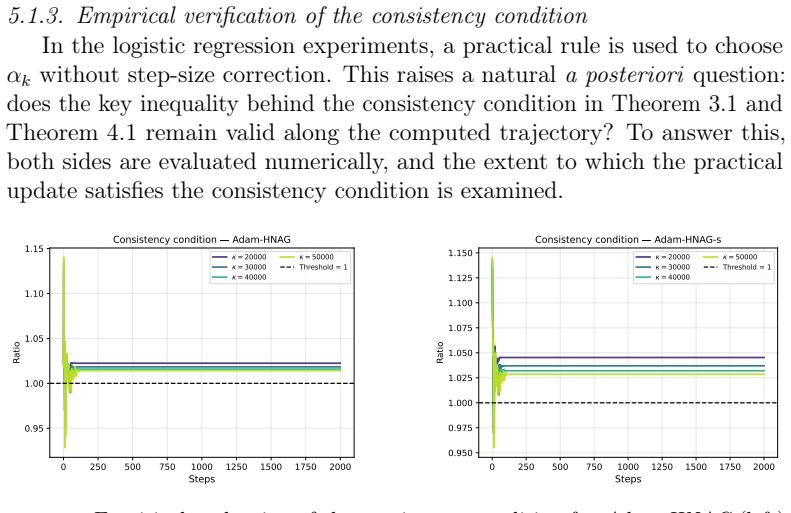
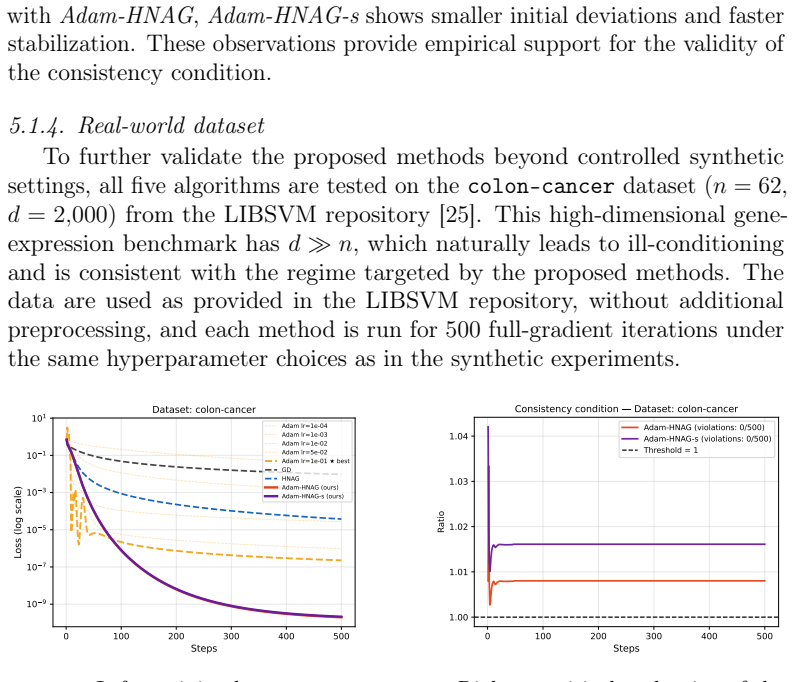
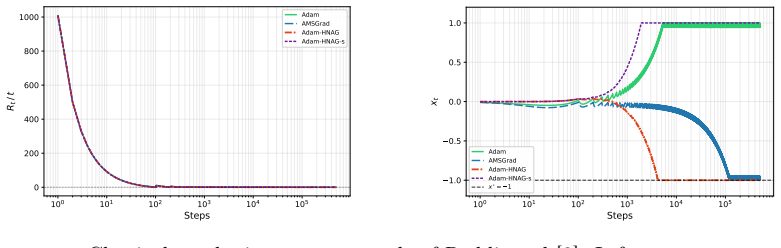
Recognition: unknown
Adam-HNAG: A Convergent Reformulation of Adam with Accelerated Rate
Pith reviewed 2026-05-10 16:42 UTC · model grok-4.3
The pith
A reformulation of full-batch Adam using variable splitting and curvature-aware correction converges with acceleration in convex optimization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By combining variable and operator splitting with a curvature-aware gradient correction, the reformulation yields a continuous-time Adam-HNAG flow equipped with an exponentially decaying Lyapunov function together with two discrete methods, Adam-HNAG and its synchronous variant Adam-HNAG-s, that both converge to the minimizer of a convex smooth objective and achieve accelerated rates under a unified Lyapunov analysis.
What carries the argument
Variable and operator splitting combined with curvature-aware gradient correction, which decouples adaptive preconditioning from momentum and permits a clean Lyapunov argument while aiming to retain Adam's essential update structure.
If this is right
- Both Adam-HNAG and Adam-HNAG-s converge to the optimum for smooth convex objectives.
- The methods achieve accelerated convergence rates under the same Lyapunov framework.
