Recognition: unknown
ParseBench: A Document Parsing Benchmark for AI Agents
Pith reviewed 2026-05-10 17:15 UTC · model grok-4.3
The pith
Current document parsing methods show inconsistent performance across dimensions critical for AI agents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ParseBench is introduced as a benchmark spanning about 2000 pages from insurance, finance, and government documents. Organized into five capability dimensions, it evaluates a range of parsing approaches and establishes that capabilities remain fragmented with persistent gaps for agent applications.
What carries the argument
ParseBench benchmark organized around five dimensions of semantic correctness for document parsing.
If this is right
- Improved parsers are needed that balance performance across all dimensions rather than specializing in one.
- Benchmarks for document parsing should incorporate semantic and structural evaluations instead of relying solely on text similarity.
- AI agent systems can use such benchmarks to select or fine-tune parsers for enterprise automation tasks.
- The identified gaps indicate specific areas like chart interpretation where further research is required.
Where Pith is reading between the lines
- Agent designers might implement fallback mechanisms or verification steps when using current parsers.
- Extending the benchmark to include more diverse document types could reveal additional challenges.
- The emphasis on semantic correctness may influence how future vision-language models are trained for parsing tasks.
Load-bearing premise
That the five dimensions chosen adequately cover the semantic correctness requirements for AI agents operating on enterprise documents.
What would settle it
Finding or developing a parsing method that maintains high accuracy in all five dimensions on the benchmark's documents would falsify the observation of a fragmented capability landscape.
Figures



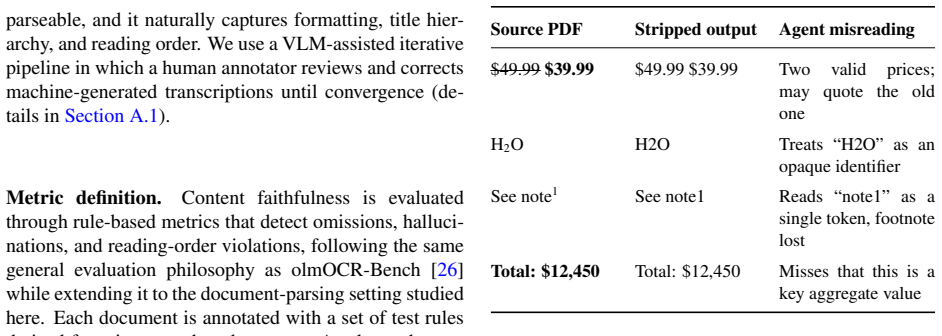

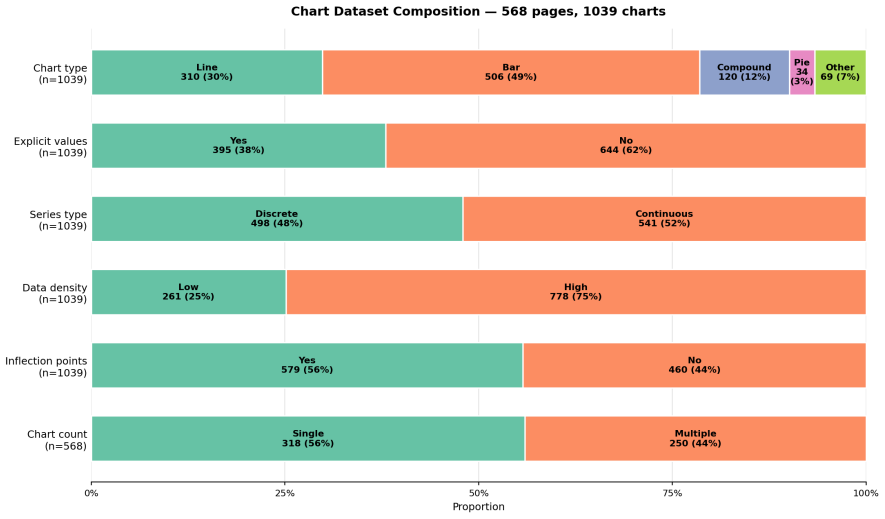
