Recognition: unknown
Skip-Connected Policy Optimization for Implicit Advantage
Pith reviewed 2026-05-10 17:24 UTC · model grok-4.3
The pith
Skip-connected policy optimization lets models apply dense rewards to early reasoning steps without the variance that normally makes them worse than outcome-only rewards.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
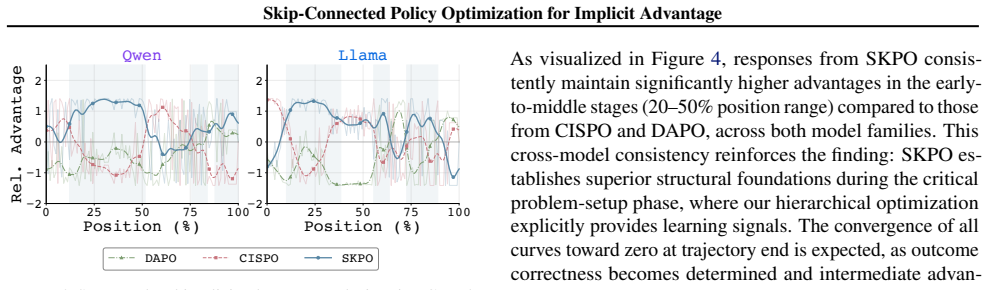
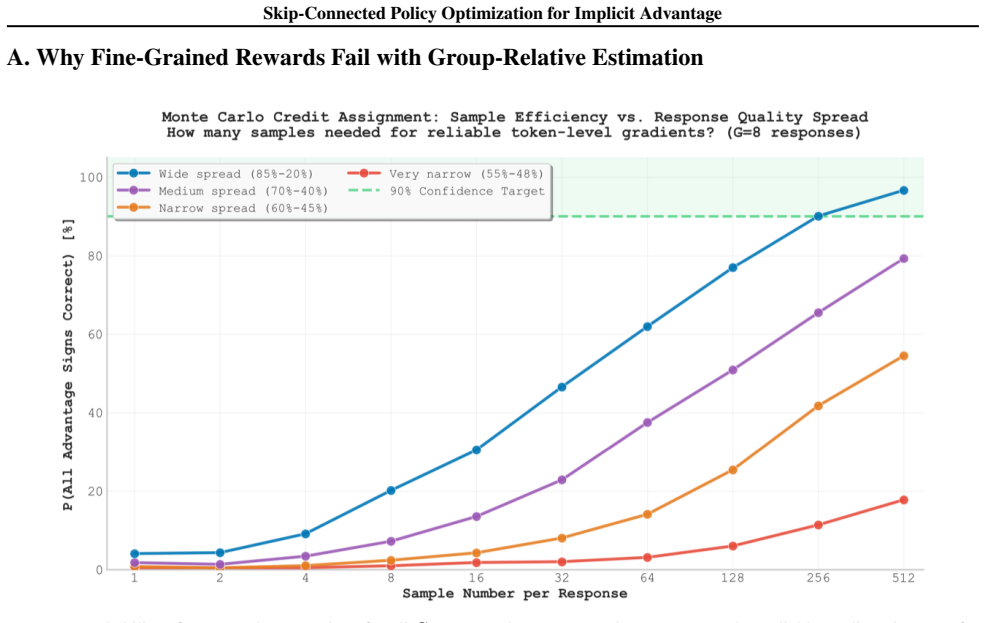
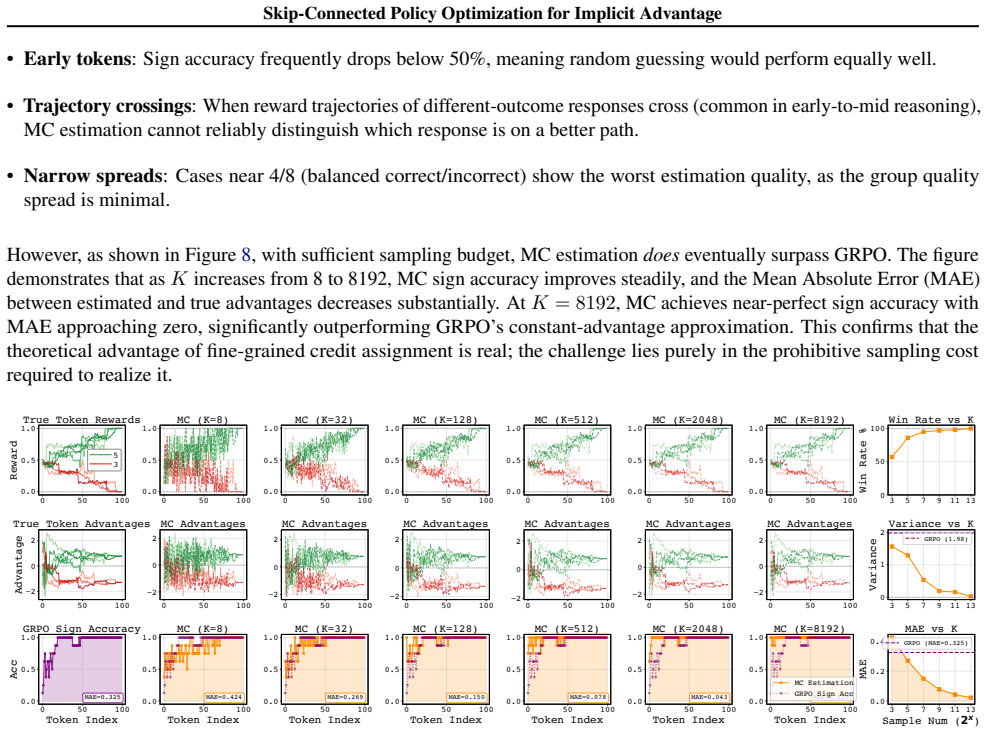
The paper establishes that Monte Carlo estimation of dense rewards leads to high-variance and sign-inconsistent advantages for early tokens, causing underperformance relative to outcome-only optimization. SKPO addresses this by decomposing the process into upstream and downstream phases, with upstream receiving dense rewards through single-stream optimization based on downstream Monte Carlo sampling, while downstream uses group-relative optimization. The key innovation is a skip connection that concatenates the upstream segment with the original problem, enabling the model to leverage useful upstream reasoning or bypass it entirely. This yields relative improvements of 3.91 percent and 6.17%
What carries the argument
The skip connection that concatenates the upstream reasoning segment with the original problem, allowing downstream optimization to use or ignore the upstream output.
If this is right
- Trajectories exhibit higher intermediate-step quality even when final answers match the correctness of baseline trajectories.
- Relative performance gains appear on both in-domain mathematical tasks and out-of-domain general reasoning and code-generation tasks.
- Single-stream optimization for the upstream phase combined with group-relative optimization for the downstream phase avoids the variance problems observed in pure dense-reward settings.
- The model retains the ability to solve the original problem directly when upstream reasoning is flawed.
Where Pith is reading between the lines
- The upstream-downstream split with skip access may extend to longer multi-hop reasoning chains by inserting additional skip points.
- The observed improvement in step quality even on correct final answers suggests the method could aid human inspection or automated verification of reasoning paths.
- The approach might reduce the sampling budget required to obtain reliable dense signals in other chain-of-thought domains.
Load-bearing premise
Monte Carlo estimation of dense rewards for early tokens remains beneficial once the skip connection is added and does not introduce new optimization inconsistencies under practical sampling budgets.
What would settle it
Training identical models with dense Monte Carlo rewards but without the skip connection and observing equal or better performance on the same mathematical benchmarks would falsify the necessity of the skip mechanism.
