Recognition: no theorem link
DMax: Aggressive Parallel Decoding for dLLMs
Pith reviewed 2026-05-10 17:54 UTC · model grok-4.3
The pith
DMax lets diffusion language models decode many tokens at once by refining guesses in continuous embedding space instead of discrete jumps.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
DMax reformulates decoding in diffusion language models as progressive self-refinement from mask embeddings to token embeddings. On-Policy Uniform Training unifies masked and uniform diffusion so the model recovers clean tokens from both masked inputs and its own erroneous predictions. Soft Parallel Decoding then represents each state as an interpolation between the predicted token embedding and the mask embedding, allowing iterative self-revision in embedding space and higher parallelism.
What carries the argument
On-Policy Uniform Training paired with Soft Parallel Decoding, which trains recovery from both masks and self-errors and enables embedding-space interpolation for iterative correction.
If this is right
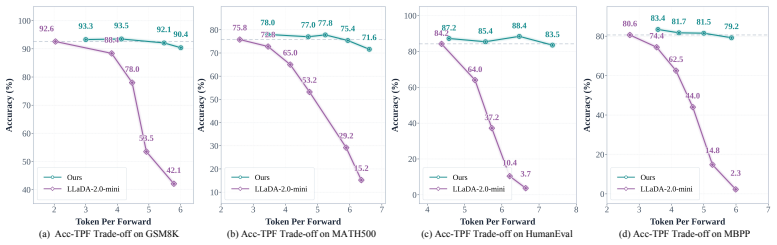
- Tokens per forward pass on GSM8K rises from 2.04 to 5.47 with accuracy preserved.
- Tokens per forward pass on MBPP rises from 2.71 to 5.86 with comparable performance.
- Average throughput reaches 1,338 tokens per second at batch size 1 on two H200 GPUs.
Where Pith is reading between the lines
- The same embedding-refinement idea could be tested on non-diffusion generative models to reduce sequential steps.
- Longer output sequences might benefit if early errors are corrected before they compound.
- Varying the interpolation schedule in Soft Parallel Decoding could be checked for further speed or quality gains.
Load-bearing premise
Progressive refinement in embedding space plus training on the model's own errors is enough to stop error buildup when many tokens are decoded together.
What would settle it
Measuring accuracy on GSM8K or MBPP when parallelism is raised past the reported levels and finding it falls below the original LLaDA-2.0-mini baseline.
Figures



read the original abstract
We present DMax, a new paradigm for efficient diffusion language models (dLLMs). It mitigates error accumulation in parallel decoding, enabling aggressive decoding parallelism while preserving generation quality. Unlike conventional masked dLLMs that decode through a binary mask-to-token transition, DMax reformulates decoding as a progressive self-refinement from mask embeddings to token embeddings. At the core of our approach is On-Policy Uniform Training, a novel training strategy that efficiently unifies masked and uniform dLLMs, equipping the model to recover clean tokens from both masked inputs and its own erroneous predictions. Building on this foundation, we further propose Soft Parallel Decoding. We represent each intermediate decoding state as an interpolation between the predicted token embedding and the mask embedding, enabling iterative self-revising in embedding space. Extensive experiments across a variety of benchmarks demonstrate the effectiveness of DMax. Compared with the original LLaDA-2.0-mini, our method improves TPF on GSM8K from 2.04 to 5.47 while preserving accuracy. On MBPP, it increases TPF from 2.71 to 5.86 while maintaining comparable performance. On two H200 GPUs, our model achieves an average of 1,338 TPS at batch size 1. Code is available at: https://github.com/czg1225/DMax
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DMax, a new paradigm for diffusion language models (dLLMs) that reformulates decoding as progressive self-refinement from mask embeddings to token embeddings. It proposes On-Policy Uniform Training to unify masked and uniform dLLMs for recovering from erroneous predictions, and Soft Parallel Decoding via embedding-space interpolation for iterative self-revision. The central empirical claim is that these techniques enable aggressive parallel decoding, improving tokens per forward pass (TPF) on GSM8K from 2.04 to 5.47 and on MBPP from 2.71 to 5.86 while preserving accuracy, with reported throughput of 1,338 TPS on two H200 GPUs.