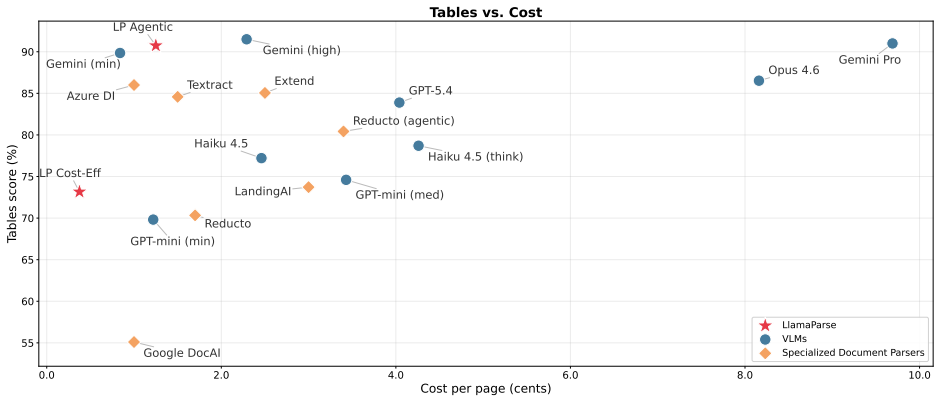




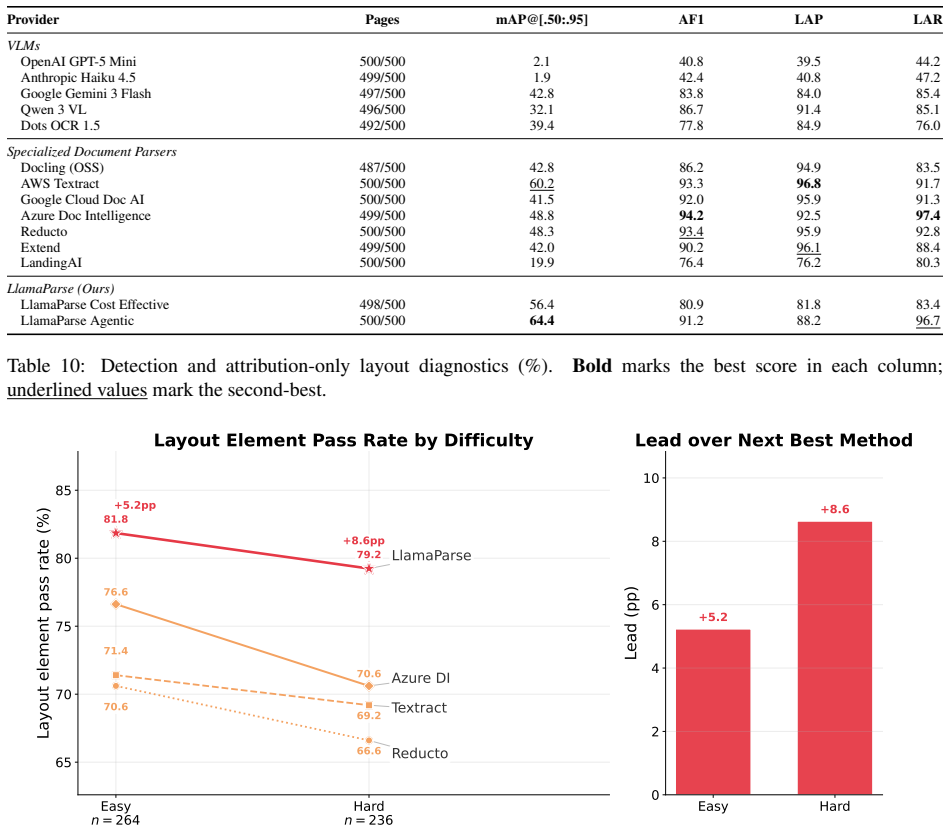






read the original abstract
AI agents are changing the requirements for document parsing. What matters is semantic correctness: parsed output must preserve the structure and meaning needed for autonomous decisions, including correct table structure, precise chart data, semantically meaningful formatting, and visual grounding. Existing benchmarks do not fully capture this setting for enterprise automation, relying on narrow document distributions and text-similarity metrics that miss agent-critical failures. We introduce ParseBench, a benchmark of ${\sim}2{,}000$ human-verified pages from enterprise documents spanning insurance, finance, and government, organized around five capability dimensions: tables, charts, content faithfulness, semantic formatting, and visual grounding. Across 14 methods spanning vision-language models, specialized document parsers, and LlamaParse, the benchmark reveals a fragmented capability landscape: no method is consistently strong across all five dimensions. LlamaParse Agentic achieves the highest overall score at 84.9%, and the benchmark highlights the remaining capability gaps across current systems. Dataset and evaluation code are available on https://huggingface.co/datasets/llamaindex/ParseBench and https://github.com/run-llama/ParseBench.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ParseBench, a benchmark of ~2,000 human-verified pages drawn from enterprise documents in insurance, finance, and government. It organizes evaluation around five capability dimensions (tables, charts, content faithfulness, semantic formatting, visual grounding) and reports results for 14 methods spanning VLMs, specialized parsers, and LlamaParse. The central finding is a fragmented capability landscape in which no method is consistently strong across all dimensions, with LlamaParse Agentic attaining the highest overall score of 84.9%. Dataset and evaluation code are released publicly.
