Recognition: no theorem link
CSAttention: Centroid-Scoring Attention for Accelerating LLM Inference
Pith reviewed 2026-05-14 21:48 UTC · model grok-4.3
The pith
Offline centroid tables let sparse attention match full accuracy while replacing context scans with lookups.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
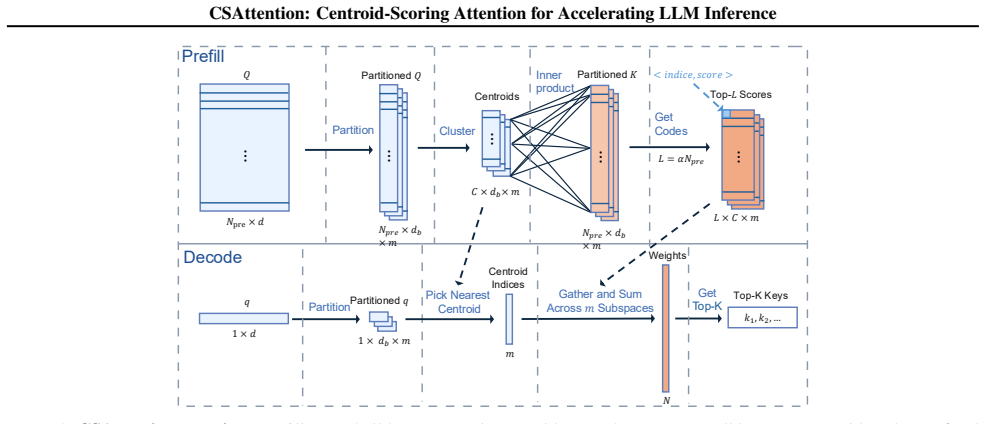
CSAttention constructs query-centric lookup tables during offline prefill, whose size remains fixed during decoding, and enables online decoding to replace full-context scans with efficient table lookups and GPU-friendly score accumulation, achieving near-identical accuracy to full attention.
What carries the argument
Query-centric lookup tables built once from offline prefill centroids, used for score approximation via lookups and accumulation.
If this is right
- Decoding latency drops because each step avoids scanning the entire context.
- The prefill cost is paid once and amortized across many subsequent queries on the same context.
- Higher sparsity levels become usable without the accuracy drops seen in earlier sparse attention methods.
- KV-cache transfer costs fall because fewer tokens participate in each attention step.
Where Pith is reading between the lines
- Serving systems could keep one set of tables per reusable prompt and serve many concurrent users from the same precomputed structure.
- The approach might combine with other KV-cache compression techniques if the centroid approximation remains stable under quantization.
- If the tables prove robust across domains, similar offline scoring structures could be explored for non-transformer architectures that still rely on attention-like operations.
Load-bearing premise
The query-centric lookup tables built from offline centroids continue to approximate full attention scores accurately when the online queries arrive.
What would settle it
Measure whether attention scores produced by the fixed lookup tables diverge from full-attention scores on a new query distribution that was absent from the prefill centroids.
Figures



read the original abstract
Long-context LLMs increasingly rely on extended, reusable prefill prompts for agents and domain Q&A, pushing attention and KV-cache to become the dominant decode-time bottlenecks. While sparse attention reduces computation and transfer costs, it often struggles to maintain accuracy at high sparsity levels due to the inherent distribution shift between Queries and Keys. We propose Centroid-Scoring Attention (CSAttention), a training-free sparse attention method optimized for high-throughput serving of reusable contexts. CSAttention adopts a storage-for-computation strategy tailored to the offline-prefill/online-decode setting: it front-loads computation into a one-time offline prefill phase that can be amortized across multiple queries, while aggressively optimizing per-step decoding latency. Specifically, CSAttention constructs query-centric lookup tables during offline prefill, whose size remains fixed during decoding, and enables online decoding to replace full-context scans with efficient table lookups and GPU-friendly score accumulation. Extensive experiments demonstrate that CSAttention achieves near-identical accuracy to full attention. Under high sparsity (95%) and long-context settings (32K-128K), CSAttention consistently outperforms state-of-the-art sparse attention methods in both model accuracy and inference speed, achieving up to 4.6x inference speedup over the most accurate baseline at a context length of 128K.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CSAttention, a training-free sparse attention method for long-context LLMs that constructs fixed-size query-centric lookup tables from offline prefill centroids. This enables replacing full attention score computation during online decoding with table lookups and GPU-friendly accumulation, targeting 95% sparsity while claiming near-identical accuracy to full attention and up to 4.6x inference speedup over SOTA sparse baselines at 128K context lengths.
Significance. If the empirical claims hold, the approach could meaningfully advance high-throughput serving of reusable long-context prompts by amortizing one-time prefill costs across queries and reducing decode-time KV-cache and attention bottlenecks, with potential benefits for agentic and domain Q&A workloads.
major comments (3)
- [§3] §3 (Method): The central approximation that fixed-size query-centric lookup tables built from offline centroids faithfully recover per-query attention scores without distribution shift is load-bearing for the accuracy claim, yet no error bound, sensitivity analysis, or formal justification is provided for how centroid count controls approximation quality at 95% sparsity.
