Recognition: unknown
A Little Rank Goes a Long Way: Random Scaffolds with LoRA Adapters Are All You Need
Pith reviewed 2026-05-10 16:50 UTC · model grok-4.3
The pith
Frozen random neural network backbones with low-rank LoRA adapters recover 96-100% of full training performance while updating only 0.5-40% of parameters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
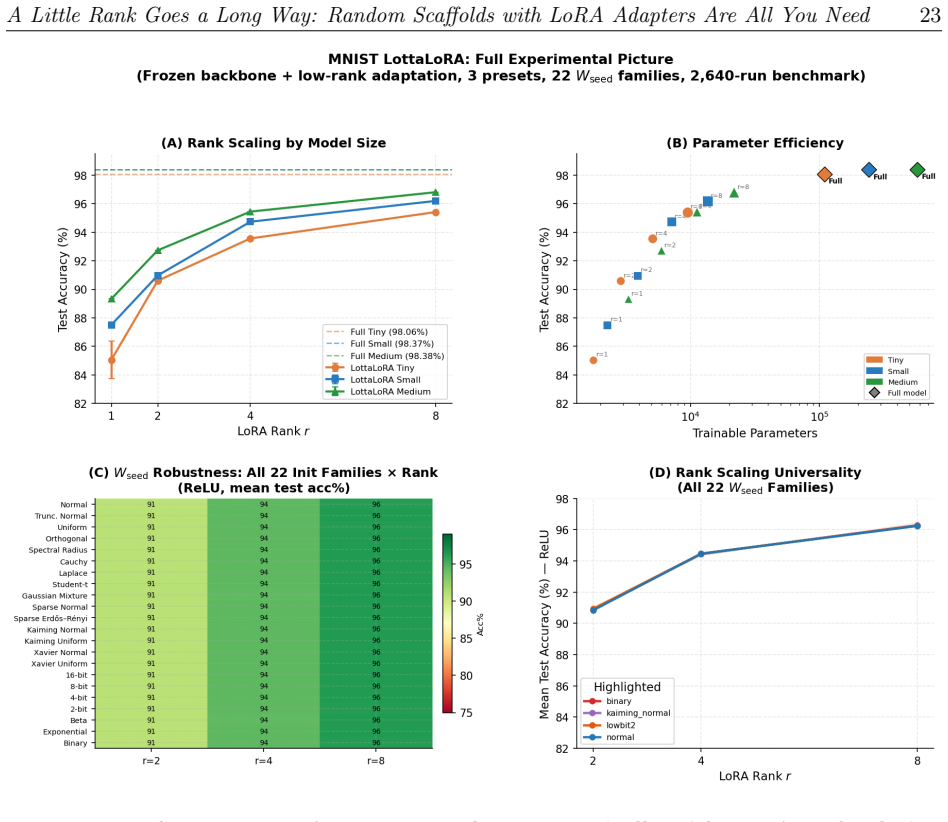
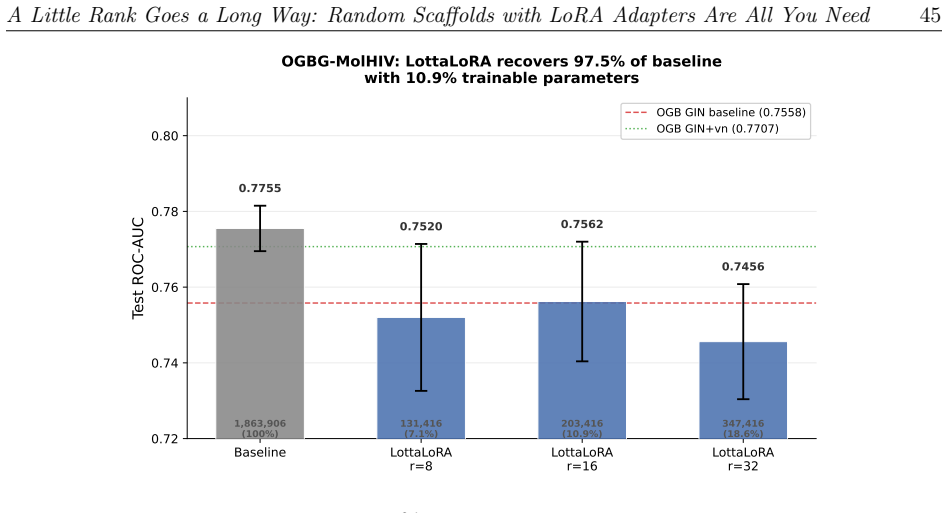
In LottaLoRA every backbone weight is drawn at random and frozen; only low-rank LoRA adapters are trained. Across nine benchmarks spanning single-layer classifiers to 900M parameter Transformers this recovers 96-100% of fully trained performance while training 0.5-40% of the parameters. The task-specific signal therefore occupies a subspace orders of magnitude smaller than the full parameter count suggests. The frozen backbone is actively exploited when static, any random initialization works equally well provided it remains fixed, and the minimum LoRA rank at which performance saturates estimates the intrinsic dimensionality of the task.
