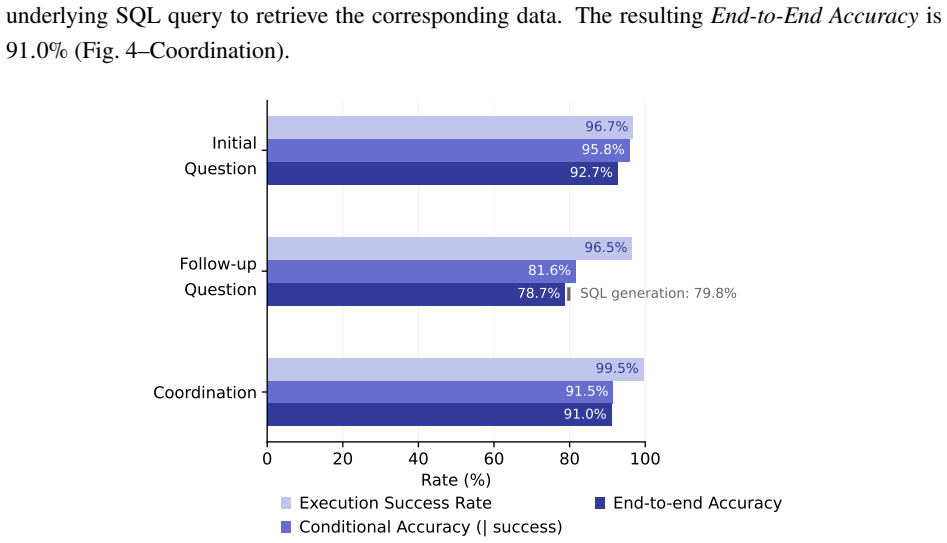
Recognition: unknown
Figures as Interfaces: Toward LLM-Native Artifacts for Scientific Discovery
Pith reviewed 2026-05-10 17:11 UTC · model grok-4.3
The pith
LLM-native figures embed full provenance to let models and users trace and extend scientific analyses.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
LLM-native figures are data-driven artifacts that are simultaneously human-legible and machine-addressable, each embedding complete provenance including the data subset, analytical operations and code, and visualization specification used to generate it. This enables an LLM to trace selections back to their sources, generate code to extend analyses, and orchestrate new visualizations through natural-language instructions or direct manipulation via a hybrid language-visual interface with bidirectional mapping. In the science of science domain, this leads to accelerated discovery, improved reproducibility, and transparent reasoning across agents and users, redefining the figure as an interface
What carries the argument
The hybrid language-visual interface integrating LLM agents with a bidirectional mapping between figures and their underlying data, code, and specifications.
If this is right
- Figures can serve as starting points for new analyses instead of endpoints.
- Provenance embedding makes all analytical steps explicitly accessible to LLMs.
- Natural language instructions suffice to modify or extend visualizations.
- Multi-agent systems benefit from shared, context-rich artifacts.
- Reproducibility gains follow from direct links to executable code and data.
Where Pith is reading between the lines
- Similar native artifacts could be developed for other research outputs such as tables or simulation results.
- Adoption might require new standards for figure formats that support provenance embedding.
- This framework could integrate with existing visualization libraries to make the transition easier.
- Long-term, it may influence how scientific papers are structured around interactive rather than static elements.
Load-bearing premise
A reliable bidirectional mapping between the rendered figure and its underlying data and code can be maintained without errors or constant human correction during LLM interactions.
What would settle it
A test case in which an LLM is asked to modify a figure's analysis and the resulting output is checked for fidelity to the original data and code without external fixes.
Figures




read the original abstract
Large language models (LLMs) are transforming scientific workflows, not only through their generative capabilities but also through their emerging ability to use tools, reason about data, and coordinate complex analytical tasks. Yet in most human-AI collaborations, the primary outputs, figures, are still treated as static visual summaries: once rendered, they are handled by both humans and multimodal LLMs as images to be re-interpreted from pixels or captions. The emergent capabilities of LLMs open an opportunity to fundamentally rethink this paradigm. In this paper, we introduce the concept of LLM-native figures: data-driven artifacts that are simultaneously human-legible and machine-addressable. Unlike traditional plots, each artifact embeds complete provenance: the data subset, analytical operations and code, and visualization specification used to generate it. As a result, an LLM can "see through" the figure--tracing selections back to their sources, generating code to extend analyses, and orchestrating new visualizations through natural-language instructions or direct manipulation. We implement this concept through a hybrid language-visual interface that integrates LLM agents with a bidirectional mapping between figures and underlying data. Using the science of science domain as a testbed, we demonstrate that LLM-native figures can accelerate discovery, improve reproducibility, and make reasoning transparent across agents and users. More broadly, this work establishes a general framework for embedding provenance, interactivity, and explainability into the artifacts of modern research, redefining the figure not as an end product, but as an interface for discovery. For more details, please refer to the demo video available at www.llm-native-figure.com.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LLM-native figures as data-driven artifacts that embed complete provenance (data subsets, code, analytical operations, and visualization specs) to enable bidirectional interaction between humans, LLMs, and the underlying data. Unlike static plots, these figures support tracing, code generation, and orchestration via natural-language instructions through a hybrid language-visual interface. Using a science-of-science testbed, the work claims to demonstrate accelerated discovery, improved reproducibility, and transparent reasoning across agents and users, establishing a general framework for provenance-embedded research artifacts.
