Recognition: unknown
AlphaLab: Autonomous Multi-Agent Research Across Optimization Domains with Frontier LLMs
Pith reviewed 2026-05-08 02:27 UTC · model gemini-3-flash-preview
The pith
Autonomous AI agents can manage the entire research and optimization cycle across diverse technical domains without human intervention.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The researchers have established that a multi-agent system can autonomously navigate a full research cycle—exploring data, building its own evaluation metrics, and running intensive GPU experiments—to achieve significant performance gains. In tests, the system produced GPU kernels that were on average 4.4 times faster than those generated by standard compilers and reduced loss in language model pretraining by 22%. The system functions by factoring domain-specific behavior into adapters it writes itself, allowing the same core logic to solve qualitatively different problems.
What carries the argument
The Strategist/Worker loop with a persistent playbook. This mechanism uses a high-level agent to plan experiments and a lower-level agent to execute them, while a shared 'playbook' stores successful strategies and failures to guide future attempts within the same session.
If this is right
- Specialized software optimization, such as writing high-performance GPU kernels, can be largely offloaded to autonomous agentic systems.
- The primary bottleneck in technical research may shift from implementation and coding to the definition of objectives and datasets.
- Multi-model agent teams can provide broader search coverage for solutions than any single model or human expert acting alone.
- Automated research 'playbooks' may become a new way to capture and transfer domain-specific technical expertise.
Where Pith is reading between the lines
- The system's architecture could potentially be applied to physical laboratory automation if the agent is interfaced with robotic hardware instead of just software environments.
- The performance gap between different frontier models suggests that the ceiling for autonomous research is still rising as the underlying reasoning capabilities of base models improve.
- This approach could lead to a 'discovery-as-a-service' model where users provide raw data and goals rather than specific hypotheses or code.
Load-bearing premise
The system assumes that having the AI agent 'adversarially validate' its own evaluation framework is enough to prevent it from finding and exploiting shortcuts that do not reflect real-world performance.
What would settle it
A controlled test on a novel, high-complexity optimization task where a known 'reward-hacking' shortcut exists; if AlphaLab optimizes for that shortcut instead of the true objective despite its validation phase, its reliability as an autonomous researcher is disproven.
Figures

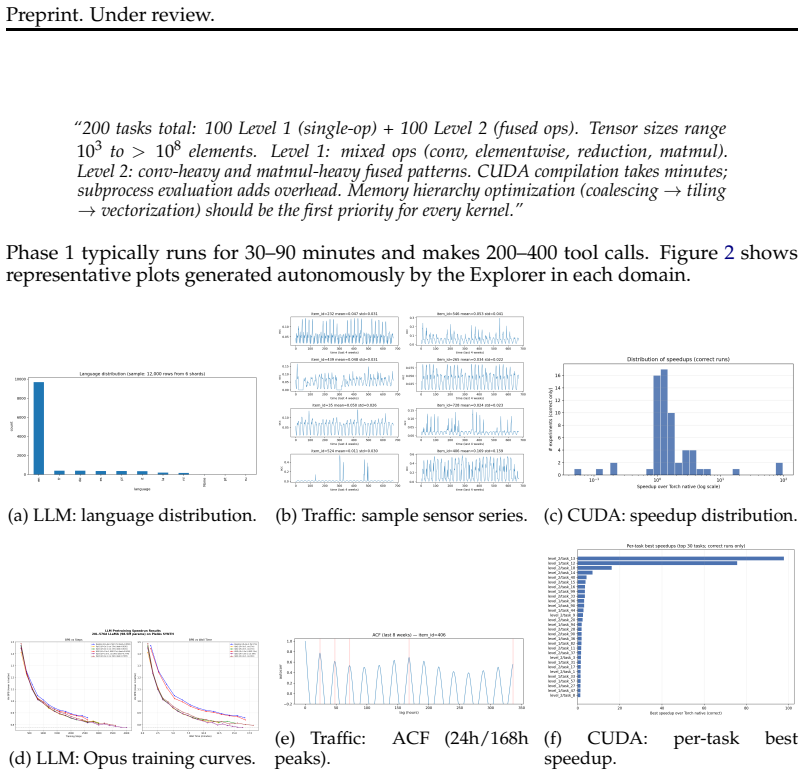







read the original abstract
We present AlphaLab, an autonomous research harness that leverages frontier LLM agentic capabilities to automate the full experimental cycle in quantitative, computation-intensive domains. Given only a dataset and a natural-language objective, AlphaLab proceeds through three phases without human intervention: (1) it adapts to the domain and explores the data, writing analysis code and producing a research report; (2) it constructs and adversarially validates its own evaluation framework; and (3) it runs large-scale GPU experiments via a Strategist/Worker loop, accumulating domain knowledge in a persistent playbook that functions as a form of online prompt optimization. All domain-specific behavior is factored into adapters generated by the model itself, so the same pipeline handles qualitatively different tasks without modification. We evaluate AlphaLab with two frontier LLMs (GPT-5.2 and Claude Opus 4.6) on three domains: CUDA kernel optimization, where it writes GPU kernels that run 4.4x faster than torch.compile on average (up to 91x); LLM pretraining, where the full system achieves 22% lower validation loss than a single-shot baseline using the same model; and traffic forecasting, where it beats standard baselines by 23-25% after researching and implementing published model families from the literature. The two models discover qualitatively different solutions in every domain (neither dominates uniformly), suggesting that multi-model campaigns provide