Recognition: 2 theorem links
· Lean TheoremUniversalVTG: A Universal and Lightweight Foundation Model for Video Temporal Grounding
Pith reviewed 2026-05-10 17:52 UTC · model grok-4.3
The pith
A single lightweight model for video temporal grounding outperforms specialized models across many datasets and matches much larger approaches.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
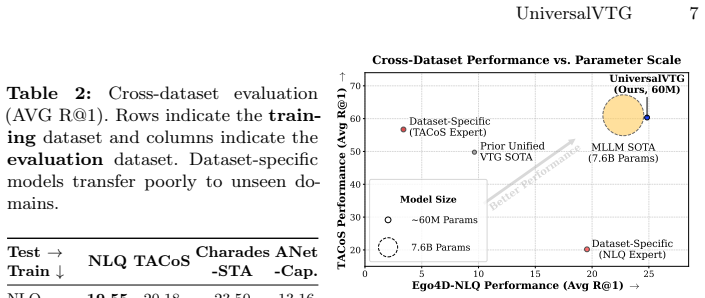
UniversalVTG is a single VTG model trained with large-scale cross-dataset pretraining. An offline Query Unifier canonicalizes heterogeneous query formats into a shared declarative space, reducing linguistic mismatch and preventing negative transfer observed under naive joint training. Combined with an efficient grounding head, UniversalVTG scales to long untrimmed videos. One checkpoint achieves state-of-the-art performance versus dedicated VTG models on GoalStep-StepGrounding, Ego4D-NLQ, TACoS, Charades-STA, and ActivityNet-Captions, and matches or exceeds accuracy of recent MLLM-based approaches despite being over 100 times smaller.
What carries the argument
The offline Query Unifier that converts heterogeneous query formats into a shared declarative space, paired with an efficient grounding head that enables scaling to long videos.
If this is right
- One trained checkpoint delivers strong results on GoalStep-StepGrounding, Ego4D-NLQ, TACoS, Charades-STA, and ActivityNet-Captions without needing separate models per dataset.
- The model handles long untrimmed videos without the context limits that affect larger language-model methods.
- Negative transfer from naive joint training on multiple datasets is avoided through query standardization.
- It supplies a low-compute alternative to parameter-heavy multimodal language model methods for the same grounding task.
Where Pith is reading between the lines
- The same query standardization step could help other multimodal tasks that currently suffer when datasets use incompatible input formats.
- Input normalization may prove more critical than increasing model size for achieving reliable cross-domain performance in temporal grounding.
- The compact size opens the door to running accurate video moment search directly on phones or edge devices.
Load-bearing premise
Converting different query formats into one shared space preserves all information needed for accurate moment localization without introducing errors.
What would settle it
Remove the Query Unifier, retrain on the same mixed datasets, and check whether accuracy falls on benchmarks that contain varied query styles compared to the full model.
Figures


read the original abstract
Video temporal grounding (VTG) is typically tackled with dataset-specific models that transfer poorly across domains and query styles. Recent efforts to overcome this limitation have adapted large multimodal language models (MLLMs) to VTG, but their high compute cost and limited video context still hinder long-video grounding. We instead scale unified supervision while keeping the model lightweight. We present UniversalVTG, a single VTG model trained with large-scale cross-dataset pretraining. An offline Query Unifier canonicalizes heterogeneous query formats into a shared declarative space, reducing linguistic mismatch and preventing the negative transfer observed under na\"ive joint training. Combined with an efficient grounding head, UniversalVTG scales to long, untrimmed videos. Across diverse benchmarks-GoalStep-StepGrounding, Ego4D-NLQ, TACoS, Charades-STA, and ActivityNet-Captions-one UniversalVTG checkpoint achieves state-of-the-art performance versus dedicated VTG models. Moreover, despite being $>100\times$ smaller than recent MLLM-based approaches, UniversalVTG matches or exceeds their accuracy on multiple benchmarks, offering a practical alternative to parameter-heavy MLLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces UniversalVTG, a single lightweight model for video temporal grounding (VTG) trained via large-scale cross-dataset pretraining. It employs an offline Query Unifier to canonicalize heterogeneous query formats into a shared declarative space and pairs this with an efficient grounding head to handle long untrimmed videos. The central claim is that one UniversalVTG checkpoint achieves state-of-the-art results against dedicated VTG models on GoalStep-StepGrounding, Ego4D-NLQ, TACoS, Charades-STA, and ActivityNet-Captions while matching or exceeding the accuracy of MLLM-based approaches that are >100× larger.