Significance. If the bidirectional mapping can be shown to be robust, the framework could meaningfully advance human-AI scientific collaboration by redefining figures as active interfaces rather than passive outputs, with potential benefits for reproducibility and multi-agent workflows in data-intensive fields.
major comments (1)
- [Abstract / testbed demonstration] Abstract and science-of-science testbed demonstration: the central claim that LLM-native figures accelerate discovery, improve reproducibility, and make reasoning transparent rests on an asserted demonstration, yet the manuscript provides no quantitative metrics, error rates, or systematic analysis of failure modes (e.g., ambiguous instructions, data-subset drift after LLM edits, or visualization-spec inconsistencies). This leaves the reliability of the bidirectional mapping unverified and is load-bearing for the primary contribution.
minor comments (1)
- [Abstract] The demo video link is referenced but the manuscript text does not include sufficient standalone description of the interface mechanics or example interaction traces to allow readers to assess the hybrid mapping without external resources.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address the single major comment below, acknowledging where the current manuscript falls short and outlining specific revisions.
read point-by-point responses
-
Referee: [Abstract / testbed demonstration] Abstract and science-of-science testbed demonstration: the central claim that LLM-native figures accelerate discovery, improve reproducibility, and make reasoning transparent rests on an asserted demonstration, yet the manuscript provides no quantitative metrics, error rates, or systematic analysis of failure modes (e.g., ambiguous instructions, data-subset drift after LLM edits, or visualization-spec inconsistencies). This leaves the reliability of the bidirectional mapping unverified and is load-bearing for the primary contribution.
Authors: We agree that the science-of-science testbed demonstration is primarily qualitative and illustrative, consisting of worked examples that show provenance tracing, code generation, and natural-language orchestration rather than controlled quantitative evaluation. The manuscript does not report metrics such as task success rates, error rates, or systematic failure-mode analysis for issues like ambiguous instructions or post-edit data drift. This is a substantive limitation for claims about acceleration, reproducibility, and transparency. In the revised version we will add a dedicated evaluation subsection that (1) defines a set of representative tasks with success/failure criteria, (2) reports quantitative results (e.g., success rates over repeated trials, latency, and reproducibility scores), and (3) provides a categorized analysis of observed failure modes together with mitigation strategies. We will also make the testbed artifacts and query logs available to support reproducibility of the evaluation itself. revision: yes
Circularity Check
No significant circularity: conceptual framework with independent implementation and demonstration.
