Recognition: no theorem link
Awakening the Sleeping Agent: Lean-Specific Agentic Data Reactivates General Tool Use in Goedel Prover
Pith reviewed 2026-05-10 17:48 UTC · model grok-4.3
The pith
Heavy fine-tuning on formal mathematics suppresses a model's tool-calling ability, yet 100 domain-specific traces restore it and transfer to unrelated tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
After domain specialization via heavy supervised fine-tuning, the model loses its capacity to produce valid tool calls, but fine-tuning on only 100 Lean-specific traces of natural-language queries to search Mathlib restores tool-calling accuracy to levels approaching the base model, with the regained ability transferring to general function-calling benchmarks and yielding measurable gains on formal proof tasks.
What carries the argument
Lean-specific agentic traces that use natural-language queries to retrieve theorems and lemmas, which reactivate suppressed general tool-calling behavior.
If this is right
- Domain-specialized models can recover lost general capabilities through minimal additional fine-tuning.
- The recovered tool-use ability generalizes across mismatched task distributions and protocols.
- In-domain formal mathematics performance improves alongside the cross-domain gains.
- Heavy supervised fine-tuning on one domain need not permanently remove skills present in the base model.
Where Pith is reading between the lines
- Models may retain latent capabilities that become inaccessible after specialization but can be surfaced efficiently.
- This pattern could extend to other suppressed skills such as reasoning chains or multi-step planning in specialized models.
- Recovery strategies might reduce reliance on large-scale retraining when adapting already-tuned models to new agentic roles.
Load-bearing premise
The small set of Lean traces reactivates a dormant general tool-use capacity rather than merely teaching patterns that happen to match the evaluation protocols.
What would settle it
Measure performance on a fresh function-calling benchmark whose tasks and protocol share no overlap with the Lean traces or the original training data, and check whether accuracy returns to near zero when the traces are replaced by non-agentic Lean examples.
Figures

read the original abstract
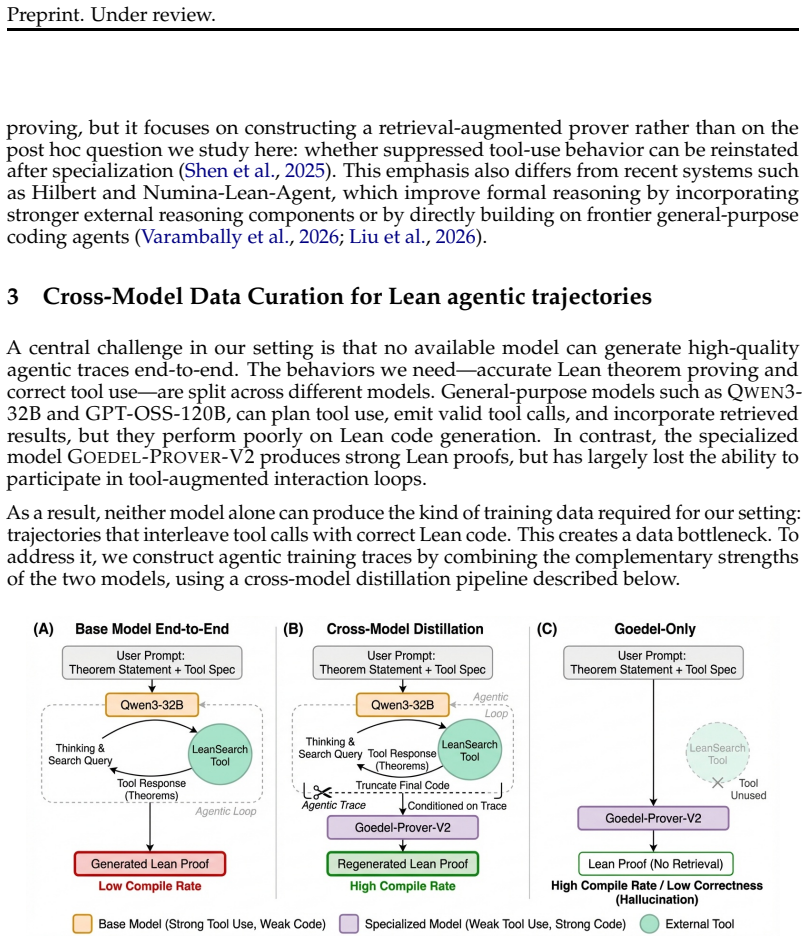
Heavy supervised fine-tuning on a target domain can strongly suppress capabilities that were present in the base model. We study this phenomenon in formal mathematics using Goedel-Prover-V2, an open-source model heavily trained on 1.8 million formal-math examples. After domain specialization, the model almost completely loses its ability to produce valid tool calls, even when explicitly instructed to use tools, dropping from 89.4% function-calling accuracy in the base model to nearly 0%. We ask whether this agentic collapse is permanent or instead reversible. To answer this question, we fine-tune the specialized model on a small amount of Lean-specific tool-use data. Remarkably, as few as 100 agentic traces are sufficient to restore strong tool-calling behavior. Importantly, this recovery is not the result of reward hacking or benchmark-specific optimization: the recovery data is entirely drawn from the Lean setting, where the model uses natural-language queries to search the Mathlib library for relevant theorems and lemmas, yet the regained capability transfers well beyond that domain. In particular, these same 100 Lean-specific traces improve performance on the Berkeley Function Calling Leaderboard from near zero to 83.8%, approaching the base model's 89.4% despite the mismatch in task distribution and protocol. The recovered capability is also practically useful in-domain. On ProofNet, pass@32 improves from 21.51% to 25.81%. Together, these results show that heavy domain supervised fine-tuning can suppress general tool-use ability without permanently erasing it, and that a small amount of domain-specific agentic data can awaken dormant tool-use capabilities.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that heavy SFT on 1.8M formal-math examples suppresses general tool-calling in Goedel-Prover-V2 (Berkeley accuracy drops from 89.4% to ~0%), but fine-tuning on only 100 Lean-specific agentic traces (natural-language Mathlib queries) restores strong tool use, raising Berkeley performance to 83.8% and ProofNet pass@32 from 21.51% to 25.81%. The recovery is presented as reactivation of a dormant capability rather than domain-specific re-learning, with transfer across mismatched protocols offered as evidence.
