Recognition: 2 theorem links
· Lean TheoremActiveGlasses: Learning Manipulation with Active Vision from Ego-centric Human Demonstration
Pith reviewed 2026-05-10 17:20 UTC · model grok-4.3
The pith
ActiveGlasses captures ego-centric human demonstrations with smart glasses to enable zero-shot robot manipulation transfer using active vision.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ActiveGlasses achieves zero-shot transfer of manipulation policies from ego-centric human demonstrations to robotic platforms by using a stereo camera on smart glasses for data collection and replicating active vision on a perception arm during inference, with policies based on object trajectories and point-cloud representations that jointly control manipulation and head movement.
What carries the argument
The object-centric point-cloud policy that jointly predicts manipulation actions and head movements from object trajectories extracted from ego-centric stereo demonstrations.
Load-bearing premise
Object trajectories extracted from ego-centric stereo demonstrations combined with an object-centric point-cloud policy can faithfully reproduce naturally coordinated human perception-manipulation behaviors for zero-shot robot transfer without additional embodiment-specific tuning.
What would settle it
A controlled experiment in which a robot running the ActiveGlasses policy fails to complete a precise interaction task that a human demonstrator performs successfully under identical visual occlusion conditions.
Figures





read the original abstract
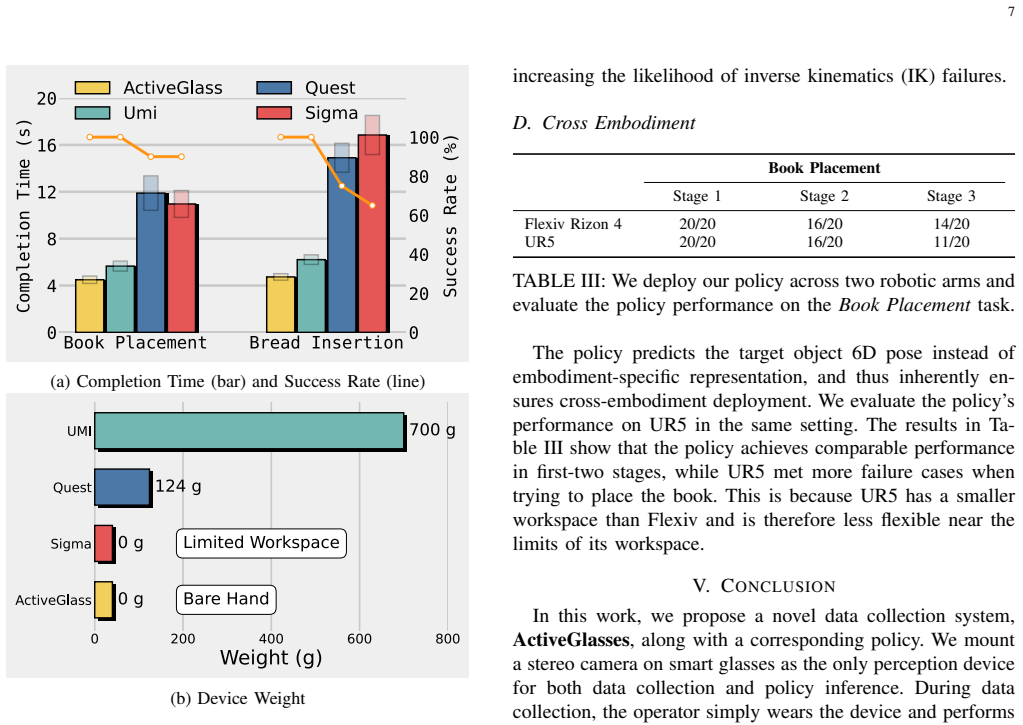
Large-scale real-world robot data collection is a prerequisite for bringing robots into everyday deployment. However, existing pipelines often rely on specialized handheld devices to bridge the embodiment gap, which not only increases operator burden and limits scalability, but also makes it difficult to capture the naturally coordinated perception-manipulation behaviors of human daily interaction. This challenge calls for a more natural system that can faithfully capture human manipulation and perception behaviors while enabling zero-shot transfer to robotic platforms. We introduce ActiveGlasses, a system for learning robot manipulation from ego-centric human demonstrations with active vision. A stereo camera mounted on smart glasses serves as the sole perception device for both data collection and policy inference: the operator wears it during bare-hand demonstrations, and the same camera is mounted on a 6-DoF perception arm during deployment to reproduce human active vision. To enable zero-transfer, we extract object trajectories from demonstrations and use an object-centric point-cloud policy to jointly predict manipulation and head movement. Across several challenging tasks involving occlusion and precise interaction, ActiveGlasses achieves zero-shot transfer with active vision, consistently outperforms strong baselines under the same hardware setup, and generalizes across two robot platforms.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ActiveGlasses, a system that mounts a stereo camera on smart glasses to capture ego-centric human demonstrations of manipulation tasks. Object trajectories are extracted from these demonstrations and fed into an object-centric point-cloud policy that jointly outputs manipulation actions and head motions to enable active vision. The same camera hardware is then mounted on a 6-DoF perception arm for zero-shot deployment on robots. The central claims are that this pipeline achieves successful zero-shot transfer on occlusion-heavy and precision tasks, consistently outperforms strong baselines under identical hardware, and generalizes across two robot platforms.