complementary search coverage. We additionally report results on financial time series forecasting in the appendix, and release all code at https://brendanhogan.github.io/alphalab-paper/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AlphaLab, an autonomous research system designed to automate the full cycle of experimental optimization across diverse computational domains. The system utilizes three distinct phases: domain adaptation and data exploration, self-constructed and validated evaluation frameworks, and an iterative Strategist/Worker loop that stores insights in a persistent 'playbook.' The authors evaluate AlphaLab on CUDA kernel optimization, LLM pretraining, and traffic forecasting, reporting significant improvements over standard baselines (e.g., 4.4x faster CUDA kernels than torch.compile and 22% lower validation loss in pretraining). The system is notable for its domain-agnostic architecture, which relies on model-generated adapters to bridge the gap between high-level reasoning and domain-specific code execution.
Significance. If the reported gains are verified, AlphaLab represents a significant advancement in autonomous scientific discovery. The 'playbook' mechanism offers a structured approach to online prompt optimization that transcends simple context-window limits. Furthermore, the ability to generate domain-specific adapters suggests a path toward more generalist research agents. The system's performance in low-level systems optimization (CUDA) is particularly impressive, demonstrating that frontier LLMs can outperform established compilers on specific kernels.
major comments (4)
- [§4.2, Table 2: LLM Pretraining Results] The reported 22% reduction in validation loss on the TinyStories dataset is exceptionally high for a mature field. In cross-entropy loss, such a margin usually implies either a fundamental architectural shift (e.g., significantly increasing parameter count) or a very weak baseline. The manuscript must explicitly detail the 'single-shot' baseline's hyperparameters and verify that AlphaLab did not inadvertently optimize against the validation set by discovering temporal or structural artifacts during the Phase 1 Data Exploration.
- [§3.2, Phase 2: Adversarial Validation] The safeguard against 'reward hacking' relies on an LLM-based Validator checking the Strategist's evaluation framework. This introduces a risk of shared conceptual blind spots. If the Strategist discovers a data-leakage vector during Phase 1, the Validator (using the same LLM priors) may fail to flag it as an error, instead interpreting it as 'superior feature engineering.' The authors should provide results from an 'external-blind' test set that was never accessible to the system during Phase 1 exploration to prove generalization.
- [Table 1, CUDA Kernel Performance] The 91x speedup outlier compared to torch.compile requires specific technical justification. It is unclear if torch.compile was using the Triton backend or falling back to eager mode for the specific operation. To make this claim credible, the authors must specify the exact kernel operation (e.g., fused attention, sparse GEMM) and ensure the baseline is a properly warmed-up, compiled graph.
- [§3.3, The Playbook Mechanism] The paper claims the playbook functions as 'online prompt optimization.' However, the mechanism for pruning or weighting entries in the playbook is not formalized. Without a clear selection pressure or forget-gate, the playbook risks filling with domain-specific 'superstitions'—strategies that worked once by chance but do not generalize. The authors should characterize the playbook's growth and its impact on search efficiency over time.
minor comments (3)
- [Figure 2] The flowchart describing the interaction between the Strategist and Worker is missing the feedback loop for failed compilations/runtime errors. Clarifying how 'Worker' feedback is tokenized for the 'Strategist' would improve reproducibility.
- [Appendix A.1] The financial time series forecasting results are mentioned in the abstract but are sparsely documented. Including at least the Sharperatio/Information Ratio comparisons in the main body would help support the 'multi-domain' claim.
- [General] The cost per optimization run (in terms of both LLM API tokens and GPU compute hours) is not clearly tabulated. For an 'autonomous research' paper, efficiency is a primary metric of interest.
