Recognition: no theorem link
What Matters in Virtual Try-Off? Dual-UNet Diffusion Model For Garment Reconstruction
Pith reviewed 2026-05-10 17:44 UTC · model grok-4.3
The pith
A Dual-UNet diffusion model reconstructs flat canonical garments from draped try-on images more accurately than prior methods by testing specific backbone, conditioning, and loss choices.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
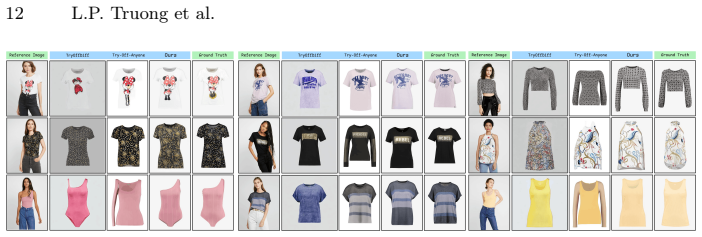
The Dual-UNet Diffusion Model, when equipped with an effective Stable Diffusion backbone, carefully chosen mask and semantic conditioning, and auxiliary attention-based perceptual losses trained in curriculum stages, achieves state-of-the-art virtual try-off performance by reducing DISTS by 9.5 percent on VITON-HD and DressCode while delivering competitive scores on LPIPS, FID, KID, and SSIM.
What carries the argument
Dual-UNet Diffusion Model that processes masked and unmasked image inputs through parallel U-Net paths while adding high-level semantic features and attention-based losses to guide accurate recovery of garment details.
If this is right
- Mask design and whether inputs are masked or unmasked during conditioning directly influence boundary accuracy and texture fidelity in the output garment.
- Inclusion of high-level semantic features improves the model's ability to capture overall garment style and structure beyond low-level pixels.
- Auxiliary attention-based losses combined with perceptual objectives and curriculum schedules reduce artifacts in reconstructed folds and seams.
- The resulting configurations supply stronger baselines that future virtual try-off work can build upon or extend to related inverse clothing tasks.
Where Pith is reading between the lines
- The conditioning ablations may transfer to other clothing image translation problems such as garment editing or virtual fitting preview generation.
- If the model proves robust outside benchmarks, retailers could automatically extract clean product images from model photos without additional photography.
- Combining the reconstruction output with 3D garment simulation pipelines could produce more accurate virtual try-on experiences from single 2D images.
Load-bearing premise
The performance gains measured on controlled benchmark datasets will continue to hold for real-world garment images that differ in lighting, pose, and fabric appearance.
What would settle it
Testing the trained model on a new set of real-world photographs of people wearing garments under varied natural lighting and poses, then comparing reconstructed flat images against ground-truth canonical garment photos using the same DISTS metric.
Figures













read the original abstract
Virtual Try-On (VTON) has seen rapid advancements, providing a strong foundation for generative fashion tasks. However, the inverse problem, Virtual Try-Off (VTOFF)-aimed at reconstructing the canonical garment from a draped-on image-remains a less understood domain, distinct from the heavily researched field of VTON. In this work, we seek to establish a robust architectural foundation for VTOFF by studying and adapting various diffusion-based strategies from VTON and general Latent Diffusion Models (LDMs). We focus our investigation on the Dual-UNet Diffusion Model architecture and analyze three axes of design: (i) Generation Backbone: comparing Stable Diffusion variants; (ii) Conditioning: ablating different mask designs, masked/unmasked inputs for image conditioning, and the utility of high-level semantic features; and (iii) Losses and Training Strategies: evaluating the impact of the auxiliary attention-based loss, perceptual objectives and multi-stage curriculum schedules. Extensive experiments reveal trade-offs across various configuration options. Evaluated on VITON-HD and DressCode datasets, our framework achieves state-of-the-art performance with a drop of 9.5\% on the primary metric DISTS and competitive performance on LPIPS, FID, KID, and SSIM, providing both stronger baselines and insights to guide future Virtual Try-Off research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a Dual-UNet diffusion model for Virtual Try-Off (VTOFF), the inverse task of reconstructing canonical garment images from draped-on person images. It systematically ablates three axes—generation backbone (Stable Diffusion variants), conditioning (mask designs, masked/unmasked inputs, high-level semantic features), and losses/training (auxiliary attention loss, perceptual objectives, multi-stage curriculum)—and reports state-of-the-art results on the VITON-HD and DressCode datasets, including a 9.5% drop in the primary DISTS metric along with competitive LPIPS, FID, KID, and SSIM scores.