Significance. If the experimental claims are substantiated with quantitative evidence, the work would offer a practical advance in scalable robot learning by enabling natural bare-hand data collection that preserves coordinated perception-manipulation behaviors without specialized handheld devices or embodiment-specific retargeting. The reuse of the identical stereo camera for both data collection and policy inference directly addresses the embodiment gap and active-vision coordination, which are recurring bottlenecks in imitation learning.
major comments (2)
- [Abstract] Abstract and Experimental Results section: the central claims that ActiveGlasses 'achieves zero-shot transfer with active vision' and 'consistently outperforms strong baselines' are unsupported by any reported success rates, failure modes, statistical tests, or quantitative comparisons; without these metrics the superiority and transfer assertions cannot be evaluated.
- [§4] §4 (Policy Learning) and §5 (Experiments): the description of the object-centric point-cloud policy does not specify the input representation (e.g., how trajectories are encoded into the point cloud), the action space for head motion, or the training objective, leaving the mechanism that enables joint manipulation-plus-active-vision prediction unclear and load-bearing for the zero-shot claim.
minor comments (2)
- [§3] The term 'object-centric point-cloud policy' is used without an explicit definition or diagram showing how object trajectories are fused with the current point cloud; a figure or short paragraph clarifying the state representation would improve readability.
- [Abstract] The abstract states generalization 'across two robot platforms' but does not name the platforms or report any platform-specific ablations; adding this detail would strengthen the generalization claim.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. We address each major comment below and will revise the manuscript to improve clarity and substantiation of the claims.
read point-by-point responses
-
Referee: [Abstract] Abstract and Experimental Results section: the central claims that ActiveGlasses 'achieves zero-shot transfer with active vision' and 'consistently outperforms strong baselines' are unsupported by any reported success rates, failure modes, statistical tests, or quantitative comparisons; without these metrics the superiority and transfer assertions cannot be evaluated.
Authors: We agree that the abstract and the presentation of results would be strengthened by explicit quantitative metrics. The experiments were run with multiple trials per task and hardware setup, so we will revise the abstract to report key success rates (means and standard deviations), a summary of failure modes, and direct comparisons to baselines. We will also add a table or prominent quantitative summary in §5 with statistical tests where appropriate. This revision will make the central claims directly evaluable while preserving the existing experimental design. revision: yes
-
Referee: [§4] §4 (Policy Learning) and §5 (Experiments): the description of the object-centric point-cloud policy does not specify the input representation (e.g., how trajectories are encoded into the point cloud), the action space for head motion, or the training objective, leaving the mechanism that enables joint manipulation-plus-active-vision prediction unclear and load-bearing for the zero-shot claim.
Authors: We acknowledge that the current description in §4 is insufficiently detailed on these load-bearing aspects. We will expand the section to explicitly state: the input representation (object trajectories encoded as sequences of object-centric 3D point clouds augmented with velocity features), the head-motion action space (6-DoF velocity commands for the perception arm), and the training objective (multi-head behavior cloning loss jointly supervising manipulation and head actions). These additions will clarify the joint prediction mechanism and its role in enabling zero-shot active-vision transfer. We will also cross-reference the updated description in §5. revision: yes
Circularity Check
No significant circularity
full rationale
The paper describes an end-to-end robotics system for ego-centric data collection and zero-shot policy transfer using stereo cameras and object-centric point clouds. No equations, derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text or abstract. Experimental claims rest on hardware-matched deployment and task performance rather than any internal reduction to prior fitted quantities or author-defined uniqueness theorems.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Object trajectories can be reliably extracted from ego-centric stereo video demonstrations.
