Recognition: no theorem link
Dead Weights, Live Signals: Feedforward Graphs of Frozen Language Models
Pith reviewed 2026-05-10 17:50 UTC · model grok-4.3
The pith
Frozen language models linked by learned projections outperform any single model with only 17.6 million trainable parameters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Three small frozen models encode the input into a shared latent space whose aggregate signal is injected into two larger frozen models, whose representations feed a lightweight cross-attention output node; gradient flow through the frozen boundaries remains tractable and the output node learns selective routing without supervision.
What carries the argument
The feedforward graph in which frozen LLMs serve as nodes that communicate through learned linear projections into a shared continuous latent space, with residual stream injection hooks enabling end-to-end backpropagation.
If this is right
- Gradient flow across multiple frozen model boundaries is empirically tractable.
- The output node develops selective routing behavior across layer-2 nodes without explicit supervision.
- The graph outperforms parameter-matched learned classifiers on frozen single models by 9.1, 5.2, and 6.7 points on ARC-Challenge, OpenBookQA, and MMLU respectively.
- Extends prior static two-model steering results to fully trainable multi-node graphs.
Where Pith is reading between the lines
- The same wiring approach could incorporate additional heterogeneous models to increase capability without a proportional rise in trainable parameters.
- Pre-trained components might be reused modularly across tasks by swapping only the projection matrices and output node.
- Verification on larger model pools or different benchmarks would test whether the observed geometric compatibility generalizes.
Load-bearing premise
The latent spaces of independently trained heterogeneous LLMs are geometrically compatible enough that linear projections can align and combine their signals usefully.
What would settle it
Replace the learned projection matrices with fixed random ones and retrain only the output node; if the performance advantage over single models disappears, the claim that learned projections enable effective multi-model combination would be falsified.
Figures


read the original abstract
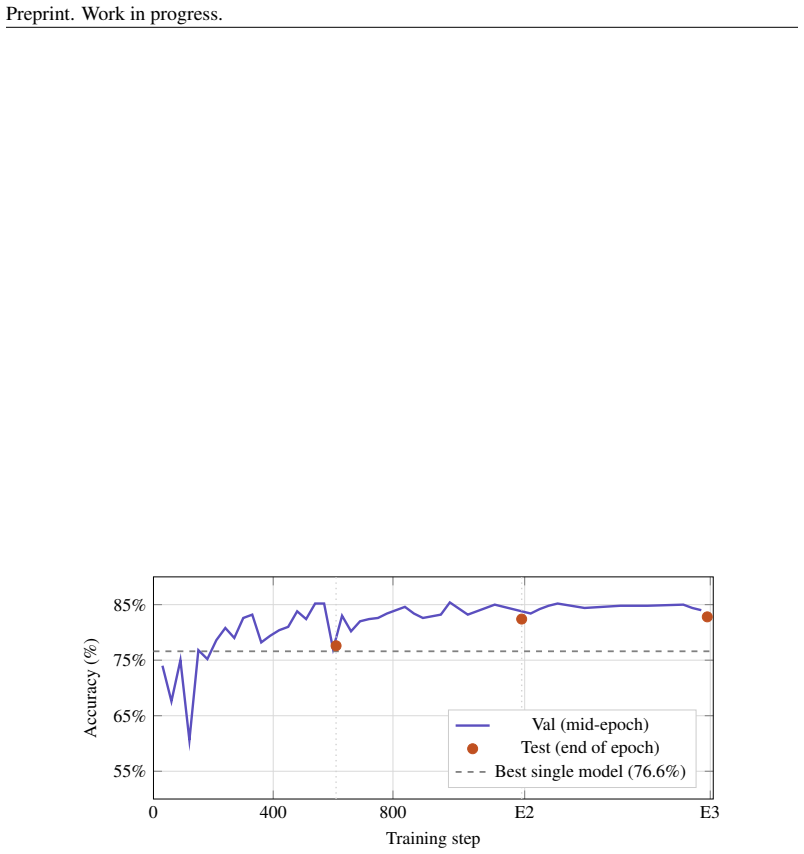