Significance. If the central empirical claims hold under matched evaluation protocols, the work supplies both stronger baselines and actionable design insights for the under-explored VTOFF domain. The controlled ablations across backbone, conditioning, and loss axes on two standard datasets constitute a solid empirical contribution that can guide subsequent diffusion-based garment reconstruction research.
major comments (2)
- [§4 and Table 1] §4 (Experimental Evaluation) and Table 1 (main quantitative results): the SOTA claim of a 9.5% DISTS reduction is load-bearing for the paper's contribution, yet the manuscript does not explicitly confirm that the exact test splits, pose/lighting distributions, mask generation procedure, and metric implementation match those used by the cited VTOFF baselines. Small protocol differences can produce metric shifts of this magnitude in perceptual reconstruction tasks.
- [§4.3] §4.3 (Ablation studies): all reported metric improvements are given as single-point estimates without error bars, standard deviations across random seeds, or statistical significance tests. Because diffusion sampling is stochastic, the absence of these statistics weakens the reliability of the ablation conclusions on conditioning strength and auxiliary loss weights.
minor comments (2)
- [Abstract] Abstract: the parenthetical '(VTOFF)-aimed' is missing a space after the closing parenthesis.
- [§4] The manuscript would benefit from an explicit statement in the experimental section confirming that all baseline numbers were either re-implemented with the authors' preprocessing pipeline or taken from the original papers under identical conditions.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation and the recommendation for minor revision. We address the two major comments point by point below, providing honest clarifications and indicating the changes we will incorporate.
read point-by-point responses
-
Referee: [§4 and Table 1] §4 (Experimental Evaluation) and Table 1 (main quantitative results): the SOTA claim of a 9.5% DISTS reduction is load-bearing for the paper's contribution, yet the manuscript does not explicitly confirm that the exact test splits, pose/lighting distributions, mask generation procedure, and metric implementation match those used by the cited VTOFF baselines. Small protocol differences can produce metric shifts of this magnitude in perceptual reconstruction tasks.
Authors: We appreciate this concern regarding protocol consistency. Our experiments strictly follow the official test splits, preprocessing pipelines, mask generation procedures, and metric implementations from the VITON-HD and DressCode papers as well as the released code of the cited baselines. To make this explicit and eliminate any ambiguity, we will revise §4.1 to include a dedicated paragraph on evaluation protocols and add a clarifying statement to the caption of Table 1 confirming matched protocols. This will directly support the validity of the reported 9.5% DISTS improvement. revision: yes
-
Referee: [§4.3] §4.3 (Ablation studies): all reported metric improvements are given as single-point estimates without error bars, standard deviations across random seeds, or statistical significance tests. Because diffusion sampling is stochastic, the absence of these statistics weakens the reliability of the ablation conclusions on conditioning strength and auxiliary loss weights.
Authors: We agree that the stochastic nature of diffusion sampling makes single-point estimates less reliable and that error bars or multi-seed statistics would strengthen the ablation analysis. However, the computational cost of running multiple random seeds for every ablation configuration is substantial. In the revised manuscript we will add an explicit discussion in §4.3 acknowledging this limitation, noting that the observed trends remained consistent in our internal multi-seed spot-checks on key configurations, and we will report standard deviations for the main results in Table 1 where space allows. revision: partial
Circularity Check
No circularity: empirical ablation on external benchmarks
full rationale
The paper is an empirical study that proposes a Dual-UNet diffusion architecture for virtual try-off, performs ablations across backbones, conditioning masks, and loss terms, and reports quantitative results on the standard VITON-HD and DressCode test sets. No derivation, uniqueness theorem, or predictive equation is presented whose output is forced by construction from its own fitted inputs or self-citations. All performance numbers (DISTS, LPIPS, etc.) are obtained by running the trained model on held-out external data and comparing against independently published baselines, satisfying the criterion of an independent, falsifiable evaluation.
Axiom & Free-Parameter Ledger
free parameters (2)
- Mask design variants and conditioning strength
- Auxiliary loss weights and curriculum schedule stages
axioms (1)
- domain assumption Diffusion models trained on VTON data can be directly repurposed for the inverse VTOFF task with architectural modifications.