Significance. If the empirical claims are substantiated with full results, ablations, and training details, the work would be significant for demonstrating that unified supervision plus query canonicalization can yield a practical, parameter-efficient foundation model for VTG. This would offer a scalable alternative to heavy MLLMs and reduce negative transfer across query styles and domains, with potential impact on long-video understanding applications.
major comments (2)
- [Abstract] Abstract: the manuscript asserts SOTA performance and parity with much larger MLLMs across five benchmarks, yet provides no quantitative metrics, tables, error bars, ablation studies, or training hyperparameters. Without these, the central empirical claim cannot be evaluated and the soundness assessment remains low.
- [Abstract] Query Unifier description (inferred from abstract): the assumption that an offline canonicalizer reduces linguistic mismatch without introducing information loss or errors that degrade grounding accuracy is load-bearing for the no-negative-transfer claim, but no ablation isolating its contribution or error analysis on query reformulation is referenced.
minor comments (2)
- [Abstract] The abstract mentions 'large-scale cross-dataset pretraining' without specifying the datasets, sampling strategy, or loss weighting used to combine them.
- [Abstract] Notation for the grounding head and its efficiency claims (e.g., how it scales to long videos) would benefit from a brief equation or complexity statement even in the abstract.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments highlight opportunities to make the abstract more self-contained and to strengthen the empirical support for the Query Unifier. We address each point below and will incorporate revisions in the next version of the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the manuscript asserts SOTA performance and parity with much larger MLLMs across five benchmarks, yet provides no quantitative metrics, tables, error bars, ablation studies, or training hyperparameters. Without these, the central empirical claim cannot be evaluated and the soundness assessment remains low.
Authors: We agree that the abstract should include key quantitative highlights so that the central claims can be assessed without immediately consulting the full text. The manuscript body already contains the requested elements: Table 1 reports mIoU and R@1 scores with standard deviations across all five benchmarks, Tables 2-3 present comparisons to dedicated VTG models and MLLM baselines (including parameter counts showing the >100× size reduction), Section 4.3 contains ablations, figures include error bars, and hyperparameters plus training details appear in Appendix A. We will revise the abstract to insert concise performance numbers (e.g., average mIoU gains and model-size comparison) while preserving its length constraints. revision: yes
-
Referee: [Abstract] Query Unifier description (inferred from abstract): the assumption that an offline canonicalizer reduces linguistic mismatch without introducing information loss or errors that degrade grounding accuracy is load-bearing for the no-negative-transfer claim, but no ablation isolating its contribution or error analysis on query reformulation is referenced.
