Recognition: unknown
Meta-learning In-Context Enables Training-Free Cross Subject Brain Decoding
Pith reviewed 2026-05-10 17:37 UTC · model grok-4.3
The pith
A meta-learned model decodes visual stimuli from any new subject's fMRI signals using only a few examples.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors claim that their meta-optimized approach enables training-free cross-subject semantic visual decoding from fMRI by conditioning on a small set of image-brain examples from a novel subject. The model performs this through two stages of hierarchical inference: first estimating per-voxel visual response encoder parameters from context over stimuli and responses, and second aggregating encoder parameters and responses over voxels for functional inversion. This achieves strong generalization across subjects, scanners, and visual backbones without anatomical alignment or stimulus overlap.
What carries the argument
Hierarchical in-context inference for encoder parameter estimation and functional inversion, where context examples allow rapid inference of subject-specific neural encoding patterns that are then inverted to decode stimuli.
Load-bearing premise
That a small set of image and brain activation examples from a new subject is sufficient for the meta-learned model to accurately infer and invert that individual's unique neural encoding patterns.
What would settle it
Observing that decoding performance on novel subjects remains at chance levels even after providing context examples, while it succeeds only when the model has been fine-tuned on the target subject, would falsify the claim.
Figures





read the original abstract
Visual decoding from brain signals is a key challenge at the intersection of computer vision and neuroscience, requiring methods that bridge neural representations and computational models of vision. A field-wide goal is to achieve generalizable, cross-subject models. A major obstacle towards this goal is the substantial variability in neural representations across individuals, which has so far required training bespoke models or fine-tuning separately for each subject. To address this challenge, we introduce a meta-optimized approach for semantic visual decoding from fMRI that generalizes to novel subjects without any fine-tuning. By simply conditioning on a small set of image-brain activation examples from the new individual, our model rapidly infers their unique neural encoding patterns to facilitate robust and efficient visual decoding. Our approach is explicitly optimized for in-context learning of the new subject's encoding model and performs decoding by hierarchical inference, inverting the encoder. First, for multiple brain regions, we estimate the per-voxel visual response encoder parameters by constructing a context over multiple stimuli and responses. Second, we construct a context consisting of encoder parameters and response values over multiple voxels to perform aggregated functional inversion. We demonstrate strong cross-subject and cross-scanner generalization across diverse visual backbones without retraining or fine-tuning. Moreover, our approach requires neither anatomical alignment nor stimulus overlap. This work is a critical step towards a generalizable foundation model for non-invasive brain decoding.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a meta-optimized in-context learning approach for semantic visual decoding from fMRI signals. It claims that by conditioning on a small set of image-brain activation examples from a new subject, the model can infer unique neural encoding patterns and perform robust visual decoding without any fine-tuning, anatomical alignment, or stimulus overlap. The method involves estimating per-voxel visual response encoder parameters via context over stimuli and responses, followed by aggregated functional inversion over voxels.
Significance. If the empirical results support the claims with rigorous validation, this work could have high significance as a step toward generalizable, training-free cross-subject brain decoding models. It potentially reduces the need for subject-specific training, which has been a major barrier in the field, and could contribute to the development of foundation models for non-invasive neural decoding across diverse visual backbones and scanners.
major comments (3)
- The abstract asserts 'strong cross-subject and cross-scanner generalization' and 'robust and efficient visual decoding' but provides no quantitative metrics, ablation studies, or baseline comparisons. This makes it impossible to evaluate the magnitude of improvement or the validity of the central claim without the full results section.
- The hierarchical inference process—first estimating per-voxel encoder parameters from context over multiple stimuli/responses, then aggregating for functional inversion—is described at a high level. The paper should include the specific loss function or optimization objective used in meta-training, as well as details on how context is constructed to ensure it does not rely on population-level statistics.
- The weakest assumption is that a small set of examples suffices to accurately recover subject-specific mappings given high inter-subject variability in fMRI. The manuscript needs to report performance as a function of context size and demonstrate that decoding accuracy exceeds what would be achieved by a population-averaged model.
minor comments (1)
- The term 'semantic visual decoding' could be more precisely defined, and the phrase 'inverting the encoder' should be clarified with reference to the specific inversion method used.
Simulated Author's Rebuttal
We thank the referee for their insightful comments, which have helped us improve the clarity and rigor of our manuscript. We provide point-by-point responses to the major comments below.
read point-by-point responses
-
Referee: The abstract asserts 'strong cross-subject and cross-scanner generalization' and 'robust and efficient visual decoding' but provides no quantitative metrics, ablation studies, or baseline comparisons. This makes it impossible to evaluate the magnitude of improvement or the validity of the central claim without the full results section.