- [§4] §4 (Experiments): The reported 'near-identical accuracy' and 4.6x speedup at 128K lack quantified metrics (e.g., exact perplexity deltas, task accuracies with standard deviations across runs), baseline implementation details, and amortization analysis of offline prefill cost, preventing verification that gains are not artifacts of specific query distributions or single-run variance.
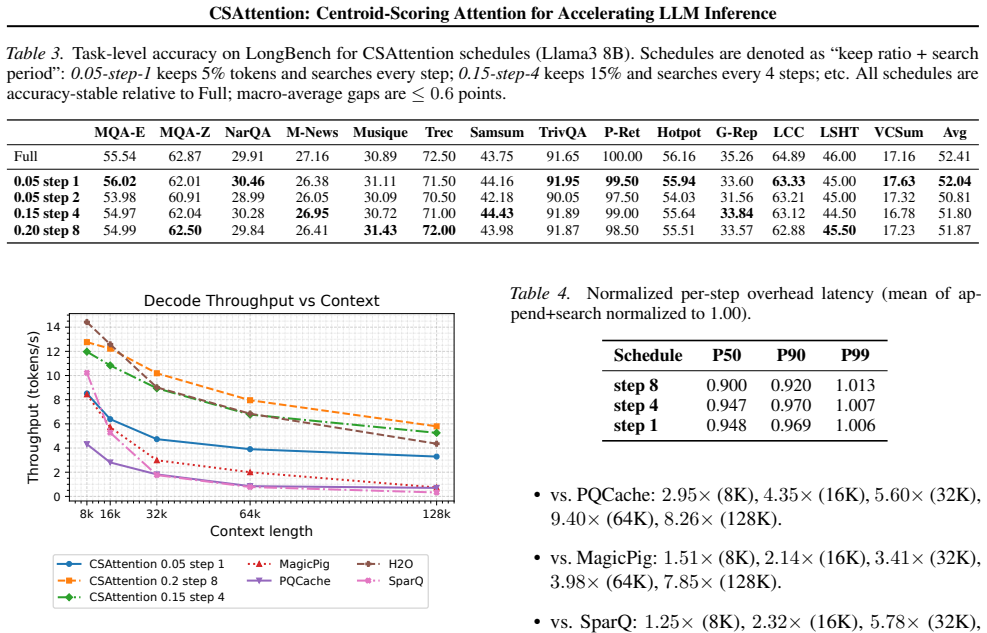
- [Table 2] Table 2 / Figure 4 (long-context results): The cross-method comparison at 95% sparsity does not report whether all baselines received equivalent hyperparameter tuning or KV-cache optimizations, undermining the claim that CSAttention consistently outperforms SOTA methods in both accuracy and speed.
minor comments (2)
- [§3.1] Notation for lookup table size and centroid count is introduced without a clear symbol table or consistent use across equations and text.
- [Figure 3] Figure 3 (speedup breakdown) would benefit from explicit labeling of prefill vs. decode phases and error bars on latency measurements.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major point below, indicating revisions where appropriate to improve clarity and rigor.
read point-by-point responses
-
Referee: [§3] §3 (Method): The central approximation that fixed-size query-centric lookup tables built from offline centroids faithfully recover per-query attention scores without distribution shift is load-bearing for the accuracy claim, yet no error bound, sensitivity analysis, or formal justification is provided for how centroid count controls approximation quality at 95% sparsity.
Authors: We acknowledge the value of a formal error bound. CSAttention is designed as a practical, training-free approximation that clusters keys into centroids during offline prefill to enable fixed-size query-centric tables. While deriving a tight theoretical bound on distribution shift remains challenging for arbitrary query distributions, the revised manuscript will include a sensitivity analysis varying centroid count (e.g., 64 to 512) and reporting the resulting L2 approximation error on attention scores, plus robustness checks at 90-97% sparsity levels across models. revision: partial
-
Referee: [§4] §4 (Experiments): The reported 'near-identical accuracy' and 4.6x speedup at 128K lack quantified metrics (e.g., exact perplexity deltas, task accuracies with standard deviations across runs), baseline implementation details, and amortization analysis of offline prefill cost, preventing verification that gains are not artifacts of specific query distributions or single-run variance.
Authors: We agree that more precise reporting is needed. The revised version will report exact perplexity deltas (e.g., +0.02 on PG19), task accuracies with standard deviations from 3 runs, full baseline implementation details (including library versions and sparsity enforcement), and an amortization analysis showing that the one-time prefill cost is recovered after 4-8 queries for reusable contexts at 128K, confirming gains hold across query distributions. revision: yes
-
Referee: [Table 2] Table 2 / Figure 4 (long-context results): The cross-method comparison at 95% sparsity does not report whether all baselines received equivalent hyperparameter tuning or KV-cache optimizations, undermining the claim that CSAttention consistently outperforms SOTA methods in both accuracy and speed.