Authors: The Query Unifier is indeed central to avoiding negative transfer. Section 3.2 describes its offline operation and Section 4.2 reports the performance difference between naïve joint training and training with the Unifier, which supports the claim of reduced negative transfer. However, we did not provide an isolated ablation that removes only the Unifier while keeping all other components fixed, nor a quantitative error analysis of the reformulation step (e.g., semantic fidelity metrics on a held-out query set). We will add both: a dedicated ablation table isolating the Unifier’s contribution and a short error analysis subsection reporting reformulation accuracy and downstream impact on grounding metrics. revision: yes
Circularity Check
No significant circularity; empirical claims rest on external benchmarks
full rationale
The paper presents an empirical architecture (offline Query Unifier + lightweight grounding head + cross-dataset pretraining) whose central claims are validated through independent benchmark evaluations on GoalStep-StepGrounding, Ego4D-NLQ, TACoS, Charades-STA, and ActivityNet-Captions. No mathematical derivation chain, fitted-parameter predictions, or self-citation load-bearing steps are present in the provided text. The performance assertions are falsifiable against held-out datasets and external models rather than reducing to internal definitions or ansatzes.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Heterogeneous query formats can be canonicalized into a shared declarative space without significant information loss
invented entities (2)
-
Query Unifier
no independent evidence
-
Efficient grounding head
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We instead scale unified supervision while keeping the model lightweight.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2510.23043 (2025)
An, J., Grauman, K.: Hieramamba: Video temporal grounding via hierarchical anchor-mamba pooling. arXiv preprint arXiv:2510.23043 (2025)
-
[2]
In: ICCV
Anne Hendricks, L., Wang, O., Shechtman, E., Sivic, J., Darrell, T., Russell, B.: Localizing moments in video with natural language. In: ICCV. pp. 5803–5812 (2017)
2017
-
[3]
Bai, S., Cai, Y., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., et al.: Qwen3-vl technical report. arXiv preprint arXiv:2511.21631 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Bertasius, G., Wang, H., Torresani, L.: Is space-time attention all you need for video understanding? In: ICML. vol. 2, p. 4 (2021)
2021
-
[5]
Perception Encoder: The best visual embeddings are not at the output of the network
Bolya, D., Huang, P.Y., Sun, P., Cho, J.H., Madotto, A., Wei, C., Ma, T., Zhi, J., Rajasegaran, J., Rasheed, H., et al.: Perception encoder: The best visual embeddings are not at the output of the network. arXiv preprint arXiv:2504.13181 (2025)
work page internal anchor Pith review arXiv 2025
-
[6]
In: ECCV (2020)
Carion, N., Massa, F., Synnaeve, G., Usunier, N., Kirillov, A., Zagoruyko, S.: End-to-end object detection with transformers. In: ECCV (2020)
2020
-
[7]
Chen, S., Lan, X., Yuan, Y., Jie, Z., Ma, L.: Timemarker: A versatile video-llm for long and short video understanding with superior temporal localization ability. arXiv preprint arXiv:2411.18211 (2024)
-
[8]
In: Proceedings of the 31st ACM International Conference on Multimedia
Chen, Z., Jiang, X., Xu, X., Cao, Z., Mo, Y., Shen, H.T.: Joint searching and grounding: Multi-granularity video content retrieval. In: Proceedings of the 31st ACM International Conference on Multimedia. pp. 975–983 (2023)
2023
-
[9]