Authors: The full manuscript contains extensive quantitative evaluations, including metrics for cross-subject and cross-scanner performance, ablation studies on the meta-learning components, and comparisons to baselines in the results section. However, we agree that the abstract would be strengthened by including key quantitative highlights. In the revised version, we will incorporate specific numbers, such as average decoding accuracy and improvement margins, into the abstract to better substantiate the claims. revision: yes
-
Referee: The hierarchical inference process—first estimating per-voxel encoder parameters from context over multiple stimuli/responses, then aggregating for functional inversion—is described at a high level. The paper should include the specific loss function or optimization objective used in meta-training, as well as details on how context is constructed to ensure it does not rely on population-level statistics.
Authors: We will provide the requested details in the revision. The meta-training objective is the expected negative log-likelihood loss over the meta-training subjects, where the model parameters are optimized to enable effective in-context adaptation. Context is constructed exclusively from the few examples of the target subject, using their specific stimulus-response pairs without any aggregation from other subjects or population statistics. We will add the precise equations for the loss and the context construction algorithm to the methods section. revision: yes
-
Referee: The weakest assumption is that a small set of examples suffices to accurately recover subject-specific mappings given high inter-subject variability in fMRI. The manuscript needs to report performance as a function of context size and demonstrate that decoding accuracy exceeds what would be achieved by a population-averaged model.
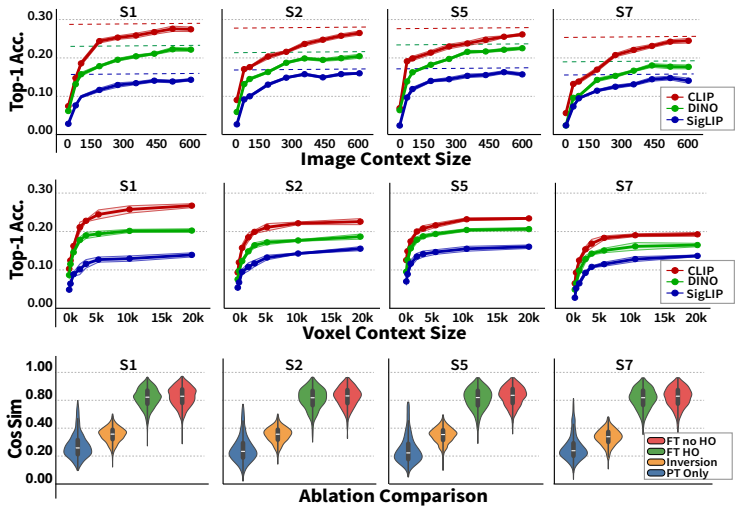
Authors: We have conducted experiments varying the context size from 1 to 20 examples and observed that performance increases with context size, stabilizing around 5-10 examples, which supports that a small set is sufficient. We also include a direct comparison showing that our in-context method outperforms a population-averaged encoder model across subjects. To address the comment fully, we will make these analyses more prominent in the revised manuscript, potentially adding a new figure summarizing the context size ablation and the baseline comparison. revision: partial
Circularity Check
No circularity: meta-learning setup is self-contained optimization
full rationale
The paper frames its contribution as training a meta-learner explicitly optimized for in-context estimation of subject-specific encoders from few stimulus-response pairs, followed by hierarchical inversion. No equations, definitions, or steps in the provided abstract or description reduce a claimed prediction to a fitted parameter or self-referential input by construction. The generalization claim is an empirical assertion about the trained model's behavior on held-out subjects, not a derivation that collapses to its own inputs. No self-citations or uniqueness theorems are invoked in the text to bear load on the central result.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Predicting brain activity using transformers.bioRxiv, pages 2023–08, 2023
Hossein Adeli, Sun Minni, and Nikolaus Kriegeskorte. Predicting brain activity using transformers.bioRxiv, pages 2023–08, 2023. 2
2023
-
[2]
A massive 7t fmri dataset to bridge cognitive neuroscience and artificial intelligence.Nature neuroscience, 25(1):116–126, 2022
Emily J Allen, Ghislain St-Yves, Yihan Wu, Jesse L Breedlove, Jacob S Prince, Logan T Dowdle, Matthias Nau, Brad Caron, Franco Pestilli, Ian Charest, et al. A massive 7t fmri dataset to bridge cognitive neuroscience and artificial intelligence.Nature neuroscience, 25(1):116–126, 2022. 1, 6