Significance. If the empirical results hold under rigorous controls, DMax could meaningfully advance inference efficiency for dLLMs by addressing error accumulation in parallel decoding, potentially closing the gap with autoregressive models. Strengths include the linked code repository for reproducibility and the explicit focus on preserving generation quality alongside speed gains. The approach builds on existing dLLM ideas with targeted innovations in training and decoding.
major comments (2)
- [Experiments] Experiments section: the abstract and results report specific TPF gains (e.g., GSM8K 2.04→5.47) and accuracy preservation, but no details are provided on baseline LLaDA-2.0-mini re-implementation, number of evaluation runs, statistical significance tests, or hyperparameter selection procedures. This limits verification that the gains are robust and not due to post-hoc choices.
- [§3.2] §3.2 (On-Policy Uniform Training): the description of unifying masked and uniform dLLMs via on-policy training is central to mitigating error accumulation, but the manuscript does not include an ablation isolating its contribution versus standard masked training or the soft interpolation alone.
minor comments (3)
- [§3.1] The notation for mask embeddings versus token embeddings in the progressive refinement process could be clarified with a diagram or explicit equations in §3.1.
- Add a reference to prior work on diffusion-based parallel decoding (e.g., any related dLLM papers) to better situate the novelty of Soft Parallel Decoding.
- Figure captions for any throughput or TPF plots should explicitly state the batch size, hardware, and comparison baselines used.
Simulated Author's Rebuttal
We thank the referee for their thoughtful comments and suggestions. We have carefully considered each point and made revisions to the manuscript to address the concerns regarding experimental details and ablations. Below, we provide point-by-point responses.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the abstract and results report specific TPF gains (e.g., GSM8K 2.04→5.47) and accuracy preservation, but no details are provided on baseline LLaDA-2.0-mini re-implementation, number of evaluation runs, statistical significance tests, or hyperparameter selection procedures. This limits verification that the gains are robust and not due to post-hoc choices.
Authors: We agree that more details on the experimental setup are necessary to ensure reproducibility and robustness. In the revised manuscript, we have expanded the Experiments section to include: (1) a detailed description of the LLaDA-2.0-mini baseline re-implementation, which utilizes the publicly available model weights and adheres to the original training and inference configurations; (2) results are now reported as averages over 5 independent evaluation runs with different random seeds, along with standard deviations; (3) a note on statistical significance, where we performed paired t-tests to confirm the improvements are significant (p < 0.05); and (4) the hyperparameter selection procedure, which involved a grid search on a held-out validation set for key parameters such as the number of diffusion steps and interpolation factors. These additions should allow for better verification of the reported gains. revision: yes
-
Referee: [§3.2] §3.2 (On-Policy Uniform Training): the description of unifying masked and uniform dLLMs via on-policy training is central to mitigating error accumulation, but the manuscript does not include an ablation isolating its contribution versus standard masked training or the soft interpolation alone.
Authors: We appreciate this suggestion for strengthening the analysis. To isolate the contribution of On-Policy Uniform Training, we have added a new ablation study in the Experiments section (now Section 4.4). This study compares the full DMax model against variants: one using standard masked training without on-policy elements, and another without the soft embedding interpolation. The results demonstrate that On-Policy Uniform Training significantly improves the model's ability to recover from errors at high parallelism levels, contributing to the observed TPF gains while maintaining accuracy. We believe this addresses the concern about its central role. revision: yes
Circularity Check
No significant circularity
full rationale
The paper advances an empirical engineering method (progressive mask-to-token embedding refinement, On-Policy Uniform Training, and Soft Parallel Decoding) whose value is demonstrated solely through external benchmark measurements (TPF and accuracy on GSM8K/MBPP) and released code. No derivation, first-principles prediction, or fitted parameter is presented that reduces by construction to quantities defined inside the paper; the central claims rest on observable performance deltas against an external baseline (LLaDA-2.0-mini).
