Recognition: 2 theorem links
· Lean TheoremUnified Multimodal Uncertain Inference
Pith reviewed 2026-05-10 18:00 UTC · model grok-4.3
The pith
A 3B-parameter model produces calibrated probability estimates that match or exceed those of models up to 32B parameters across text, audio, and video.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Unified Multimodal Uncertain Inference requires models to produce calibrated probability estimates of hypotheses conditioned on a premise in any modality or combination. CLUE achieves this by combining self-consistent teacher calibration with distribution-based confidence probing, and a 3B-parameter model using CLUE achieves equivalent or stronger performance than baselines up to 32B parameters on the new evaluation set and existing benchmarks.
What carries the argument
CLUE (Calibrated Latent Uncertainty Estimation), which combines self-consistent teacher calibration and distribution-based confidence probing to produce calibrated predictions from a base model.
If this is right
- Fine-grained probabilistic reasoning becomes measurable in audio and video, beyond the binary entailment judgments that existed before.
- A 3B model can reach calibration levels previously associated only with much larger models.
- The same calibration approach applies equally to existing text and audio benchmarks and the new multimodal set.
- Models can be trained and tested on mixed-modality inputs rather than one modality at a time.
Where Pith is reading between the lines
- Systems that output explicit probabilities could reduce overconfident errors when multimodal models are used for high-stakes decisions such as interpreting video evidence.
- The calibration technique might transfer to additional modalities such as sensor streams or 3D scene data without requiring entirely new architectures.
- Releasing the human-annotated set publicly would let other groups test whether the reported calibration holds on data collected independently.
Load-bearing premise
The human-annotated evaluation set supplies reliable scalar probability judgments that accurately reflect true uncertainty.
What would settle it
Running the 3B model and the 32B baselines on a new collection of human scalar probability judgments in audio or audiovisual settings and finding that the smaller model falls clearly behind would falsify the performance claim.
Figures









read the original abstract
We introduce Unified Multimodal Uncertain Inference (UMUI), a multimodal inference task spanning text, audio, and video, where models must produce calibrated probability estimates of hypotheses conditioned on a premise in any modality or combination. While uncertain inference has been explored in text, extension to other modalities has been limited to single-modality binary entailment judgments, leaving no framework for fine-grained probabilistic reasoning in or across other modalities. To address this, we curate a human-annotated evaluation set with scalar probability judgments across audio, visual, and audiovisual settings, and additionally evaluate on existing text and audio benchmarks. We introduce CLUE (Calibrated Latent Uncertainty Estimation), which combines self-consistent teacher calibration and distribution-based confidence probing to produce calibrated predictions. We demonstrate that our 3B-parameter model achieves equivalent or stronger performance than baselines up to 32B parameters across all modalities.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Unified Multimodal Uncertain Inference (UMUI) task, requiring models to output calibrated scalar probability estimates for hypotheses given premises in text, audio, video, or audiovisual combinations. It curates a new human-annotated evaluation set with scalar probability judgments, proposes the CLUE method (self-consistent teacher calibration combined with distribution-based confidence probing), evaluates on the new set plus existing text/audio benchmarks, and claims that a 3B-parameter CLUE model achieves equivalent or stronger performance than baselines up to 32B parameters across all modalities.
Significance. If the results hold after validation of the benchmark, this would establish the first framework for fine-grained probabilistic reasoning across modalities beyond binary entailment, with the small-model performance result offering a notable counterpoint to scaling trends if the calibration advantage is intrinsic rather than benchmark-specific.
major comments (2)
- [Abstract and §5] Abstract and §5 (Experiments): The central claim that the 3B CLUE model matches or exceeds up to 32B baselines rests entirely on the newly curated human-annotated evaluation set supplying reliable scalar probability targets. However, the manuscript reports no inter-annotator agreement statistics, modality-balanced sampling details, or external calibration checks against known references, leaving open the possibility that reported advantages arise from annotation artifacts or easier items rather than model capability.
