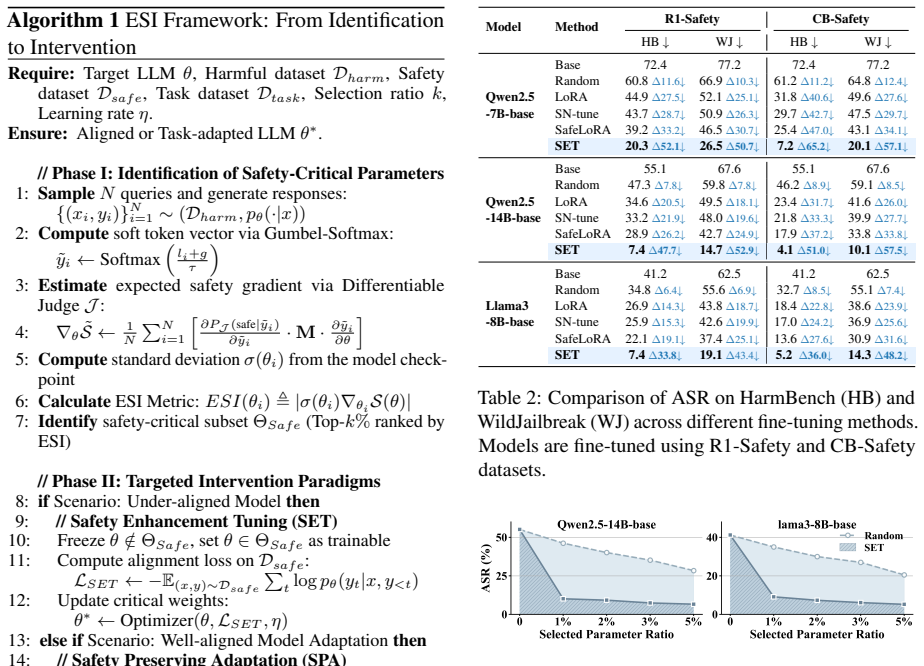
- Updating roughly 1 percent of model weights via SET reduces attack success rates of unaligned LLMs by over 50 percent after 100 iterations.
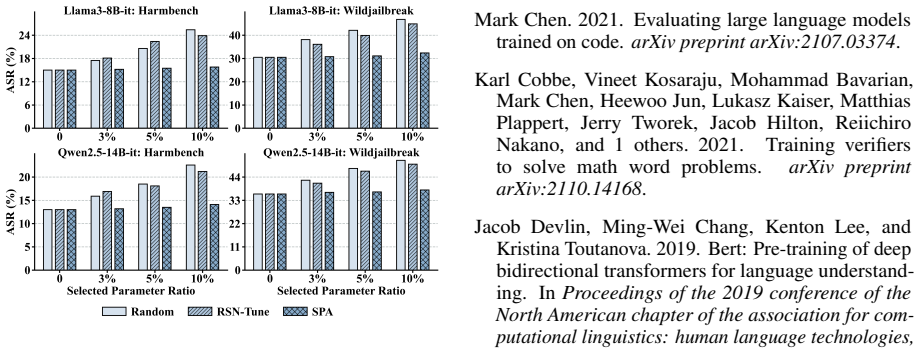
- SPA keeps safety degradation below 1 percent even after 1,000 iterations of instruction fine-tuning on new tasks.
- Safety-critical parameters cluster in middle-layer value matrices and MLPs for dense architectures but shift to late-layer MLPs for MoE models.
- Both methods maintain the model's original performance on non-safety tasks while changing only the targeted safety behavior.
Where Pith is reading between the lines
- If the ESI locations prove stable across model scales, safety modules could be extracted and reused when building new models.
- The same scoring approach might extend to identifying parameters for other behaviors such as factual accuracy or refusal of harmful requests.
- Testing whether freezing ESI parameters also protects against jailbreaks introduced by later fine-tuning would be a direct next check.
- Combining SET for initial alignment with SPA for ongoing adaptation could support lifelong safe model updates without repeated full retraining.
Load-bearing premise
The ESI score identifies parameters that causally drive safety behavior rather than merely correlating with it, and that selective updates will not create new unintended failure modes.
What would settle it
An experiment that updates the top ESI-ranked parameters yet observes no reduction in attack success rate, or that leaves those parameters untouched yet still sees safety improve or degrade substantially.