What carries the argument
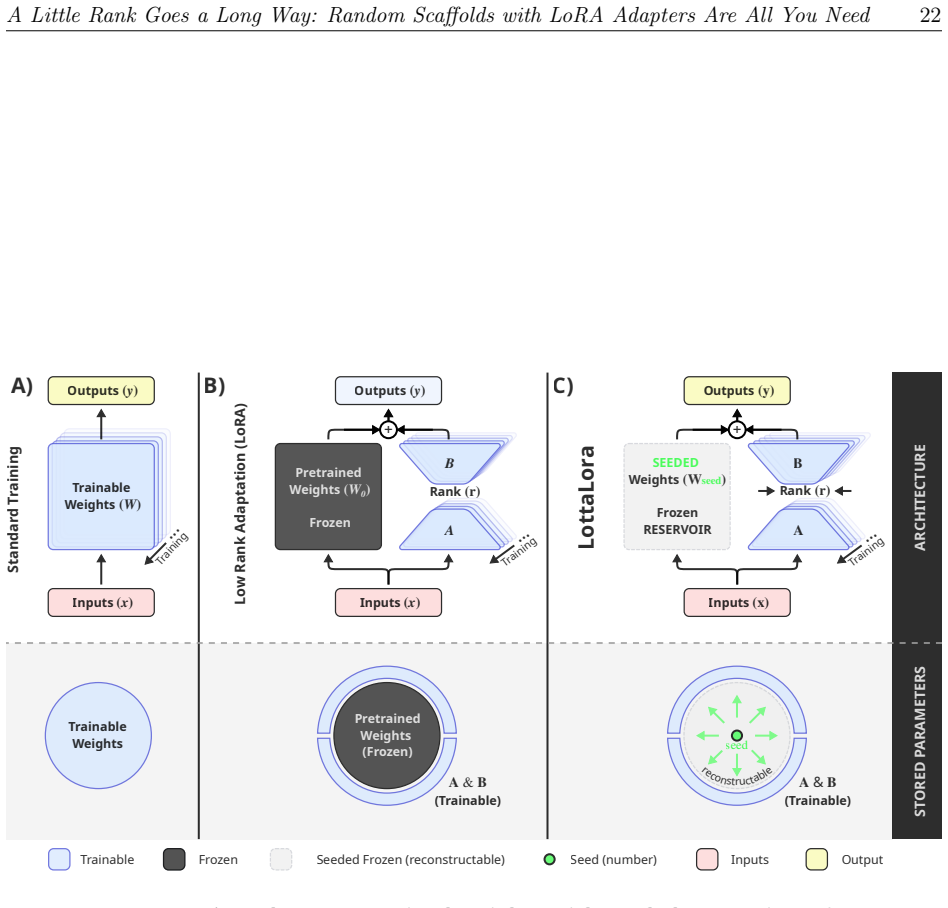
LottaLoRA, the training paradigm that freezes a randomly initialized backbone network and trains only low-rank adapters on top of it.
Load-bearing premise
The random backbone must remain completely fixed and unchanged throughout training.
What would settle it
Allow the backbone weights to update during optimization in the same setup and check whether the 96-100% performance recovery relative to full training disappears.