- [§5] §5: The performance tables and comparisons lack any description of baseline implementations (e.g., prompting strategies or fine-tuning details for the 32B models), the exact calibration metrics used (ECE, Brier score, or others), or statistical significance tests for the 'equivalent or stronger' claims, preventing independent verification and assessment of whether the small-model superiority is robust.
minor comments (1)
- [Abstract] The abstract introduces terms such as 'self-consistent teacher calibration' and 'distribution-based confidence probing' without one-sentence definitions, which reduces accessibility for readers outside the immediate subfield.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our submission. The comments highlight important aspects of benchmark validation and experimental reproducibility that we will address to strengthen the manuscript. We respond point-by-point to the major comments below.
read point-by-point responses
-
Referee: [Abstract and §5] Abstract and §5 (Experiments): The central claim that the 3B CLUE model matches or exceeds up to 32B baselines rests entirely on the newly curated human-annotated evaluation set supplying reliable scalar probability targets. However, the manuscript reports no inter-annotator agreement statistics, modality-balanced sampling details, or external calibration checks against known references, leaving open the possibility that reported advantages arise from annotation artifacts or easier items rather than model capability.
Authors: We agree that explicit reporting of inter-annotator agreement, sampling procedures, and validation steps is essential to establish the reliability of the new human-annotated set. The current manuscript does not include these details. In the revised version we will add a dedicated subsection describing the annotation protocol, inter-annotator agreement statistics, modality-balanced sampling strategy, and any external calibration checks performed against existing text-only references. These additions will directly support the validity of the evaluation targets and the reported performance claims. revision: yes
-
Referee: [§5] §5: The performance tables and comparisons lack any description of baseline implementations (e.g., prompting strategies or fine-tuning details for the 32B models), the exact calibration metrics used (ECE, Brier score, or others), or statistical significance tests for the 'equivalent or stronger' claims, preventing independent verification and assessment of whether the small-model superiority is robust.
Authors: We concur that the experimental section requires additional implementation and statistical details to enable independent verification. The revised manuscript will expand §5 (and add an appendix if needed) with: (i) precise descriptions of baseline prompting strategies and whether any fine-tuning was applied, (ii) the exact calibration metrics employed (Expected Calibration Error and Brier score), and (iii) statistical significance tests supporting the equivalence or superiority claims. These clarifications will be incorporated to facilitate reproducibility and robust assessment of the results. revision: yes
Circularity Check
No circularity: derivation remains self-contained
full rationale
The paper defines UMUI as a new multimodal uncertain inference task and introduces CLUE as a combination of self-consistent teacher calibration plus distribution-based probing. Performance claims rest on evaluation against a separately curated human-annotated set plus existing benchmarks; no equations, fitted parameters, or self-citations are shown that reduce the reported calibration metrics or 3B-vs-32B comparisons to the inputs by construction. The evaluation set is presented as an external reference rather than a quantity defined from the model's own outputs, satisfying the requirement for independent content.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Human scalar probability annotations constitute reliable ground truth for calibration evaluation
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
CLUE combines self-consistent teacher calibration and distribution-based confidence probing... minimizing KL divergence between target Gaussian Q ~ N(y, σ²) and predicted P
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We demonstrate that our 3B-parameter model achieves equivalent or stronger performance than baselines up to 32B parameters
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Special issue: Probabilistic models of cognition
Probabilistic models of cognition: Concep- tual foundations.Trends in Cognitive Sciences, 10(7):287–291. Special issue: Probabilistic models of cognition. Tiejin Chen, Pingzhi Li, Kaixiong Zhou, Tianlong Chen, and Hua Wei. 2025. Unveiling privacy risks in multi- modal large language models: Task-specific vulner- abilities and mitigation challenges. InFind...
2025
-
[2]
Qwen2-audio technical report.Preprint, arXiv:2407.10759. Mehul Damani, Isha Puri, Stewart Slocum, Idan Shen- feld, Leshem Choshen, Yoon Kim, and Jacob An- dreas. 2025. Beyond binary rewards: Training lms to reason about their uncertainty.arXiv preprint arXiv:2507.16806. Tri Dao, Dan Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. 2022. Flashattention: ...
work page internal anchor Pith review arXiv 2025
-
[3]
William Jurayj, Jeffrey Cheng, and Benjamin Van Durme
Addressing the binning problem in calibra- tion assessment through scalar annotations.Transac- tions of the Association for Computational Linguis- tics, 12:120–136. William Jurayj, Jeffrey Cheng, and Benjamin Van Durme. 2025. Is that your final answer? test- time scaling improves selective question answering. InProceedings of the 63rd Annual Meeting of th...
