ASPECT:Analogical Semantic Policy Execution via Language Conditioned Transfer
Pith reviewed 2026-05-10 18:00 UTC · model grok-4.3
The pith
An LLM remaps new task observations into source-task language so a trained RL policy can execute zero-shot on novel analogous tasks via a language-conditioned VAE.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that an LLM can serve as a dynamic semantic operator that aligns the textual description of a new observation with the source task; the resulting caption conditions a text-conditioned VAE to generate a compatible imagined state, allowing the original policy to be reused without modification and thereby achieving zero-shot transfer to complex novel analogous tasks.
What carries the argument
The LLM acting as a dynamic semantic operator that remaps the current observation description to a source-task caption, which then conditions the text-conditioned VAE to produce a policy-compatible imagined state.
If this is right
- Policies trained on one task can be reused on a broad spectrum of structurally related but previously unseen tasks.
- The method handles compositional and truly novel task variations that fall outside any predefined discrete class system.
- Natural language replaces rigid latent variables, removing the constraint of fixed category mappings.
- Direct policy execution occurs at test time with no additional fine-tuning or data collection.
Where Pith is reading between the lines
- The same LLM-driven remapping step could be inserted into other state-representation pipelines that already use language as an interface.
- If the VAE reconstruction remains faithful across domains, the approach might reduce the amount of environment-specific RL data needed for each new task family.
- The method implicitly assumes that semantic similarity in language corresponds to policy-compatible state similarity; testing this assumption on tasks with subtle but policy-critical differences would clarify its scope.
Load-bearing premise
The LLM must perform accurate semantic remapping of the current observation to the source task at test time without introducing errors that render the generated state incompatible with the trained policy.
What would settle it
Run the agent on a suite of held-out analogous tasks where an independent judge verifies the LLM remappings are correct, then measure whether success rate collapses when those remappings are deliberately corrupted while keeping all other components fixed.
Figures







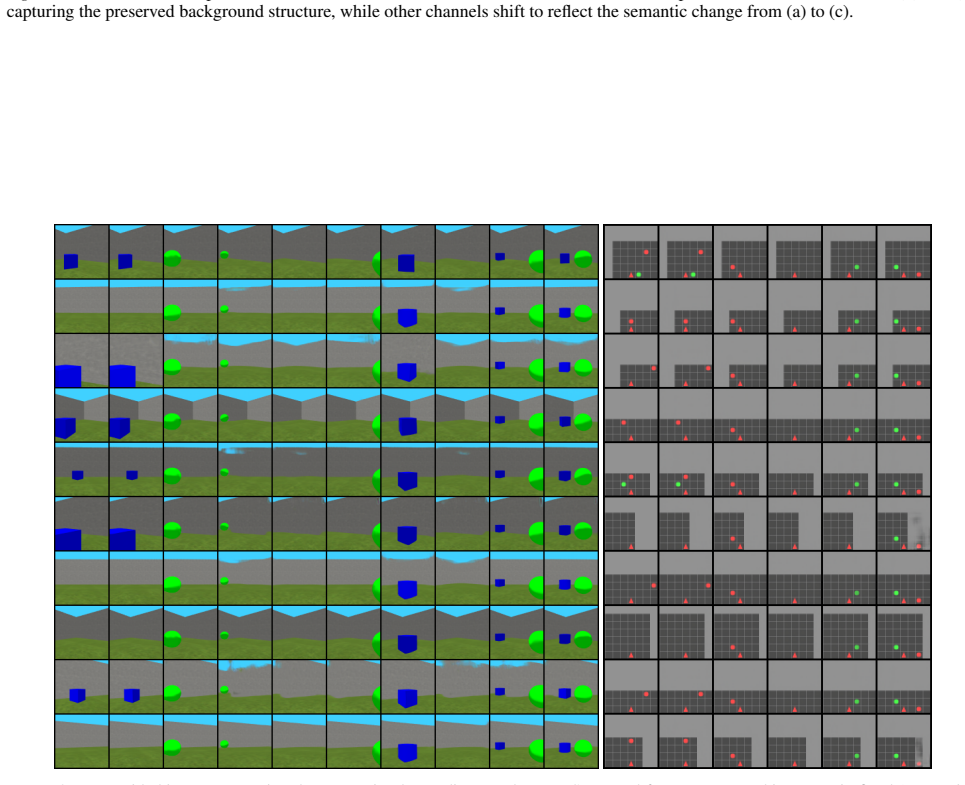


read the original abstract
Reinforcement Learning (RL) agents often struggle to generalize knowledge to new tasks, even those structurally similar to ones they have mastered. Although recent approaches have attempted to mitigate this issue via zero-shot transfer, they are often constrained by predefined, discrete class systems, limiting their adaptability to novel or compositional task variations. We propose a significantly more generalized approach, replacing discrete latent variables with natural language conditioning via a text-conditioned Variational Autoencoder (VAE). Our core innovation utilizes a Large Language Model (LLM) as a dynamic \textit{semantic operator} at test time. Rather than relying on rigid rules, our agent queries the LLM to semantically remap the description of the current observation to align with the source task. This source-aligned caption conditions the VAE to generate an imagined state compatible with the agent's original training, enabling direct policy reuse. By harnessing the flexible reasoning capabilities of LLMs, our approach achieves zero-shot transfer across a broad spectrum of complex and truly novel analogous tasks, moving beyond the limitations of fixed category mappings. Code and videos are available \href{https://anonymous.4open.science/r/ASPECT-85C3/}{here}.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ASPECT, a method for zero-shot transfer in reinforcement learning. It trains a text-conditioned VAE and policy on source tasks, then at test time employs an LLM to semantically remap the current observation description into a source-aligned caption. This caption conditions the VAE to generate an imagined state, allowing direct reuse of the source policy on novel analogous tasks without relying on fixed discrete category mappings.