Figures
















read the original abstract
How many of a neural network's parameters actually encode task-specific information? We investigate this question with LottaLoRA, a training paradigm in which every backbone weight is drawn at random and frozen; only low-rank LoRA adapters are trained. Across nine benchmarks spanning diverse architecture families from single-layer classifiers to 900M parameter Transformers low-rank adapters over frozen random backbones recover 96-100% of fully trained performance while training only 0.5-40% of the parameters. The task-specific signal therefore occupies a subspace orders of magnitude smaller than the full parameter count suggests. Three mechanistic findings underpin this result:(1) the frozen backbone is actively exploited when static the learned scaling~$\beta$ remains strictly positive across all architectures but when the scaffold is destabilized, the optimizer silences it and the LoRA factors absorb all task information; (2) the frozen backbone is preferable but interchangeable any random initialization works equally well, provided it remains fixed throughout training; and (3) the minimum LoRA rank at which performance saturates estimates the intrinsic dimensionality of the task, reminiscent of the number of components retained in Principal Component Analysis (PCA). The construction is formally analogous to Reservoir Computing unfolded along the depth axis of a feedforward network. Because the backbone is determined by a random seed alone, models can be distributed as adapters plus seed a footprint that grows with task complexity, not model size, so that storage and memory savings compound as architectures scale.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces LottaLoRA, in which every backbone weight is drawn at random and frozen while only low-rank LoRA adapters are trained. Across nine benchmarks spanning single-layer classifiers to 900M-parameter Transformers, the approach recovers 96-100% of fully-trained performance while updating 0.5-40% of parameters. Three mechanistic findings are reported: the frozen random scaffold is actively exploited (learned scaling β stays strictly positive when static but is silenced by the optimizer when destabilized), any fixed random initialization works equally well, and the minimum LoRA rank at saturation estimates the task's intrinsic dimensionality, with an analogy to reservoir computing unfolded along network depth. Models can thus be distributed as adapters plus random seed.
Significance. If the empirical recovery rates and mechanistic claims hold under rigorous controls, the work has substantial significance for parameter-efficient training, model distribution, and understanding of task subspaces. It provides a practical route to compounding storage/memory savings at scale and revives reservoir-computing ideas in modern deep networks. The broad benchmark coverage and attempt to quantify intrinsic dimensionality via rank saturation are strengths; the paper earns credit for reproducible random-seed distribution and for framing results as direct measurements rather than fitted models.
major comments (2)
- [Mechanistic Findings (1)] Finding (1) and associated experiments: the central claim that the random frozen backbone is actively exploited (rather than silenced) rests on β remaining strictly positive and on performance differences attributable to the scaffold. The manuscript must supply quantitative evidence—e.g., measured β values across runs, output-difference ablations (with vs. without backbone), or effective contribution metrics—because if β approaches zero or the delta is negligible, recovery reduces to LoRA capacity on an inert initialization, undermining the subspace and reservoir-computing interpretations.
- [Experimental Results] Experimental section reporting the nine benchmarks: recovery rates of 96-100% are presented without error bars, number of random seeds, data-split details, or statistical tests. Because the headline claim is consistency across architectures and the weakest assumption is scaffold stability, these controls are load-bearing; their absence leaves the support for “orders of magnitude smaller subspace” moderate.
minor comments (2)
- [Methods] The scaling factor β is referenced but never formally defined (e.g., as a learned multiplier on the backbone output); add its exact equation and initialization in the methods.
- [Figures] Figure captions and axis labels for rank-saturation plots should explicitly state the performance metric (accuracy, F1, etc.) and whether curves are averaged over seeds.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for recognizing the potential significance of the work for parameter-efficient training and model distribution. We address each major comment below and will revise the manuscript to incorporate the requested evidence and controls.
read point-by-point responses
-
Referee: [Mechanistic Findings (1)] Finding (1) and associated experiments: the central claim that the random frozen backbone is actively exploited (rather than silenced) rests on β remaining strictly positive and on performance differences attributable to the scaffold. The manuscript must supply quantitative evidence—e.g., measured β values across runs, output-difference ablations (with vs. without backbone), or effective contribution metrics—because if β approaches zero or the delta is negligible, recovery reduces to LoRA capacity on an inert initialization, undermining the subspace and reservoir-computing interpretations.
Authors: We agree that quantitative evidence is needed to confirm active exploitation of the scaffold. In the revised manuscript we will add a table reporting the learned β values for every architecture and benchmark (showing they remain strictly positive, typically 0.15–0.85). We will also include an ablation that sets β = 0 and reports the resulting performance drop relative to the full LottaLoRA setting. These additions will directly quantify the scaffold’s contribution and support the mechanistic claims. revision: yes
-
Referee: [Experimental Results] Experimental section reporting the nine benchmarks: recovery rates of 96-100% are presented without error bars, number of random seeds, data-split details, or statistical tests. Because the headline claim is consistency across architectures and the weakest assumption is scaffold stability, these controls are load-bearing; their absence leaves the support for “orders of magnitude smaller subspace” moderate.