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Diffusion language models can be trained to recover clean tokens from both masked inputs and their own erroneous predictions
invented entities (2)
-
On-Policy Uniform Training
no independent evidence
-
Soft Parallel Decoding
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [2]
-
[3]
Marianne Arriola, Aaron Gokaslan, Justin T Chiu, Zhihan Yang, Zhixuan Qi, Jiaqi Han, Subham Sekhar Sahoo, and V olodymyr Kuleshov. Block diffusion: Interpolating between autoregressive and diffusion language models.arXiv preprint arXiv:2503.09573, 2025
-
[4]
Structured denoising diffusion models in discrete state-spaces.Advances in neural information processing systems, 34:17981–17993, 2021
Jacob Austin, Daniel D Johnson, Jonathan Ho, Daniel Tarlow, and Rianne Van Den Berg. Structured denoising diffusion models in discrete state-spaces.Advances in neural information processing systems, 34:17981–17993, 2021
2021
-
[5]
Program Synthesis with Large Language Models
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, et al. Program synthesis with large language models. arXiv preprint arXiv:2108.07732, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[6]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. Qwen technical report.arXiv preprint arXiv:2309.16609, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
Learning to parallel: Accelerating diffusion large language models via adaptive parallel decoding
Wenrui Bao, Zhiben Chen, Dan Xu, and Yuzhang Shang. Learning to parallel: Accelerating diffusion large language models via adaptive parallel decoding. InThe Fourteenth International Conference on Learning Representations, 2025
2025
-
[8]
Heli Ben-Hamu, Itai Gat, Daniel Severo, Niklas Nolte, and Brian Karrer. Accelerated sampling from masked diffusion models via entropy bounded unmasking.arXiv preprint arXiv:2505.24857, 2025
- [9]
-
[10]
Tiwei Bie, Maosong Cao, Kun Chen, Lun Du, Mingliang Gong, Zhuochen Gong, Yanmei Gu, Jiaqi Hu, Zenan Huang, Zhenzhong Lan, et al. Llada2. 0: Scaling up diffusion language models to 100b.arXiv preprint arXiv:2512.15745, 2025
work page internal anchor Pith review arXiv 2025
-
[11]
Medusa: Simple LLM Inference Acceleration Framework with Multiple Decoding Heads
Tianle Cai, Yuhong Li, Zhengyang Geng, Hongwu Peng, Jason D Lee, Deming Chen, and Tri Dao. Medusa: Simple llm inference acceleration framework with multiple decoding heads.arXiv preprint arXiv:2401.10774, 2024
work page internal anchor Pith review arXiv 2024
-
[12]
Dflash: Block diffusion for flash speculative decoding
Jian Chen, Yesheng Liang, and Zhijian Liu. Dflash: Block diffusion for flash speculative decoding.arXiv preprint arXiv:2602.06036, 2026
-
[13]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian...