Reference graph
Works this paper leans on
-
[1]
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., Zhong, H., Zhu, Y., Yang, M., Li, Z., Wan, J., Wang, P., Ding, W., Fu, Z., Xu, Y., Ye, J., Zhang, X., Xie, T., Cheng, Z., Zhang, H., Yang, Z., Xu, H., Lin, J.: Qwen2.5-vl technical report. arXiv preprint arXiv:2502.13923 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
In: The Thirteenth International Conference on Learning Representa- tions (2025)
Berrada, T., Astolfi, P., Hall, M., Havasi, M., Benchetrit, Y., Romero-Soriano, A., Alahari, K., Drozdzal, M., Verbeek, J.: Boosting latent diffusion with perceptual objectives. In: The Thirteenth International Conference on Learning Representa- tions (2025)
2025
-
[3]
Bookstein, F.L.: Principal Warps: Thin-Plate Splines and the Decomposition of Deformations. IEEE Trans. Pattern Anal. Mach. Intell.11(6), 567–585 (Jun 1989). https://doi.org/10.1109/34.24792
-
[4]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Choi, S., Park, S., Lee, M., Choo, J.: Viton-hd: High-resolution virtual try-on via misalignment-aware normalization. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 14131–14140 (2021)
2021
-
[5]
In: Computer Vision – ECCV 2024
Choi, Y., Kwak, S., Lee, K., Choi, H., Shin, J.: Improving Diffusion Models for Authentic Virtual Try-on in the Wild. In: Computer Vision – ECCV 2024. vol. 15144, pp. 206–235. Springer Nature Switzerland, Cham (2025), lecture Notes in Computer Science
2024
-
[6]
In: The Thirteenth International Conference on Learning Representations (2025)
Chong, Z., Dong, X., Li, H., Zhang, W., Zhao, H., Jiang, D., Liang, X., et al.: Catvton: Concatenation is all you need for virtual try-on with diffusion models. In: The Thirteenth International Conference on Learning Representations (2025)
2025
-
[7]
In: Proceedings of the IEEE/CVF international conference on computer vision
Cui, A., McKee, D., Lazebnik, S.: Dressing in order: Recurrent person image gen- eration for pose transfer, virtual try-on and outfit editing. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 14638–14647 (2021)
2021
-
[8]
Advances in neural in- formation processing systems27(2014)
Goodfellow, I.J., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., Bengio, Y.: Generative adversarial nets. Advances in neural in- formation processing systems27(2014)
2014
-
[9]
In: Proceedings of the 31st ACM International Conference on Multimedia
Gou,J.,Sun,S.,Zhang,J.,Si,J.,Qian,C.,Zhang,L.:Tamingthepowerofdiffusion models for high-quality virtual try-on with appearance flow. In: Proceedings of the 31st ACM International Conference on Multimedia. pp. 7599–7607 (2023)
2023
-
[10]
In: Proceedings of the IEEE/CVF international conference on computer vision
Han,X.,Hu,X.,Huang,W.,Scott,M.R.:Clothflow:Aflow-basedmodelforclothed person generation. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 10471–10480 (2019)
2019
-
[11]
In: 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition
Han, X., Wu, Z., Wu, Z., Yu, R., Davis, L.S.: VITON: An Image- Based Virtual Try-on Network. In: 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 7543–7552 (Jun 2018). https://doi.org/10.1109/CVPR.2018.00787, iSSN: 2575-7075
-
[12]
Advances in neural information processing systems33, 6840–6851 (2020)
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. Advances in neural information processing systems33, 6840–6851 (2020)
2020
-
[13]
In: Proceedings of the IEEE international conference on computer vision workshops
Jetchev, N., Bergmann, U.: The conditional analogy gan: Swapping fashion arti- cles on people images. In: Proceedings of the IEEE international conference on computer vision workshops. pp. 2287–2292 (2017)
2017
-
[14]
In: European Conference on Computer Vision (ECCV) (2024) 14 L.P
Kang, M., Zhang, R., Barnes, C., Paris, S., Kwak, S., Park, J., Shechtman, E., Zhu, J.Y., Park, T.: Distilling Diffusion Models into Conditional GANs. In: European Conference on Computer Vision (ECCV) (2024) 14 L.P. Truong et al