Significance. If the empirical validation holds, the approach could meaningfully advance zero-shot generalization in RL by replacing rigid class-based transfer with flexible, language-driven semantic remapping. The core idea of using LLMs as dynamic semantic operators to produce policy-compatible imagined states is a promising direction that extends beyond prior work limited to predefined mappings. No machine-checked proofs or parameter-free derivations are present, but the method is falsifiable via standard RL transfer benchmarks.
major comments (2)
- [Abstract] Abstract: The central claim of successful zero-shot transfer on 'complex and truly novel analogous tasks' is asserted without any reported experimental details, baselines, metrics, success rates, or validation procedures. This is load-bearing for the contribution, as the soundness of the transfer mechanism cannot be assessed from the given information.
- [Method] Proposed method (LLM semantic remapping step): The approach assumes the LLM reliably produces source-aligned captions that preserve the semantic invariants (object relations, affordances) on which the VAE and policy were trained. No accuracy bounds, remapping fidelity metrics, failure-mode analysis, or ablation on prompt sensitivity are described, leaving open the risk that misalignment generates out-of-support states and immediate policy failure.
minor comments (2)
- [Abstract] The abstract contains a minor grammatical issue: 'a significantly more generalized approach' should be 'a significantly more general approach' for precision.
- [Abstract] The code and video link is provided as an anonymous URL; this is acceptable for review but should be replaced with a permanent repository upon acceptance.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the potential of ASPECT to advance zero-shot RL generalization through language-driven semantic remapping. We address the major comments point by point below, providing clarifications from the manuscript and indicating where revisions will strengthen the presentation.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim of successful zero-shot transfer on 'complex and truly novel analogous tasks' is asserted without any reported experimental details, baselines, metrics, success rates, or validation procedures. This is load-bearing for the contribution, as the soundness of the transfer mechanism cannot be assessed from the given information.
Authors: The abstract serves as a high-level summary of the contribution and claims. The manuscript's Experiments section provides the requested details: we evaluate on a suite of source and target tasks in standard RL environments (e.g., object manipulation and navigation domains), compare against baselines including fixed discrete mapping methods and prior zero-shot transfer approaches, report success rates and transfer metrics (e.g., average return and completion rates), and describe the validation procedure (zero-shot evaluation on held-out analogous tasks with no fine-tuning). To improve accessibility, we will revise the abstract to include a concise summary of these key empirical outcomes. revision: yes
-
Referee: [Method] Proposed method (LLM semantic remapping step): The approach assumes the LLM reliably produces source-aligned captions that preserve the semantic invariants (object relations, affordances) on which the VAE and policy were trained. No accuracy bounds, remapping fidelity metrics, failure-mode analysis, or ablation on prompt sensitivity are described, leaving open the risk that misalignment generates out-of-support states and immediate policy failure.
