Recognition: unknown
Model Space Reasoning as Search in Feedback Space for Planning Domain Generation
Pith reviewed 2026-05-10 16:49 UTC · model grok-4.3
The pith
An agentic LLM framework performs heuristic search over model space using symbolic feedback to generate planning domains from natural language.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors claim that heuristic search over the space of possible planning domains, directed by symbolic feedback including landmarks and VAL plan validator output, enables an agentic language model to produce domains of sufficient quality for practical use from natural language descriptions augmented with only a small amount of symbolic information.
What carries the argument
Heuristic search over model space in which each state is a candidate planning domain and transitions are driven by symbolic feedback from landmarks and VAL validator results.
If this is right
- Including landmarks in the feedback improves the ability of search to reach domains that generate valid plans.
- VAL validator output supplies concrete error signals that the search process can use to correct domain flaws.
- A small amount of symbolic augmentation added to natural language is enough to bootstrap effective search-based domain generation.
- The resulting domains support plan generation that passes independent validation checks in automated planners.
Where Pith is reading between the lines
- The same search-in-feedback-space pattern could be tested on generating formal models for other tasks such as workflow specification or constraint satisfaction problems.
- One could measure whether adding cost or resource feedback signals beyond landmarks further speeds convergence to usable domains.
- The method suggests treating LLM output as starting points for iterative search rather than final artifacts when the target is a formal structure.
Load-bearing premise
The chosen symbolic feedback signals from landmarks and VAL output supply enough reliable guidance to make search in model space effective, and LLMs can incorporate this feedback without introducing unrecoverable errors.
What would settle it
The central claim would be falsified if domains produced after search iterations with landmarks and VAL feedback fail to yield valid plans under VAL validation at rates no better than those from direct LLM prompting without search or feedback.
Figures

read the original abstract
The generation of planning domains from natural language descriptions remains an open problem even with the advent of large language models and reasoning models. Recent work suggests that while LLMs have the ability to assist with domain generation, they are still far from producing high quality domains that can be deployed in practice. To this end, we investigate the ability of an agentic language model feedback framework to generate planning domains from natural language descriptions that have been augmented with a minimal amount of symbolic information. In particular, we evaluate the quality of the generated domains under various forms of symbolic feedback, including landmarks, and output from the VAL plan validator. Using these feedback mechanisms, we experiment using heuristic search over model space to optimize domain quality.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that an agentic LLM framework can generate deployable planning domains from natural language descriptions (augmented with minimal symbolic information) by framing domain generation as heuristic search over model space, where search is guided by symbolic feedback signals including detected landmarks and output from the VAL plan validator.
Significance. If the empirical claims hold, the work offers a structured neuro-symbolic approach to a longstanding open problem in automated planning, potentially improving the reliability of LLM-generated PDDL domains beyond current direct-generation baselines. The explicit use of external validators and landmarks as feedback provides a falsifiable mechanism that could generalize to other formal synthesis tasks.
major comments (1)
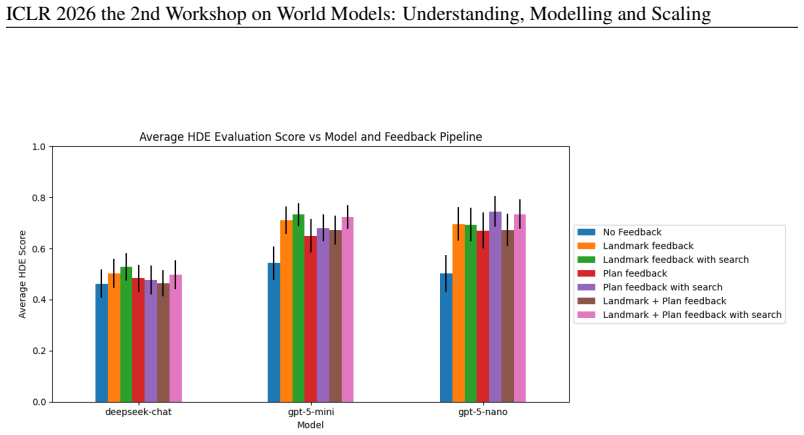
- [Experimental evaluation] The manuscript provides no quantitative results, baseline comparisons, or explicit definition of the domain-quality metric used to guide or evaluate the search (see abstract and any experimental section). This absence prevents assessment of whether the proposed feedback-driven search actually yields deployable domains or outperforms simpler LLM prompting.
minor comments (2)
- Clarify the precise state representation used for model-space search and how the heuristic is computed from the symbolic feedback signals.
- The abstract would be strengthened by a single sentence summarizing the key quantitative outcome (e.g., success rate or plan validity improvement).