2024
-
[15]
In: 2024 IEEE/CVF Conference on Computer Vision and Pat- tern Recognition (CVPR)
Kim, J., Gu, G., Park, M., Park, S., Choo, J.: Stable VITON: Learn- ing Semantic Correspondence with Latent Diffusion Model for Virtual Try- On. In: 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 8176–8185. IEEE, Seattle, WA, USA (Jun 2024). https://doi.org/10.1109/CVPR52733.2024.00781
-
[16]
In: Proceedings of the IEEE/CVF international confer- ence on computer vision workshops
Lee, H.J., Lee, R., Kang, M., Cho, M., Park, G.: La-viton: A network for looking- attractive virtual try-on. In: Proceedings of the IEEE/CVF international confer- ence on computer vision workshops. pp. 0–0 (2019)
2019
-
[17]
In: The Eleventh International Conference on Learning Representations (2023), https://openreview.net/forum?id=PqvMRDCJT9t
Lipman, Y., Chen, R.T.Q., Ben-Hamu, H., Nickel, M., Le, M.: Flow matching for generative modeling. In: The Eleventh International Conference on Learning Representations (2023), https://openreview.net/forum?id=PqvMRDCJT9t
2023
-
[18]
Decoupled Weight Decay Regularization
Loshchilov, I., Hutter, F.: Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[19]
Conditional Generative Adversarial Nets
Mirza, M., Osindero, S.: Conditional generative adversarial nets. arXiv preprint arXiv:1411.1784 (2014)
work page internal anchor Pith review arXiv 2014
-
[20]
In: Proceedings of the 31st ACM international conference on multimedia
Morelli, D., Baldrati, A., Cartella, G., Cornia, M., Bertini, M., Cucchiara, R.: Ladi- vton: Latent diffusion textual-inversion enhanced virtual try-on. In: Proceedings of the 31st ACM international conference on multimedia. pp. 8580–8589 (2023)
2023
-
[21]
In: Proceedings of the Eu- ropean Conference on Computer Vision (2022)
Morelli, D., Fincato, M., Cornia, M., Landi, F., Cesari, F., Cucchiara, R.: Dress Code: High-Resolution Multi-Category Virtual Try-On. In: Proceedings of the Eu- ropean Conference on Computer Vision (2022)
2022
-
[22]
Mou, C., Wang, X., Xie, L., Wu, Y., Zhang, J., Qi, Z., Shan, Y.: T2i- adapter: learning adapters to dig out more controllable ability for text-to- image diffusion models. In: Proceedings of the Thirty-Eighth AAAI Con- ference on Artificial Intelligence and Thirty-Sixth Conference on Innovative Applications of Artificial Intelligence and Fourteenth Symposi...
-
[23]
Peebles,W.,Xie,S.:Scalablediffusionmodelswithtransformers.In:Proceedingsof the IEEE/CVF international conference on computer vision. pp. 4195–4205 (2023)
2023
-
[24]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
Podell, D., English, Z., Lacey, K., Blattmann, A., Dockhorn, T., Müller, J., Penna, J., Rombach, R.: Sdxl: Improving latent diffusion models for high-resolution image synthesis. arXiv preprint arXiv:2307.01952 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[25]
In: International conference on machine learning
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International conference on machine learning. pp. 8748–8763. PmLR (2021)
2021
-
[26]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10684–10695 (2022)
2022
-
[27]
https://doi.org/10.48550/arXiv.2412.11513, arXiv:2412.11513 [cs]
Shen, L., Huang, R., Wang, Z.: IGR: Improving Diffusion Model for Garment Restoration from Person Image (Dec 2024). https://doi.org/10.48550/arXiv.2412.11513, arXiv:2412.11513 [cs]
-
[28]
https://unsplash.com/ (Accessed 2025)
Unsplash: Unsplash - the internet’s source of free stock photos and images. https://unsplash.com/ (Accessed 2025)
2025
-
[29]
Advances in neural information pro- cessing systems30(2017) What Matters in Virtual Try-Off? 15
Vaswani,A.,Shazeer,N.,Parmar,N.,Uszkoreit,J.,Jones,L.,Gomez,A.N.,Kaiser, Ł., Polosukhin, I.: Attention is all you need. Advances in neural information pro- cessing systems30(2017) What Matters in Virtual Try-Off? 15
2017
-
[30]
arXiv preprint arXiv:2411.18350 , year=