Figures








read the original abstract
Group Relative Policy Optimization (GRPO) has proven effective in RLVR by using outcome-based rewards. While fine-grained dense rewards can theoretically improve performance, we reveal that under practical sampling budgets, Monte Carlo estimation yields high-variance and sign-inconsistent advantages for early reasoning tokens, paradoxically underperforming outcome-only GRPO. We propose Skip-Connected Optimization (SKPO), which decomposes reasoning into upstream and downstream phases: upstream receives dense rewards from downstream Monte Carlo sampling with single-stream optimization; downstream maintains group-relative optimization, where a skip connection concatenates the upstream segment with the original problem, enabling the model to leverage helpful upstream reasoning while preserving the freedom to bypass flawed reasoning through direct problem access. Experiments demonstrate improvements of 3.91% and 6.17% relative gains over the strongest baselines on Qwen2.5-Math-7B and Llama-3.2-3B respectively across mathematical benchmarks and out-of-domain tasks including general reasoning and code generation. Further analysis reveals an implicit advantage: SKPO generates trajectories with higher intermediate-step quality even when matched for final correctness.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Skip-Connected Policy Optimization (SKPO) to improve upon Group Relative Policy Optimization (GRPO) in RLVR settings. It decomposes reasoning trajectories into upstream and downstream phases, applies Monte Carlo dense rewards to upstream tokens under single-stream optimization, and uses a skip connection in the downstream phase that concatenates the upstream segment with the original problem. This is claimed to yield an implicit advantage by preserving helpful upstream reasoning while allowing bypass of flawed segments. Experiments report relative gains of 3.91% on Qwen2.5-Math-7B and 6.17% on Llama-3.2-3B across math benchmarks plus out-of-domain reasoning and code tasks, with additional analysis showing higher intermediate-step quality even on trajectories matched for final correctness.
Significance. If the reported mechanism holds, SKPO offers a lightweight architectural modification that stabilizes advantage estimation for early tokens without requiring changes to the reward model or sampling budget. The multi-model, multi-task empirical results and the intermediate-quality observation provide concrete evidence of practical utility in LLM reasoning optimization.
major comments (3)
- [§4] §4 (Mechanism and Analysis): The central claim that SKPO produces an implicit advantage via dense upstream rewards depends on upstream tokens receiving informative signals rather than being bypassed. The skip connection explicitly conditions downstream generation on both the problem and the upstream segment, yet no ablation measures the frequency or impact of bypass (e.g., by comparing performance with and without the skip or by correlating upstream token quality with final reward under fixed sampling budgets). Without this, the observed gains and intermediate-step improvements could arise from altered conditioning or optimization dynamics instead of the intended dense-reward mechanism.
- [§5] §5 (Experiments): The abstract and experimental tables report relative gains of 3.91% and 6.17% without error bars, standard deviations, or details on the number of random seeds and sampling budgets used for Monte Carlo estimation. Given the paper's own observation that plain GRPO yields sign-inconsistent advantages under practical budgets, the absence of statistical characterization makes it impossible to determine whether the SKPO improvements are robust or could be explained by variance in the evaluation protocol.
- [§3.2] §3.2 (Optimization): The upstream phase uses single-stream optimization with Monte Carlo dense rewards while the downstream phase retains group-relative optimization. The manuscript does not analyze whether this split introduces gradient inconsistencies or reward-scale mismatches at the boundary between phases, which could affect convergence under the same practical sampling budgets that already produce noisy advantages in GRPO.
minor comments (2)
- The notation for the skip connection (e.g., how the concatenated input is formatted for the policy) is described only at a high level; a concrete example or pseudocode would improve reproducibility.
- Figure captions and table footnotes should explicitly state the number of evaluation runs and whether the reported metrics are means or best-of-N.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point-by-point below, clarifying the intended mechanism, committing to added statistical reporting and analyses, and outlining the revisions that will be incorporated in the next version of the manuscript.
read point-by-point responses
-
Referee: [§4] The central claim that SKPO produces an implicit advantage via dense upstream rewards depends on upstream tokens receiving informative signals rather than being bypassed. The skip connection explicitly conditions downstream generation on both the problem and the upstream segment, yet no ablation measures the frequency or impact of bypass (e.g., by comparing performance with and without the skip or by correlating upstream token quality with final reward under fixed sampling budgets). Without this, the observed gains and intermediate-step improvements could arise from altered conditioning or optimization dynamics instead of the intended dense-reward mechanism.