Authors: The manuscript grounds the LLM remapping in empirical results across multiple novel task compositions, showing that the generated captions enable successful policy reuse without retraining. Qualitative discussion of failure cases (e.g., when semantic invariants are not preserved) appears in the Limitations and Discussion sections. We did not include quantitative remapping fidelity metrics (such as embedding-based alignment scores) or prompt-sensitivity ablations. We will add these in revision, including an ablation table varying prompt templates and a fidelity analysis comparing LLM outputs to ground-truth source descriptions. revision: partial
Circularity Check
No circularity: method uses external LLM remapping and trained VAE without self-referential reduction
full rationale
The paper describes training a text-conditioned VAE and policy on source-task data, then invoking an external LLM at test time to produce a source-aligned caption that conditions the VAE for state generation and policy reuse. This is a methodological proposal relying on the independent capabilities of LLMs and data-driven models. No equations, fitted parameters renamed as predictions, self-definitional constructs, or load-bearing self-citations appear in the abstract or description. The zero-shot transfer claim rests on the LLM's semantic remapping accuracy, which is an external assumption rather than a derivation that collapses to the paper's own inputs by construction.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Our core innovation utilizes a Large Language Model (LLM) as a dynamic semantic operator at test time... ct→s = M_LLM(ct, C)
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
affordance-preserving mapping Φ : V_T → V_S ... exact MDP homomorphism h
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
A brief about the environment
-
[2]
What is the target task?
-
[3]
A description of the current observation This is the Context,C ###ROLE AND PURPOSE You must:
-
[4]
Show detailed reasoning | step-by-step interpretation of how imagination occurs
-
[5]
Output a final JSON containing the transformed or unchanged scene description. You are not just answering but *solving the target task through reasoning * | explain what changes are needed, why, and finally give the exact JSON result. ###HOW IMAGINATION WORKS - The agent performs strictly its known skills (source tasks). - When the target task differs (Ag...
-
[6]
- Preserve spatial layout, geometry, and environment details
**Minimal Transformation ** - Modify only what is necessary to make the target solvable. - Preserve spatial layout, geometry, and environment details
-
[7]
**Affordance Reasoning ** 14 ASPECT:Analogical Semantic Policy Execution via Language Conditioned Transfer - If two objects afford the same action (e.g., pick, push, open), they can be substituted. - Example: - Known: "pick red ball" - Target: "pick green ball" →Imagine the green ball as red. This will direct the agent to pick the red ball, as it is a kno...
-
[8]
**Multi-Object or Sequential Tasks ** - Give proper attention to the spatial position if there are multiple object. Don’t mix up the positions
-
[9]
**No Fabrication ** - Never add or invent objects or properties not present in the input scene
-
[10]
Do not invent additional texts
**Realism and Consistency ** - Maintain the original tone, structure, style, and spatial wording. Do not invent additional texts. - Modify only essential object properties (color, shape, size, etc.). ###REASONING STYLE - Think step-by-step, like a human reasoning through perception. - Explain:
-
[11]
What the agent currently knows
-
[12]
What the target task is
-
[13]
What are the differences between the target and the source task
-
[14]
How to map such differences to the source task
-
[15]
Whether the subtask division is necessary
-
[16]
What is visible in the current scene?
-
[17]
What minimal changes are needed and why?
-
[18]
Can the minimal changes help the agent to solve the target task by mentally imagining an altered scene?. Check against each of the subtasks. Discard if the change doesn’t affect the subtask. - Use clear, causal reasoning before outputting the JSON. - Stop reasoning once the decision is made. ###OUTPUT FORMAT After reasoning, always output only valid JSON ...
-
[19]
A brief description of the environment dynamics and rules
-
[20]
The source task description (what the agent knows)
-
[21]
The target task description
-
[22]
Pick the blue box and avoid green ball from the room with grass floor and concrete wall
A description of the current observation. Example (MiniWorld): •Environment Context: - The agent operates in a partially observable 3D gridworld-like room. The agent sees a portion of the room. - At the start of each episode, the agent and objects are randomly initialised in the environment. - The agent can perform the following actions: rotate left/right...
-
[23]
Remapping the target reward (yellow duckie) to the source reward (blue box)
-
[24]
Remapping the old source reward (blue box), which is now a distractor, to a known distractor (green ball) to ensure avoidance
-
[25]
Hallucinating the environment textures (wooden floor/brick walls) back to the training environment (grass floor/concrete walls) to ensure feature consistency. C. Structured vs. Unstructured Captions C.1. Structured Captions The structured query is template filling. For example, in the MiniWorld environment: The agent is in a room with a grass floor <floor...
work page 2021
-
[26]
FiLM Modulation:The spatial latent z is upsampled to the features’ resolution and mapped to affine parameters (γ, β) for Feature-wise Linear Modulation, allowing the latent structure to spatially modulate the features
-
[27]
Cross-Attention:A Multi-Head Cross-Attention layer allows the visual features to attend to the sequence of text embeddingst, injecting semantic information. Discriminators.The architecture includes two distinct adversarial modules used during training: • Caption Discriminator (Dtext):To ensure the latent z captures only visual informationorthogonalto the ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.