Velioglu, R., Bevandic, P., Chan, R., Hammer, B.: TryOffDiff: Virtual-Try-Off via High-Fidelity Garment Reconstruction using Diffusion Models (Nov 2024). https://doi.org/10.48550/arXiv.2411.18350, arXiv:2411.18350 [cs]
-
[31]
In: Proceedings of the European conference on computer vision (ECCV)
Wang, B., Zheng, H., Liang, X., Chen, Y., Lin, L., Yang, M.: Toward characteristic- preserving image-based virtual try-on network. In: Proceedings of the European conference on computer vision (ECCV). pp. 589–604 (2018)
2018
-
[32]
arXiv preprint arXiv:2404.14162 (2024)
Wang,C.,Chen,T.,Chen,Z.,Huang,Z.,Jiang,T.,Wang,Q.,Shan,H.:Fldm-vton: Faithful latent diffusion model for virtual try-on. arXiv preprint arXiv:2404.14162 (2024)
-
[33]
arXiv preprint arXiv:2507.16010 (2025)
Wang, Z., Sun, X., Wu, S., Zhan, J., Si, J., Zhang, C., Zhang, L., Zhang, J.: Fw- vton: Flattening-and-warping for person-to-person virtual try-on. arXiv preprint arXiv:2507.16010 (2025)
-
[34]
arXiv preprint arXiv:2412.08573 (2024)
Xarchakos, I., Koukopoulos, T.: TryOffAnyone: Tiled Cloth Generation from a Dressed Person (Jan 2025). https://doi.org/10.48550/arXiv.2412.08573, arXiv:2412.08573 [cs]
-
[35]
Xu, Y., Gu, T., Chen, W., Chen, A.: Ootdiffusion: outfitting fusion based latent diffusion for controllable virtual try-on. In: Proceedings of the Thirty-Ninth AAAI Conference on Artificial Intelligence and Thirty-Seventh Conference on Innovative Applications of Artificial Intelligence and Fifteenth Symposium on Educational Advances in Artificial Intellig...
-
[36]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Yang, B., Gu, S., Zhang, B., Zhang, T., Chen, X., Sun, X., Chen, D., Wen, F.: Paint by example: Exemplar-based image editing with diffusion models. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 18381–18391 (2023)
2023
-
[37]
IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models
Ye, H., Zhang, J., Liu, S., Han, X., Yang, W.: Ip-adapter: Text compati- ble image prompt adapter for text-to-image diffusion models. arXiv preprint arXiv:2308.06721 (2023)
work page internal anchor Pith review arXiv 2023
-
[38]
Neural Computing and Applications32, 17587–17600 (2020)
Zeng, W., Zhao, M., Gao, Y., Zhang, Z.: Tilegan: category-oriented attention-based high-quality tiled clothes generation from dressed person. Neural Computing and Applications32, 17587–17600 (2020)
2020
-
[39]
In: Proceedings of the IEEE/CVF international conference on computer vision
Zhai, X., Mustafa, B., Kolesnikov, A., Beyer, L.: Sigmoid loss for language im- age pre-training. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 11975–11986 (2023)
2023
-
[40]
In: Proceedings of the IEEE/CVF international conference on computer vision
Zhang, L., Rao, A., Agrawala, M.: Adding conditional control to text-to-image diffusion models. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 3836–3847 (2023)
2023
-
[41]
IEEE Transactions on Visualization and Computer Graphics pp
Zhang, N., Xie, Z., Sun, Z., Zhu, H., Jin, Z., Xiang, N., Han, X., Wu, S.: Viton-gun: Person-to-person virtual try-on via garment unwrapping. IEEE Transactions on Visualization and Computer Graphics pp. 1–13 (2025). https://doi.org/10.1109/TVCG.2025.3550776
-
[42]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Zhou, Z., Liu, S., Han, X., Liu, H., Ng, K.W., Xie, T., Cong, Y., Li, H., Xu, M., Pérez-Rúa, J.M., et al.: Learning flow fields in attention for controllable person image generation. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 2491–2501 (2025)
2025
-
[43]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Zhu, L., Yang, D., Zhu, T., Reda, F., Chan, W., Saharia, C., Norouzi, M., Kemelmacher-Shlizerman, I.: Tryondiffusion: A tale of two unets. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 4606–4615 (2023) 16 L.P. Truong et al. Supplementary Material A Dataset and Training Details Fig.5.Failure case in VTOFF due to...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.