Significance. If the benchmark construction and metrics prove reliable, ParseBench supplies a needed resource for assessing document parsers under the semantic-correctness requirements of autonomous agents. The public release of the dataset and code is a clear strength that supports reproducibility and community follow-up.
major comments (2)
- [Abstract and benchmark construction] The abstract and benchmark-construction description provide no explicit definitions of the per-dimension metrics, no page-selection criteria, and no inter-annotator agreement statistics for the human verification step. These omissions directly limit independent verification of the reported scores and of the claim that capabilities are fragmented.
- [Evaluation results] The headline result that 'no method is consistently strong across all five dimensions' is asserted without accompanying per-dimension score tables or breakdowns in the provided summary; such tables are required to substantiate the fragmentation conclusion and to allow readers to assess whether LlamaParse Agentic's 84.9% overall score masks specific weaknesses.
minor comments (2)
- [Introduction] The five dimensions and the chosen document domains are presented as capturing agent-critical semantic needs, yet the manuscript does not discuss potential gaps such as multi-page table continuity or cross-reference resolution; a short paragraph acknowledging these scope limitations would strengthen the paper.
- [Dataset and code availability] Ensure that the released evaluation code on GitHub includes the exact scripts used to compute the 84.9% aggregate score so that future comparisons remain reproducible.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback and recommendation for minor revision. We address each of the major comments below and commit to revisions that will improve the manuscript's clarity and verifiability.
read point-by-point responses
-
Referee: [Abstract and benchmark construction] The abstract and benchmark-construction description provide no explicit definitions of the per-dimension metrics, no page-selection criteria, and no inter-annotator agreement statistics for the human verification step. These omissions directly limit independent verification of the reported scores and of the claim that capabilities are fragmented.
Authors: We acknowledge that the abstract, being a high-level summary, does not contain these specifics. The full paper describes the benchmark construction in detail, but to directly address this comment, we will revise the manuscript to include explicit definitions of the per-dimension metrics early in the benchmark section, specify the page-selection criteria, and report the inter-annotator agreement statistics for the human verification. These additions will be made in a new or expanded subsection to support independent verification. revision: yes
-
Referee: [Evaluation results] The headline result that 'no method is consistently strong across all five dimensions' is asserted without accompanying per-dimension score tables or breakdowns in the provided summary; such tables are required to substantiate the fragmentation conclusion and to allow readers to assess whether LlamaParse Agentic's 84.9% overall score masks specific weaknesses.
Authors: The manuscript's results section presents the overall scores and discusses the fragmentation, but we agree that dedicated per-dimension tables are essential for full substantiation. We will add or expand the per-dimension score tables and breakdowns in the evaluation results to clearly show performance across all five dimensions for each method. This will allow readers to verify the claim and evaluate LlamaParse Agentic's specific profile. revision: yes
Circularity Check
No circularity: purely empirical benchmark with direct ground-truth evaluation
full rationale
The paper introduces ParseBench as a new empirical benchmark consisting of ~2000 human-verified enterprise document pages scored across five author-defined capability dimensions. It reports direct evaluation results for 14 methods (including LlamaParse Agentic) against this ground truth, with no equations, derivations, fitted parameters, predictions derived from inputs, or load-bearing self-citations. The central claims (fragmented landscape, highest score of 84.9%) follow immediately from the tabulated scores on the held-out verified pages. This is self-contained against external human annotations and contains none of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Human verification of parsed output provides reliable ground truth for semantic correctness in tables, charts, formatting, faithfulness, and visual grounding.