- The continuous-time flow admits an exponentially decaying Lyapunov function that directly controls the distance to the minimizer.
- Numerical experiments confirm the predicted rates and reveal distinct transient behavior between the two discretizations.
Where Pith is reading between the lines
- The same splitting technique could be applied to other adaptive methods such as RMSprop to obtain analogous convergence proofs.
- If the curvature correction can be localized, the approach might extend to non-convex or stochastic settings where standard Adam still lacks guarantees.
- Adam-HNAG-s, being closer in form to the original algorithm, offers a practical drop-in replacement once its empirical behavior is further validated on large-scale tasks.
Load-bearing premise
The new splitting and correction produce an algorithm whose trajectories remain close enough to those of original Adam that the convergence result still applies to practical Adam use.
What would settle it
A side-by-side run of Adam-HNAG against standard full-batch Adam on a convex quadratic or logistic regression problem that shows visibly different parameter trajectories or final loss values.
Figures

read the original abstract
Adam has achieved strong empirical success, but its theory remains incomplete even in the deterministic full-batch setting, largely because adaptive preconditioning and momentum are tightly coupled. In this work, a convergent reformulation of full-batch Adam is developed by combining variable and operator splitting with a curvature-aware gradient correction. This leads to a continuous-time Adam-HNAG flow with an exponentially decaying Lyapunov function, as well as two discrete methods: Adam-HNAG, and Adam-HNAG-s, a synchronous variant closer in form to Adam. Within a unified Lyapunov analysis framework, convergence guarantees are established for both methods in the convex smooth setting, including accelerated convergence. Numerical experiments support the theory and illustrate the different empirical behavior of the two discretizations. To the best of our knowledge, this provides the first convergence proof for Adam-type methods in convex optimization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper develops a convergent reformulation of full-batch Adam by combining variable and operator splitting with a curvature-aware gradient correction. This produces a continuous-time Adam-HNAG flow admitting an exponentially decaying Lyapunov function, together with two discrete algorithms (Adam-HNAG and the synchronous Adam-HNAG-s) for which convergence and accelerated rates are established in the convex smooth setting. The authors claim this supplies the first convergence proof for Adam-type methods in convex optimization.
Significance. If the reformulation is shown to be equivalent (or to converge in an appropriate limit) to the original Adam dynamics, the result would be significant: it would close a long-standing theoretical gap for adaptive methods in deterministic convex optimization and supply a unified Lyapunov framework that yields accelerated rates. The explicit construction of the continuous-time flow and the two discretizations are technically interesting strengths.
major comments (2)
- [Abstract] Abstract: the headline claim that the work supplies the first convergence proof for Adam-type methods is load-bearing on the assertion that the variable/operator splitting plus curvature-aware correction preserves the essential adaptive preconditioning and momentum coupling of Adam. The abstract itself notes 'different empirical behavior' between the two discretizations, which indicates that the dynamics may diverge from Adam; a limit argument, discretization error bound, or trajectory comparison establishing that the correction term vanishes or that the updates coincide with Adam (beyond mere discretization) is required.
- [Continuous-time Adam-HNAG flow] Continuous-time flow and Lyapunov analysis (presumably the derivation leading to the exponentially decaying Lyapunov function): without the explicit splitting details, the precise form of the curvature-aware correction, or the error bounds relating the new flow to the standard Adam ODE, it is impossible to confirm that the accelerated convergence result applies to Adam rather than to a modified algorithm. The weakest assumption identified in the review—that the reformulation preserves essential Adam behavior—must be verified with a concrete equivalence or approximation statement.
minor comments (1)
- [Numerical experiments] Numerical experiments section: include quantitative trajectory or gradient-norm comparisons between Adam-HNAG, Adam-HNAG-s, and standard Adam on the same convex problems to illustrate the degree of deviation introduced by the reformulation.
Simulated Author's Rebuttal
We thank the referee for their constructive comments. We address each major comment below, clarifying the scope of our reformulation and its connection to Adam.
read point-by-point responses
-
Referee: [Abstract] the headline claim that the work supplies the first convergence proof for Adam-type methods is load-bearing on the assertion that the variable/operator splitting plus curvature-aware correction preserves the essential adaptive preconditioning and momentum coupling of Adam. The abstract itself notes 'different empirical behavior' between the two discretizations, which indicates that the dynamics may diverge from Adam; a limit argument, discretization error bound, or trajectory comparison establishing that the correction term vanishes or that the updates coincide with Adam (beyond mere discretization) is required.