Clark, C., Zhang, J., Ma, Z., Park, J.S., Salehi, M., Tripathi, R., Lee, S., Ren, Z., Kim, C.D., Yang, Y., et al.: Molmo2: Open weights and data for vision-language models with video understanding and grounding. arXiv preprint arXiv:2601.10611 (2026)
-
[10]
In: ICCV
Feichtenhofer, C., Fan, H., Malik, J., He, K.: Slowfast networks for video recognition. In: ICCV. pp. 6202–6211 (2019)
2019
-
[11]
In: CVPR
Feng, Y., Zhang, H., Liu, M., Guan, W., Nie, L.: Object-shot enhanced grounding network for egocentric video. In: CVPR. pp. 24190–24200 (2025)
2025
-
[12]
In: ICCV
Gao, J., Sun, C., Yang, Z., Nevatia, R.: Tall: Temporal activity localization via language query. In: ICCV. pp. 5267–5275 (2017)
2017
-
[13]
arXiv preprint arXiv:1904.02755 (2019)
Ghosh,S.,Agarwal,A.,Parekh,Z.,Hauptmann,A.:Excl:Extractivecliplocalization using natural language descriptions. arXiv preprint arXiv:1904.02755 (2019)
-
[14]
arXiv preprint arXiv:2410.01615 (2024)
Gordeev, A., Dokholyan, V., Tolstykh, I., Kuprashevich, M.: Saliency-guided detr for moment retrieval and highlight detection. arXiv preprint arXiv:2410.01615 (2024)
-
[15]
Grattafiori, A., Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Letman, A., Mathur, A., Schelten, A., Vaughan, A., et al.: The llama 3 herd of models. arXiv preprint arXiv:2407.21783 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
In: CVPR
Grauman, K., Westbury, A., Byrne, E., Chavis, Z., Furnari, A., Girdhar, R., Hamburger, J., Jiang, H., Liu, M., Liu, X., et al.: Ego4d: Around the world in 3,000 hours of egocentric video. In: CVPR. pp. 18995–19012 (2022)
2022
-
[17]
In: AAAI (2025)
Guo, Y., Liu, J., Li, M., Cheng, D., Tang, X., Sui, D., Liu, Q., Chen, X., Zhao, K.: Vtg-llm: Integrating timestamp knowledge into video llms for enhanced video temporal grounding. In: AAAI (2025)
2025
-
[18]
In: ECCV
Hannan, T., Islam, M.M., Seidl, T., Bertasius, G.: Rgnet: A unified clip retrieval and grounding network for long videos. In: ECCV. pp. 352–369. Springer (2024)
2024
-
[19]
Hou, Z., Zhong, W., Ji, L., Gao, D., Yan, K., Chan, W.K., Ngo, C.W., Shou, Z., Duan, N.: Cone: An efficient coarse-to-fine alignment framework for long video temporal grounding. arXiv preprint arXiv:2209.10918 (2022) 16 J. An et al
-
[20]
In: CVPR (2024)
Huang, B., Wang, X., Chen, H., Song, Z., Zhu, W.: Vtimellm: Empower llm to grasp video moments. In: CVPR (2024)
2024
-
[21]
In: ECCV (2024)
Huang, D.A., Liao, S., Radhakrishnan, S., Yin, H., Molchanov, P., Yu, Z., Kautz, J.: Lita: Language instructed temporal-localization assistant. In: ECCV (2024)
2024
-
[22]
In: ICCV (2023)
Jang,J.,Park,J., Kim,J.,Kwon,H.,Sohn,K.:Knowingwheretofocus:Event-aware transformer for video grounding. In: ICCV (2023)
2023
-
[23]
In: Proceedings of the IEEE international conference on computer vision
Krishna, R., Hata, K., Ren, F., Fei-Fei, L., Carlos Niebles, J.: Dense-captioning events in videos. In: Proceedings of the IEEE international conference on computer vision. pp. 706–715 (2017)
2017
-
[24]
In: ECCV
Lee, P., Byun, H.: Bam-detr: Boundary-aligned moment detection transformer for temporal sentence grounding in videos. In: ECCV. pp. 220–238. Springer (2024)
2024
-
[25]
NeurIPS34, 11846–11858 (2021)
Lei, J., Berg, T.L., Bansal, M.: Detecting moments and highlights in videos via natural language queries. NeurIPS34, 11846–11858 (2021)
2021
-
[26]
arXiv preprint arXiv:2506.18883 (2025)
Li, Z., Di, S., Zhai, Z., Huang, W., Wang, Y., Xie, W.: Universal video temporal grounding with generative multi-modal large language models. arXiv preprint arXiv:2506.18883 (2025)
-
[27]
NeurIPS35, 7575–7586 (2022)