Reference graph
Works this paper leans on
-
[1]
Amazon Textract pricing
Amazon Web Services. Amazon Textract pricing. https://aws.amazon.com/textract/ pricing/, 2026. Accessed: 2026-04-01
2026
-
[2]
Claude Haiku 4.5 System Card
Anthropic. Claude Haiku 4.5 System Card. Technical report, October 2025. URL https://www-cdn.anthropic.com/ 7aad69bf12627d42234e01ee7c36305dc2f6a970. pdf
2025
-
[3]
Claude Opus 4.5 System Card
Anthropic. Claude Opus 4.5 System Card. Technical report, November 2025. URL https://www-cdn.anthropic.com/ bf10f64990cfda0ba858290be7b8cc6317685f47. pdf
2025
-
[4]
Claude pricing.https: //platform.claude.com/docs/en/ about-claude/pricing, 2026
Anthropic. Claude pricing.https: //platform.claude.com/docs/en/ about-claude/pricing, 2026. Accessed: 2026-04-01
2026
-
[5]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhi- fang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhaohai Li, Ming- sheng Li, Mei Li, Kaixin Li, Zicheng Lin, Jun- yang Lin, Xuejing Liu, Jiawei Liu, Chenglong Liu, Yang Liu, Dayiheng Liu, Sh...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
PaddleOCR 3.0 Technical Report
Cheng Cui, Ting Sun, Manhui Lin, Tingquan Gao, Yubo Zhang, Jiaxuan Liu, Xueqing Wang, Zelun Zhang, Changda Zhou, Hongen Liu, Yue Zhang, Wenyu Lv, Kui Huang, Yichao Zhang, Jing Zhang, Jun Zhang, Yi Liu, Dianhai Yu, and Yanjun Ma. Pad- dleocr 3.0 technical report, 2025. URLhttps: //arxiv.org/abs/2507.05595
work page internal anchor Pith review arXiv 2025
-
[7]
How credits work – Extend AI
Extend AI. How credits work – Extend AI. https://docs.extend.ai/2026-02-09/ product/general/how-credits-work,
2026
-
[9]
Ling Fu, Zhebin Kuang, Jiajun Song, Mingxin Huang, Biao Yang, Yuzhe Li, Linghao Zhu, Qidi Luo, Xinyu Wang, Hao Lu, Zhang Li, Guozhi Tang, Bin Shan, Chunhui Lin, Qi Liu, Binghong Wu, Hao Feng, Hao Liu, Can Huang, Jingqun Tang, Wei Chen, Lianwen Jin, Yuliang Liu, and Xiang Bai. OCRBench v2: An improved bench- mark for evaluating large multimodal models on v...
-
[10]
Gemini API pricing.https://ai
Google. Gemini API pricing.https://ai. google.dev/gemini-api/docs/pricing,
-
[11]
Accessed: 2026-04-01
2026
-
[12]
Google cloud Document AI pricing.https://cloud.google.com/ document-ai/pricing, 2026
Google Cloud. Google cloud Document AI pricing.https://cloud.google.com/ document-ai/pricing, 2026. Accessed: 2026-04-01
2026
-
[13]
Gemini 3 flash model card
Google DeepMind. Gemini 3 flash model card. Technical report, Google DeepMind, December 2025. URL https://storage.googleapis.com/ deepmind-media/Model-Cards/ Gemini-3-Flash-Model-Card.pdf
2025
-
[14]
Granite Vision Team, Leonid Karlinsky, Assaf Ar- belle, Abraham Daniels, Ahmed Nassar, et al. Gran- ite vision: A lightweight, open-source multimodal model for enterprise intelligence, 2025. URL https://arxiv.org/abs/2502.09927
-
[15]
Efficient memory management for large language model serving with PagedAttention
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gon- zalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. InProceedings of the 29th Sym- posium on Operating Systems Principles (SOSP), pages 611–626. ACM, 2023. doi: 10.1145/3600006. 3613165
-
[16]
Landingai Document Extraction pricing.https://docs.landing.ai/ade/ ade-pricing, 2026
LandingAI. Landingai Document Extraction pricing.https://docs.landing.ai/ade/ ade-pricing, 2026. Accessed: 2026-04-01
2026
-
[17]
Yumeng Li, Guang Yang, Hao Liu, Bowen Wang, and Colin Zhang. dots.ocr: Multilingual docu- ment layout parsing in a single vision-language model, 2025. URLhttps://arxiv.org/ abs/2512.02498
-
[18]
Lawrence Zitnick
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C. Lawrence Zitnick. Microsoft COCO: Common objects in context. InEuropean Confer- ence on Computer Vision (ECCV), pages 740–755. Springer, 2014. 13
2014
-
[19]
Nikolaos Livathinos, Christoph Auer, Maksym Lysak, Ahmed Nassar, Michele Dolfi, Panos Vage- nas, Cesar Berrospi Ramis, Matteo Omenetti, Kasper Dinkla, Yusik Kim, Shubham Gupta, Rafael Teixeira de Lima, Valery Weber, Lu- cas Morin, Ingmar Meijer, Viktor Kuropiatnyk, and Peter W. J. Staar. Docling: An efficient open-source toolkit for ai-driven document con...