- domain assumption The learned policy can jointly predict manipulation actions and head movements for zero-shot transfer.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearobject-centric point-cloud policy to jointly predict manipulation and head movement
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearextract object trajectories from demonstrations and use an object-centric point-cloud policy
Reference graph
Works this paper leans on
-
[1]
RT-1: Robotics Transformer for Real-World Control at Scale
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, J. Dabis, C. Finn, K. Gopalakrishnan, K. Hausman, A. Herzog, J. Hsuet al., “Rt-1: Robotics transformer for real-world control at scale,”arXiv preprint arXiv:2212.06817, 2022
work page internal anchor Pith review arXiv 2022
-
[2]
Rt-2: Vision-language-action models transfer web knowledge to robotic control,
B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao, F. Xia, J. Wu, P. Wohlhart, S. Welker, A. Wahidet al., “Rt-2: Vision-language-action models transfer web knowledge to robotic control,” inConference on Robot Learning. PMLR, 2023, pp. 2165–2183
2023
-
[3]
OpenVLA: An Open-Source Vision-Language-Action Model
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketiet al., “Openvla: An open- source vision-language-action model,”arXiv preprint arXiv:2406.09246, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
P. Intelligence, K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, M. Y . Galliker, D. Ghosh, L. Groom, K. Hausman, B. Ichter, S. Jakubczak, T. Jones, L. Ke, D. LeBlanc, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, A. Z. Ren, L. X. Shi, L. Smith, J. T. Springenberg, K. Stachowicz, J. Tanner, Q. V...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Good old-fashioned engineering can close the 100,000- year “data gap
K. Goldberg, “Good old-fashioned engineering can close the 100,000- year “data gap” in robotics,” p. eaea7390, 2025
2025
-
[6]
S. Kareer, K. Pertsch, J. Darpinian, J. Hoffman, D. Xu, S. Levine, C. Finn, and S. Nair, “Emergence of human to robot transfer in vision- language-action models,”arXiv preprint arXiv:2512.22414, 2025
-
[7]
Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware
T. Z. Zhao, V . Kumar, S. Levine, and C. Finn, “Learning fine- grained bimanual manipulation with low-cost hardware,”arXiv preprint arXiv:2304.13705, 2023
work page internal anchor Pith review arXiv 2023
-
[8]
Gello: A general, low-cost, and intuitive teleoperation framework for robot manipulators,
P. Wu, Y . Shentu, Z. Yi, X. Lin, and P. Abbeel, “Gello: A general, low-cost, and intuitive teleoperation framework for robot manipulators,” in2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2024, pp. 12 156–12 163
2024
-
[9]
Universal Manipulation Interface: In-The-Wild Robot Teaching Without In-The-Wild Robots
C. Chi, Z. Xu, C. Pan, E. Cousineau, B. Burchfiel, S. Feng, R. Tedrake, and S. Song, “Universal manipulation interface: In-the-wild robot teach- ing without in-the-wild robots,”arXiv preprint arXiv:2402.10329, 2024
work page internal anchor Pith review arXiv 2024
-
[10]
K. Liu, C. Guan, Z. Jia, Z. Wu, X. Liu, T. Wang, S. Liang, P. Chen, P. Zhang, H. Songet al., “Fastumi: A scalable and hardware- independent universal manipulation interface with dataset,”arXiv preprint arXiv:2409.19499, 2024
-
[11]
Open-television: Teleoperation with immersive active visual feedback,
X. Cheng, J. Li, S. Yang, G. Yang, and X. Wang, “Open-television: Teleoperation with immersive active visual feedback,”arXiv preprint arXiv:2407.01512, 2024
-
[12]
U-arm: Ultra low-cost general teleoperation interface for robot manipulation,