Lin, K.Q., Wang, J., Soldan, M., Wray, M., Yan, R., Xu, E.Z., Gao, D., Tu, R.C., Zhao, W., Kong, W., et al.: Egocentric video-language pretraining. NeurIPS35, 7575–7586 (2022)
2022
-
[28]
In: ICCV (2023)
Lin, K.Q., Zhang, P., Chen, J., Pramanick, S., Gao, D., Wang, A.J., Yan, R., Shou, M.Z.: Univtg: Towards unified video-language temporal grounding. In: ICCV (2023)
2023
-
[29]
In: ICCV
Lin, T.Y., Goyal, P., Girshick, R., He, K., Dollár, P.: Focal loss for dense object detection. In: ICCV. pp. 2980–2988 (2017)
2017
-
[30]
In: CVPR
Lu, Z., Iftekhar, A., Mittal, G., Meng, T., Wang, X., Zhao, C., Kukkala, R., Elhamifar, E., Chen, M.: Decafnet: Delegate and conquer for efficient temporal grounding in long videos. In: CVPR. pp. 24066–24076 (2025)
2025
-
[31]
Chrono: A simple blueprint for representing time in mllms.arXiv preprint arXiv:2406.18113, 2024
Meinardus, B., Batra, A., Rohrbach, A., Rohrbach, M.: The surprising effectiveness of multimodal large language models for video moment retrieval. arXiv preprint arXiv:2406.18113 (2024)
-
[32]
arXiv preprint arXiv:2311.08835 (2023)
Moon, W., Hyun, S., Lee, S., Heo, J.P.: Correlation-guided query-dependency calibration for video temporal grounding. arXiv preprint arXiv:2311.08835 (2023)
-
[33]
In: CVPR (2023)
Moon, W., Hyun, S., Park, S., Park, D., Heo, J.P.: Query-dependent video repre- sentation for moment retrieval and highlight detection. In: CVPR (2023)
2023
-
[34]
In: CVPR
Mu, F., Mo, S., Li, Y.: Snag: Scalable and accurate video grounding. In: CVPR. pp. 18930–18940 (2024)
2024
-
[35]
In: CVPR
Mun, J., Cho, M., Han, B.: Local-global video-text interactions for temporal grounding. In: CVPR. pp. 10810–10819 (2020)
2020
-
[36]
In: ICCV
Pan, Y., He, X., Gong, B., Lv, Y., Shen, Y., Peng, Y., Zhao, D.: Scanning only once: An end-to-end framework for fast temporal grounding in long videos. In: ICCV. pp. 13767–13777 (2023)
2023
-
[37]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Pramanick, S., Mavroudi, E., Song, Y., Chellappa, R., Torresani, L., Afouras, T.: Enrich and detect: Video temporal grounding with multimodal llms. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 24297–24308 (2025)
2025
-
[38]
Momentor: Ad- vancing video large language model with fine-grained temporal reasoning,
Qian, L., Li, J., Wu, Y., Ye, Y., Fei, H., Chua, T.S., Zhuang, Y., Tang, S.: Momentor: Advancing video large language model with fine-grained temporal reasoning. arXiv preprint arXiv:2402.11435 (2024)
-
[39]
In: International conference on machine learning
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International conference on machine learning. pp. 8748–8763. PmLR (2021) UniversalVTG 17
2021
-
[40]
In: CVPR
Ramakrishnan, S.K., Al-Halah, Z., Grauman, K.: Naq: Leveraging narrations as queries to supervise episodic memory. In: CVPR. pp. 6694–6703 (2023)
2023
-
[41]
In: ICML
Ramakrishnan, S.K., Al-Halah, Z., Grauman, K.: Spotem: Efficient video search for episodic memory. In: ICML. pp. 28618–28636. PMLR (2023)
2023
-
[42]
Transactions of the Association for Computational Linguistics1, 25–36 (2013)
Regneri,M.,Rohrbach,M.,Wetzel,D.,Thater,S.,Schiele,B.,Pinkal,M.:Grounding action descriptions in videos. Transactions of the Association for Computational Linguistics1, 25–36 (2013)
2013
-
[43]
In: CVPR (2024)
Ren, S., Yao, L., Li, S., Sun, X., Hou, L.: Timechat: A time-sensitive multimodal large language model for long video understanding. In: CVPR (2024)
2024
-
[44]
In: European conference on computer vision
Sigurdsson, G.A., Varol, G., Wang, X., Farhadi, A., Laptev, I., Gupta, A.: Hollywood in homes: Crowdsourcing data collection for activity understanding. In: European conference on computer vision. pp. 510–526. Springer (2016)
