Recognition: no theorem link
TTVS: Boosting Self-Exploring Reinforcement Learning via Test-time Variational Synthesis
Pith reviewed 2026-05-10 18:16 UTC · model grok-4.3
The pith
Test-time variational synthesis lets reasoning models outperform supervised RL using only unlabeled data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
TTVS enables large reasoning models to self-evolve at test time by augmenting the training stream from unlabeled queries: Online Variational Synthesis produces diverse but meaning-preserving variants, while Test-time Hybrid Exploration trades off accuracy and cross-variant consistency, yielding higher performance than supervised baselines.
What carries the argument
TTVS framework whose two modules are Online Variational Synthesis, which converts static test queries into a dynamic stream of semantically equivalent variations, and Test-time Hybrid Exploration, which balances accuracy exploitation with consistency-driven exploration.
If this is right
- Models can improve on novel or specialized tasks without any labeled training data.
- Overfitting to textual phrasing is reduced because the model must succeed across multiple equivalent phrasings.
- Test-time adaptation can exceed the performance of large-scale supervised RLVR pipelines.
- The same unlabeled query set can be reused dynamically to create an effectively infinite training stream.
Where Pith is reading between the lines
- The approach may generalize to other self-supervised regimes where test-time data can be mutated without external labels.
- If the synthesis step proves robust, it could lower the data-labeling cost barrier for deploying reasoning models in new domains.
- Hybrid exploitation-exploration at inference time may become a standard substitute for pre-training data volume.
Load-bearing premise
That automatically generated variations of a query will reliably push the model to discover the true problem logic rather than new superficial patterns.
What would settle it
A controlled test where TTVS is applied to queries whose surface forms can be varied without altering the underlying logic, yet accuracy fails to rise above a static-query baseline or drops when synthetic variants are removed.
Figures


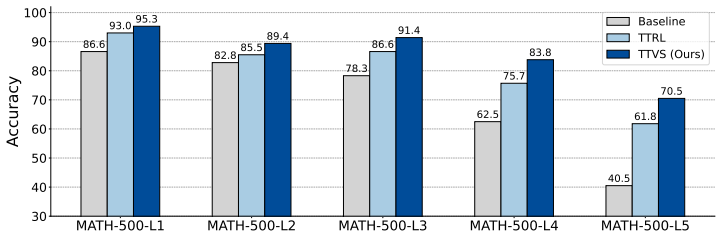



read the original abstract
Despite significant advances in Large Reasoning Models (LRMs) driven by reinforcement learning with verifiable rewards (RLVR), this paradigm is fundamentally limited in specialized or novel domains where such supervision is prohibitively expensive or unavailable, posing a key challenge for test-time adaptation. While existing test-time methods offer a potential solution, they are constrained by learning from static query sets, risking overfitting to textual patterns. To address this gap, we introduce Test-Time Variational Synthesis (TTVS), a novel framework that enables LRMs to self-evolve by dynamically augmenting the training stream from unlabeled test queries. TTVS comprises two synergistic modules: (1) Online Variational Synthesis, which transforms static test queries into a dynamic stream of diverse, semantically-equivalent variations, enforcing the model to learn underlying problem logic rather than superficial patterns; (2) Test-time Hybrid Exploration, which balances accuracy-driven exploitation with consistency-driven exploration across synthetic variants. Extensive experiments show TTVS yields superior performance across eight model architectures. Notably, using only unlabeled test-time data, TTVS not only surpasses other test-time adaptation methods but also outperforms state-of-the-art supervised RL-based techniques trained on vast, high-quality labeled data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Test-Time Variational Synthesis (TTVS) as a framework to enable Large Reasoning Models to self-evolve at test time using only unlabeled queries. It introduces two modules—an Online Variational Synthesis module that generates diverse semantically-equivalent variations of static test queries, and a Test-time Hybrid Exploration module that combines accuracy-driven exploitation with consistency-driven exploration—and claims that this yields superior performance across eight model architectures, outperforming both existing test-time adaptation methods and state-of-the-art supervised RLVR techniques trained on large labeled datasets.
Significance. If the empirical results hold, TTVS would be a notable contribution to test-time adaptation and self-improving reasoning systems by demonstrating that unlabeled data plus internal consistency signals can exceed supervised RL baselines. The approach directly targets the limitation of RLVR in domains lacking verifiable rewards, and the variational synthesis idea offers a concrete mechanism for moving beyond static query overfitting.
major comments (3)
- [Abstract] Abstract: the headline claim of outperforming supervised RLVR baselines trained on vast labeled data using only unlabeled test-time data is presented without any metrics, baselines, ablation studies, or experimental protocols, making it impossible to assess whether the data actually support the assertion.
- [§3] §3 (Online Variational Synthesis): the assertion that generated variants enforce learning of underlying problem logic rather than superficial textual patterns is stated without a formal argument or empirical test showing that semantic equivalence is preserved while diversity is sufficient to prevent collapse to consistent-but-incorrect policies.