2025
-
[4]
Language Models (Mostly) Know What They Know
Garden path traversal in gpt-2. InProceedings of the fifth blackboxnlp workshop on analyzing and interpreting neural networks for nlp, pages 305–313. Saurav Kadavath, Tom Conerly, Amanda Askell, Tom Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer, Zac Hatfield-Dodds, Nova DasSarma, Eli Tran-Johnson, and 1 others. 2022. Language mod- els (mostly) know...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[5]
These approaches differ in where and how uncertainty is measured
or to define early-stopping policies to min- imize inference costs (Wang et al., 2026). These approaches differ in where and how uncertainty is measured. At the token level, Skow et al. (2026) show that logit-based calibration can be used to rerank videos by relevance, while ensemble methods like self-consistency (Wang et al., 2023b) or LoRA ensembles (Wa...
2026
-
[6]
This setting extends conventional binary judgments toward metrics of credence that more closely align with human uncertainty (Pavlick and Kwiatkowski, 2019; Nie et al., 2020)
extends traditional natural language infer- ence (Bowman et al., 2015) to measure language models’ ability to evaluate the likelihood of a hy- pothesis given a premise on a continuous scale. This setting extends conventional binary judgments toward metrics of credence that more closely align with human uncertainty (Pavlick and Kwiatkowski, 2019; Nie et al...
2015
-
[7]
have been independently studied for multi- modal problems, this line of work has been con- ducted almost exclusively in the text and image domain. Our work extends the uncertain inference to video-language models, showing how models learn to integrate visual, auditory, and linguistic cues into well-calibrated probabilistic judgments. B Annotation Protocol...
-
[8]
Launch and commissioning of the James Webb Space Telescope
-
[9]
2018 lower Puna eruption
2018
-
[10]
2022 United States Senate election in Georgia
2022
-
[11]
2018 Anchorage earthquake
2018
-
[12]
2025 Canadian federal election
2025
-
[13]
2025 Myanmar earthquake
2025
-
[14]
Blue Ghost Mission 1
-
[15]
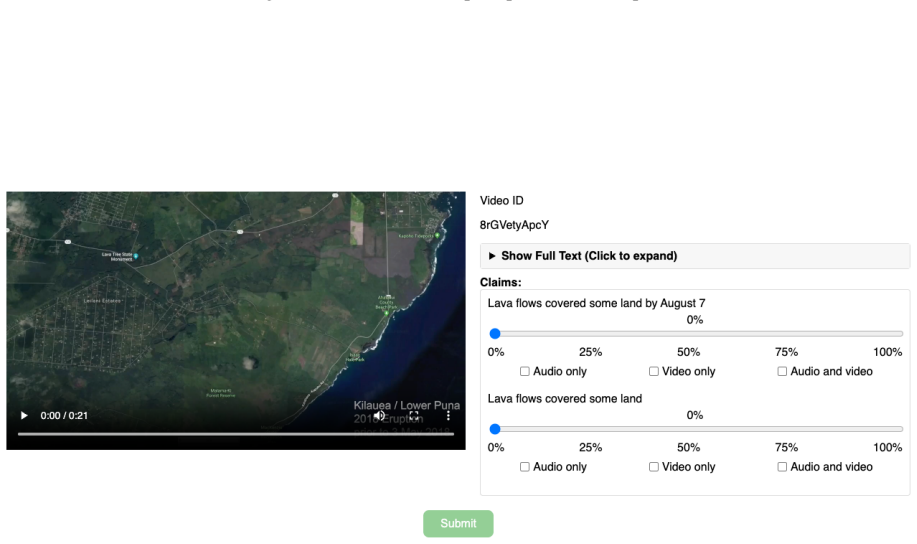
Annotators are given a video and a set of claims and asked to estimate the probability (0–100%) that each claim is true given the video
