Recognition: unknown
Adversarial Label Invariant Graph Data Augmentations for Out-of-Distribution Generalization
Pith reviewed 2026-05-10 16:56 UTC · model grok-4.3
The pith
Adversarial label-invariant augmentations improve graph classifier accuracy under covariate shift.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
RIA performs adversarial exploration of counterfactual data environments through label-invariant augmentations, which prevents collapse to an in-distribution learner and raises accuracy on out-of-distribution graph classification under covariate shift.
What carries the argument
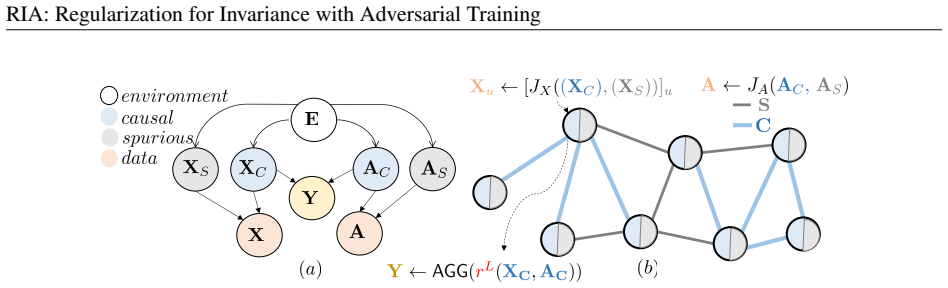
RIA (Regularization for Invariance with Adversarial training), which induces counterfactual environments via adversarial label-invariant data augmentations and optimizes them with alternating gradient descent-ascent.
Load-bearing premise
That adversarial label-invariant augmentations will reliably prevent collapse to an in-distribution learner and that the Q-learning analogy supplies a sound reason to generate counterfactual graph environments.
What would settle it
On a controlled causally generated graph dataset with known covariate shift, if adding the adversarial component produces no accuracy gain over the same label-invariant augmentations without the adversarial step, the claimed benefit would not hold.
Figures


read the original abstract
Out-of-distribution (OoD) generalization occurs when representation learning encounters a distribution shift. This occurs frequently in practice when training and testing data come from different environments. Covariate shift is a type of distribution shift that occurs only in the input data, while the concept distribution stays invariant. We propose RIA - Regularization for Invariance with Adversarial training, a new method for OoD generalization under convariate shift. Motivated by an analogy to $Q$-learning, it performs an adversarial exploration for counterfactual data environments. These new environments are induced by adversarial label invariant data augmentations that prevent a collapse to an in-distribution trained learner. It works with many existing OoD generalization methods for covariate shift that can be formulated as constrained optimization problems. We develop an alternating gradient descent-ascent algorithm to solve the problem in the context of causally generated graph data, and perform extensive experiments on OoD graph classification for various kinds of synthetic and natural distribution shifts. We demonstrate that our method can achieve high accuracy compared with OoD baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes RIA (Regularization for Invariance with Adversarial training), a method for OoD generalization under covariate shift on graphs. Motivated by a Q-learning analogy, it uses adversarial label-invariant data augmentations to induce counterfactual environments that prevent collapse to an in-distribution learner. The approach integrates with existing constrained-optimization OoD methods, is solved via alternating gradient descent-ascent, and is evaluated on synthetic and natural distribution shifts in graph classification, reporting higher accuracy than baselines.
Significance. If the construction is sound, RIA could offer a practical augmentation-based regularizer that enhances robustness of graph models to covariate shifts by simulating varied environments while preserving labels. Compatibility with other OoD methods and the alternating optimization procedure are positive features. However, the heuristic (rather than formally derived) nature of the Q-learning motivation limits the potential theoretical contribution and raises questions about whether the OoD gains are reliably attributable to the stated mechanism rather than generic adversarial effects.
major comments (2)
- [Abstract / Method] The core motivation (abstract and method description) relies on an analogy to Q-learning for inducing counterfactual data environments via adversarial augmentations, but no explicit reduction, equivalence, or mapping is shown equating the alternating GD-ascent objective to a Bellman operator, value iteration, or Q-update on the causal graph. Without this, the claim that the augmentations prevent collapse to an in-distribution learner and generate independent counterfactuals remains heuristic; the regularizer could reduce to standard adversarial training whose OoD benefit is not guaranteed by the construction.
- [Method] The alternating gradient descent-ascent algorithm (method section) is presented for solving the constrained optimization with label-invariant augmentations on causally generated graphs, yet it is unclear how label invariance is enforced during the ascent step or how the procedure ensures the induced environments are independent of the fitted model parameters rather than circularly dependent on them. This directly affects whether the OoD generalization claim holds beyond the reported experiments.
minor comments (2)
- [Abstract] Abstract contains a typo: 'convariate shift' should be 'covariate shift'.