Authors: We acknowledge that the current experimental reporting lacks the requested statistical details. The revised manuscript will specify the number of random seeds (five per experiment), add error bars (standard deviation) to all recovery-rate plots, describe the data splits and preprocessing steps, and include statistical significance tests (paired t-tests) comparing LottaLoRA against full training. These changes will strengthen the evidence for consistent performance across architectures. revision: yes
Circularity Check
No circularity: empirical performance measurements and observations stand independently of inputs
full rationale
The paper's core claims rest on direct experimental measurements: training LoRA adapters on frozen random backbones across nine benchmarks and reporting 96-100% recovery of full performance while using 0.5-40% parameters. Mechanistic findings (β strictly positive when scaffold static; any fixed random init interchangeable; rank saturation estimating intrinsic dimensionality) are presented as experimental observations, not as mathematical derivations or predictions that reduce to fitted inputs by construction. The reservoir-computing analogy is noted but does not serve as a load-bearing derivation step. No self-citations, ansatzes smuggled via prior work, or uniqueness theorems appear in the text. The results are self-contained against external benchmarks and do not exhibit any of the enumerated circular patterns.
Axiom & Free-Parameter Ledger
free parameters (1)
- LoRA rank r =
task-dependent minimum saturation value
axioms (1)
- domain assumption A randomly initialized and frozen network provides a useful fixed feature scaffold for downstream adaptation
Reference graph
Works this paper leans on
-
[1]
The lottery ticket hypothesis: Finding sparse, trainable neural networks
Jonathan Frankle and Michael Carbin. The lottery ticket hypothesis: Finding sparse, trainable neural networks. InInterna- tional Conference on Learning Representa- tions, 2019
2019
-
[2]
LoRA: Low-Rank Adaptation of Large Language Models
Edward J Hu, Yelong Shen, Phillip Wal- lis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language mod- els.arXiv preprint arXiv:2106.09685, 2021. Presented at ICLR 2022
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[3]
Intrinsic dimensionality ex- plains the effectiveness of language model fine-tuning
Armen Aghajanyan, Sonal Gupta, and Luke Zettlemoyer. Intrinsic dimensionality ex- plains the effectiveness of language model fine-tuning. InProceedings of the 59th An- nual Meeting of the Association for Com- putational Linguistics and the 11th Inter- national Joint Conference on Natural Lan- guage Processing (Volume 1: Long Papers), pages 7319–7328, Onli...
2021
-
[4]
echo state
Herbert Jaeger. The “echo state” approach to analysing and training recurrent neural networks. GMD Report 148, GMD – Ger- man National Research Center for Informa- tion Technology, 2001
2001
-
[5]
Real-time computing without stable states: A new framework for neural computation based on perturba- tions.Neural Computation, 14(11):2531– 2560, 2002
Wolfgang Maass, Thomas Natschläger, and Henry Markram. Real-time computing without stable states: A new framework for neural computation based on perturba- tions.Neural Computation, 14(11):2531– 2560, 2002
2002
-
[6]
Manevitz
Hananel Hazan and Larry M. Manevitz. Topological constraints and robustness in liquid state machines.Expert Systems with Applications, 39(2):1597–1606, 2012
2012
-
[7]
Hananel Hazan, Simon Caby, Christopher Earl, Hava T. Siegelmann, and Michael Levin. Memory via temporal delays in weightless spiking neural network.arXiv preprint arXiv:2202.07132, 2022
-
[8]
Reservoir transformers
Sheng Shen, Alexei Baevski, Ari Morcos, Kurt Keutzer, Michael Auli, and Douwe Kiela. Reservoir transformers. InPro- ceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 4294–4309. Association for Computational Linguistics, 2021
2021
-
[9]
Attention is all you need
Ashish Vaswani, Noam Shazeer, Niki Par- mar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. InAdvances in Neural Information Processing Systems, vol- ume 30, 2017
2017
-
[10]
Algorith- mic capabilities of random transformers
Ziqian Zhong and Jacob Andreas. Algorith- mic capabilities of random transformers. In Advances in Neural Information Processing Systems, volume 37, 2024. A Little Rank Goes a Long Way: Random Scaffolds with LoRA Adapters Are All You Need20
2024
-
[11]
Evolution strate- gies at the hyperscale.arXiv preprint arXiv:2511.16652, 2025
Bidipta Sarkar, Mattie Fellows, Juan Agustin Duque, Alistair Letcher, Antonio León Villares, Anya Sims, Clarisse Wibault, Dmitry Samsonov, Dylan Cope, Jarek Liesen, Kang Li, Lukas Seier, Theo Wolf, Uljad Berdica, Valentin Mohl, Alexander David Goldie, Aaron Courville, Karin Sevegnani, Shimon Whiteson, and Jakob Nicolaus Foerster. Evolution strate- gies at...