We present a feedforward graph architecture in which heterogeneous frozen large language models serve as computational nodes, communicating through a shared continuous latent space via learned linear projections. Building on recent work demonstrating geometric compatibility between independently trained LLM latent spaces~\cite{armstrong2026thinking}, we extend this finding from static two-model steering to end-to-end trainable multi-node graphs, where projection matrices are optimized jointly via backpropagation through residual stream injection hooks. Three small frozen models (Llama-3.2-1B, Qwen2.5-1.5B, Gemma-2-2B) encode the input into a shared latent space whose aggregate signal is injected into two larger frozen models (Phi-3-mini, Mistral-7B), whose representations feed a lightweight cross-attention output node. With only 17.6M trainable parameters against approximately 12B frozen, the architecture achieves 87.3\% on ARC-Challenge, 82.8\% on OpenBookQA, and 67.2\% on MMLU, outperforming the best single constituent model by 11.4, 6.2, and 1.2 percentage points respectively, and outperforming parameter-matched learned classifiers on frozen single models by 9.1, 5.2, and 6.7 points. Gradient flow through multiple frozen model boundaries is empirically verified to be tractable, and the output node develops selective routing behavior across layer-2 nodes without explicit supervision.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
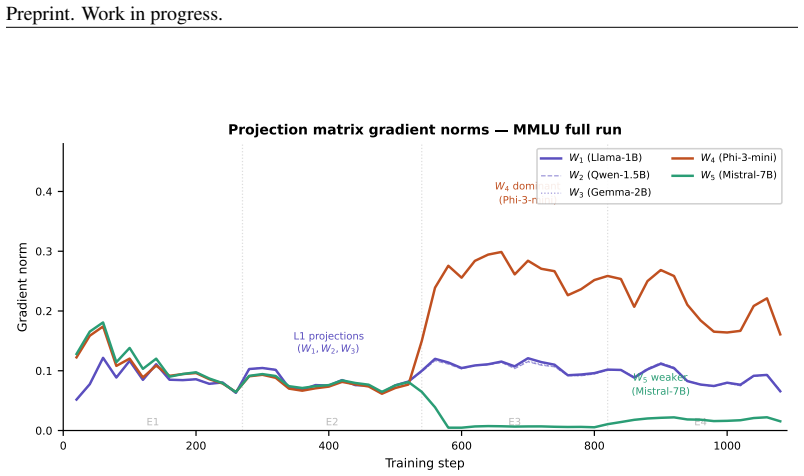
Summary. The paper introduces a feedforward graph architecture in which five heterogeneous frozen LLMs (Llama-3.2-1B, Qwen2.5-1.5B, Gemma-2-2B, Phi-3-mini, Mistral-7B) act as nodes whose residual streams are connected via learned linear projections into a shared latent space; three smaller models encode inputs, their aggregated signals are injected into the two larger models, and a lightweight cross-attention node produces the final output. With 17.6 M trainable parameters, the system reports 87.3 % on ARC-Challenge, 82.8 % on OpenBookQA and 67.2 % on MMLU, exceeding the best single constituent model by 11.4, 6.2 and 1.2 points and parameter-matched single-model classifiers by 9.1, 5.2 and 6.7 points. Gradient flow across frozen boundaries is stated to be empirically tractable and the output node exhibits selective routing.
Significance. If the central claim holds, the work demonstrates that independently trained LLMs can be composed into an end-to-end trainable graph with minimal trainable parameters while delivering measurable gains over both single-model and parameter-matched baselines. The explicit verification of gradient flow through multiple model boundaries and the emergence of routing behavior without supervision are concrete strengths that could influence efficient ensembling methods.
major comments (3)
- [Abstract, §4] Abstract and §4 (Experiments): the performance tables report point estimates without error bars, multiple random seeds, or statistical significance tests. The 11.4-point ARC-Challenge gain is therefore difficult to interpret as robust evidence for the graph architecture rather than training variance on the target tasks.
