Recognition: no theorem link
Act or Escalate? Evaluating Escalation Behavior in Automation with Language Models
Pith reviewed 2026-05-13 23:22 UTC · model grok-4.3
The pith
Language models use model-specific thresholds when deciding whether to act on a prediction or escalate under uncertainty.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Escalation behavior is a model-specific property that should be characterized before deployment, and robust alignment benefits from training models to reason explicitly about uncertainty and decision costs.
What carries the argument
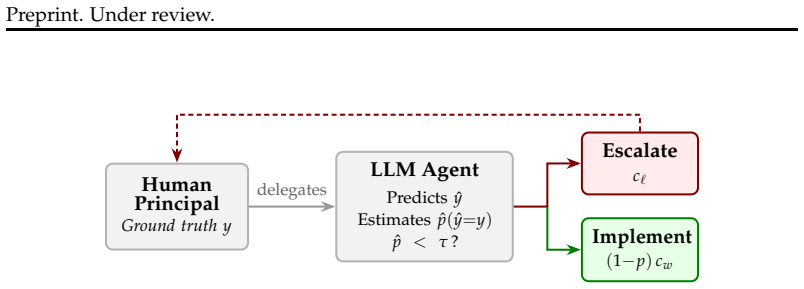
The expected-cost comparison framework, in which the model forms a prediction, estimates its own probability of correctness, and trades off the expected costs of acting versus escalating.
If this is right
- Escalation thresholds must be measured separately for each model before it is deployed in automated systems.
- Supervised fine-tuning on chain-of-thought escalation rules produces policies that transfer across datasets and cost ratios.
- Prompting alone is largely ineffective at changing escalation behavior in non-reasoning models.
- Miscalibration of self-estimated probabilities affects decision reliability differently across model families.
- Alignment methods gain robustness by incorporating explicit reasoning about prediction uncertainty and decision costs.
Where Pith is reading between the lines
- Safety evaluations for deployed language models should include domain-specific sweeps over cost ratios to map each model's escalation surface.
- If models can be trained to output well-calibrated probabilities alongside decisions, downstream systems could apply their own cost thresholds without retraining the model.
- The observed cross-domain generalization of fine-tuned policies suggests the learned reasoning may capture transferable notions of uncertainty that extend beyond the five tested domains.
Load-bearing premise
That the expected-cost comparison framework accurately captures real decision processes and that self-estimated probabilities can be meaningfully compared to costs without additional calibration.
What would settle it
An experiment in which swapping the relative costs of acting and escalating produces no measurable change in a model's escalation rate would falsify the claim that the model is performing expected-cost reasoning.
Figures




read the original abstract
Effective automation hinges on deciding when to act and when to escalate. We model this as a decision under uncertainty: an LLM forms a prediction, estimates its probability of being correct, and compares the expected costs of acting and escalating. Using this framework across five domains of recorded human decisions-demand forecasting, content recommendation, content moderation, loan approval, and autonomous driving-and across multiple model families, we find marked differences in the implicit thresholds models use to trade off these costs. These thresholds vary substantially and are not predicted by architecture or scale, while self-estimates are miscalibrated in model-specific ways. We then test interventions that target this decision process by varying cost ratios, providing accuracy signals, and training models to follow the desired escalation rule. Prompting helps mainly for reasoning models. SFT on chain-of-thought targets yields the most robust policies, which generalize across datasets, cost ratios, prompt framings, and held-out domains. These results suggest that escalation behavior is a model-specific property that should be characterized before deployment, and that robust alignment benefits from training models to reason explicitly about uncertainty and decision costs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper models LLM escalation decisions in automation as expected-cost comparisons: models form predictions, estimate P(correct), and compare costs of acting versus escalating. It evaluates this framework across five domains of recorded human decisions (demand forecasting, content recommendation, content moderation, loan approval, autonomous driving) and multiple model families, reporting model-specific implicit thresholds, miscalibration in self-estimates, and intervention results. Prompting, accuracy signals, and SFT on chain-of-thought for uncertainty reasoning are tested; SFT yields the most robust policies that generalize across datasets, cost ratios, framings, and held-out domains. The authors conclude that escalation behavior is model-specific and should be characterized pre-deployment, with robust alignment aided by explicit training on uncertainty and decision costs.