full rationale
The paper proposes LLM-native figures as a new class of artifacts embedding provenance for bidirectional LLM-human interaction. Its central claims rest on a definitional introduction of the concept, description of a hybrid language-visual interface, and empirical demonstration within a science-of-science testbed rather than any derivation chain. No equations, fitted parameters, or load-bearing self-citations appear that would reduce the claims to inputs by construction; the bidirectional mapping is presented as an implemented capability rather than a result derived from prior self-referential assumptions. The work is therefore self-contained against external benchmarks of reproducibility and transparency.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs can effectively use bidirectional mappings between rendered figures and underlying data/code for analysis extension
invented entities (1)
-
LLM-native figure
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Anscombe, F. J. Graphs in statistical analysis.The american statistician27, 17–21 (1973)
1973
-
[2]
Introducing deep research (2025)
OpenAI. Introducing deep research (2025). URLhttps://openai.com/index/int roducing-deep-research/. Accessed: 2026-02-09
2025
-
[3]
Gemini deep research (2025)
Gemini, G. Gemini deep research (2025). URLhttps://gemini.google/overvi ew/deep-research/?hl=en. Accessed: 2026-02-09
2025
-
[4]
Transforming r&d with agentic ai: Introducing microsoft discovery (2025)
Datar, A. Transforming r&d with agentic ai: Introducing microsoft discovery (2025). URL https://azure.microsoft.com/en-us/blog/transforming-rd-with-a gentic-ai-introducing-microsoft-discovery/. Accessed: 2026-02-09
2025
- [5]
-
[6]
Tu, T.et al.Towards conversational diagnostic artificial intelligence.Nature(2025)
2025
-
[7]
Harvey Professional Class AI (2025)
AI, H. Harvey Professional Class AI (2025). URLhttps://www.harvey.ai/. Accessed: 2026-02-09
2025
-
[8]
Lu, C.et al.The ai scientist: Towards fully automated open-ended scientific discovery.arXiv preprint arXiv:2408.06292(2024)
work page internal anchor Pith review arXiv 2024
-
[9]
Creating an executable paper is a journey through open science.Communications Physics(2020)
Lasser, J. Creating an executable paper is a journey through open science.Communications Physics(2020)
2020
-
[10]
& Goulier, L
Konkol, M., N¨ ust, D. & Goulier, L. Publishing computational research-a review of infras- tructures for reproducible and transparent scholarly communication.Research integrity and peer review(2020)
2020
-
[11]
& Bora, A
Ziemann, M., Poulain, P. & Bora, A. The five pillars of computational reproducibility: bioinformatics and beyond.Briefings in Bioinformatics(2023)
2023
-
[12]
A publishing platform that places code front and centre (2025)
Nature. A publishing platform that places code front and centre (2025). URLhttps: //www.nature.com/articles/d41586-024-02577-1. Accessed: 2026-02-09
2025
-
[13]
Pioneering ’live-code’ article allows scientists to play with each other’s results (2025)
Nature. Pioneering ’live-code’ article allows scientists to play with each other’s results (2025). URLhttps://www.nature.com/articles/d41586-019-00724-7. Accessed: 2026-02-09
2025
-
[14]
InProceedings of the 2017 symposium on cloud computing, 405–418 (2017)
Pasquier, T.et al.Practical whole-system provenance capture. InProceedings of the 2017 symposium on cloud computing, 405–418 (2017)
2017
-
[15]
C., Arnold, C., Gur, Y
Rupprecht, L., Davis, J. C., Arnold, C., Gur, Y. & Bhagwat, D. Improving reproducibility of data science pipelines through transparent provenance capture.Proceedings of the VLDB Endowment(2020)
2020
-
[16]
Direct manipulation: A step beyond programming languages.Computer (1983)
Shneiderman, B. Direct manipulation: A step beyond programming languages.Computer (1983)
1983
-
[17]
Ware, C.Information visualization: perception for design(Morgan Kaufmann, 2019)
2019
-
[18]
InInformation visual- ization: Human-centered issues and perspectives, 154–175 (Springer, 2008)
Keim, D.et al.Visual analytics: Definition, process, and challenges. InInformation visual- ization: Human-centered issues and perspectives, 154–175 (Springer, 2008)
2008
-
[19]
Munzner, T.Visualization analysis and design(CRC press, 2014). 24
2014
- [20]
-
[21]
InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing(Association for Computational Linguistics, 2024)
Zhang, Y.et al.A comprehensive survey of scientific large language models and their applications in scientific discovery. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing(Association for Computational Linguistics, 2024)
2024
-
[22]
Wang, H.et al.Scientific discovery in the age of artificial intelligence.Nature620, 47–60 (2023)
2023
-