2021
-
[14]
Shirui Chen, Jiantao Jiao, Lillian J Ratliff, and Banghua Zhu. dultra: Ultra-fast diffusion language models via reinforcement learning.arXiv preprint arXiv:2512.21446, 2025
-
[15]
DPad: Efficient Diffusion Language Models with Suffix Dropout, August 2025a
Xinhua Chen, Sitao Huang, Cong Guo, Chiyue Wei, Yintao He, Jianyi Zhang, Hai Li, Yiran Chen, et al. Dpad: Efficient diffusion language models with suffix dropout.arXiv preprint arXiv:2508.14148, 2025
-
[16]
dparallel: Learnable parallel decoding for dllms.arXiv preprint arXiv:2509.26488,
Zigeng Chen, Gongfan Fang, Xinyin Ma, Ruonan Yu, and Xinchao Wang. dparallel: Learnable parallel decoding for dllms.arXiv preprint arXiv:2509.26488, 2025. 11
-
[17]
Shuang Cheng, Yihan Bian, Dawei Liu, Linfeng Zhang, Qian Yao, Zhongbo Tian, Wenhai Wang, Qipeng Guo, Kai Chen, Biqing Qi, et al. Sdar: A synergistic diffusion-autoregression paradigm for scalable sequence generation.arXiv preprint arXiv:2510.06303, 2025
-
[18]
Shuang Cheng, Yuhua Jiang, Zineng Zhou, Dawei Liu, Wang Tao, Linfeng Zhang, Biqing Qi, and Bowen Zhou. Sdar-vl: Stable and efficient block-wise diffusion for vision-language understanding.arXiv preprint arXiv:2512.14068, 2025
-
[19]
Alexandros Christoforos and Chadbourne Davis. Moe-diffuseq: Enhancing long-document diffusion models with sparse attention and mixture of experts.arXiv preprint arXiv:2512.20604, 2025
-
[20]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[21]
Stable-diffcoder: Pushing the frontier of code diffusion large language model
Chenghao Fan, Wen Heng, Bo Li, Sichen Liu, Yuxuan Song, Jing Su, Xiaoye Qu, Kai Shen, and Wei Wei. Stable-diffcoder: Pushing the frontier of code diffusion large language model.arXiv preprint arXiv:2601.15892, 2026
-
[22]
dvoting: Fast voting for dllms.arXiv preprint arXiv:2602.12153, 2026
Sicheng Feng, Zigeng Chen, Xinyin Ma, Gongfan Fang, and Xinchao Wang. dvoting: Fast voting for dllms.arXiv preprint arXiv:2602.12153, 2026
-
[23]
Efficient-DLM: From Autoregressive to Diffusion Language Models, and Beyond in Speed
Yonggan Fu, Lexington Whalen, Zhifan Ye, Xin Dong, Shizhe Diao, Jingyu Liu, Chengyue Wu, Hao Zhang, Enze Xie, Song Han, et al. Efficient-dlm: From autoregressive to diffusion language models, and beyond in speed.arXiv preprint arXiv:2512.14067, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
Shansan Gong, Ruixiang Zhang, Huangjie Zheng, Jiatao Gu, Navdeep Jaitly, Lingpeng Kong, and Yizhe Zhang. Diffucoder: Understanding and improving masked diffusion models for code generation.arXiv preprint arXiv:2506.20639, 2025
-
[25]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models. arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
OpenThoughts: Data Recipes for Reasoning Models
Etash Guha, Ryan Marten, Sedrick Keh, Negin Raoof, Georgios Smyrnis, Hritik Bansal, Marianna Nezhurina, Jean Mercat, Trung Vu, Zayne Sprague, et al. Openthoughts: Data recipes for reasoning models.arXiv preprint arXiv:2506.04178, 2025
work page internal anchor Pith review arXiv 2025
-
[27]
Daehoon Gwak, Minseo Jung, Junwoo Park, Minho Park, ChaeHun Park, Junha Hyung, and Jaegul Choo. Reward-weighted sampling: Enhancing non-autoregressive characteristics in masked diffusion llms.arXiv preprint arXiv:2509.00707, 2025
-
[28]
Guangxin He, Shen Nie, Fengqi Zhu, Yuankang Zhao, Tianyi Bai, Ran Yan, Jie Fu, Chongxuan Li, and Binhang Yuan. Ultrallada: Scaling the context length to 128k for diffusion large language models.arXiv preprint arXiv:2510.10481, 2025