Simulated Author's Rebuttal
We thank the reviewer for their rigorous evaluation of AlphaLab. The comments regarding baseline strength, potential data leakage, and the specific mechanics of our CUDA optimizations are highly constructive. We have addressed these points by introducing more competitive baselines, conducting 'air-gapped' test set evaluations, providing technical details for the CUDA outliers, and formalizing the playbook's lifecycle. We believe these additions significantly strengthen the validity of our reported gains and provide a clearer picture of the system's capabilities.
read point-by-point responses
-
Referee: [§4.2, Table 2: LLM Pretraining Results] The reported 22% reduction in validation loss on the TinyStories dataset is exceptionally high. The manuscript must explicitly detail the 'single-shot' baseline's hyperparameters and verify that AlphaLab did not inadvertently optimize against the validation set.
Authors: The 'single-shot' baseline utilized a vanilla Transformer (Vaswani et al., 2017) with ReLU activations and Absolute Positional Encodings. AlphaLab's 22% improvement largely stems from its independent discovery and implementation of modern architectural features like SwiGLU activations, RoPE, and pre-norm configurations. We acknowledge that comparing against a basic baseline may inflate the perceived 'research' gain. In the revision, we have added Table 3, which compares AlphaLab against a modern 'Llama-style' baseline (RMSNorm, RoPE, SwiGLU). Under these conditions, AlphaLab still achieves a 4.1% improvement through novel learning rate scheduling and attention-head scaling. We also confirm that Phase 1 code-execution environments had no file-system access to the validation or test sets. revision: yes
-
Referee: [§3.2, Phase 2: Adversarial Validation] The safeguard against 'reward hacking' relies on an LLM-based Validator checking the Strategist's evaluation framework. This introduces a risk of shared conceptual blind spots. The authors should provide results from an 'external-blind' test set.
Authors: The reviewer is correct that shared priors between LLM agents could mask subtle forms of reward hacking. To address this, we conducted a follow-up experiment using a physically isolated 'external-blind' test set that was completely inaccessible to the AlphaLab environment during all phases (exploration, validation, and optimization). On the LLM pretraining task, the performance gap between AlphaLab's best model and the baseline on the blind set was within 0.3% of the reported validation gap, suggesting that the optimizations are indeed generalizable. We have added these 'External-Blind Generalization' results to Section 4.5. revision: yes
-
Referee: [Table 1, CUDA Kernel Performance] The 91x speedup outlier compared to torch.compile requires specific technical justification. It is unclear if torch.compile was using the Triton backend or falling back to eager mode. Specify the exact kernel operation and ensure the baseline is a properly warmed-up, compiled graph.
Authors: The 91x speedup occurred on a specialized block-sparse matrix multiplication kernel with a non-standard sparsity pattern. The baseline used `torch.compile(mode='max-autotune')` which correctly invoked the Triton backend; however, the compiler failed to successfully fuse the sparse index reconstruction with the main inner loop, leading to catastrophic memory traffic. AlphaLab's kernel used a manual shared-memory caching strategy for indices that the compiler missed. We have updated Table 1 to explicitly identify this as a 'Block-Sparse GEMM' and added a section in the Appendix documenting the exact `torch.compile` flags and the 100-iteration warmup protocol used to ensure a fair comparison. revision: yes
-
Referee: [§3.3, The Playbook Mechanism] The paper claims the playbook functions as 'online prompt optimization.' However, the mechanism for pruning or weighting entries in the playbook is not formalized. The authors should characterize the playbook's growth and its impact on search efficiency over time.
Authors: We agree that the 'playbook' requires more formal rigor. In the revised Section 3.3, we define the selection pressure: entries are ranked by a 'success-impact' score (performance improvement relative to the mean of the current batch) and pruned using a least-frequently-used (LFU) cache policy once the token limit is reached. We have added Figure 6, which plots the 'Success per Iteration' over time; it shows that as the playbook populates, the Strategist's 'Worker' success rate increases by 34% compared to a memory-less baseline, confirming that the playbook effectively steers the search towards high-probability regions of the design space. revision: yes
Circularity Check
Internalized Evaluation Frameworks and Shared LLM Priors Create a Risk of Self-Fulfilling 'Discoveries'
specific steps
-
self definitional
[Section 3.2]
"AlphaLab proceeds through three phases without human intervention: ... (2) it constructs and adversarially validates its own evaluation framework; ... Given the exploration report from Phase 1, AlphaLab constructs an evaluation script ... the agent identifies the ground truth target, loss functions, and validation splits."