Significance. If the central empirical result holds after controls, the finding that minimal domain-specific agentic data can recover suppressed general tool-use has clear value for understanding capability retention under specialization. The reported transfer from Lean traces to Berkeley protocol and the in-domain ProofNet gain are the strongest elements; they would support broader claims about non-destructive fine-tuning if the reactivation interpretation is isolated from simpler re-teaching accounts.
major comments (3)
- [Abstract / Results] Abstract and implied Results section: the reactivation interpretation (dormant general capability restored by Lean traces) is load-bearing for the central claim, yet no ablation compares the 100 agentic traces against an equal number of non-agentic Lean examples or against a model lacking prior tool-use exposure; without these, the data cannot distinguish reactivation from the traces simply supplying sufficient supervision to re-learn output formats that happen to generalize to Berkeley.
- [Abstract / Evaluation] Evaluation protocol (implied in abstract): the before/after Berkeley numbers are presented without reported controls for prompt phrasing, system instructions, or evaluation harness differences between the base model and the post-SFT versions; these factors are known confounders in tool-calling benchmarks and directly affect defensibility of the 83.8% recovery figure.
- [Methods] Methods (implied): the paper states that the 100 traces use natural-language queries to search Mathlib, but provides no quantitative comparison of format alignment or token-level overlap between the Lean traces and Berkeley function-call schemas; such analysis is needed to assess whether transfer is protocol-agnostic reactivation or partial format alignment.
minor comments (1)
- [Abstract] The abstract reports pass@32 on ProofNet but does not clarify whether the same 100-trace model or an additional in-domain fine-tune was used; this should be stated explicitly for clarity.
Simulated Author's Rebuttal
We thank the referee for their insightful comments on our manuscript. We address each of the major comments point by point below, providing clarifications and indicating revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract / Results] Abstract and implied Results section: the reactivation interpretation (dormant general capability restored by Lean traces) is load-bearing for the central claim, yet no ablation compares the 100 agentic traces against an equal number of non-agentic Lean examples or against a model lacking prior tool-use exposure; without these, the data cannot distinguish reactivation from the traces simply supplying sufficient supervision to re-learn output formats that happen to generalize to Berkeley.
Authors: We acknowledge that the suggested ablations would provide stronger isolation of the reactivation effect from re-learning. However, the central evidence in our work is the transfer of the recovered capability to the Berkeley Function Calling Leaderboard, which employs a substantially different protocol and task distribution from the Lean natural-language queries used in the 100 traces. This mismatch makes it unlikely that the improvement is due to re-learning specific output formats. Regarding a model without prior tool-use exposure, our base model (Goedel-Prover-V2 before heavy SFT) already demonstrates high tool-calling performance, and the SFT on formal math examples suppresses this ability, which is then restored. We have revised the manuscript to include additional discussion in the Results and Limitations sections clarifying these points and acknowledging the absence of the requested ablations as a direction for future work. revision: partial
-
Referee: [Abstract / Evaluation] Evaluation protocol (implied in abstract): the before/after Berkeley numbers are presented without reported controls for prompt phrasing, system instructions, or evaluation harness differences between the base model and the post-SFT versions; these factors are known confounders in tool-calling benchmarks and directly affect defensibility of the 83.8% recovery figure.