[23]
ACM Computing Surveys57, 1–38 (2025)
Zhang, Q.et al.Scientific large language models: A survey on biological & chemical domains. ACM Computing Surveys57, 1–38 (2025)
2025
-
[24]
& Buehler, M
Ghafarollahi, A. & Buehler, M. J. SciAgents: automating scientific discovery through bioin- spired multi-agent intelligent graph reasoning.Advanced Materials(2025)
2025
-
[25]
Zheng, Y.et al.Large language models for scientific discovery in molecular property predic- tion.Nature Machine Intelligence1–11 (2025)
2025
-
[26]
Maojun, S.et al.A survey on large language model-based agents for statistics and data science.The American Statistician1–21 (2025)
2025
-
[27]
P.et al.Data analysis in the era of generative ai.arXiv preprint arXiv:2409.18475 (2024)
Inala, J. P.et al.Data analysis in the era of generative ai.arXiv preprint arXiv:2409.18475 (2024)
-
[28]
arXiv preprint arXiv:2412.14222(2024)
Sun, M.et al.A survey on large language model-based agents for statistics and data science. arXiv preprint arXiv:2412.14222(2024)
- [29]
- [30]
-
[31]
Wang, D.et al.Human-ai collaboration in data science: Exploring data scientists’ perceptions of automated ai.Proceedings of the ACM on human-computer interaction3, 1–24 (2019)
2019
-
[32]
S., Zhu, K
Manning, B. S., Zhu, K. & Horton, J. J. Automated social science: Language models as scientist and subjects. Tech. Rep., National Bureau of Economic Research (2024)
2024
- [33]
- [34]
-
[35]
Huang, K.et al.Biomni: A general-purpose biomedical AI agent.biorxiv(2025)
2025
-
[36]
Sphinx: Enabling data science across academia
Sphinx. Sphinx: Enabling data science across academia. (2026). URLhttps://www.sp hinx.ai. Accessed: 2026-02-09
2026
-
[37]
Introducing observable canvases a collaborative, visual, spatial medium for data analysis (2026)
Observable. Introducing observable canvases a collaborative, visual, spatial medium for data analysis (2026). URLhttps://observablehq.com/blog/introducing-can vases-early-access. Accessed: 2026-02-09
2026
- [38]
-
[39]
Plottie: Free to explore, collect and inspire your next figure
Plottie. Plottie: Free to explore, collect and inspire your next figure. discover high-quality scientific plots from open-access literature. (2026). URLhttps://plottie.art/. Accessed: 2026-02-09
2026
-
[40]
Lu, C.et al.Towards end-to-end automation of ai research.Nature651, 914–919 (2026)
2026
-
[41]
& Wang, D
Wang, Y., Qian, Y., Qi, X., Cao, N. & Wang, D. Innovationinsights: A visual analytics approach for understanding the dual frontiers of science and technology.IEEE Transactions on Visualization and Computer Graphics30, 518–528 (2023)
2023
- [42]
-
[43]
Introducing Observable Canvases (2025)
Bostock, M. Introducing Observable Canvases (2025). URLhttps://observablehq .com/blog/introducing-canvases-early-access. Accessed: 2026-02-09
2025
-
[44]
& Lee, B
Wang, C., Thompson, J. & Lee, B. Data Formulator: Ai-powered concept-driven visualization authoring.IEEE Transactions on Visualization and Computer Graphics30, 1128–1138 (2023)
2023
-
[45]
M., Marshall, D
Wang, C., Lee, B., Drucker, S. M., Marshall, D. & Gao, J. Data Formulator 2: Iterative creation of data visualizations, with ai transforming data along the way. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems, 1–17 (2025)
2025
-
[46]
Tableau Agent (2025)
Tableau. Tableau Agent (2025). URLhttps://www.tableau.com/products/tab leau-agent. Accessed: 2026-02-09. 26
2025
-
[47]
IEEE Transactions on Visualization and Computer Graphics(2024)
Tian, Y.et al.Chartgpt: Leveraging llms to generate charts from abstract natural language. IEEE Transactions on Visualization and Computer Graphics(2024)
2024
-
[48]
& Wang, Y
Wang, L., Zhang, S., Wang, Y., Lim, E.-P. & Wang, Y. LLM4Vis: Explainable visualization recommendation using ChatGPT. In Wang, M. & Zitouni, I. (eds.)Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing
2023
-
[49]
LIDA: A tool for automatic generation of grammar-agnostic visualizations and infographics using large language models
Dibia, V. LIDA: A tool for automatic generation of grammar-agnostic visualizations and infographics using large language models. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics(Association for Computational Linguistics, 2023)
2023
-
[50]
Zhao, Y.et al.LightV A: Lightweight visual analytics with llm agent-based task planning and execution.IEEE Transactions on Visualization and Computer Graphics(2024)
2024
-
[51]
Zhao, Y.et al.LA V A: Using large language models to enhance visual analytics.IEEE transactions on visualization and computer graphics(2024)
2024
- [52]
- [53]
-
[54]
In Extended Abstracts of the CHI Conference on Human Factors in Computing Systems(2024)