-
[29]
Measuring Mathematical Problem Solving With the MATH Dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset.arXiv preprint arXiv:2103.03874, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[30]
Soft-masked diffusion language models.arXiv preprint arXiv:2510.17206,
Michael Hersche, Samuel Moor-Smith, Thomas Hofmann, and Abbas Rahimi. Soft-masked diffusion language models.arXiv preprint arXiv:2510.17206, 2025
-
[31]
Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
2020
-
[32]
Feng Hong, Geng Yu, Yushi Ye, Haicheng Huang, Huangjie Zheng, Ya Zhang, Yanfeng Wang, and Jiangchao Yao. Wide-in, narrow-out: Revokable decoding for efficient and effective dllms.arXiv preprint arXiv:2507.18578, 2025
-
[33]
Yanzhe Hu, Yijie Jin, Pengfei Liu, Kai Yu, and Zhijie Deng. Lightningrl: Breaking the accuracy- parallelism trade-off of block-wise dllms via reinforcement learning.arXiv preprint arXiv:2603.13319, 2026
-
[34]
Mahoney, Sewon Min, Mehrdad Farajtabar, Kurt Keutzer, Amir Gholami, and Chenfeng Xu
Yuezhou Hu, Harman Singh, Monishwaran Maheswaran, Haocheng Xi, Coleman Hooper, Jintao Zhang, Aditya Tomar, Michael W Mahoney, Sewon Min, Mehrdad Farajtabar, et al. Residual context diffusion language models.arXiv preprint arXiv:2601.22954, 2026. 12
-
[35]
S., Seo, J.-s., Zhang, Z., and Gupta, U
Zhanqiu Hu, Jian Meng, Yash Akhauri, Mohamed S Abdelfattah, Jae-sun Seo, Zhiru Zhang, and Udit Gupta. Accelerating diffusion language model inference via efficient kv caching and guided diffusion. arXiv preprint arXiv:2505.21467, 2025
-
[36]
Jianuo Huang, Yaojie Zhang, Yicun Yang, Benhao Huang, Biqing Qi, Dongrui Liu, and Linfeng Zhang. Mask tokens as prophet: Fine-grained cache eviction for efficient dllm inference.arXiv preprint arXiv:2510.09309, 2025
-
[37]
Accelerating diffusion llms via adaptive parallel decoding.arXiv preprint arXiv:2506.00413, 2025
Daniel Israel, Guy Van den Broeck, and Aditya Grover. Accelerating diffusion llms via adaptive parallel decoding.arXiv preprint arXiv:2506.00413, 2025
-
[38]
Minseo Kim, Chenfeng Xu, Coleman Hooper, Harman Singh, Ben Athiwaratkun, Ce Zhang, Kurt Keutzer, and Amir Gholami. Cdlm: Consistency diffusion language models for faster sampling.arXiv preprint arXiv:2511.19269, 2025
-
[39]
Fast inference from transformers via speculative decoding
Yaniv Leviathan, Matan Kalman, and Yossi Matias. Fast inference from transformers via speculative decoding. InInternational Conference on Machine Learning, pages 19274–19286. PMLR, 2023
2023
-
[40]
Numinamath: The largest public dataset in ai4maths with 860k pairs of competition math problems and solutions.Hugging Face repository, 13(9):9, 2024
Jia Li, Edward Beeching, Lewis Tunstall, Ben Lipkin, Roman Soletskyi, Shengyi Huang, Kashif Rasul, Longhui Yu, Albert Q Jiang, Ziju Shen, et al. Numinamath: The largest public dataset in ai4maths with 860k pairs of competition math problems and solutions.Hugging Face repository, 13(9):9, 2024
2024
-
[41]
Beyond fixed: Variable-length denoising for diffusion large language models.arXiv e-prints, pages arXiv–2508, 2025
Jinsong Li, Xiaoyi Dong, Yuhang Zang, Yuhang Cao, Jiaqi Wang, and Dahua Lin. Beyond fixed: Variable-length denoising for diffusion large language models.arXiv e-prints, pages arXiv–2508, 2025
2025
-
[42]
A survey on diffusion language models.arXiv preprint arXiv:2508.10875, 2025
Tianyi Li, Mingda Chen, Bowei Guo, and Zhiqiang Shen. A survey on diffusion language models.arXiv preprint arXiv:2508.10875, 2025