Authors: We confirm that the Berkeley evaluations for all model variants were conducted using the identical official benchmark prompts, system instructions, and evaluation harness to ensure fair comparison. No modifications were made to the evaluation setup between the base model and the fine-tuned versions. To address this concern, we have added a subsection in the Methods describing the evaluation protocol in detail, including confirmation that the same settings were used throughout. revision: yes
-
Referee: [Methods] Methods (implied): the paper states that the 100 traces use natural-language queries to search Mathlib, but provides no quantitative comparison of format alignment or token-level overlap between the Lean traces and Berkeley function-call schemas; such analysis is needed to assess whether transfer is protocol-agnostic reactivation or partial format alignment.
Authors: The manuscript highlights the protocol mismatch as key evidence for general reactivation. We have updated the Methods section to provide a more detailed qualitative comparison of the Lean agentic traces (natural language queries to Mathlib) versus the structured function call schemas in Berkeley, underscoring the differences in input format and expected outputs. While a quantitative token-level overlap analysis is not present in the original submission, the described differences support our interpretation; we note this as an area for potential expansion in future revisions if additional space permits. revision: partial
Circularity Check
No circularity: purely empirical benchmark results with no derivations or self-referential reductions
full rationale
The paper reports an empirical fine-tuning experiment: a model specialized on 1.8M math examples is further tuned on 100 Lean agentic traces, after which direct measurements show recovery on the Berkeley Function Calling Leaderboard (to 83.8%) and ProofNet (pass@32 to 25.81%). No equations, fitted parameters, uniqueness theorems, or ansatzes appear in the provided text or abstract. Performance numbers are external benchmark outcomes, not quantities derived by construction from the training data or prior self-citations. The reactivation interpretation is an explanatory claim about the results rather than a load-bearing step that reduces to the inputs; the evidence chain remains falsifiable via the reported scores and does not collapse into self-definition or renaming.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Mitigating catastrophic forgetting in language transfer via model merging
Anton Alexandrov, Veselin Raychev, Mark Niklas Müller, Ce Zhang, Martin Vechev, and Kristina Toutanova. Mitigating catastrophic forgetting in language transfer via model merging. InFindings of the Association for Computational Linguistics: EMNLP 2024, pp. 17167–17186,
2024
-
[2]
Guoxiong Gao, Haocheng Ju, Jiedong Jiang, Zihan Qin, and Bin Dong
doi: 10.1016/S1364-6613(99)01294-2. Guoxiong Gao, Haocheng Ju, Jiedong Jiang, Zihan Qin, and Bin Dong. A semantic search engine for mathlib4. InFindings of the Association for Computational Linguistics: EMNLP 2024, pp. 8001–8013,
-
[3]
doi: 10.1073/pnas.1611835114. Suhas Kotha, Jacob Mitchell Springer, and Aditi Raghunathan. Understanding catastrophic forgetting in language models via implicit inference. InThe Twelfth International Conference on Learning Representations,
-
[4]
Revisiting catastrophic forget- ting in large language model tuning
Hongyu Li, Liang Ding, Meng Fang, and Dacheng Tao. Revisiting catastrophic forget- ting in large language model tuning. InFindings of the Association for Computational Linguistics: EMNLP 2024, pp. 4297–4308. Association for Computational Linguistics,
2024
-
[5]
URL https://aclanthology.org/2024
doi: 10.18653/v1/2024.findings-emnlp.249. URL https://aclanthology.org/2024. findings-emnlp.249/. Yong Lin, Shange Tang, Bohan Lyu, et al. Goedel-prover-v2: Scaling formal theorem proving with scaffolded data synthesis and self-correction,
-
[6]
Junqi Liu, Zihao Zhou, Zekai Zhu, Marco Dos Santos, Weikun He, Jiawei Liu, Ran Wang, Yunzhou Xie, Junqiao Zhao, Qiufeng Wang, et al. Numina-lean-agent: An open and general agentic reasoning system for formal mathematics.arXiv preprint arXiv:2601.14027,
-
[7]
URLhttps: //www.sciencedirect.com/science/article/pii/S0079742108605368
doi: 10.1016/S0079-7421(08)60536-8. Ivan Moshkov, Darragh Hanley, Ivan Sorokin, Shubham Toshniwal, Christof Henkel, Benedikt Schifferer, Wei Du, and Igor Gitman. Aimo-2 winning solution: Building state-of-the-art mathematical reasoning models with openmathreasoning dataset.arXiv preprint arXiv:2504.16891,
-
[8]
Ziju Shen, Naohao Huang, Fanyi Yang, Yutong Wang, Guoxiong Gao, Tianyi Xu, Jiedong Jiang, Wanyi He, Pu Yang, Mengzhou Sun, et al. Real-prover: Retrieval augmented lean prover for mathematical reasoning.arXiv preprint arXiv:2505.20613,
-
[9]
type": "function
A Tool-calling instruction prompt The following system message is prepended to every agentic training example and used at inference time to specify the LEANSEARCHtool schema and invocation format. You are a Lean 4 theorem prover that uses leansearch tool to find relevant theorems in Mathlib before producing the Lean 4 code. # Tools You may call one or mor...
1959
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.