Gao, J.et al.A taxonomy for human-llm interaction modes: An initial exploration. In Extended Abstracts of the CHI Conference on Human Factors in Computing Systems(2024)
2024
-
[55]
Shen, L., Li, H., Wang, Y., Xie, X. & Qu, H. Prompting generative ai with interaction- augmented instructions. InExtended Abstracts of the CHI Conference on Human Factors in Computing Systems, 1–9 (2025)
2025
-
[56]
& Gadiraju, U
He, G., Demartini, G. & Gadiraju, U. Plan-then-execute: An empirical study of user trust and team performance when using llm agents as a daily assistant. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems(2025)
2025
-
[57]
Shen, L., Wang, Y., Qu, H., Xie, X. & Li, H. Interaction-augmented instruction: Modeling the synergy of prompts and interactions in human-genai collaboration. InCHI 2026(2026)
2026
- [58]
-
[59]
Generative Interfaces for Language Models
Chen, J., Zhang, Y., Zhang, Y., Shao, Y. & Yang, D. Generative interfaces for language models.arXiv preprint arXiv:2508.19227(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[60]
ChatGPT Canvas (2025)
ChatGPT. ChatGPT Canvas (2025). URLhttps://openai.com/index/introdu cing-canvas/. Accessed: 2026-02-09
2025
-
[61]
What are artifacts and how do i use them? (2025)
Claude. What are artifacts and how do i use them? (2025). URLhttps://support.cl aude.com/en/articles/9487310-what-are-artifacts-and-how-do-i -use-them. Accessed: 2026-02-09
-
[62]
& Xia, H
Cao, Y., Jiang, P. & Xia, H. Generative and malleable user interfaces with generative and evolving task-driven data model. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems(2025)
2025
-
[63]
& Xia, H
Suh, S., Min, B., Palani, S. & Xia, H. Sensecape: Enabling multilevel exploration and sensemaking with large language models. InProceedings of the 36th annual ACM symposium on user interface software and technology, 1–18 (2023)
2023
-
[64]
You, W.et al.DesignManager: An agent-powered copilot for designers to integrate ai design tools into creative workflows.ACM Transactions on Graphics (TOG)(2025)
2025
-
[65]
Get to know BigQuery data canvas: an ai-centric experience to reimagine data analytics (2025)
BigQuery, G. Get to know BigQuery data canvas: an ai-centric experience to reimagine data analytics (2025). URLhttps://cloud.google.com/blog/products/data-a nalytics/get-to-know-bigquery-data-canvas. Accessed: 2026-02-09
2025
-
[66]
& Heer, J
Satyanarayan, A., Moritz, D., Wongsuphasawat, K. & Heer, J. Vega-lite: A grammar of interactive graphics.IEEE transactions on visualization and computer graphics23, 341–350 (2016)
2016
-
[67]
& Jones, B
Ahmadpoor, M. & Jones, B. F. The dual frontier: Patented inventions and prior scientific advance.Science357, 583–587 (2017)
2017
-
[68]
Liang, W., Elrod, S., McFarland, D. A. & Zou, J. Systematic analysis of 50 years of stanford university technology transfer and commercialization.Patterns3(2022)
2022
-
[69]
& Jones, B
Yin, Y., Dong, Y., Wang, K., Wang, D. & Jones, B. F. Public use and public funding of science.Nature human behaviour6, 1344–1350 (2022)
2022
-
[70]
Tripodi, G.et al.Tenure and research trajectories.Proceedings of the National Academy of Sciences122, e2500322122 (2025). 28
2025
-
[71]
InInternational Conference on Learning Representations (ICLR)(2023)
Yao, S.et al.React: Synergizing reasoning and acting in language models. InInternational Conference on Learning Representations (ICLR)(2023)
2023
-
[72]
Advances in neural information processing systems36, 11809–11822 (2023)
Yao, S.et al.Tree of thoughts: Deliberate problem solving with large language models. Advances in neural information processing systems36, 11809–11822 (2023)
2023
-
[73]
Schick, T.et al.Toolformer: Language models can teach themselves to use tools.Advances in Neural Information Processing Systems36, 68539–68551 (2023)
2023
-
[74]
Madaan, A.et al.Self-refine: Iterative refinement with self-feedback.Advances in Neural Information Processing Systems36, 46534–46594 (2023)
2023
-
[75]
& Yao, S
Shinn, N., Cassano, F., Gopinath, A., Narasimhan, K. & Yao, S. Reflexion: Language agents with verbal reinforcement learning.Advances in Neural Information Processing Systems36, 8634–8652 (2023)
2023
- [76]
-
[77]
Chen, Q.et al.Vizlinter: A linter and fixer framework for data visualization.IEEE transactions on visualization and computer graphics28, 206–216 (2021)
2021
- [78]
-
[79]
Hong, Z.et al.Next-generation database interfaces: A survey of llm-based text-to-sql.IEEE Transactions on Knowledge and Data Engineering(2025)
2025
-
[80]
IEEE Transactions on Visualization and Computer Graphics28, 5049–5070 (2021)
Wu, A.et al.AI4VIS: Survey on artificial intelligence approaches for data visualization. IEEE Transactions on Visualization and Computer Graphics28, 5049–5070 (2021)
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.