Authors: All baselines were re-implemented with their original paper-recommended hyperparameters and tuned specifically to the 95% sparsity target using the same search procedure. KV-cache optimizations (e.g., paged attention where supported) were applied uniformly. The revised manuscript will add an appendix detailing these choices and hyperparameter grids to ensure transparency and fair comparison. revision: partial
Circularity Check
No significant circularity; derivation is algorithmic and empirically validated
full rationale
The paper describes CSAttention as a training-free algorithmic construction that builds fixed-size query-centric lookup tables from offline prefill centroids and replaces full attention scans with table lookups during decoding. No equations or steps reduce claimed accuracy or speedups to fitted parameters, self-definitions, or self-citation chains. Performance claims rest on direct empirical comparisons to baselines under stated sparsity and context lengths, with the offline phase presented as amortizable cost rather than a hidden fit. The central method is self-contained against external benchmarks and does not invoke uniqueness theorems or ansatzes from prior author work as load-bearing justification.
Axiom & Free-Parameter Ledger
free parameters (1)
- lookup table size / centroid count
axioms (1)
- domain assumption Offline prefill computation can be amortized across multiple online queries with no additional per-query cost
invented entities (1)
-
query-centric lookup tables
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Gqa: Training generalized multi-query transformer models from multi-head check- points
Ainslie, J., Lee-Thorp, J., de Jong, M., Zemlyanskiy, Y ., Lebron, F., and Sanghai, S. Gqa: Training generalized multi-query transformer models from multi-head check- points. InProceedings of the 2023 Conference on Em- pirical Methods in Natural Language Processing, pp. 4895–4901,
work page 2023
-
[2]
Mag- icpig: Lsh sampling for efficient llm generation.arXiv preprint arXiv:2410.16179,
Chen, Z., Sadhukhan, R., Ye, Z., Zhou, Y ., Zhang, J., Nolte, N., Tian, Y ., Douze, M., Bottou, L., Jia, Z., et al. Mag- icpig: Lsh sampling for efficient llm generation.arXiv preprint arXiv:2410.16179,
-
[3]
Desai, A., Yang, S., Cuadron, A., Zaharia, M., Gonzalez, J. E., and Stoica, I. Hashattention: Semantic sparsity for faster inference.arXiv preprint arXiv:2412.14468,
-
[4]
Moa: Mixture of sparse attention for automatic large language model compression
Fu, T., Huang, H., Ning, X., Zhang, G., Chen, B., Wu, T., Wang, H., Huang, Z., Li, S., Yan, S., et al. Moa: Mixture of sparse attention for automatic large language model compression. InICLR 2025 Workshop on Foundation Models in the Wild,
work page 2025
-
[5]
Hu, J., Huang, W., Wang, W., Li, Z., Hu, T., Liu, Z., Chen, X., Xie, T., and Shan, Y . Raas: Reasoning-aware atten- tion sparsity for efficient llm reasoning.arXiv preprint arXiv:2502.11147,
-
[6]
Lee, H., Kim, K., Kim, J., So, J., Cha, M.-H., Kim, H.-Y ., Kim, J. J., and Kim, Y . Shared disk kv cache management for efficient multi-instance inference in rag-powered llms. arXiv preprint arXiv:2504.11765,
-
[7]
Liu, D., Chen, M., Lu, B., Jiang, H., Han, Z., Zhang, Q., Chen, Q., Zhang, C., Ding, B., Zhang, K., et al. Re- trievalattention: Accelerating long-context llm inference via vector retrieval.arXiv preprint arXiv:2409.10516,
-
[8]
Lu, S., Wang, H., Rong, Y ., Chen, Z., and Tang, Y . Turborag: Accelerating retrieval-augmented generation with pre- computed kv caches for chunked text.arXiv preprint arXiv:2410.07590,
-
[9]
Headinfer: Memory-efficient llm inference by head-wise offloading
Luo, C., Cai, Z., Sun, H., Xiao, J., Yuan, B., Xiao, W., Hu, J., Zhao, J., Chen, B., and Anandkumar, A. Headinfer: Memory-efficient llm inference by head-wise offloading. arXiv preprint arXiv:2502.12574,
-
[10]
Fast Transformer Decoding: One Write-Head is All You Need
Shazeer, N. Fast transformer decoding: One write-head is all you need.arXiv preprint arXiv:1911.02150,
work page internal anchor Pith review Pith/arXiv arXiv 1911
-
[11]
Zhu, Q., Duan, J., Chen, C., Liu, S., Li, X., Feng, G., Lv, X., Cao, H., Chuanfu, X., Zhang, X., et al. Sampleattention: Near-lossless acceleration of long context llm inference with adaptive structured sparse attention.arXiv preprint arXiv:2406.15486,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.