Y . Zou, Z. Zhou, C. Shi, Z. Ye, J. Huang, Y . Ding, and B. Zhao, “U-arm: Ultra low-cost general teleoperation interface for robot manipulation,” arXiv preprint arXiv:2509.02437, 2025
-
[13]
Rise: 3d perception makes real-world robot imitation simple and effective,
C. Wang, H. Fang, H.-S. Fang, and C. Lu, “Rise: 3d perception makes real-world robot imitation simple and effective,” in2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2024, pp. 2870–2877
2024
- [14]
-
[15]
H.-S. Fang, B. Romero, Y . Xie, A. Hu, B.-R. Huang, J. Alvarez, M. Kim, G. Margolis, K. Anbarasu, M. Tomizukaet al., “Dexop: A device for robotic transfer of dexterous human manipulation,”arXiv preprint arXiv:2509.04441, 2025
-
[16]
Dexumi: Using human hand as the universal manipulation interface for dexterous manipulation, 2025
M. Xu, H. Zhang, Y . Hou, Z. Xu, L. Fan, M. Veloso, and S. Song, “Dexumi: Using human hand as the universal manipulation interface for dexterous manipulation,”arXiv preprint arXiv:2505.21864, 2025
-
[17]
Egozero: Robot learning from smart glasses.arXiv preprint arXiv:2505.20290, 2025
V . Liu, A. Adeniji, H. Zhan, S. Haldar, R. Bhirangi, P. Abbeel, and L. Pinto, “Egozero: Robot learning from smart glasses,”arXiv preprint arXiv:2505.20290, 2025
-
[18]
Egomimic: Scaling imitation learning via egocentric video,
S. Kareer, D. Patel, R. Punamiya, P. Mathur, S. Cheng, C. Wang, J. Hoffman, and D. Xu, “Egomimic: Scaling imitation learning via egocentric video,” in2025 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2025, pp. 13 226–13 233
2025
-
[19]
I. Guzey, H. Qi, J. Urain, C. Wang, J. Yin, K. Bodduluri, M. Lambeta, L. Pinto, A. Rai, J. Maliket al., “Dexterity from smart lenses: Multi- fingered robot manipulation with in-the-wild human demonstrations,” arXiv preprint arXiv:2511.16661, 2025
-
[20]
R. Yang, Q. Yu, Y . Wu, R. Yan, B. Li, A.-C. Cheng, X. Zou, Y . Fang, X. Cheng, R.-Z. Qiuet al., “Egovla: Learning vision- language-action models from egocentric human videos,”arXiv preprint arXiv:2507.12440, 2025
-
[21]
C. Yuan, R. Zhou, M. Liu, Y . Hu, S. Wang, L. Yi, C. Wen, S. Zhang, and Y . Gao, “Motiontrans: Human vr data enable motion-level learning for robotic manipulation policies,”arXiv preprint arXiv:2509.17759, 2025
-
[22]
Emma: Scaling mobile manipulation via egocentric human data.arXiv preprint arXiv:2509.04443, 2025
L. Y . Zhu, P. Kuppili, R. Punamiya, P. Aphiwetsa, D. Patel, S. Kareer, S. Ha, and D. Xu, “Emma: Scaling mobile manipulation via egocentric human data,”arXiv preprint arXiv:2509.04443, 2025
-
[23]
Arcap: Collecting high-quality human demonstrations for robot learning with augmented reality feedback,
S. Chen, C. Wang, K. Nguyen, L. Fei-Fei, and C. K. Liu, “Arcap: Collecting high-quality human demonstrations for robot learning with augmented reality feedback,” in2025 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2025, pp. 8291–8298
2025
-
[24]
arXiv preprint arXiv:2511.00153 , year=
J. Yu, Y . Shentu, D. Wu, P. Abbeel, K. Goldberg, and P. Wu, “Egomi: Learning active vision and whole-body manipulation from egocentric human demonstrations,”arXiv preprint arXiv:2511.00153, 2025
-
[25]
Fastumi pro,
“Fastumi pro,” https://www.fastumi.com/pro/, 2026, access date:2026- 01-20
2026
-
[26]
M. Lepert, J. Fang, and J. Bohg, “Masquerade: Learning from in-the-wild human videos using data-editing,”arXiv preprint arXiv:2508.09976, 2025
-
[27]
Active perception,
R. Bajcsy, “Active perception,”Proceedings of the IEEE, vol. 76, no. 8, pp. 966–1005, 1988
1988
-
[28]
Humanoid robot hrp-3,
K. Kaneko, K. Harada, F. Kanehiro, G. Miyamori, and K. Akachi, “Humanoid robot hrp-3,” in2008 IEEE/RSJ International Conference on Intelligent Robots and Systems. IEEE, 2008, pp. 2471–2478
2008
-
[29]
Humanoid robot hrp-4-humanoid robotics platform with lightweight and slim body,