Figures



read the original abstract
Ensuring Large Language Model (LLM) safety is crucial, yet the lack of a clear understanding about safety mechanisms hinders the development of precise and reliable methodologies for safety intervention across diverse tasks. To better understand and control LLM safety, we propose the Expected Safety Impact (ESI) framework for quantifying how different parameters affect LLM safety. Based on ESI, we reveal distinct safety-critical patterns across different LLM architectures: In dense LLMs, many safety-critical parameters are located in value matrices (V) and MLPs in middle layers, whereas in Mixture-of-Experts (MoE) models, they shift to the late-layer MLPs. Leveraging ESI, we further introduce two targeted intervention paradigms for safety enhancement and preservation, i.e., Safety Enhancement Tuning (SET) and Safety Preserving Adaptation (SPA). SET can align unsafe LLMs by updating only a few safety-critical parameters, effectively enhancing safety while preserving original performance. SPA safeguards well-aligned LLMs during capability-oriented intervention (e.g., instruction tuning) by preventing disruption of safety-critical weights, allowing the LLM to acquire new abilities and maintain safety capabilities. Extensive evaluations on different LLMs demonstrate that SET can reduce the attack success rates of unaligned LLMs by over 50% with only a 100-iteration update on 1% of model weights. SPA can limit the safety degradation of aligned LLMs within 1% after a 1,000-iteration instruction fine-tuning on different tasks. Our code is available at: https://github.com/ZJU-LLM-Safety/SafeWeights-ACL.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Expected Safety Impact (ESI) framework to quantify how individual parameters influence LLM safety. It identifies architecture-specific patterns (safety-critical parameters concentrated in V-projections and middle-layer MLPs for dense models; late-layer MLPs for MoE models). Building on ESI, it proposes Safety Enhancement Tuning (SET) to align unaligned models via 100-iteration updates to 1% of weights (claiming >50% ASR reduction) and Safety Preserving Adaptation (SPA) to limit safety degradation to <1% during 1000-iteration instruction fine-tuning on aligned models. Code is released at https://github.com/ZJU-LLM-Safety/SafeWeights-ACL.
Significance. If ESI-guided interventions prove robust and causal, the work would advance parameter-efficient safety methods for LLMs, offering practical tools for both alignment and alignment preservation without full retraining. The dense-vs-MoE pattern analysis could inform architecture-aware safety research. Code release aids reproducibility, a positive factor for empirical claims in this area.
major comments (2)
- Abstract and Results: The headline claims (>50% ASR reduction via SET on 1% weights; <1% degradation via SPA) are presented without baselines, control conditions, statistical tests, or details on model count/variance. This undermines assessment of whether gains are due to ESI targeting or generic tuning effects.
- ESI definition and intervention sections (methods/results): ESI is described as quantifying parameter safety impact, but no causal validation is provided (e.g., ablation on non-ESI parameters, do-no-harm tests on unrelated tasks, or checks for new failure modes post-update). Selective updates may induce compensatory changes elsewhere in the network rather than true causal control, which is load-bearing for both SET and SPA claims.
minor comments (3)
- Clarify the precise ESI computation formula, including any gradient/activation details, prompt sets, and hyperparameters.
- Add quantitative support (e.g., layer-wise ESI distributions or percentages) for the claimed dense vs. MoE safety-critical patterns.
- Define acronyms at first use (e.g., ASR, SET, SPA) and ensure figure/table captions are self-contained.
Simulated Author's Rebuttal
Thank you for the constructive review and for highlighting areas where the empirical presentation and causal validation can be strengthened. We address each major comment point by point below, agreeing where revisions are warranted.
read point-by-point responses
-
Referee: Abstract and Results: The headline claims (>50% ASR reduction via SET on 1% weights; <1% degradation via SPA) are presented without baselines, control conditions, statistical tests, or details on model count/variance. This undermines assessment of whether gains are due to ESI targeting or generic tuning effects.
Authors: We agree that the abstract presents the headline numbers concisely without explicit reference to controls or statistics, which can make it harder to immediately assess specificity. The full manuscript does include comparisons of ESI-guided updates against random parameter selection (and against full fine-tuning) in the experimental sections, with results aggregated across multiple dense and MoE models and reported with variance. To directly address the concern, we will revise the abstract to briefly note the control conditions and add explicit statistical tests (e.g., significance markers) plus model-count details to the results summary in the revised version. This will more clearly distinguish ESI-driven gains from generic tuning effects. revision: yes
-
Referee: ESI definition and intervention sections (methods/results): ESI is described as quantifying parameter safety impact, but no causal validation is provided (e.g., ablation on non-ESI parameters, do-no-harm tests on unrelated tasks, or checks for new failure modes post-update). Selective updates may induce compensatory changes elsewhere in the network rather than true causal control, which is load-bearing for both SET and SPA claims.