- [§4] §4 (Experiments): no details are provided on how the hybrid exploration strategy is implemented, how balance between exploitation and exploration is maintained, or on the specific performance deltas versus supervised baselines, rendering the central outperformance claim unverifiable.
minor comments (2)
- [Abstract] The abstract uses 'self-evolve' without a precise definition in terms of the update rule or objective.
- [Abstract] Notation for the two modules is introduced but not consistently referenced in the high-level description.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. The comments highlight areas where additional clarity and detail will strengthen the manuscript, and we address each point below with plans for revision.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline claim of outperforming supervised RLVR baselines trained on vast labeled data using only unlabeled test-time data is presented without any metrics, baselines, ablation studies, or experimental protocols, making it impossible to assess whether the data actually support the assertion.
Authors: We agree that the abstract would be strengthened by including a few key quantitative indicators. In the revision we will add concise statements of average performance gains over the strongest test-time baselines and over supervised RLVR methods (with the exact numbers drawn from the main results table), while keeping the abstract within length limits. The full list of baselines, protocols, and ablations already appears in Section 4 and the appendix; we will add a forward reference in the abstract to these sections. revision: yes
-
Referee: [§3] §3 (Online Variational Synthesis): the assertion that generated variants enforce learning of underlying problem logic rather than superficial textual patterns is stated without a formal argument or empirical test showing that semantic equivalence is preserved while diversity is sufficient to prevent collapse to consistent-but-incorrect policies.
Authors: We will expand Section 3 with a short formal argument that the synthesis procedure (paraphrase generation followed by semantic-consistency filtering) preserves logical equivalence while increasing surface-form diversity. We will also add an empirical subsection reporting (i) average embedding cosine similarity between original and synthesized queries, (ii) lexical diversity metrics, and (iii) a controlled comparison showing that models trained on the synthesized stream exhibit lower accuracy on superficially altered but logically identical test items than models trained on static queries. These additions directly address the concern about collapse to consistent-but-incorrect policies. revision: yes
-
Referee: [§4] §4 (Experiments): no details are provided on how the hybrid exploration strategy is implemented, how balance between exploitation and exploration is maintained, or on the specific performance deltas versus supervised baselines, rendering the central outperformance claim unverifiable.
Authors: We acknowledge that the current description of the Test-time Hybrid Exploration module is high-level. The revised Section 4 will include (i) pseudocode for the hybrid selection rule, (ii) the precise weighting schedule between accuracy-driven exploitation and consistency-driven exploration (including the hyper-parameter values used in all reported runs), and (iii) an expanded results table that lists per-model accuracy deltas versus each supervised RLVR baseline. These changes will make the implementation and the magnitude of the reported gains fully verifiable. revision: yes
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper presents TTVS as a novel framework consisting of Online Variational Synthesis (generating dynamic semantically-equivalent variants from unlabeled test queries) and Test-time Hybrid Exploration (balancing exploitation and consistency-driven exploration). These modules are defined independently from the input data and do not reduce by construction to fitted parameters, prior self-citations, or renamed known results. The central claims rest on empirical performance across eight model architectures using only unlabeled test-time data, with no load-bearing steps that equate predictions to inputs via self-definition or self-citation chains. The method is self-contained against external benchmarks and does not invoke uniqueness theorems or ansatzes from overlapping prior work in a circular manner.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Reinforcement learning signals can be derived from consistency across semantically equivalent query variations without external labels
invented entities (2)
-
Online Variational Synthesis module
no independent evidence
-
Test-time Hybrid Exploration module
no independent evidence
Forward citations
Cited by 1 Pith paper
-
Entropy Polarity in Reinforcement Fine-Tuning: Direction, Asymmetry, and Control
Entropy polarity from a first-order entropy change approximation enables Polarity-Aware Policy Optimization (PAPO) that preserves complementary polarity branches and outperforms baselines on math and agentic RL fine-t...
Reference graph
Works this paper leans on
-
[1]
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
Test-time prompt tuning for zero-shot gener- alization in vision-language models.Advances in Neural Information Processing Systems, 35:14274– 14289. David Silver and Richard S Sutton. 2025. Welcome to the era of experience.Google AI, 1. Charlie Snell, Jaehoon Lee, Kelvin Xu, and Aviral Ku- mar. 2024. Scaling llm test-time compute optimally can be more eff...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Qwen3 technical report.arXiv preprint arXiv:2505.09388. An Yang, Beichen Zhang, Binyuan Hui, Bofei Gao, Bowen Yu, Chengpeng Li, Dayiheng Liu, Jianhong Tu, Jingren Zhou, Junyang Lin, and 1 others. 2024. Qwen2. 5-math technical report: Toward mathe- matical expert model via self-improvement.arXiv preprint arXiv:2409.12122. Rui Yang, Lin Song, Yanwei Li, Sij...
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.