2016
-
[45]
Singh, A., Fry, A., Perelman, A., Tart, A., Ganesh, A., El-Kishky, A., McLaughlin, A., Low, A., Ostrow, A., Ananthram, A., et al.: Openai gpt-5 system card. arXiv preprint arXiv:2601.03267 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[46]
In: ICCV
Soldan, M., Xu, M., Qu, S., Tegner, J., Ghanem, B.: Vlg-net: Video-language graph matching network for video grounding. In: ICCV. pp. 3224–3234 (2021)
2021
-
[47]
NeurIPS36, 38863–38886 (2023)
Song, Y., Byrne, E., Nagarajan, T., Wang, H., Martin, M., Torresani, L.: Ego4d goal-step: Toward hierarchical understanding of procedural activities. NeurIPS36, 38863–38886 (2023)
2023
-
[48]
In: CVPR
Tang, Y., Ding, D., Rao, Y., Zheng, Y., Zhang, D., Zhao, L., Lu, J., Zhou, J.: Coin: A large-scale dataset for comprehensive instructional video analysis. In: CVPR. pp. 1207–1216 (2019)
2019
-
[49]
In: ICCV
Tran, D., Bourdev, L., Fergus, R., Torresani, L., Paluri, M.: Learning spatiotemporal features with 3d convolutional networks. In: ICCV. pp. 4489–4497 (2015)
2015
-
[50]
In: CVPR
Wang, H., Zha, Z.J., Li, L., Liu, D., Luo, J.: Structured multi-level interaction network for video moment localization via language query. In: CVPR. pp. 7026–7035 (2021)
2021
-
[51]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Wang, P., Bai, S., Tan, S., Wang, S., Fan, Z., Bai, J., Chen, K., Liu, X., Wang, J., Ge, W., et al.: Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution. arXiv preprint arXiv:2409.12191 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[52]
Internvideo: General video foundation models via generative and discriminative learning
Wang, Y., Li, K., Li, Y., He, Y., Huang, B., Zhao, Z., Zhang, H., Xu, J., Liu, Y., Wang, Z., et al.: Internvideo: General video foundation models via generative and discriminative learning. arXiv preprint arXiv:2212.03191 (2022)
-
[53]
Hawkeye: Training video-text llms for grounding text in videos,
Wang, Y., Meng, X., Liang, J., Wang, Y., Liu, Q., Zhao, D.: Hawkeye: Training video-text llms for grounding text in videos. arXiv preprint arXiv:2403.10228 (2024)
-
[54]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Yan, S., Xiong, X., Nagrani, A., Arnab, A., Wang, Z., Ge, W., Ross, D., Schmid, C.: Unloc: A unified framework for video localization tasks. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 13623–13633 (2023)
2023
-
[55]
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., et al.: Qwen3 technical report. arXiv preprint arXiv:2505.09388 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[56]
NeurIPS32(2019)
Yuan, Y., Ma, L., Wang, J., Liu, W., Zhu, W.: Semantic conditioned dynamic modulation for temporal sentence grounding in videos. NeurIPS32(2019)
2019
-
[57]
In: CVPR
Zala, A., Cho, J., Kottur, S., Chen, X., Oguz, B., Mehdad, Y., Bansal, M.: Hier- archical video-moment retrieval and step-captioning. In: CVPR. pp. 23056–23065 (2023)
2023
-
[58]
In: CVPR
Zeng, R., Xu, H., Huang, W., Chen, P., Tan, M., Gan, C.: Dense regression network for video grounding. In: CVPR. pp. 10287–10296 (2020)
2020
-
[59]
In: ICLR (2024) 18 J
Zeng, X., Li, K., Wang, C., Li, X., Jiang, T., Yan, Z., Li, S., Shi, Y., Yue, Z., Wang, Y., et al.: Timesuite: Improving mllms for long video understanding via grounded tuning. In: ICLR (2024) 18 J. An et al
2024
-
[60]
VideoLLaMA 3: Frontier Multimodal Foundation Models for Image and Video Understanding
Zhang, B., Li, K., Cheng, Z., Hu, Z., Yuan, Y., Chen, G., Leng, S., Jiang, Y., Zhang, H., Li, X., et al.: Videollama 3: Frontier multimodal foundation models for image and video understanding. arXiv preprint arXiv:2501.13106 (2025)