- [Experiments] The experimental claims of 'high accuracy' and 'extensive experiments' would benefit from explicit reporting of error bars, statistical significance tests, and per-shift breakdowns in the results tables/figures to allow assessment of consistency.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the practical value of RIA as a compatible regularizer for OoD methods on graphs. We address the two major comments below by clarifying the intended role of the Q-learning analogy and the mechanics of the alternating optimization. We will incorporate revisions to improve clarity without altering the core claims or experiments.
read point-by-point responses
-
Referee: [Abstract / Method] The core motivation (abstract and method description) relies on an analogy to Q-learning for inducing counterfactual data environments via adversarial augmentations, but no explicit reduction, equivalence, or mapping is shown equating the alternating GD-ascent objective to a Bellman operator, value iteration, or Q-update on the causal graph. Without this, the claim that the augmentations prevent collapse to an in-distribution learner and generate independent counterfactuals remains heuristic; the regularizer could reduce to standard adversarial training whose OoD benefit is not guaranteed by the construction.
Authors: The Q-learning analogy is explicitly motivational, as stated in the abstract and method: it draws a parallel between an agent exploring actions to discover high-reward policies across states and our adversarial augmentations exploring label-invariant graph perturbations to create diverse counterfactual environments that the learner must handle. We do not claim or derive a formal reduction to the Bellman operator or value iteration, nor do we equate the GD-ascent objective to a Q-update; the paper presents the approach as an analogy to motivate the exploration of counterfactuals that prevent collapse to the training distribution. To strengthen this, we will revise the method section to explicitly label the connection as an analogy, explain the intended parallel (exploration of environments while preserving labels), and add a brief discussion distinguishing RIA from generic adversarial training via its integration with constrained OoD objectives and the label-invariance requirement. The OoD improvements are supported empirically across synthetic and natural shifts rather than by theoretical equivalence. revision: partial
-
Referee: [Method] The alternating gradient descent-ascent algorithm (method section) is presented for solving the constrained optimization with label-invariant augmentations on causally generated graphs, yet it is unclear how label invariance is enforced during the ascent step or how the procedure ensures the induced environments are independent of the fitted model parameters rather than circularly dependent on them. This directly affects whether the OoD generalization claim holds beyond the reported experiments.
Authors: Label invariance is enforced by restricting the augmentation operator (in both the formulation and the ascent step) to graph transformations that are known or constrained to preserve the label, such as structure-preserving perturbations on causally generated graphs (e.g., edge additions/deletions that do not alter the target property). This constraint is part of the constrained optimization problem solved by the alternating procedure. The ascent step maximizes the loss over valid label-invariant augmentations, while the descent step retrains the model on the resulting environments; the alternation decouples the dependence by iterating the two steps to convergence, so that the final model is not circularly tied to a fixed set of augmentations. We agree the current description is terse and will add pseudocode plus an expanded paragraph in the revised method section detailing the constraint enforcement and alternation to make the independence explicit. revision: yes
Circularity Check
No circularity; standard adversarial optimization with heuristic motivation
full rationale
The paper introduces RIA as an adversarial regularization technique for OoD graph classification under covariate shift, solved via alternating gradient descent-ascent on a constrained optimization problem. This is a conventional algorithmic approach that does not reduce to its own inputs by construction, nor does it rely on self-citations, uniqueness theorems from prior author work, or renaming of known results. The Q-learning analogy is used only for motivational framing of counterfactual environments and label-invariant augmentations; no equations or derivations equate the objective to a Bellman operator or force the outcome by definition. The method augments existing OoD baselines without tautological fitting or self-referential premises.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Out-of-distribution generalization on graphs: A survey.arXiv preprint arXiv:2202.07987,
Haoyang Li, Xin Wang, Ziwei Zhang, and Wenwu Zhu. Out-of-distribution generalization on graphs: A survey.arXiv preprint arXiv:2202.07987,
-
[2]
Towards out-of-distribution generalization: A survey.arXiv preprint arXiv:2108.13624, 2021