Authors: We agree that quantifying bypass behavior would provide stronger direct support for the implicit-advantage interpretation. The skip connection is explicitly introduced so that the downstream policy can ignore unhelpful upstream segments by attending directly to the original problem statement; our existing analysis already shows that SKPO produces higher-quality intermediate steps even on trajectories whose final answer matches the baseline, which is difficult to explain by conditioning changes alone. Nevertheless, the absence of an explicit ablation on bypass frequency or a with/without-skip comparison is a limitation. In the revised manuscript we will add (i) an ablation that removes the skip connection while retaining the upstream dense-reward signal and (ii) a correlation analysis between upstream token quality (measured by step-wise correctness) and final reward under fixed sampling budgets. revision: yes
-
Referee: [§5] The abstract and experimental tables report relative gains of 3.91% and 6.17% without error bars, standard deviations, or details on the number of random seeds and sampling budgets used for Monte Carlo estimation. Given the paper's own observation that plain GRPO yields sign-inconsistent advantages under practical budgets, the absence of statistical characterization makes it impossible to determine whether the SKPO improvements are robust or could be explained by variance in the evaluation protocol.
Authors: We acknowledge that the lack of error bars and seed information weakens the statistical presentation, especially given the variance issues we ourselves highlight for GRPO. In the revised manuscript we will report all main results with standard deviations computed over at least three independent random seeds, explicitly state the Monte Carlo sampling budgets used for both training and evaluation, and include these details in the experimental tables and abstract where appropriate. revision: yes
-
Referee: [§3.2] The upstream phase uses single-stream optimization with Monte Carlo dense rewards while the downstream phase retains group-relative optimization. The manuscript does not analyze whether this split introduces gradient inconsistencies or reward-scale mismatches at the boundary between phases, which could affect convergence under the same practical sampling budgets that already produce noisy advantages in GRPO.
Authors: The hybrid optimization is intentional: single-stream dense rewards are applied only to upstream tokens to obtain low-variance signals, while group-relative optimization is retained for the downstream phase to preserve the stable advantage estimation that GRPO already provides. The skip connection ensures that the downstream input always includes the original problem, so the policy gradient at the boundary remains well-defined. We did not observe training divergence or anomalous gradient magnitudes in any of our runs. Still, we agree that an explicit check is warranted. In the revision we will add a short analysis (including gradient-norm and reward-scale statistics at the phase boundary) to confirm the absence of systematic mismatches. revision: yes
Circularity Check
Architectural change with empirical validation; no derivation reduces to self-referential inputs
full rationale
The paper defines SKPO via an explicit decomposition into upstream/downstream phases plus a skip connection, then reports experimental gains and intermediate-quality analysis. No equations are shown where a 'prediction' or 'implicit advantage' is mathematically identical to a fitted parameter or input quantity by construction. No load-bearing self-citations or uniqueness theorems are invoked to force the result. The central claims rest on the proposed mechanism being tested against baselines rather than on tautological renaming or fitted-input predictions.
Axiom & Free-Parameter Ledger
free parameters (1)
- RL training hyperparameters
axioms (1)
- domain assumption Outcome-based rewards can be extended to dense estimates via Monte Carlo sampling under practical budgets
Forward citations
Cited by 1 Pith paper
-
Entropy Polarity in Reinforcement Fine-Tuning: Direction, Asymmetry, and Control
Entropy polarity from a first-order entropy change approximation enables Polarity-Aware Policy Optimization (PAPO) that preserves complementary polarity branches and outperforms baselines on math and agentic RL fine-t...
Reference graph
Works this paper leans on
-
[1]
URL https://openreview.net/forum? id=QGJ9ttXLTy. Gao, C., Zheng, C., Chen, X.-H., Dang, K., Liu, S., Yu, B., Yang, A., Bai, S., Zhou, J., and Lin, J. Soft adaptive policy optimization.arXiv preprint arXiv:2511.20347, 2025. Guo, D., Yang, D., Zhang, H., Song, J., Wang, P., Zhu, Q., Xu, R., Zhang, R., Ma, S., et al. Deepseek-r1 in- centivizes reasoning in l...
-
[2]
how easy is it to reach a correct answer from this intermediate state
URL https://aclanthology.org/2025. emnlp-main.252/. Li, L., Lu, D., Shao, J., Zhang, C., and Li, X. Scrpo: From errors to insights.arXiv preprint arXiv:2511.06065, 2025c. Li, Z., Xu, T., Zhang, Y ., Lin, Z., Yu, Y ., Sun, R., and Luo, Z.-Q. Remax: A simple, effective, and efficient rein- forcement learning method for aligning large language models. InFort...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.