2022
-
[3]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. Qwen technical report.arXiv preprint arXiv:2309.16609, 2023. 5
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Guangyin Bao, Qi Zhang, Zixuan Gong, Zhuojia Wu, and Duoqian Miao. Mindsimulator: Exploring brain concept localization via synthetic fmri.arXiv preprint arXiv:2503.02351, 2025. 2
-
[5]
Neural population control via deep image synthesis.Science, 364(6439): eaav9436, 2019
Pouya Bashivan, Kohitij Kar, and James J DiCarlo. Neural population control via deep image synthesis.Science, 364(6439): eaav9436, 2019. 3
2019
-
[6]
The wisdom of a crowd of brains: A universal brain encoder.arXiv preprint arXiv:2406.12179, 2024
Roman Beliy, Navve Wasserman, Amit Zalcher, and Michal Irani. The wisdom of a crowd of brains: A universal brain encoder. arXiv preprint arXiv:2406.12179, 2024. 2
-
[7]
Music can be reconstructed from human auditory cortex activity using nonlinear decoding models.PLoS biology, 21(8):e3002176, 2023
Ludovic Bellier, Ana ¨ıs Llorens, D´eborah Marciano, Aysegul Gunduz, Gerwin Schalk, Peter Brunner, and Robert T Knight. Music can be reconstructed from human auditory cortex activity using nonlinear decoding models.PLoS biology, 21(8):e3002176, 2023. 3
2023
-
[8]
Yohann Benchetrit, Hubert Banville, and Jean-R ´emi King. Brain decoding: toward real-time reconstruction of visual perception. arXiv preprint arXiv:2310.19812, 2023. 3
-
[9]
Decoding and reconstructing color from responses in human visual cortex.Journal of Neuroscience, 29(44):13992–14003, 2009
Gijs Joost Brouwer and David J Heeger. Decoding and reconstructing color from responses in human visual cortex.Journal of Neuroscience, 29(44):13992–14003, 2009. 3
2009
-
[10]
Cross-orientation suppression in human visual cortex.Journal of neurophysiology, 106(5): 2108–2119, 2011
Gijs Joost Brouwer and David J Heeger. Cross-orientation suppression in human visual cortex.Journal of neurophysiology, 106(5): 2108–2119, 2011. 3
2011
-
[11]
Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901, 2020
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901, 2020. 3
1901
-
[12]
Complementary hemispheric specialization for language production and visuospatial attention.Proceedings of the National Academy of Sciences, 110(4):E322–E330, 2013
Qing Cai, Lise Van der Haegen, and Marc Brysbaert. Complementary hemispheric specialization for language production and visuospatial attention.Proceedings of the National Academy of Sciences, 110(4):E322–E330, 2013. 1
2013
-
[13]
Brainactiv: Identifying visuo-semantic properties driving cortical selectivity using diffusion-based image manipulation.bioRxiv, pages 2024–10, 2024
Diego Garc ´ıa Cerdas, Christina Sartzetaki, Magnus Petersen, Gemma Roig, Pascal Mettes, and Iris Groen. Brainactiv: Identifying visuo-semantic properties driving cortical selectivity using diffusion-based image manipulation.bioRxiv, pages 2024–10, 2024. 3
2024
-
[14]
Bold5000, a public fMRI dataset while viewing 5000 visual images.Scientific Data, 6(1):1–18, 2019
Nadine Chang, John A Pyles, Austin Marcus, Abhinav Gupta, Michael J Tarr, and Elissa M Aminoff. Bold5000, a public fMRI dataset while viewing 5000 visual images.Scientific Data, 6(1):1–18, 2019. 1, 6
2019
-
[15]
Seeing beyond the brain: Conditional diffusion model with sparse masked modeling for vision decoding
Zijiao Chen, Jiaxin Qing, Tiange Xiang, Wan Lin Yue, and Juan Helen Zhou. Seeing beyond the brain: Conditional diffusion model with sparse masked modeling for vision decoding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22710–22720, 2023. 1, 3
2023
-
[16]
Zijiao Chen, Jiaxin Qing, and Juan Helen Zhou. Cinematic mindscapes: High-quality video reconstruction from brain activity.arXiv preprint arXiv:2305.11675, 2023. 3
-
[17]