Significance. If the central claims hold, the work is significant for reliable automation and LLM alignment. It provides empirical evidence across diverse domains that escalation thresholds are model-specific and not predicted by architecture or scale, while demonstrating that SFT targeting uncertainty reasoning produces generalizable policies. The multi-domain evaluation and held-out domain tests are strengths, as is the focus on characterizing decision processes before deployment. These findings could inform pre-deployment auditing practices if the mapping from self-estimates to costs is validated.
major comments (2)
- [Decision framework and experimental evaluation] The expected-cost framework (described in the abstract and modeling sections) uses raw self-reported P(correct) directly in cost comparisons to derive implicit thresholds, yet provides no validation that these probabilities correlate with realized accuracy on the five datasets or reproduce observed human escalation rates. This is load-bearing for claims of model-specific thresholds and intervention benefits, especially given the noted miscalibration.
- [Experimental setup and results] No details are given on measurement of thresholds, statistical methods, sample sizes, controls, or how self-estimates were compared to actual outcomes. This leaves the reported differences across models and the benefits of SFT without verifiable support, undermining the soundness of the central empirical claims.
minor comments (2)
- [Abstract and results] Clarify the exact number of models tested per family and the precise definition of 'held-out domains' in the generalization experiments.
- [Results] Add a table summarizing per-domain accuracy of self-estimates versus realized performance to support the miscalibration discussion.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help clarify the need for stronger empirical grounding of our framework. We address each major point below and will revise the manuscript to add the requested validations and details.
read point-by-point responses
-
Referee: [Decision framework and experimental evaluation] The expected-cost framework (described in the abstract and modeling sections) uses raw self-reported P(correct) directly in cost comparisons to derive implicit thresholds, yet provides no validation that these probabilities correlate with realized accuracy on the five datasets or reproduce observed human escalation rates. This is load-bearing for claims of model-specific thresholds and intervention benefits, especially given the noted miscalibration.
Authors: We agree that explicit validation of self-reported P(correct) against realized accuracy is necessary to support the framework, particularly given the reported miscalibration. The current manuscript notes model-specific miscalibration but does not include direct correlation analyses or comparisons to human escalation rates. We will add these in the revision: calibration plots, Pearson/Spearman correlations between self-estimates and accuracy per model-domain pair, and (where human data permits) comparisons of model-derived thresholds to observed human escalation rates. This will be placed in a new subsection of the results. revision: yes
-
Referee: [Experimental setup and results] No details are given on measurement of thresholds, statistical methods, sample sizes, controls, or how self-estimates were compared to actual outcomes. This leaves the reported differences across models and the benefits of SFT without verifiable support, undermining the soundness of the central empirical claims.
Authors: We acknowledge the omission of these methodological details, which are essential for reproducibility. Thresholds are computed by finding the P(correct) value at which expected cost of acting equals the cost of escalation for a given cost ratio. We will expand the Methods and Experimental Setup sections to specify: the exact algebraic derivation of thresholds, statistical procedures (bootstrapped confidence intervals over 1000 resamples), per-domain sample sizes (500–2000 instances), prompt controls (fixed templates with randomized order), and direct outcome comparisons (self-estimate vs. binary correctness label). These additions will support the reported model differences and SFT benefits. revision: yes
Circularity Check
No circularity: empirical measurements of model-specific escalation thresholds
full rationale
The paper applies a standard expected-cost decision framework to LLM self-reported probabilities and observed behaviors across five domains, then measures implicit thresholds and tests interventions (cost ratios, accuracy signals, SFT) on held-out data. No equations, fitted parameters, or self-citations reduce any central claim to its own inputs by construction; thresholds are reported as empirical observations rather than derived tautologies. The analysis is self-contained against external benchmarks and does not rely on load-bearing self-citations or ansatzes smuggled from prior work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM decisions can be modeled as comparing expected costs of acting versus escalating using the model's self-estimated probability of correctness.