-
[20]
Llamacloud pricing.https: //developers.llamaindex.ai/python/ cloud/general/pricing/, 2026
LlamaIndex. Llamacloud pricing.https: //developers.llamaindex.ai/python/ cloud/general/pricing/, 2026. Accessed: 2026-04-01
2026
-
[21]
ChartQA: A benchmark for question answering about charts with visual and logical reasoning
Ahmed Masry, Do Xuan Long, Jia Qing Tan, Shafiq Joty, and Enamul Hoque. ChartQA: A benchmark for question answering about charts with visual and logical reasoning. InFindings of the Association for Computational Linguistics: ACL 2022, pages 2263–2279. Association for Computational Linguis- tics, 2022
2022
-
[22]
Azure AI Document Intelligence pricing.https://azure.microsoft
Microsoft. Azure AI Document Intelligence pricing.https://azure.microsoft. com/en-us/pricing/details/ document-intelligence/, 2026. Accessed: 2026-04-01
2026
-
[23]
Modal: AI infrastructure that develop- ers love.https://modal.com, 2026
Modal Labs. Modal: AI infrastructure that develop- ers love.https://modal.com, 2026. Accessed: 2026-04-01
2026
-
[24]
OpenAI. OpenAI GPT-5 System Card.arXiv preprint arXiv:2601.03267, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
OpenAI API pricing.https: //developers.openai.com/api/docs/ pricing, 2026
OpenAI. OpenAI API pricing.https: //developers.openai.com/api/docs/ pricing, 2026. Accessed: 2026-04-01
2026
-
[26]
OmniDocBench: Benchmarking diverse PDF document parsing with comprehensive anno- tations
Linke Ouyang, Yuan Qu, Hongbin Zhou, Jiawei Zhu, Rui Zhang, Qunshu Lin, Bin Wang, Zhiyuan Zhao, Man Jiang, Xiaomeng Zhao, Jin Shi, Fan Wu, Pei Chu, Minghao Liu, Zhenxiang Li, Chao Xu, Bo Zhang, Botian Shi, Zhongying Tu, and Con- ghui He. OmniDocBench: Benchmarking diverse PDF document parsing with comprehensive anno- tations. InProceedings of the IEEE/CVF...
2025
-
[27]
Birgit Pfitzmann, Christoph Auer, Michele Dolfi, Ahmed S. Nassar, and Peter Staar. Doclaynet: A large human-annotated dataset for document- layout segmentation. InProceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 3743–3751. ACM, August 2022. doi: 10.1145/3534678. 3539043. URLhttp://dx.doi.org/10. 1145/3534678.3539043
-
[28]
Jake Poznanski, Aman Rangapur, Jon Borchardt, Ja- son Dunkelberger, Regan Huff, Daniel Lin, Aman Rangapur, Christopher Wilhelm, Kyle Lo, and Luca Soldaini. olmocr: Unlocking trillions of tokens in pdfs with vision language models, 2025. URL https://arxiv.org/abs/2502.18443
-
[29]
Credit usage – Reducto.https: //docs.reducto.ai/reference/ credit-usage, 2026
Reducto. Credit usage – Reducto.https: //docs.reducto.ai/reference/ credit-usage, 2026. Accessed: 2026-04- 01
2026
-
[30]
Grits: Grid table similarity metric for ta- ble structure recognition, 2023
Brandon Smock, Rohith Pesala, and Robin Abra- ham. Grits: Grid table similarity metric for ta- ble structure recognition, 2023. URLhttps:// arxiv.org/abs/2203.12555
-
[31]
Bin Wang, Chao Xu, Xiaomeng Zhao, Linke Ouyang, Fan Wu, Zhiyuan Zhao, Rui Xu, Kaiwen Liu, Yuan Qu, Fukai Shang, Bo Zhang, Liqun Wei, Zhihao Sui, Wei Li, Botian Shi, Yu Qiao, Dahua Lin, and Conghui He. Mineru: An open-source solution for precise document content extraction, 2024. URL https://arxiv.org/abs/2409.18839
-
[32]
Global ta- ble extractor (GTE): A framework for joint table identification and cell structure recognition using vi- sual context
Xinyi Zheng, Douglas Burdick, Lucian Popa, Xu Zhong, and Nancy Xin Ru Wang. Global ta- ble extractor (GTE): A framework for joint table identification and cell structure recognition using vi- sual context. InProceedings of the IEEE/CVF Win- ter Conference on Applications of Computer Vision (WACV), pages 697–706, 2021