Overcoming a theoretical limitation of self-attention.arXiv preprint arXiv:2202.12172, 2022
David Chiang and Peter Cholak. Overcoming a theoretical limitation of self-attention.arXiv preprint arXiv:2202.12172, 2022. 5
-
[18]
Meta-in-context learning in large language models.Advances in Neural Information Processing Systems, 36:65189–65201, 2023
Julian Coda-Forno, Marcel Binz, Zeynep Akata, Matt Botvinick, Jane Wang, and Eric Schulz. Meta-in-context learning in large language models.Advances in Neural Information Processing Systems, 36:65189–65201, 2023. 3
2023
-
[19]
A large-scale examination of inductive biases shaping high-level visual representation in brains and machines.Nature communications, 15(1):9383, 2024
Colin Conwell, Jacob S Prince, Kendrick N Kay, George A Alvarez, and Talia Konkle. A large-scale examination of inductive biases shaping high-level visual representation in brains and machines.Nature communications, 15(1):9383, 2024. 6, 10
2024
-
[20]
Neural portraits of perception: reconstructing face images from evoked brain activity.Neuroimage, 94:12–22, 2014
Alan S Cowen, Marvin M Chun, and Brice A Kuhl. Neural portraits of perception: reconstructing face images from evoked brain activity.Neuroimage, 94:12–22, 2014. 3
2014
-
[21]
Brainx: A universal brain decoding frame- work with feature disentanglement and neuro-geometric representation learning
Zheng Cui, Dong Nie, Pengcheng Xue, Xia Wu, Daoqiang Zhang, and Xuyun Wen. Brainx: A universal brain decoding frame- work with feature disentanglement and neuro-geometric representation learning. InProceedings of the 34th ACM International Conference on Information and Knowledge Management, pages 478–487, 2025. 3
2025
-
[22]
Why can gpt learn in-context? language models secretly perform gradient descent as meta optimizers
Damai Dai, Yutao Sun, Li Dong, Yaru Hao, Shuming Ma, Zhifang Sui, and Furu Wei. Why can gpt learn in-context? language models implicitly perform gradient descent as meta-optimizers.arXiv preprint arXiv:2212.10559, 2022. 3
-
[23]
Yuqin Dai, Zhouheng Yao, Chunfeng Song, Qihao Zheng, Weijian Mai, Kunyu Peng, Shuai Lu, Wanli Ouyang, Jian Yang, and Jiamin Wu. Mindaligner: Explicit brain functional alignment for cross-subject visual decoding from limited fmri data.arXiv preprint arXiv:2502.05034, 2025. 2
-
[24]
arXiv preprint arXiv:2209.11737 , volume=
Adrien Doerig, Tim C Kietzmann, Emily Allen, Yihan Wu, Thomas Naselaris, Kendrick Kay, and Ian Charest. Semantic scene descriptions as an objective of human vision.arXiv preprint arXiv:2209.11737, 2022. 3
-
[25]
Population receptive field estimates in human visual cortex.Neuroimage, 39(2):647–660,
Serge O Dumoulin and Brian A Wandell. Population receptive field estimates in human visual cortex.Neuroimage, 39(2):647–660,
-
[26]
What’s the opposite of a face? finding shared decodable concepts and their negations in the brain.arXiv e-prints, pages arXiv–2405, 2024
Cory Efird, Alex Murphy, Joel Zylberberg, and Alona Fyshe. What’s the opposite of a face? finding shared decodable concepts and their negations in the brain.arXiv e-prints, pages arXiv–2405, 2024. 2
2024
-
[27]
Seeing it all: Convolutional network layers map the function of the human visual system.NeuroImage, 152:184–194, 2017
Michael Eickenberg, Alexandre Gramfort, Ga ¨el Varoquaux, and Bertrand Thirion. Seeing it all: Convolutional network layers map the function of the human visual system.NeuroImage, 152:184–194, 2017. 2
2017
-
[28]
Matteo Ferrante, Furkan Ozcelik, Tommaso Boccato, Rufin VanRullen, and Nicola Toschi. Brain captioning: Decoding human brain activity into images and text.arXiv preprint arXiv:2305.11560, 2023. 3
-
[29]
Model-agnostic meta-learning for fast adaptation of deep networks
Chelsea Finn, Pieter Abbeel, and Sergey Levine. Model-agnostic meta-learning for fast adaptation of deep networks. InInternational conference on machine learning, pages 1126–1135. PMLR, 2017. 3