- [§3.1, §3.2] §3.1 and §3.2: the central assumption that linear projections align the latent spaces of the five heterogeneous models is invoked from prior two-model results but is not directly tested (no post-projection CCA, singular-value overlap, or ablation replacing learned projections with frozen random matrices). Without such a control, the reported gains over parameter-matched single-model classifiers could be explained by task-specific optimization of the 17.6 M parameters rather than cross-model signal combination.
- [§4.2] §4.2 (Ablations): the manuscript provides no ablation that isolates the contribution of the multi-node graph (e.g., single large model + learned projections versus the full three-to-two injection graph). The existing parameter-matched baseline does not address whether the specific injection topology or the number of frozen nodes is load-bearing for the observed improvements.
minor comments (2)
- [Abstract] The citation armstrong2026thinking appears to be a future or placeholder reference; please verify and supply the correct bibliographic details.
- [§3.2] Exact layer indices and dimensionalities of the projection matrices and injection hooks are described as free parameters but are not tabulated; a supplementary table listing these values would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below and commit to revisions that directly respond to the concerns raised.
read point-by-point responses
-
Referee: [Abstract, §4] Abstract and §4 (Experiments): the performance tables report point estimates without error bars, multiple random seeds, or statistical significance tests. The 11.4-point ARC-Challenge gain is therefore difficult to interpret as robust evidence for the graph architecture rather than training variance on the target tasks.
Authors: We agree that the absence of multi-seed statistics and error bars weakens the interpretability of the reported gains. In the revised manuscript we will rerun all experiments across three independent random seeds, report means and standard deviations for every metric, and add a brief discussion of effect sizes relative to observed variance. The magnitude of the improvements (particularly the 11.4-point ARC-Challenge delta) makes variance an unlikely sole explanation, yet we accept that formal reporting is required for robust claims. revision: yes
-
Referee: [§3.1, §3.2] §3.1 and §3.2: the central assumption that linear projections align the latent spaces of the five heterogeneous models is invoked from prior two-model results but is not directly tested (no post-projection CCA, singular-value overlap, or ablation replacing learned projections with frozen random matrices). Without such a control, the reported gains over parameter-matched single-model classifiers could be explained by task-specific optimization of the 17.6 M parameters rather than cross-model signal combination.
Authors: The alignment premise rests on the cited two-model geometric compatibility results. To isolate the contribution of learned projections, we will add an ablation that freezes the projection matrices to random values of identical shape while keeping all other trainable parameters. A substantial performance drop in this condition would indicate that the learned mappings are necessary for effective cross-model signal flow rather than the gains arising purely from optimizing 17.6 M parameters on the downstream tasks. We will also include a short post-projection representation overlap analysis if space allows. revision: yes
-
Referee: [§4.2] §4.2 (Ablations): the manuscript provides no ablation that isolates the contribution of the multi-node graph (e.g., single large model + learned projections versus the full three-to-two injection graph). The existing parameter-matched baseline does not address whether the specific injection topology or the number of frozen nodes is load-bearing for the observed improvements.
Authors: The current parameter-matched baselines compare against single frozen models but do not isolate the multi-node topology itself. We will add a targeted ablation that routes the three small-model encoders into a single larger frozen model (e.g., Mistral-7B) via the same learned projections, thereby removing the heterogeneous two-model injection stage. Direct comparison of this reduced topology against the full three-to-two graph will clarify whether the specific node count and injection pattern are load-bearing for the observed gains. revision: yes
Circularity Check
No circularity; empirical results on external benchmarks are independent of cited compatibility assumption
full rationale
The paper reports performance on standard held-out benchmarks (ARC-Challenge 87.3%, OpenBookQA 82.8%, MMLU 67.2%) after training 17.6M parameters. These metrics are defined externally and not constructed from the projection matrices or the cited two-model compatibility result. The self-citation to prior geometric compatibility work supplies background motivation but is not substituted for the new multi-node graph experiments or the reported gains over single-model baselines. No equations, fitted quantities, or claims reduce the final performance numbers to the inputs by definition or by construction.