Reference graph
Works this paper leans on
-
[1]
doi: 10.1016/j.dib.2018.11.126. Edmond Awad, Sohan Dsouza, Richard Kim, Jonathan Schulz, Joseph Henrich, Azim Shariff, Jean-Franc ¸ois Bonnefon, and Iyad Rahwan. The moral machine experiment.Nature, 563: 59–64,
-
[2]
Chatbot Arena: An Open Platform for Evaluating LLMs by Human Preference
doi: 10.1038/s41586-018-0637-6. Wei-Lin Chiang, Lianmin Zheng, Ying Sheng, Anastasios Nikolas Angelopoulos, Tianle Li, Dacheng Li, Hao Zhang, Banghua Zhu, Michael Jordan, Joseph E. Gonzalez, and Ion Stoica. Chatbot arena: An open platform for evaluating LLMs by human preference.arXiv preprint arXiv:2403.04132,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1038/s41586-018-0637-6
-
[3]
Improving Factuality and Reasoning in Language Models through Multiagent Debate
Yilun Du, Shuang Li, Antonio Torralba, Joshua B Tenenbaum, and Igor Mordatch. Improving factuality and reasoning in language models through multiagent debate.arXiv preprint arXiv:2305.14325,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
doi: 10.1145/ 2827872. Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. SWE-bench: Can language models resolve real-world GitHub issues?arXiv preprint arXiv:2310.06770,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Language Models (Mostly) Know What They Know
Saurav Kadavath, Tom Conerly, Amanda Askell, Tom Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer, Zac Hatfield-Dodds, Nova DasSarma, Eli Tran-Johnson, et al. Language models (mostly) know what they know.arXiv preprint arXiv:2207.05221,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Measuring Faithfulness in Chain-of-Thought Reasoning
Tamera Lanham, Anna Chen, Ansh Radhakrishnan, Benoit Steiner, Carson Denison, Danny Hernandez, Dustin Li, Esin Durmus, Evan Hubinger, Jackson Kernion, et al. Measuring faithfulness in chain-of-thought reasoning.arXiv preprint arXiv:2307.13702,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Encouraging Divergent Thinking in Large Language Models through Multi-Agent Debate
Tian Liang, Zhiwei He, Wenxiang Jiao, Xing Wang, Yan Wang, Rui Wang, Yujiu Yang, Zhaopeng Tu, and Shuming Shi. Encouraging divergent thinking in large language models through multi-agent debate.arXiv preprint arXiv:2305.19118,
work page internal anchor Pith review arXiv
-
[8]
10 Preprint. Under review. Katherine Tian, Eric Mitchell, Huaxiu Yao, Christopher D. Manning, and Chelsea Finn. Just ask for calibration: Strategies for eliciting calibrated confidence scores from language models fine-tuned with human feedback.arXiv preprint arXiv:2305.14975,
-
[9]
Appworld: A controllable world of apps and people for benchmarking interactive coding agents,
Harsh Trivedi, Tushar Khot, Mareike Hartmann, Ruskin Manber, Vinber Dong, Edward Li, Shashank Gupta, Ashish Sabharwal, and Niranjan Balasubramanian. AppWorld: A controllable world of apps and people for benchmarking interactive coding agents.arXiv preprint arXiv:2407.18901,
-
[10]
Miao Xiong, Zhiyuan Hu, Xinyang Lu, Yifei Li, Jie Fu, Junxian He, and Bryan Hooi
doi: 10.1145/3038912.3052591. Miao Xiong, Zhiyuan Hu, Xinyang Lu, Yifei Li, Jie Fu, Junxian He, and Bryan Hooi. Can LLMs express their uncertainty? an empirical evaluation of confidence elicitation in LLMs. arXiv preprint arXiv:2306.13063,
-
[11]
12 Preprint. Under review. Figure 5: Implicit escalation threshold p∗ (left) and self-estimated accuracy ˆa (right) for each model. The threshold p∗ varies widely (53% to over 100%), while self-estimated accuracy ranges from 76% to 97%. The dotted lines show the optimal threshold τ∗ = 75% at cost ratio R=4 (left) and average actual accuracy (right). F Exa...
work page 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.