2017
-
[30]
Brain netflix: Scaling data to reconstruct videos from brain signals
Camilo Fosco, Benjamin Lahner, Bowen Pan, Alex Andonian, Emilie Josephs, Alex Lascelles, and Aude Oliva. Brain netflix: Scaling data to reconstruct videos from brain signals. InEuropean Conference on Computer Vision, pages 457–474. Springer, 2024. 3
2024
-
[31]
What can transformers learn in-context? a case study of simple function classes.Advances in Neural Information Processing Systems, 35:30583–30598, 2022
Shivam Garg, Dimitris Tsipras, Percy S Liang, and Gregory Valiant. What can transformers learn in-context? a case study of simple function classes.Advances in Neural Information Processing Systems, 35:30583–30598, 2022. 3
2022
-
[32]
Expertise for cars and birds recruits brain areas involved in face recognition.Nature neuroscience, 3(2):191–197, 2000
Isabel Gauthier, Pawel Skudlarski, John C Gore, and Adam W Anderson. Expertise for cars and birds recruits brain areas involved in face recognition.Nature neuroscience, 3(2):191–197, 2000. 1
2000
-
[33]
Self-supervised natural image reconstruction and large-scale semantic classification from brain activity.NeuroImage, 254:119121, 2022
Guy Gaziv, Roman Beliy, Niv Granot, Assaf Hoogi, Francesca Strappini, Tal Golan, and Michal Irani. Self-supervised natural image reconstruction and large-scale semantic classification from brain activity.NeuroImage, 254:119121, 2022. 2
2022
-
[34]
What opportunities do large-scale visual neural datasets offer to the vision sciences community?Journal of Vision, 24(10):152–152, 2024
Alessandro T Gifford, Benjamin Lahner, Pablo Oyarzo, Aude Oliva, Gemma Roig, and Radoslaw M Cichy. What opportunities do large-scale visual neural datasets offer to the vision sciences community?Journal of Vision, 24(10):152–152, 2024. 2
2024
-
[35]
A large-scale fmri dataset for the visual processing of naturalistic scenes.Scientific Data, 10(1):559, 2023
Zhengxin Gong, Ming Zhou, Yuxuan Dai, Yushan Wen, Youyi Liu, and Zonglei Zhen. A large-scale fmri dataset for the visual processing of naturalistic scenes.Scientific Data, 10(1):559, 2023. 1
2023
-
[36]
Neuroclips: Towards high-fidelity and smooth fMRI-to-video reconstruction
Zixuan Gong, Guangyin Bao, Qi Zhang, Zhongwei Wan, Duoqian Miao, Shoujin Wang, Lei Zhu, Changwei Wang, Rongtao Xu, Liang Hu, Ke Liu, and Yu Zhang. Neuroclips: Towards high-fidelity and smooth fMRI-to-video reconstruction. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. 3
2024
-
[37]
NeuroGen: activation optimized image synthesis for discovery neuroscience.NeuroIm- age, 247:118812, 2022
Zijin Gu, Keith Wakefield Jamison, Meenakshi Khosla, Emily J Allen, Yihan Wu, Ghislain St-Yves, Thomas Naselaris, Kendrick Kay, Mert R Sabuncu, and Amy Kuceyeski. NeuroGen: activation optimized image synthesis for discovery neuroscience.NeuroIm- age, 247:118812, 2022. 3
2022
-
[38]
Deep neural networks reveal a gradient in the complexity of neural representations across the ventral stream.Journal of Neuroscience, 35(27):10005–10014, 2015
Umut G ¨uc ¸l¨u and Marcel AJ Van Gerven. Deep neural networks reveal a gradient in the complexity of neural representations across the ventral stream.Journal of Neuroscience, 35(27):10005–10014, 2015. 2
2015
-
[39]
Neuro-3d: Towards 3d visual decoding from eeg signals
Zhanqiang Guo, Jiamin Wu, Yonghao Song, Jiahui Bu, Weijian Mai, Qihao Zheng, Wanli Ouyang, and Chunfeng Song. Neuro-3d: Towards 3d visual decoding from eeg signals. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 23870–23880, 2025. 3
2025
-
[40]
Variational autoencoder: An unsupervised model for encoding and decoding fmri activity in visual cortex.NeuroImage, 198:125–136, 2019
Kuan Han, Haiguang Wen, Junxing Shi, Kun-Han Lu, Yizhen Zhang, Di Fu, and Zhongming Liu. Variational autoencoder: An unsupervised model for encoding and decoding fmri activity in visual cortex.NeuroImage, 198:125–136, 2019. 2