Axiom & Free-Parameter Ledger
free parameters (2)
- Shared latent space dimension
- Projection matrix dimensions and injection layers
axioms (1)
- domain assumption Latent spaces of independently trained LLMs are geometrically compatible and alignable via linear projections
Reference graph
Works this paper leans on
-
[1]
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
M. Abdin, J. Aneja, H. Awadalla, A. Awadallah, A. A. Awan, N. Bach, A. Bahree, A. Bakhtiari, J. Bao, et al. Phi-3 technical report: A highly capable language model locally on your phone. arXiv preprint arXiv:2404.14219,
work page internal anchor Pith review arXiv
-
[2]
M. Armstrong, N. Ayoobi, and A. Mukherjee. Thinking in different spaces: Domain-specific latent geometry survives cross-architecture translation.arXiv preprint arXiv:2603.20406,
- [3]
-
[4]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
P. Clark, I. Cowhey, O. Etzioni, T. Khot, A. Sabharwal, C. Schoenick, and O. Tafjord. Think you have solved question answering? try ARC, the AI2 reasoning challenge.arXiv preprint arXiv:1803.05457,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
LoRA: Low-Rank Adaptation of Large Language Models
8 Preprint. Work in progress. E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, and W. Chen. LoRA: Low-rank adaptation of large language models.arXiv preprint arXiv:2106.09685,
work page internal anchor Pith review Pith/arXiv arXiv
- [6]
-
[7]
A. Q. Jiang, A. Sablayrolles, A. Roux, A. Mensch, B. Savary, C. Bamford, D. S. Chaplot, D. de las Casas, et al. Mixtral of experts.arXiv preprint arXiv:2401.04088,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Decoupled Weight Decay Regularization
I. Loshchilov and F. Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Mihaylov, P
T. Mihaylov, P. Clark, T. Khot, and A. Sabharwal. Can a suit of armor conduct electricity? a new dataset for open book question answering. InProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing (EMNLP),
2018
-
[10]
Q. Team. Qwen2.5 technical report.arXiv preprint arXiv:2412.15115,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
A. M. Turner, L. Thiergart, G. Leech, D. Udell, J. J. Vazquez, U. Mini, and M. MacDiarmid. Steering language models with activation engineering.arXiv preprint arXiv:2308.10248,
work page internal anchor Pith review arXiv
-
[12]
T. Wolf, L. Debut, V . Sanh, J. Chaumond, C. Delangue, A. Moi, P. Cistac, T. Rault, R. Louf, M. Fun- towicz, et al. Transformers: State-of-the-art natural language processing. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstra- tions,
2020
-
[13]
Q. Wu, G. Bansal, J. Zhang, Y . Wu, S. Zhang, E. Zhu, B. Li, L. Jiang, X. Zhang, and C. Wang. AutoGen: Enabling next-gen LLM applications via multi-agent conversation.arXiv preprint arXiv:2308.08155,
work page internal anchor Pith review Pith/arXiv arXiv
- [14]
-
[15]
A. Zou, L. Phan, S. Chen, J. Campbell, P. Guo, R. Ren, A. Pan, X. Yin, M. Mazeika, et al. Represen- tation engineering: A top-down approach to AI transparency.arXiv preprint arXiv:2310.01405,
work page internal anchor Pith review arXiv
-
[16]
and Qwen2.5-1.5B-Instruct (destination,d= 1536), connected by a single projection matrixW∈ R1536×2048 and a four-class linear output headH∈R 4×1536. The forward pass proceeds as follows: (1) encode a factual question with Llama-3.2-1B, extracting the final-token hidden state at layer 24 of 32 (depth 0.75); (2) L2-normalize the resulting vector hsrc ∈R 204...
2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.