K. Kaneko, F. Kanehiro, M. Morisawa, K. Akachi, G. Miyamori, A. Hayashi, and N. Kanehira, “Humanoid robot hrp-4-humanoid robotics platform with lightweight and slim body,” in2011 IEEE/RSJ interna- tional conference on intelligent robots and systems. IEEE, 2011, pp. 4400–4407
2011
-
[30]
Robovie: an interactive humanoid robot,
H. Ishiguro, T. Ono, M. Imai, T. Maeda, T. Kanda, and R. Nakatsu, “Robovie: an interactive humanoid robot,”Industrial robot: An interna- tional journal, vol. 28, no. 6, pp. 498–504, 2001
2001
-
[31]
Mechanical design of humanoid robot platform khr-3 (kaist humanoid robot 3: Hubo),
I.-W. Park, J.-Y . Kim, J. Lee, and J.-H. Oh, “Mechanical design of humanoid robot platform khr-3 (kaist humanoid robot 3: Hubo),” in5th IEEE-RAS International Conference on Humanoid Robots, 2005.IEEE, 2005, pp. 321–326
2005
-
[32]
Mechanical design of the humanoid robot platform, hubo,
——, “Mechanical design of the humanoid robot platform, hubo,” Advanced Robotics, vol. 21, no. 11, pp. 1305–1322, 2007
2007
-
[33]
Eye, robot: Learning to look to act with a bc-rl perception-action loop,
J. Kerr, K. Hari, E. Weber, C. M. Kim, B. Yi, T. Bonnen, K. Goldberg, and A. Kanazawa, “Eye, robot: Learning to look to act with a bc-rl perception-action loop,”arXiv preprint arXiv:2506.10968, 2025
-
[34]
Hommi: Learning whole-body mobile manipulation from human demonstrations, 2026
X. Xu, J. Park, H. Zhang, E. Cousineau, A. Bhat, J. Barreiros, D. Wang, and S. Song, “Hommi: Learning whole-body mobile manipulation from human demonstrations,”arXiv preprint arXiv:2603.03243, 2026
-
[35]
Vision in action: Learning active perception from human demonstrations
H. Xiong, X. Xu, J. Wu, Y . Hou, J. Bohg, and S. Song, “Vision in action: Learning active perception from human demonstrations,”arXiv preprint arXiv:2506.15666, 2025
-
[36]
Foundationstereo: Zero-shot stereo matching,
B. Wen, M. Trepte, J. Aribido, J. Kautz, O. Gallo, and S. Birchfield, “Foundationstereo: Zero-shot stereo matching,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2025, pp. 5249–5260
2025
-
[37]
Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks
T. Ren, S. Liu, A. Zeng, J. Lin, K. Li, H. Cao, J. Chen, X. Huang, Y . Chen, F. Yanet al., “Grounded sam: Assembling open-world models for diverse visual tasks,”arXiv preprint arXiv:2401.14159, 2024
work page internal anchor Pith review arXiv 2024
-
[38]
SAM 2: Segment Anything in Images and Videos
N. Ravi, V . Gabeur, Y .-T. Hu, R. Hu, C. Ryali, T. Ma, H. Khedr, R. R ¨adle, C. Rolland, L. Gustafson, E. Mintun, J. Pan, K. V . Alwala, N. Carion, C.-Y . Wu, R. Girshick, P. Doll ´ar, and C. Feichtenhofer, “Sam 2: Segment anything in images and videos,”arXiv preprint arXiv:2408.00714, 2024. [Online]. Available: https://arxiv.org/abs/2408. 00714
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[39]
FoundationPose: Unified 6d pose estimation and tracking of novel objects,
B. Wen, W. Yang, J. Kautz, and S. Birchfield, “FoundationPose: Unified 6d pose estimation and tracking of novel objects,” inCVPR, 2024
2024
-
[40]
Anygrasp: Robust and efficient grasp perception in spatial and temporal domains,
H.-S. Fang, C. Wang, H. Fang, M. Gou, J. Liu, H. Yan, W. Liu, Y . Xie, and C. Lu, “Anygrasp: Robust and efficient grasp perception in spatial and temporal domains,”IEEE Transactions on Robotics, vol. 39, no. 5, pp. 3929–3945, 2023
2023
-
[41]
Spot: Se (3) pose trajectory diffusion for object-centric manipulation,
C.-C. Hsu, B. Wen, J. Xu, Y . Narang, X. Wang, Y . Zhu, J. Biswas, and S. Birchfield, “Spot: Se (3) pose trajectory diffusion for object-centric manipulation,” in2025 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2025, pp. 4853–4860
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.