Authors: The referee correctly identifies that stronger causal evidence would bolster the claims. While the manuscript already shows that ESI-selected parameters outperform random selection on the safety metrics (providing initial evidence of specificity), we did not include dedicated do-no-harm evaluations on a broad set of unrelated tasks or explicit checks for compensatory weight changes in non-updated parameters. We will add these in the revision: (1) ablations comparing ESI vs. non-ESI parameters on additional general-capability benchmarks, (2) monitoring for new failure modes after intervention, and (3) analysis of weight dynamics outside the selected subset. These additions will help substantiate that the observed safety changes are causally tied to the targeted parameters rather than indirect network effects. revision: yes
Circularity Check
No circularity: empirical definition of ESI and direct intervention tests are self-contained.
full rationale
The paper introduces ESI as a quantification of parameter effects on safety, computed from observed changes, then applies it to identify patterns and perform targeted updates (SET, SPA) whose outcomes are measured in experiments (e.g., ASR reduction after 100 iterations on 1% weights). No equations reduce a claimed result to its own inputs by construction, no fitted parameter is relabeled as a prediction, and no load-bearing self-citation chain is invoked. The derivation chain consists of empirical measurement followed by intervention testing, remaining independent of the reported metrics.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard machine-learning assumption that gradient-based updates on selected parameters can isolate behavioral changes.
invented entities (1)
-
Expected Safety Impact (ESI)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
ESI(θi) ≜ |σ(θi) ∇θi S(θ)| ... ΔS(θ) ≈ ∇θ S(θ)^T Δθ ... first-order Taylor expansion
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
safety-critical patterns ... middle-layer value matrices (V) and MLPs ... late-layer MLPs in MoE
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, and Yuxiong He
Direct preference optimization: Your language model is secretly a reward model.Advances in neural information processing systems, 36:53728–53741. Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, and Yuxiong He. 2020. Zero: Memory optimizations toward training trillion parameter models. InSC20: International Conference for High Performance Com- puting, Ne...
2020
-
[2]
Kui Ren, Tianhang Zheng, Zhan Qin, and Xue Liu
IEEE. Kui Ren, Tianhang Zheng, Zhan Qin, and Xue Liu. 2020. Adversarial attacks and defenses in deep learning. Engineering, 6(3):346–360. Mingjie Sun, Zhuang Liu, Anna Bair, and J Zico Kolter
2020
-
[3]
Llama 2: Open Foundation and Fine-Tuned Chat Models
A simple and effective pruning approach for large language models. InThe Twelfth International Conference on Learning Representations. Hugo Touvron, Louis Martin, Kevin Stone, Peter Al- bert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, and 1 others. 2023. Llama 2: Open foun- dation and fine-tuned ch...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Jailbroken: How does llm safety training fail? Advances in Neural Information Processing Systems, 36:80079–80110. Boyi Wei, Kaixuan Huang, Yangsibo Huang, Tinghao Xie, Xiangyu Qi, Mengzhou Xia, Prateek Mittal, Mengdi Wang, and Peter Henderson. 2024. Assess- ing the brittleness of safety alignment via pruning and low-rank modifications. InProceedings of th...
-
[5]
GPTFUZZER: Red Teaming Large Language Models with Auto-Generated Jailbreak Prompts
Gptfuzzer: Red teaming large language mod- els with auto-generated jailbreak prompts.arXiv preprint arXiv:2309.10253. Yi Zeng, Hongpeng Lin, Jingwen Zhang, Diyi Yang, Ruoxi Jia, and Weiyan Shi. 2024. How johnny can persuade llms to jailbreak them: Rethinking persua- sion to challenge ai safety by humanizing llms. In Proceedings of the 62nd Annual Meeting ...
work page internal anchor Pith review arXiv 2024
-
[6]
embedding scores between the generated response and the ground truth in a 0-shot setting. B Additional Implementation Details and Results for Perturbation Analysis B.1 Experimental Setup To comprehensively verify the scalability and ro- bustness of the proposed ESI framework across a broader spectrum of model sizes and architec- tural designs, we extend o...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.