work page internal anchor Pith review arXiv 2025
-
[61]
In: ECCV
Zhang, C.L., Wu, J., Li, Y.: Actionformer: Localizing moments of actions with transformers. In: ECCV. pp. 492–510. Springer (2022)
2022
-
[62]
Span-based localizing network for natural language video localization,
Zhang, H., Sun, A., Jing, W., Zhou, J.T.: Span-based localizing network for natural language video localization. arXiv preprint arXiv:2004.13931 (2020)
-
[63]
In: AAAI
Zhang, S., Peng, H., Fu, J., Luo, J.: Learning 2d temporal adjacent networks for moment localization with natural language. In: AAAI. vol. 34, pp. 12870–12877 (2020)
2020
-
[64]
In: AAAI
Zheng, Z., Wang, P., Liu, W., Li, J., Ye, R., Ren, D.: Distance-iou loss: Faster and better learning for bounding box regression. In: AAAI. vol. 34, pp. 12993–13000 (2020)
2020
-
[65]
Zhou, L., Xu, C., Corso, J.: Towards automatic learning of procedures from web instructional videos. In: AAAI. vol. 32 (2018) Supplementary Material 19 A Analysis of the Unifier Module As introduced in Section 4.2 of the main paper, the Unifier module can be instantiated with any Large Language Model (LLM). Its primary role is to convert diverse incoming ...
-
[66]
Preserves ALL semantic meaning, visual cues, objects, attributes, and agent information
-
[67]
Standardizes the style to a consistent format across all datasets
-
[68]
Unified Style Target
Maintains the original perspective (first-person if original is first-person, third- person if original is third-person). Unified Style Target
-
[69]
Directly describe the event to locate (Subject-Verb- Object-Location), which is more natural for temporal matching than questions
Format (Descriptive statement):All queries should be phrased as complete, descriptive statements. Directly describe the event to locate (Subject-Verb- Object-Location), which is more natural for temporal matching than questions
-
[70]
was", "put
Tense (Past tense):Use past tense verbs (e.g., "was", "put", "took"). This indicates events that have already occurred and can be located temporally. 26 Supplementary Material 3.Perspective Preservation: –If original is first-person ("I", "my"):Keep first-person. –If original is third-person ("he", "the woman"):Keep third-person. –Do NOT convertbetween pe...
-
[71]
Capitalize the first letter and end with a period
Completeness:Use complete, grammatically correct sentences. Capitalize the first letter and end with a period
-
[72]
I" →"I",
Visual Grounding:All information must be purely visually deducible. Do NOT require reasoning about intentions, motivations, or external knowledge. Critical Preservation Rules –1. Agent/Subject:Preserve the original agent noun phrase exactly (e.g., "I" →"I", "a woman"→"a woman"). Agent identity is a strong visual cue. –2. Action/Verb:Preserve the main verb...
-
[73]
Identify elements:Agent, Action, Objects, Location, Attributes, Temporal relations
-
[74]
Preserve perspective:First-person stays first-person; third-person stays third-person
-
[75]
was", "had
Convert to statement:Use specific event verbs. Avoid weak verbs ("was", "had") unless part of a compound event. 4.Convert to past tense:"is"→"was", "takes"→"took"
-
[76]
No explana- tions, no original sentences, no commentary
Output Requirements:Provide ONLY the converted statement. No explana- tions, no original sentences, no commentary. A single, complete, grammatically correct sentence ending in a period. Supplementary Material 27 Query: peel potatoes 1s – 62s 0s – 64s GT Ours 24s – 30s 23s – 30s GT Ours Prediction: Query: person turn a light on Video Source: Goalstep Video...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.