-
[43]
EAGLE: Speculative Sampling Requires Rethinking Feature Uncertainty
Yuhui Li, Fangyun Wei, Chao Zhang, and Hongyang Zhang. Eagle: Speculative sampling requires rethinking feature uncertainty.arXiv preprint arXiv:2401.15077, 2024
work page internal anchor Pith review arXiv 2024
-
[44]
Let’s verify step by step
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. InThe Twelfth International Conference on Learning Representations, 2023
2023
-
[45]
Aiwei Liu, Minghua He, Shaoxun Zeng, Sijun Zhang, Linhao Zhang, Chuhan Wu, Wei Jia, Yuan Liu, Xiao Zhou, and Jie Zhou. Wedlm: Reconciling diffusion language models with standard causal attention for fast inference.arXiv preprint arXiv:2512.22737, 2025
-
[46]
Jingyu Liu, Xin Dong, Zhifan Ye, Rishabh Mehta, Yonggan Fu, Vartika Singh, Jan Kautz, Ce Zhang, and Pavlo Molchanov. Tidar: Think in diffusion, talk in autoregression.arXiv preprint arXiv:2511.08923, 2025
-
[47]
Longllada: Unlocking long context capabilities in diffusion llms
Xiaoran Liu, Yuerong Song, Zhigeng Liu, Zengfeng Huang, Qipeng Guo, Ziwei He, and Xipeng Qiu. Longllada: Unlocking long context capabilities in diffusion llms. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 32186–32194, 2026
2026
-
[48]
Yang Liu, Pengxiang Ding, Tengyue Jiang, Xudong Wang, Wenxuan Song, Minghui Lin, Han Zhao, Hongyin Zhang, Zifeng Zhuang, Wei Zhao, et al. Mmada-vla: Large diffusion vision-language-action model with unified multi-modal instruction and generation.arXiv preprint arXiv:2603.25406, 2026
-
[49]
Zhiyuan Liu, Yicun Yang, Yaojie Zhang, Junjie Chen, Chang Zou, Qingyuan Wei, Shaobo Wang, and Linfeng Zhang. dllm-cache: Accelerating diffusion large language models with adaptive caching.arXiv preprint arXiv:2506.06295, 2025
-
[50]
Lingkun Long, Yushi Huang, Shihao Bai, Ruihao Gong, Jun Zhang, Ao Zhou, and Jianlei Yang. Focus- dllm: Accelerating long-context diffusion llm inference via confidence-guided context focusing.arXiv preprint arXiv:2602.02159, 2026
-
[51]
Discrete diffusion language modeling by estimating the ratios of the data distribution
Aaron Lou, Chenlin Meng, and Stefano Ermon. Discrete diffusion language modeling by estimating the ratios of the data distribution. 2023
2023
-
[52]
Linrui Ma, Yufei Cui, Kai Han, and Yunhe Wang. Diffusion in diffusion: Breaking the autoregressive bottleneck in block diffusion models.arXiv preprint arXiv:2601.13599, 2026
-
[53]
dkv-cache: The cache for diffusion language models.arXiv preprint arXiv:2505.15781,
Xinyin Ma, Runpeng Yu, Gongfan Fang, and Xinchao Wang. dkv-cache: The cache for diffusion language models.arXiv preprint arXiv:2505.15781, 2025. 13
-
[54]
dinfer: An efficient inference framework for diffusion language models, 2025
Yuxin Ma, Lun Du, Lanning Wei, Kun Chen, Qian Xu, Kangyu Wang, Guofeng Feng, Guoshan Lu, Lin Liu, Xiaojing Qi, et al. dinfer: An efficient inference framework for diffusion language models.arXiv preprint arXiv:2510.08666, 2025
-
[55]
A diverse corpus for evaluating and developing english math word problem solvers, 2021
Shen-Yun Miao, Chao-Chun Liang, and Keh-Yih Su. A diverse corpus for evaluating and developing english math word problem solvers, 2021
2021
-
[56]
Diffusion language models are super data learners.arXiv preprint arXiv:2511.03276,
Jinjie Ni, Qian Liu, Longxu Dou, Chao Du, Zili Wang, Hang Yan, Tianyu Pang, and Michael Qizhe Shieh. Diffusion language models are super data learners.arXiv preprint arXiv:2511.03276, 2025