Simulated Author's Rebuttal
We thank the referee for their constructive feedback and for recognizing the potential of our neuro-symbolic approach to the open problem of planning domain generation. We agree that the current manuscript requires a substantially strengthened experimental evaluation section with quantitative results, baseline comparisons, and an explicit domain-quality metric. We will revise accordingly to address this major comment.
read point-by-point responses
-
Referee: [Experimental evaluation] The manuscript provides no quantitative results, baseline comparisons, or explicit definition of the domain-quality metric used to guide or evaluate the search (see abstract and any experimental section). This absence prevents assessment of whether the proposed feedback-driven search actually yields deployable domains or outperforms simpler LLM prompting.
Authors: We acknowledge the validity of this observation. Although the abstract describes evaluation under symbolic feedback (landmarks and VAL output) and heuristic search over model space, the experimental section in the submitted manuscript is preliminary and lacks the requested quantitative details. In the revised version we will: (1) define the domain-quality metric explicitly as a composite score combining VAL validation success rate, landmark coverage, and plan executability; (2) report quantitative results including success rates, average search iterations to convergence, and domain-quality scores across a set of natural-language-to-PDDL tasks; and (3) include direct baseline comparisons against simple LLM prompting (no feedback, no search) and against search without symbolic feedback. These additions will enable a clear assessment of whether the feedback-driven search improves deployability over simpler methods. revision: yes
Circularity Check
No significant circularity; derivation relies on external validators
full rationale
The paper presents an agentic LLM framework performing heuristic search over model space, guided by independent external symbolic feedback (landmarks and VAL plan validator output). These components are standard, pre-existing tools from the planning literature and not constructed from the paper's own fitted parameters, self-definitions, or prior self-citations. No load-bearing step reduces by construction to the inputs; the quality optimization is driven by verifiable external signals rather than internal renaming or ansatz smuggling. The approach is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LLMs can be guided by symbolic feedback signals such as landmarks and validator output to produce higher-quality planning domains
- domain assumption Heuristic search over the space of possible models can optimize domain quality when driven by the chosen feedback
Reference graph
Works this paper leans on
-
[1]
A reminder about the importance of computing and exploiting invariants in planning
Vidal Alc´azar and ´Alvaro Torralba. A reminder about the importance of computing and exploiting invariants in planning. In Ronen Brafman, Carmel Domshlak, Patrik Haslum, and Shlomo Zil- berstein (eds.),Proceedings of the Twenty-Fifth International Conference on Automated Planning and Scheduling (ICAPS 2015), pp. 2–6. AAAI Press,
2015
-
[2]
Can LLMs fix issues with reasoning models? towards more likely models for AI planning
Turgay Caglar, Sirine Belhaj, Tathagata Chakraborti, Michael Katz, and Sarath Sreedharan. Can LLMs fix issues with reasoning models? towards more likely models for AI planning. In Jennifer Dy and Sriraam Natarajan (eds.),Proceedings of the Thirty-Eighth AAAI Conference on Artificial Intelligence (AAAI 2024), pp. 20061–20069. AAAI Press,
2024
-
[3]
A require- ments engineering-driven methodology for planning domain generation via llms with invariant- based refinement.LM4Plan @ ICAPS 2025,
Angelo Casciani, Giuseppe De Giacomo, Andrea Marrella, and Christoph Weinhuber. A require- ments engineering-driven methodology for planning domain generation via llms with invariant- based refinement.LM4Plan @ ICAPS 2025,
2025
-
[4]
NL2Plan: Robust LLM-driven planning from minimal text descriptions
Elliot Gestrin, Marco Kuhlmann, and Jendrik Seipp. NL2Plan: Robust LLM-driven planning from minimal text descriptions. InICAPS 2024 Workshop on Human-Aware and Explainable Planning (HAXP),
2024
-
[5]
Leveraging pre- trained large language models to construct and utilize world models for model-based task plan- ning
Lin Guan, Karthik Valmeekam, Sarath Sreedharan, and Subbarao Kambhampati. Leveraging pre- trained large language models to construct and utilize world models for model-based task plan- ning. In Alice Oh, Tristan Naumann, Amir Globerson, Kate Saenko, Moritz Hardt, and Sergey Levine (eds.),Advances in Neural Information Processing Systems 36: Annual Confere...