2021
-
[33]
Image-based table recognition: Data, model, and evaluation
Xu Zhong, Elaheh ShafieiBavani, and Antonio Ji- meno Yepes. Image-based table recognition: Data, model, and evaluation. InEuropean Conference on Computer Vision (ECCV), pages 564–580. Springer, 2020
2020
-
[34]
editable
Xu Zhong, Elaheh ShafieiBavani, and Antonio Ji- meno Yepes. Image-based table recognition: Data, model, and evaluation. InEuropean Conference on Computer Vision (ECCV), pages 564–580. Springer, 2020. 14 Appendix Contents A Benchmark Construction Details 15 A.1 Annotation Pipeline . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . ...
2020
-
[35]
A VLM (Gemini 3.0 Flash) transcribes the source document into Markdown
-
[36]
A second VLM pass analyzes the Markdown against the original document, generating a quality report with suggested patches for any errors or omissions
-
[37]
A human annotator manually reviews the Markdown and approves or rejects patches in a custom-built annotation interface
-
[38]
Primary 2015
If modifications were made in step 3, we return to step 2 and re-generate patches for human review. The loop terminates when the annotator accepts the transcription without further edits. This VLM-in-the-loop approach substantially reduces annotation time compared to fully manual transcription, while the human review step ensures ground-truth quality. A.2...
2015
-
[39]
Bbox format: [x1, y1, x2, y2]
-
[40]
Layout Categories: The possible categories are [’Caption’, ’Footnote’, ’Formula’, ’List-item’, ’Page-footer’, ’Page-header’, ’Picture’, ’Section-header’, ’Table’, ’Text’, ’Title’]
-
[41]
For non-chart pictures, the text field should be omitted
Text Extraction & Formatting Rules: - Picture: If the picture is a chart or graph, extract all data points and format as an HTML table with flat combined column headers. For non-chart pictures, the text field should be omitted. - Formula: Format its text as LaTeX. - Table: Format its text as HTML. - All Others: Format their text as Markdown
-
[42]
All layout elements must be sorted according to human reading order
Constraints: The output text must be the original text from the image, with no translation. All layout elements must be sorted according to human reading order
-
[43]
Final Output: The entire output must be a single JSON object. Qwen 3 VL (8B).As a general-purpose VLM not specifically trained for document parsing or layout detection, Qwen 3 VL performs significantly worse when asked to produce both parsed content and layout annotations in a single prompt. We therefore use two separate pipelines: one for content parsing...
-
[44]
Bbox format: [x1, y1, x2, y2] using normalized 0-1000 coordinates
-
[45]
Layout Categories: [’Caption’, ’Footnote’, ’Formula’, ’List-item’, ’Page-footer’, ’Page-header’, ’Picture’, ’Section-header’, ’Table’, ’Text’, ’Title’]
-
[46]
Text Extraction & Formatting Rules: Picture charts as HTML tables, Formula as LaTeX, Table as HTML, all others as Markdown
-
[47]
Reading order
Constraints: Original text only, no translation. Reading order
-
[48]
502–6522
Final Output: Return ONLY a JSON array. C.3 Infrastructure Details Open-weight VLMs and the open-source Docling pipeline are deployed on Modal’s [21] serverless GPU infrastructure. Table 7 summarizes the hardware and software stack for each self-hosted model. Model GPU Serving Framework Version Notes Qwen 3 VL (8B) NVIDIA H100 vLLM 0.11.2 Full precision (...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.