-
[57]
Zanlin Ni, Shenzhi Wang, Yang Yue, Tianyu Yu, Weilin Zhao, Yeguo Hua, Tianyi Chen, Jun Song, Cheng Yu, Bo Zheng, et al. The flexibility trap: Why arbitrary order limits reasoning potential in diffusion language models.arXiv preprint arXiv:2601.15165, 2026
-
[58]
Large Language Diffusion Models
Shen Nie, Fengqi Zhu, Zebin You, Xiaolu Zhang, Jingyang Ou, Jun Hu, Jun Zhou, Yankai Lin, Ji-Rong Wen, and Chongxuan Li. Large language diffusion models.arXiv preprint arXiv:2502.09992, 2025
work page internal anchor Pith review arXiv 2025
-
[59]
d-treerpo: Towards more reliable policy optimization for diffusion language models
Leyi Pan, Shuchang Tao, Yunpeng Zhai, Zheyu Fu, Liancheng Fang, Minghua He, Lingzhe Zhang, Zhaoyang Liu, Bolin Ding, Aiwei Liu, et al. d-treerpo: Towards more reliable policy optimization for diffusion language models.arXiv preprint arXiv:2512.09675, 2025
work page internal anchor Pith review arXiv 2025
-
[60]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas Müller, Joe Penna, and Robin Rombach. Sdxl: Improving latent diffusion models for high-resolution image synthesis.arXiv preprint arXiv:2307.01952, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[61]
Hierarchy decoding: A training-free parallel decoding strategy for diffusion large language models
Xiaojing Qi, Lun Du, Xinyuan Zhang, Lanning Wei, Tao Jin, and Da Zheng. Hierarchy decoding: A training-free parallel decoding strategy for diffusion large language models. InThe Fourteenth International Conference on Learning Representations
-
[62]
Yu-Yang Qian, Junda Su, Lanxiang Hu, Peiyuan Zhang, Zhijie Deng, Peng Zhao, and Hao Zhang. d3llm: Ultra-fast diffusion llm using pseudo-trajectory distillation.arXiv preprint arXiv:2601.07568, 2026
-
[63]
arXiv preprint arXiv:2510.08554 , year=
Kevin Rojas, Jiahe Lin, Kashif Rasul, Anderson Schneider, Yuriy Nevmyvaka, Molei Tao, and Wei Deng. Improving reasoning for diffusion language models via group diffusion policy optimization.arXiv preprint arXiv:2510.08554, 2025
-
[64]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022
2022
-
[65]
Dream- booth: Fine tuning text-to-image diffusion models for subject-driven generation
Nataniel Ruiz, Yuanzhen Li, Varun Jampani, Yael Pritch, Michael Rubinstein, and Kfir Aberman. Dream- booth: Fine tuning text-to-image diffusion models for subject-driven generation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 22500–22510, 2023
2023
-
[66]
Simple and effective masked diffusion language models.Advances in Neural Information Processing Systems, 37:130136–130184, 2024
Subham Sahoo, Marianne Arriola, Yair Schiff, Aaron Gokaslan, Edgar Marroquin, Justin Chiu, Alexander Rush, and V olodymyr Kuleshov. Simple and effective masked diffusion language models.Advances in Neural Information Processing Systems, 37:130136–130184, 2024
2024
-
[67]
The diffusion duality.arXiv preprint arXiv:2506.10892, 2025
Subham Sekhar Sahoo, Justin Deschenaux, Aaron Gokaslan, Guanghan Wang, Justin Chiu, and V olodymyr Kuleshov. The diffusion duality.arXiv preprint arXiv:2506.10892, 2025
-
[68]
Simple guidance mecha- nisms for discrete diffusion models
Yair Schiff, Subham Sekhar Sahoo, Hao Phung, Guanghan Wang, Alexander Rush, V olodymyr Kuleshov, Hugo Dalla-Torre, Sam Boshar, Bernardo P de Almeida, and Thomas Pierrot. Simple guidance mecha- nisms for discrete diffusion models. In... International Conference on Learning Representations, volume 2025, page 44153, 2025