2019
-
[41]
On the interpretation of weight vectors of linear models in multivariate neuroimaging.Neuroimage, 87:96–110, 2014
Stefan Haufe, Frank Meinecke, Kai G ¨orgen, Sven D¨ahne, John-Dylan Haynes, Benjamin Blankertz, and Felix Bießmann. On the interpretation of weight vectors of linear models in multivariate neuroimaging.Neuroimage, 87:96–110, 2014. 3
2014
-
[42]
Distributed and overlapping representations of faces and objects in ventral temporal cortex.Science, 293(5539):2425–2430, 2001
James V Haxby, M Ida Gobbini, Maura L Furey, Alumit Ishai, Jennifer L Schouten, and Pietro Pietrini. Distributed and overlapping representations of faces and objects in ventral temporal cortex.Science, 293(5539):2425–2430, 2001. 3
2001
-
[43]
Decoding mental states from brain activity in humans.Nature reviews neuroscience, 7(7): 523–534, 2006
John-Dylan Haynes and Geraint Rees. Decoding mental states from brain activity in humans.Nature reviews neuroscience, 7(7): 523–534, 2006. 3
2006
-
[44]
Things-data, a multimodal collection of large-scale datasets for investigating object representa- tions in human brain and behavior.Elife, 12:e82580, 2023
Martin N Hebart, Oliver Contier, Lina Teichmann, Adam H Rockter, Charles Y Zheng, Alexis Kidder, Anna Corriveau, Maryam Vaziri-Pashkam, and Chris I Baker. Things-data, a multimodal collection of large-scale datasets for investigating object representa- tions in human brain and behavior.Elife, 12:e82580, 2023. 1
2023
-
[45]
Generic decoding of seen and imagined objects using hierarchical visual features
Tomoyasu Horikawa and Yukiyasu Kamitani. Generic decoding of seen and imagined objects using hierarchical visual features. Nature communications, 8(1):15037, 2017. 1
2017
-
[46]
Meta-learning in neural networks: A survey.IEEE transactions on pattern analysis and machine intelligence, 44(9):5149–5169, 2021
Timothy Hospedales, Antreas Antoniou, Paul Micaelli, and Amos Storkey. Meta-learning in neural networks: A survey.IEEE transactions on pattern analysis and machine intelligence, 44(9):5149–5169, 2021. 3
2021
-
[47]
arXiv preprint arXiv:2405.06459 , year=
Hyejeong Jo, Yiqian Yang, Juhyeok Han, Yiqun Duan, Hui Xiong, and Won Hee Lee. Are eeg-to-text models working?arXiv preprint arXiv:2405.06459, 2024. 3
-
[48]
Decoding the visual and subjective contents of the human brain.Nature neuroscience, 8(5): 679–685, 2005
Yukiyasu Kamitani and Frank Tong. Decoding the visual and subjective contents of the human brain.Nature neuroscience, 8(5): 679–685, 2005. 2
2005
-
[49]
Identifying natural images from human brain activity
Kendrick N Kay, Thomas Naselaris, Ryan J Prenger, and Jack L Gallant. Identifying natural images from human brain activity. Nature, 452(7185):352–355, 2008. 3
2008
-
[50]
High-level visual areas act like domain-general filters with strong selectivity and functional specialization.bioRxiv, pages 2022–03, 2022
Meenakshi Khosla and Leila Wehbe. High-level visual areas act like domain-general filters with strong selectivity and functional specialization.bioRxiv, pages 2022–03, 2022. 2
2022
-
[51]
Characterizing the ventral visual stream with response- optimized neural encoding models.Advances in Neural Information Processing Systems, 35:9389–9402, 2022
Meenakshi Khosla, Keith Jamison, Amy Kuceyeski, and Mert Sabuncu. Characterizing the ventral visual stream with response- optimized neural encoding models.Advances in Neural Information Processing Systems, 35:9389–9402, 2022. 2
2022
-
[52]
what” and “where
David Klindt, Alexander S Ecker, Thomas Euler, and Matthias Bethge. Neural system identification for large populations separating “what” and “where”.Advances in neural information processing systems, 30, 2017. 2
2017
-
[53]