2023
-
[6]
V AL’s progress: The automatic validation tool for PDDL2.1 used in the International Planning Competition
Richard Howey and Derek Long. V AL’s progress: The automatic validation tool for PDDL2.1 used in the International Planning Competition. In Stefan Edelkamp and J ¨org Hoffmann (eds.), Proceedings of the ICAPS 2003 Workshop on the Competition: Impact, Organisation, Evaluation, Benchmarks,
2003
-
[7]
Text2world: Benchmarking large language models for sym- bolic world model generation
Mengkang Hu, Tianxing Chen, Yude Zou, Yuheng Lei, Qiguang Chen, Ming Li, Yao Mu, Hongyuan Zhang, Wenqi Shao, and Ping Luo. Text2world: Benchmarking large language models for sym- bolic world model generation. InACL (Findings), volume ACL 2025 ofFindings of ACL, pp. 26043–26066. Association for Computational Linguistics,
2025
-
[8]
Reshaping diverse planning
Michael Katz and Shirin Sohrabi. Reshaping diverse planning. In Vincent Conitzer and Fei Sha (eds.),Proceedings of the Thirty-Fourth AAAI Conference on Artificial Intelligence (AAAI 2020), pp. 9892–9899. AAAI Press,
2020
-
[9]
On k* search for top-k planning
Junkyu Lee, Michael Katz, and Shirin Sohrabi. On k* search for top-k planning. In Roman Bart ´ak, Wheeler Ruml, and Oren Salzman (eds.),Proceedings of the 16th Annual Symposium on Combi- natorial Search (SoCS 2023). AAAI Press,
2023
-
[10]
Leveraging environment interaction for automated PDDL translation and planning with large language models
Sadegh Mahdavi, Raquel Aoki, Keyi Tang, and Yanshuai Cao. Leveraging environment interaction for automated PDDL translation and planning with large language models. In Amir Globersons, Lester Mackey, Danielle Belgrave, Angela Fan, Ulrich Paquet, Jakub M. Tomczak, and Cheng Zhang (eds.),Advances in Neural Information Processing Systems 38: Annual Conferenc...
2024
-
[11]
PDDL – The Planning Domain Definition Language – Version 1.2
10 ICLR 2026 the 2nd Workshop on World Models: Understanding, Modelling and Scaling Drew McDermott, Malik Ghallab, Adele Howe, Craig Knoblock, Ashwin Ram, Manuela Veloso, Daniel Weld, and David Wilkins. PDDL – The Planning Domain Definition Language – Version 1.2. Technical Report CVC TR-98-003/DCS TR-1165, Yale Center for Computational Vision and Control...
2026
-
[12]
Large language models as planning domain generators
James Oswald, Kavitha Srinivas, Harsha Kokel, Junkyu Lee, Michael Katz, and Shirin Sohrabi. Large language models as planning domain generators. In Sara Bernardini and Christian Muise (eds.),Proceedings of the Thirty-Fourth International Conference on Automated Planning and Scheduling (ICAPS 2024), pp. 423–431. AAAI Press,
2024
-
[13]
Landmark heuristics for lifted classical planning
Julia Wichlacz, Daniel H¨oller, and J¨org Hoffmann. Landmark heuristics for lifted classical planning. In Luc De Raedt (ed.),Proceedings of the Thirty-First International Joint Conference on Artificial Intelligence, IJCAI 2022, Vienna, Austria, 23-29 July 2022, pp. 4665–4671. ijcai.org,
2022
-
[14]
URLhttps://doi.org/10.24963/ijcai.2022/647
doi: 10.24963/IJCAI.2022/647. URLhttps://doi.org/10.24963/ijcai.2022/647. Zhouliang Yu, Yuhuan Yuan, Tim Z. Xiao, Fuxiang Frank Xia, Jie Fu, Ge Zhang, Ge Lin, and Weiyang Liu. Generating symbolic world models via test-time scaling of large language models. Trans. Mach. Learn. Res., 2025,
-
[15]
ISR-LLM: iterative self- refined large language model for long-horizon sequential task planning
Zhehua Zhou, Jiayang Song, Kunpeng Yao, Zhan Shu, and Lei Ma. ISR-LLM: iterative self- refined large language model for long-horizon sequential task planning. InIEEE Interna- tional Conference on Robotics and Automation, ICRA 2024, Yokohama, Japan, May 13-17, 2024, pp. 2081–2088. IEEE,
2024
-
[16]
doi: 10.1109/ICRA57147.2024.10610065. URLhttps: //doi.org/10.1109/ICRA57147.2024.10610065. Max Zuo, Francisco Piedrahita Velez, Xiaochen Li, Michael Littman, and Stephen H. Bach. Plan- etarium: A rigorous benchmark for translating text to structured planning languages. InNAACL (Long Papers), pp. 11223–11240. Association for Computational Linguistics,
-
[17]
overall": {
11 ICLR 2026 the 2nd Workshop on World Models: Understanding, Modelling and Scaling A SAMPLEPDDL DOMAIN ANDDESCRIPTION Here we provide our version of the classic blocksworld domain, referred to in Tables 2 and 1 as “blocks”. (define (domain blocks) (:requirements :strips :typing) (:types block) (:predicates (on ?x - block ?y - block) (ontable ?x - block) ...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.