2025
-
[69]
Scaling beyond masked diffusion language models.arXiv e-prints, pages arXiv–2602, 2026
Subham Sekhar Sahoo, Jean-Marie Lemercier, Zhihan Yang, Justin Deschenaux, Jingyu Liu, John Thickstun, and Ante Jukic. Scaling beyond masked diffusion language models.arXiv e-prints, pages arXiv–2602, 2026
2026
-
[70]
Simplified and generalized masked diffusion for discrete data.Advances in neural information processing systems, 37:103131– 103167, 2024
Jiaxin Shi, Kehang Han, Zhe Wang, Arnaud Doucet, and Michalis Titsias. Simplified and generalized masked diffusion for discrete data.Advances in neural information processing systems, 37:103131– 103167, 2024
2024
-
[71]
Denoising Diffusion Implicit Models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models.arXiv preprint arXiv:2010.02502, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[72]
Sparse-dllm: Accelerating diffusion llms with dynamic cache eviction
Yuerong Song, Xiaoran Liu, Ruixiao Li, Zhigeng Liu, Zengfeng Huang, Qipeng Guo, Ziwei He, and Xipeng Qiu. Sparse-dllm: Accelerating diffusion llms with dynamic cache eviction. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 33038–33046, 2026. 14
2026
-
[73]
Yuxuan Song, Zheng Zhang, Cheng Luo, Pengyang Gao, Fan Xia, Hao Luo, Zheng Li, Yuehang Yang, Hongli Yu, Xingwei Qu, et al. Seed diffusion: A large-scale diffusion language model with high-speed inference.arXiv preprint arXiv:2508.02193, 2025
-
[74]
wd1: Weighted policy optimization for reasoning in diffusion language models
Xiaohang Tang, Rares Dolga, Sangwoong Yoon, and Ilija Bogunovic. wd1: Weighted policy optimization for reasoning in diffusion language models.arXiv preprint arXiv:2507.08838, 2025
-
[75]
Yuchuan Tian, Yuchen Liang, Shuo Zhang, Yingte Shu, Guangwen Yang, Wei He, Sibo Fang, Tianyu Guo, Kai Han, Chao Xu, et al. From next-token to next-block: A principled adaptation path for diffusion llms.arXiv preprint arXiv:2512.06776, 2025
-
[76]
Generalized interpolating discrete diffusion.arXiv preprint arXiv:2503.04482, 2025
Dimitri V on Rütte, Janis Fluri, Yuhui Ding, Antonio Orvieto, Bernhard Schölkopf, and Thomas Hofmann. Generalized interpolating discrete diffusion.arXiv preprint arXiv:2503.04482, 2025
-
[77]
CreditDecoding: Accelerating Parallel Decoding in Diffusion Large Language Models with Trace Credit
Kangyu Wang, Zhiyun Jiang, Haibo Feng, Weijia Zhao, Lin Liu, Jianguo Li, Zhenzhong Lan, and Weiyao Lin. Creditdecoding: Accelerating parallel decoding in diffusion large language models with trace credits. arXiv preprint arXiv:2510.06133, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[78]
Diffusion LLMs Can Do Faster- Than-AR Inference via Discrete Diffusion Forcing, August 2025c
Xu Wang, Chenkai Xu, Yijie Jin, Jiachun Jin, Hao Zhang, and Zhijie Deng. Diffusion llms can do faster-than-ar inference via discrete diffusion forcing.arXiv preprint arXiv:2508.09192, 2025
-
[79]
Sparsed: Sparse attention for diffusion language models
Zeqing Wang, Gongfan Fang, Xinyin Ma, Xingyi Yang, and Xinchao Wang. Sparsed: Sparse attention for diffusion language models. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[80]
Chain-of-thought prompting elicits reasoning in large language models.Advances in neural information processing systems, 35:24824–24837, 2022
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models.Advances in neural information processing systems, 35:24824–24837, 2022
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.