Shape perception simultaneously up-and downregulates neural activity in the primary visual cortex.Current Biology, 24(13):1531–1535, 2014
Peter Kok and Floris P De Lange. Shape perception simultaneously up-and downregulates neural activity in the primary visual cortex.Current Biology, 24(13):1531–1535, 2014. 3
2014
-
[54]
Prior expectations bias sensory representations in visual cortex.Journal of Neuroscience, 33(41):16275–16284, 2013
Peter Kok, Gijs Joost Brouwer, Marcel AJ van Gerven, and Floris P de Lange. Prior expectations bias sensory representations in visual cortex.Journal of Neuroscience, 33(41):16275–16284, 2013. 3
2013
-
[55]
Toward generalizing visual brain decoding to unseen subjects.arXiv preprint arXiv:2410.14445, 2024
Xiangtao Kong, Kexin Huang, Ping Li, and Lei Zhang. Toward generalizing visual brain decoding to unseen subjects.arXiv preprint arXiv:2410.14445, 2024. 3, 5, 7
-
[56]
Scaling Vision Transformers for Functional MRI with Flat Maps
Connor Lane, Daniel Z Kaplan, Tanishq Mathew Abraham, and Paul S Scotti. Scaling vision transformers for functional mri with flat maps.arXiv preprint arXiv:2510.13768, 2025. 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[57]
Parallel backpropagation for shared-feature visualization.Advances in Neural Information Processing Systems, 37:22993–23012,
Alexander Lappe, Anna Bogn ´ar, Ghazaleh Ghamkahri Nejad, Albert Mukovskiy, Lucas Martini, Martin Giese, and Rufin V ogels. Parallel backpropagation for shared-feature visualization.Advances in Neural Information Processing Systems, 37:22993–23012,
-
[58]
Dongyang Li, Chen Wei, Shiying Li, Jiachen Zou, Haoyang Qin, and Quanying Liu. Visual decoding and reconstruction via eeg embeddings with guided diffusion.arXiv preprint arXiv:2403.07721, 2024. 3
-
[59]
Triple-n dataset: Non-human primate neural responses to natural scenes.BioRxiv, pages 2025–05, 2025
Yipeng Li, Wei Jin, Jia Yang, Wanru Li, Baoqi Gong, Xieyi Liu, Zhengxin Gong, Kesheng Wang, Zishuo Zhao, Jingqiu Luo, et al. Triple-n dataset: Non-human primate neural responses to natural scenes.BioRxiv, pages 2025–05, 2025. 1
2025
-
[60]
Eeg2video: Towards decoding dynamic visual perception from eeg signals.Advances in Neural Information Processing Systems, 37:72245–72273, 2024
Xuan-Hao Liu, Yan-Kai Liu, Yansen Wang, Kan Ren, Hanwen Shi, Zilong Wang, Dongsheng Li, Bao-Liang Lu, and Wei-Long Zheng. Eeg2video: Towards decoding dynamic visual perception from eeg signals.Advances in Neural Information Processing Systems, 37:72245–72273, 2024. 3
2024
-
[61]
Yulong Liu, Yongqiang Ma, Wei Zhou, Guibo Zhu, and Nanning Zheng. Brainclip: Bridging brain and visual-linguistic representa- tion via clip for generic natural visual stimulus decoding from fmri.arXiv preprint arXiv:2302.12971, 2023. 3
-
[62]
Yizhuo Lu, Changde Du, Dianpeng Wang, and Huiguang He. Minddiffuser: Controlled image reconstruction from human brain activity with semantic and structural diffusion.arXiv preprint arXiv:2303.14139, 2023. 3
-
[63]
Tarr, and Leila Wehbe
Andrew Luo, Margaret Marie Henderson, Michael J. Tarr, and Leila Wehbe. Brainscuba: Fine-grained natural language captions of visual cortex selectivity. InThe Twelfth International Conference on Learning Representations, 2024. 3
2024
-
[64]
Andrew F Luo, Margaret M Henderson, Leila Wehbe, and Michael J Tarr. Brain diffusion for visual exploration: Cortical discovery using large scale generative models.arXiv preprint arXiv:2306.03089, 2023. 3, 6
-
[65]
Andrew F Luo, Jacob Yeung, Rushikesh Zawar, Shaurya Dewan, Margaret M Henderson, Leila Wehbe, and Michael J Tarr. Brain mapping with dense features: Grounding cortical semantic selectivity in natural images with vision transformers.arXiv preprint arXiv:2410.05266, 2024. 2
-
[66]
Weijian Mai and Zhijun Zhang. Unibrain: Unify image reconstruction and captioning all in one diffusion model from human brain activity.arXiv preprint arXiv:2308.07428, 2023. 3