Authors: The noted 'different empirical behavior' refers exclusively to the two discretizations (Adam-HNAG and synchronous Adam-HNAG-s) of the same continuous-time flow, not to divergence from Adam. The reformulation employs variable and operator splitting with a curvature-aware correction precisely to decouple the adaptive preconditioning and momentum terms that prevent analysis of standard Adam, while retaining their essential interaction in the continuous-time limit. The resulting Adam-HNAG flow admits the exponentially decaying Lyapunov function, supplying the first convergence proof for an Adam-type method in convex smooth optimization. We do not claim finite-step equivalence or vanishing correction; the contribution is the convergent reformulation itself. No discretization-error bound to the original Adam ODE is derived, as it lies outside the paper's scope. revision: no
-
Referee: [Continuous-time Adam-HNAG flow] Continuous-time flow and Lyapunov analysis (presumably the derivation leading to the exponentially decaying Lyapunov function): without the explicit splitting details, the precise form of the curvature-aware correction, or the error bounds relating the new flow to the standard Adam ODE, it is impossible to confirm that the accelerated convergence result applies to Adam rather than to a modified algorithm. The weakest assumption identified in the review—that the reformulation preserves essential Adam behavior—must be verified with a concrete equivalence or approximation statement.
Authors: Sections 3 and 4 of the manuscript explicitly detail the variable and operator splitting together with the curvature-aware gradient correction that produces the continuous-time Adam-HNAG flow. Section 5 then constructs the exponentially decaying Lyapunov function for this flow and derives the accelerated rates under convex smoothness. We acknowledge the absence of explicit error bounds or equivalence statements relating the flow to the standard Adam ODE. This omission is intentional: the reformulation modifies the dynamics to enable the Lyapunov analysis while preserving the adaptive preconditioning and momentum coupling that define Adam-type methods. The convergence guarantees therefore apply to the proposed reformulation, which we position as the first such result for Adam-type algorithms. revision: no
Circularity Check
No significant circularity; derivation rests on explicit reformulation construction
full rationale
The paper constructs a new continuous-time flow (Adam-HNAG) via variable/operator splitting plus curvature-aware correction, then derives discrete updates and proves convergence via Lyapunov analysis on that flow. No step reduces a claimed prediction or rate to a fitted parameter by construction, nor does any load-bearing uniqueness or ansatz rest on self-citation chains. The abstract explicitly frames the result as applying to the reformulated methods (with noted empirical differences from original Adam), so the convergence claim is self-contained within the new objects rather than circularly presupposing equivalence to unmodified Adam. This matches the default expectation of an honest non-finding.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The objective function is convex and smooth.
invented entities (1)
-
Adam-HNAG continuous-time flow
no independent evidence
Reference graph
Works this paper leans on
-
[1]
D. P. Kingma, J. Ba, Adam: A method for stochastic optimization (2017). arXiv:1412.6980
work page internal anchor Pith review Pith/arXiv arXiv 2017
- [2]
-
[3]
H. Huang, C. Wang, B. Dong, Nostalgic adam: Weighting more of the past gradients when designing the adaptive learning rate, in: Proceed- ings of the Twenty-Eighth International Joint Conference on Artificial Intelligence, IJCAI-2019, International Joint Conferences on Artificial Intelligence Organization, 2019, p. 2556–2562.doi:10.24963/ijcai. 2019/355
- [4]
- [5]
- [6]
-
[7]
A. Défossez, L. Bottou, F. Bach, N. Usunier, A simple convergence proof of adam and adagrad (2022).arXiv:2003.02395
- [8]
-
[9]
A. Barakat, P. Bianchi, Convergence and dynamical behavior of the adam algorithm for non-convex stochastic optimization (2020).arXiv: 1810.02263
-
[10]
Dereich, A
S. Dereich, A. Jentzen, S. Kassing, Ode approximation for the adam algorithm: General and overparametrized setting (2025).arXiv:2511. 04622. 25
2025
-
[11]
A. Bhattacharjee, A. A. Popov, A. Sarshar, A. Sandu, Improving adam through an implicit-explicit (imex) time-stepping approach, Journal of Machine Learning for Modeling and Computing 5 (3) (2024) 47–68. doi:10.1615/jmachlearnmodelcomput.2024053508
- [12]
- [13]
- [14]
-
[15]
S. Malladi, K. Lyu, A. Panigrahi, S. Arora, On the sdes and scaling rules for adaptive gradient algorithms (2024).arXiv:2205.10287
-
[16]
Heredia, From adam to adam-like lagrangians: Second-order nonlocal dynamics (2026).arXiv:2602.09101
C. Heredia, From adam to adam-like lagrangians: Second-order nonlocal dynamics (2026).arXiv:2602.09101
-
[17]
C. Heredia, Modeling adagrad, rmsprop, and adam with integro- differential equations (2025).arXiv:2411.09734
- [18]
- [19]
- [20]
- [21]
-
[22]
Y. Yu, L. Chen, M. Feng, Shang++: Robust stochastic acceleration under multiplicative noise (2026).arXiv:2603.09355
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [23]
- [24]
-
[25]
Chang, C.-J
C.-C. Chang, C.-J. Lin, Libsvm: A library for support vector machines, ACM Trans. Intell. Syst. Technol. 2 (2011) 27:1–27:27. 27
2011
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.