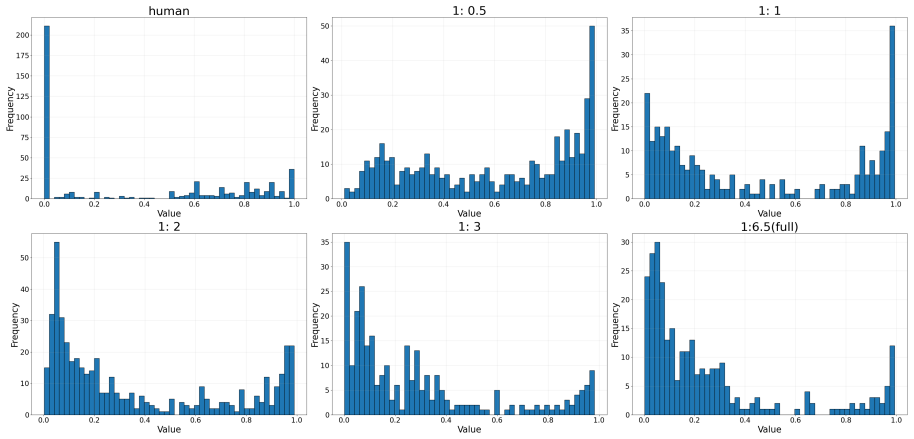
Liberation Day Tariffs B.2 Annotation Protocol In Figure 12, we provide the annotation instruc- tions given to the annotators. Annotators are given a video and a set of claims and asked to estimate the probability (0–100%) that each claim is true given the video. For each claim, annotators also indicate which modalities (audio, video, or both) informed th...
2011
-
[16]
Clotho: Development split for training; evalu- ation split for testing
-
[17]
WikiVideo: 10 events reserved for testing; the remainder for training
-
[18]
you can google information to make you more confident in claims, but not that would directly confirm or deny the claim itself
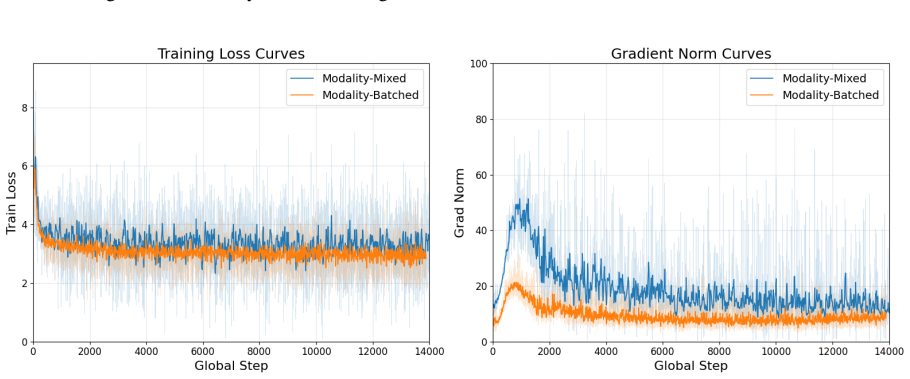
UNLI: Standard train/validation splits for training and testing. The model was trained on four NVIDIA A100 (80GB) GPUs using the DeepSpeed ZeRO-2 op- timization stage. We utilized Low-Rank Adapta- tion (LoRA) for parameter-efficient fine-tuning (Hu et al., 2022). The detailed hyperparameter configu- rations are summarized in Table 6. D.1 Modality Batching...
2022
-
[19]
Read the background story to understand the context
-
[20]
Rewatch as many times as needed to fully absorb both visual and audio details
Watch the entire video clip carefully. Rewatch as many times as needed to fully absorb both visual and audio details. Sometimes you can refer to suggestions in the background story to get extra information
-
[21]
Evaluate each claim on its own, using only the evidence presented within the video itself — including visuals, dialogue, audio cues, and on-screen text
-
[22]
To help you make more accurate and consistent judgments, here is an expanded explanation of how to interpret and assign probability percentages
Assign a percentage score (0%–100%) to reflect how likely the claim is to be true given the video. To help you make more accurate and consistent judgments, here is an expanded explanation of how to interpret and assign probability percentages. These examples are designed to cover a range of real-world cases you may encounter in the annotation task. 100% –...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.