-
[67]
Brain-conditional multimodal synthesis: A survey and taxonomy.IEEE Transactions on Artificial Intelligence, 6(5):1080–1099, 2024
Weijian Mai, Jian Zhang, Pengfei Fang, and Zhijun Zhang. Brain-conditional multimodal synthesis: A survey and taxonomy.IEEE Transactions on Artificial Intelligence, 6(5):1080–1099, 2024. 2
2024
-
[68]
Weijian Mai, Jiamin Wu, Yu Zhu, Zhouheng Yao, Dongzhan Zhou, Andrew F Luo, Qihao Zheng, Wanli Ouyang, and Chunfeng Song. Synbrain: Enhancing visual-to-fmri synthesis via probabilistic representation learning.arXiv preprint arXiv:2508.10298,
-
[69]
Lavca: Llm-assisted visual cortex captioning.arXiv preprint arXiv:2502.13606, 2025
Takuya Matsuyama, Shinji Nishimoto, and Yu Takagi. Lavca: Llm-assisted visual cortex captioning.arXiv preprint arXiv:2502.13606, 2025. 3
-
[70]
A high-performance neuroprosthesis for speech decoding and avatar control
Sean L Metzger, Kaylo T Littlejohn, Alexander B Silva, David A Moses, Margaret P Seaton, Ran Wang, Maximilian E Dougherty, Jessie R Liu, Peter Wu, Michael A Berger, et al. A high-performance neuroprosthesis for speech decoding and avatar control. Nature, 620(7976):1037–1046, 2023. 3
2023
-
[71]
arXiv preprint arXiv:2110.15943 , year=
Sewon Min, Mike Lewis, Luke Zettlemoyer, and Hannaneh Hajishirzi. Metaicl: Learning to learn in context.arXiv preprint arXiv:2110.15943, 2021. 3
-
[72]
Bayesian reconstruction of natural images from human brain activity.Neuron, 63(6):902–915, 2009
Thomas Naselaris, Ryan J Prenger, Kendrick N Kay, Michael Oliver, and Jack L Gallant. Bayesian reconstruction of natural images from human brain activity.Neuron, 63(6):902–915, 2009. 3
2009
-
[73]
Encoding and decoding in fMRI.Neuroimage, 56(2): 400–410, 2011
Thomas Naselaris, Kendrick N Kay, Shinji Nishimoto, and Jack L Gallant. Encoding and decoding in fMRI.Neuroimage, 56(2): 400–410, 2011. 2
2011
-
[74]
On First-Order Meta-Learning Algorithms
Alex Nichol, Joshua Achiam, and John Schulman. On first-order meta-learning algorithms.arXiv preprint arXiv:1803.02999, 2018. 3
work page Pith review arXiv 2018
-
[75]
Reconstructing visual experiences from brain activity evoked by natural movies.Current biology, 21(19):1641–1646, 2011
Shinji Nishimoto, An T Vu, Thomas Naselaris, Yuval Benjamini, Bin Yu, and Jack L Gallant. Reconstructing visual experiences from brain activity evoked by natural movies.Current biology, 21(19):1641–1646, 2011. 3
2011
-
[76]
Beyond mind-reading: multi-voxel pattern analysis of fmri data.Trends in cognitive sciences, 10(9):424–430, 2006
Kenneth A Norman, Sean M Polyn, Greg J Detre, and James V Haxby. Beyond mind-reading: multi-voxel pattern analysis of fmri data.Trends in cognitive sciences, 10(9):424–430, 2006. 2
2006
-
[77]
Mental imagery of faces and places activates corresponding stimulus-specific brain regions.Journal of cognitive neuroscience, 12(6):1013–1023, 2000
Kathleen M O’Craven and Nancy Kanwisher. Mental imagery of faces and places activates corresponding stimulus-specific brain regions.Journal of cognitive neuroscience, 12(6):1013–1023, 2000. 3
2000
-
[78]
Speech language models lack important brain-relevant semantics
Subba Reddy Oota, Emin C ¸ elik, Fatma Deniz, and Mariya Toneva. Speech language models lack important brain-relevant semantics. arXiv preprint arXiv:2311.04664, 2023. 3
-
[79]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timoth ´ee Darcet, Th ´eo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haz- iza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision.arXiv preprint arXiv:2304.07193, 2023. 10
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[80]
Furkan Ozcelik and Rufin VanRullen. Brain-diffuser: Natural scene reconstruction from fmri signals using generative latent diffu- sion.arXiv preprint arXiv:2303.05334, 2023. 3
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.