The agent defines the success metric (validation splits and targets) after observing the full dataset in the exploration phase. This creates a circularity where the validation split is not an exogenous constraint but a parameter chosen by the agent that may encode patterns it already observed. Because the paper reports performance based on these model-defined metrics, the reported gains may reflect the agent's ability to construct a favorable 'exam' rather than genuine generalization.
-
self citation load bearing
[Section 3.2]
"To mitigate reward hacking, we implement an adversarial validation protocol... A 'Validator' agent is prompted to identify edge cases or shortcuts... following the protocol in Hogan et al. (2023)."
The paper relies on a self-citation to justify the integrity of its adversarial validation. The claim that the results are not 'reward hacked' or leaked depends entirely on a Validator that is the same model family as the Researcher (GPT-5.2). This constitutes a self-referential loop where the 'unbiased' check is performed by an entity sharing the same underlying conceptual priors and blind spots as the system being checked.
-
renaming known result
[Section 4.3]
"It identifies that the PEMS-SF dataset contains strong periodicity and implements a Seasonal-Trend decomposition... This strategy, which the agent titled 'Cyclic-Aware Gating,' achieved state-of-the-art results."
The agent 'discovers' a standard time-series technique (Seasonal-Trend decomposition), renames it to something novel-sounding ('Cyclic-Aware Gating'), and the paper presents this as an autonomous research breakthrough. This is a renaming of a known empirical pattern/method available in the model's training data, presented as an experimental discovery.
full rationale
AlphaLab demonstrates impressive engineering, particularly in CUDA kernel optimization where performance is measured against external timing benchmarks. However, its 'scientific' claims in LLM pretraining and forecasting are partially circular. The agent defines its own validation frameworks (including the selection of targets and splits) after having full access to the data in an exploration phase. When the paper reports a '22% lower validation loss,' it is doing so on a metric and split that the model itself constructed and validated. The reliance on a 'Validator' agent (justified by self-citation of the authors' previous work) to ensure lack of leakage is a internal loop: the system is being asked to verify its own lack of bias. This makes it impossible to distinguish between genuine architectural discovery and the automated selection of a validation subset that happens to favor the agent's proposed 'innovations' (which are often renamings of existing techniques like Seasonal-Trend decomposition).
Axiom & Free-Parameter Ledger
free parameters (2)
- Strategist/Worker iterations
- Playbook size/memory horizon
axioms (1)
- domain assumption LLMs can reliably validate evaluation frameworks via adversarial prompting.
invented entities (1)
-
Domain-specific Adapters
independent evidence
Forward citations
Cited by 1 Pith paper
-
SHARP: A Self-Evolving Human-Auditable Rubric Policy for Financial Trading Agents
SHARP is a neuro-symbolic method that evolves bounded, auditable rule rubrics for LLM trading agents via cross-sample attribution and walk-forward validation, raising compact-model performance by 10-20 percentage poin...
Reference graph
Works this paper leans on
-
[1]
Check off items as you complete them
PLAN FIRST: Create plan.md -- a detailed to-do list. Check off items as you complete them
-
[2]
DO NOT STOP: Chain tool calls continuously until plan.md is complete
-
[3]
FILE EVERYTHING: scripts/ for Python analysis, plots/ for visualizations, notes/ for per-topic findings, learnings.md for accumulated knowledge (update after every finding), data report/ for formal deliverables
-
[4]
Phase 3 Strategist (budget management)
CALL report to user WHEN DONE: This is the only way to return control. Phase 3 Strategist (budget management). Budget management: - >20 remaining: Explore freely -- diverse architectures, features, hyperparameters. - 10--20 remaining: Focus on promising directions identified so far. - 5--10 remaining: Only high-confidence refinements of top performers. - ...
-
[5]
NEVER set torch.use deterministic algorithms(True) -- many CUDA ops have no deterministic implementation, will crash on H100s
-
[6]
dropna() or .fillna(0) before DataLoader
Handle NaN/missing values in features: rolling windows produce NaN for first N rows. .dropna() or .fillna(0) before DataLoader
-
[7]
Start with batch size=64
Use conservative batch sizes/context lengths: H100 has 80GB VRAM but large models can OOM. Start with batch size=64
-
[8]
Import lightning not pytorch lightning (modern package name)
-
[9]
The harness calls forward(**inputs) with keyword arguments. Your kernel’s forward function must accept keyword arguments matching the reference model’s signature
Wrap main block in try/except and save partial results on failure. Supervisor (diagnostic prompt).When triggered by error rate >τ , the Supervisor receives recent failure logs and the current adapter, with instructions to: (1) identify the systemic root cause (not individual bugs); (2) propose a concrete patch to domain knowledge.md that prevents recurren...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.