Zheyan Shen, Jiashuo Liu, Yue He, Xingxuan Zhang, Renzhe Xu, Han Yu, and Peng Cui. Towards out-of- distribution generalization: A survey.arXiv preprint arXiv:2108.13624,
-
[3]
Martin Arjovsky, Léon Bottou, Ishaan Gulrajani, and David Lopez-Paz. Invariant risk minimization.arXiv preprint arXiv:1907.02893,
work page internal anchor Pith review arXiv 1907
-
[4]
John Duchi, Peter Glynn, and Hongseok Namkoong. Statistics of robust optimization: A generalized empirical likelihood approach.arXiv preprint arXiv:1610.03425,
-
[5]
Aman Sinha, Hongseok Namkoong, Riccardo V olpi, and John Duchi. Certifying some distributional robustness with principled adversarial training.arXiv preprint arXiv:1710.10571,
-
[6]
Discovering invariant rationales for graph neural networks.arXiv preprint arXiv:2201.12872, 2022
Morgan-Kaufmann, 1991a. URL https://proceedings.neurips.cc/paper/1991/file/ ff4d5fbbafdf976cfdc032e3bde78de5-Paper.pdf. Ying-Xin Wu, Xiang Wang, An Zhang, Xiangnan He, and Tat-Seng Chua. Discovering invariant rationales for graph neural networks.arXiv preprint arXiv:2201.12872,
-
[7]
Risk variance penalization.arXiv preprint arXiv:2006.07544,
Chuanlong Xie, Haotian Ye, Fei Chen, Yue Liu, Rui Sun, and Zhenguo Li. Risk variance penalization.arXiv preprint arXiv:2006.07544,
-
[8]
Robustbench: a standardized adversarial robustness benchmark
Francesco Croce, Maksym Andriushchenko, Vikash Sehwag, Edoardo Debenedetti, Nicolas Flammarion, Mung Chiang, Prateek Mittal, and Matthias Hein. Robustbench: a standardized adversarial robustness benchmark.arXiv preprint arXiv:2010.09670,
-
[9]
Intriguing properties of neural networks
Christian Szegedy, Wojciech Zaremba, Ilya Sutskever, Joan Bruna, Dumitru Erhan, Ian Goodfellow, and Rob Fergus. Intriguing properties of neural networks.arXiv preprint arXiv:1312.6199,
work page internal anchor Pith review arXiv
-
[10]
Explaining and Harnessing Adversarial Examples
Ian J Goodfellow, Jonathon Shlens, and Christian Szegedy. Explaining and harnessing adversarial examples. arXiv preprint arXiv:1412.6572,
work page internal anchor Pith review arXiv
-
[11]
Can machine learning be secure? InProceedings of the 2006 ACM Symposium on Information, computer and communications security, pages 16–25,
Marco Barreno, Blaine Nelson, Russell Sears, Anthony D Joseph, and J Doug Tygar. Can machine learning be secure? InProceedings of the 2006 ACM Symposium on Information, computer and communications security, pages 16–25,
2006
-
[12]
Simon Zhang, Cheng Xin, and Tamal K Dey. Expressive higher-order link prediction through hypergraph symmetry breaking.arXiv preprint arXiv:2402.11339,
-
[13]
Good: A graph out-of-distribution benchmark.arXiv preprint arXiv:2206.08452,
Shurui Gui, Xiner Li, Limei Wang, and Shuiwang Ji. Good: A graph out-of-distribution benchmark.arXiv preprint arXiv:2206.08452,
-
[14]
Deep coral: Correlation alignment for deep domain adaptation
Baochen Sun and Kate Saenko. Deep coral: Correlation alignment for deep domain adaptation. InComputer Vision–ECCV 2016 Workshops: Amsterdam, The Netherlands, October 8-10 and 15-16, 2016, Proceedings, Part III 14, pages 443–450. Springer,
2016
-
[15]
Domain-adversarial training of neural networks.The journal of machine learning research, 17(1):2096–2030,
Yaroslav Ganin, Evgeniya Ustinova, Hana Ajakan, Pascal Germain, Hugo Larochelle, François Laviolette, Mario Marchand, and Victor Lempitsky. Domain-adversarial training of neural networks.The journal of machine learning research, 17(1):2096–2030,
2096
-
[16]
Shiori Sagawa, Pang Wei Koh, Tatsunori B Hashimoto, and Percy Liang. Distributionally robust neural networks for group shifts: On the importance of regularization for worst-case generalization.arXiv preprint arXiv:1911.08731,
work page internal anchor Pith review arXiv 1911
-
[17]
Mixup for node and graph classification
Yiwei Wang, Wei Wang, Yuxuan Liang, Yujun Cai, and Bryan Hooi. Mixup for node and graph classification. InProceedings of the Web Conference 2021, pages 3663–3674,
2021
-
[18]
URL https://openreview.net/forum?id=Hkx1qkrKPr. 17 RIA: Regularization for Invariance with Adversarial Training Meng Liu, Youzhi Luo, Limei Wang, Yaochen Xie, Hao Yuan, Shurui Gui, Haiyang Yu, Zhao Xu, Jingtun Zhang, Yi Liu, Keqiang Yan, Haoran Liu, Cong Fu, Bora M Oztekin, Xuan Zhang, and Shuiwang Ji. DIG: A turnkey library for diving into graph deep lea...
2013
-
[19]
It is curated by Gui et al
Dataset is derived from the MNIST dataset from computer vision. It is curated by Gui et al. [2022]. Digits are colored according to their domains. Specifically, in covariate shift split, we color digits with 7 different colors, and digits with the first 5 colors, the 6th color, and the 7th color are categorized into training, validation, and test sets. • ...
2022
-
[20]
Instead of combining the base-label spurious correlations and size covariate shift together as in Wu et al
Each graph in the dataset is generated by connecting a base graph and a motif, and the label is determined by the motif solely. Instead of combining the base-label spurious correlations and size covariate shift together as in Wu et al. [2022], the size and basis shifts are separated. Specifically, we generate graphs using five label irrelevant base graphs...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.