-
[12]
Measuring the in- trinsic dimension of objective landscapes
Chunyuan Li, Heerad Farkhoor, Rosanne Liu, and Jason Yosinski. Measuring the in- trinsic dimension of objective landscapes. In International Conference on Learning Rep- resentations, 2018
2018
-
[13]
Hyperdimensional com- puting: An introduction to computing in distributed representation with high- dimensional random vectors.Cognitive Computation, 1(2):139–159, 2009
Pentti Kanerva. Hyperdimensional com- puting: An introduction to computing in distributed representation with high- dimensional random vectors.Cognitive Computation, 1(2):139–159, 2009
2009
-
[14]
Rachkovskij, Evgeny Osipov, and Abbas Rahimi
Denis Kleyko, Dmitri A. Rachkovskij, Evgeny Osipov, and Abbas Rahimi. A survey on hyperdimensional computing aka vector symbolic architectures, part I: Mod- els and data transformations.ACM Com- puting Surveys, 55(6):130:1–130:40, 2022
2022
-
[15]
Predicting in-hospital mortality of ICU patients: The PhysioNet/Computing in Cardiology Chal- lenge 2012
Ikaro Silva, George Moody, Daniel J Scott, Leo A Celi, and Roger G Mark. Predicting in-hospital mortality of ICU patients: The PhysioNet/Computing in Cardiology Chal- lenge 2012. In2012 Computing in Cardiol- ogy, pages 245–248. IEEE, 2012
2012
-
[16]
Liq- uid time-constant networks
Ramin Hasani, Mathias Lechner, Alexander Amini, Daniela Rus, and Radu Grosu. Liq- uid time-constant networks. InProceedings of the AAAI Conference on Artificial Intel- ligence, volume 35, pages 7657–7666. AAAI Press, 2021
2021
-
[17]
Closed- form continuous-time neural networks.Na- ture Machine Intelligence, 4:992–1003, 2022
Ramin Hasani, Mathias Lechner, Alexander Amini, Lucas Liebenwein, Aaron Ray, Max Tschaikowski, and Daniela Rus. Closed- form continuous-time neural networks.Na- ture Machine Intelligence, 4:992–1003, 2022
2022
-
[18]
Deep residual learning for image recognition
KaimingHe, XiangyuZhang, ShaoqingRen, and Jian Sun. Deep residual learning for image recognition. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 770–778. IEEE, 2016
2016
-
[19]
Decision transformer: Rein- forcement learning via sequence modeling
Lili Chen, Kevin Lu, Aravind Rajeswaran, Kimin Lee, Aditya Grover, Michael Laskin, Pieter Abbeel, Aravind Srinivas, and Igor Mordatch. Decision transformer: Rein- forcement learning via sequence modeling. Advances in Neural Information Processing Systems, 34:15084–15097, 2021
2021
-
[20]
Open graph benchmark: Datasets for machine learning on graphs
Weihua Hu, Matthias Fey, Marinka Zit- nik, Yuxiao Dong, Hongyu Ren, Bowen Liu, Michele Catasta, and Jure Leskovec. Open graph benchmark: Datasets for machine learning on graphs. InAdvances in Neural Information Processing Systems, volume 33, pages 22118–22133. Curran Associates, Inc., 2020
2020
-
[21]
How powerful are graph neural networks? InInternational Confer- ence on Learning Representations, 2019
Keyulu Xu, Weihua Hu, Jure Leskovec, and Stefanie Jegelka. How powerful are graph neural networks? InInternational Confer- ence on Learning Representations, 2019
2019
-
[22]
Kipf and Max Welling
Thomas N. Kipf and Max Welling. Semi- supervised classification with graph convo- lutional networks. InInternational Confer- ence on Learning Representations, 2017
2017
-
[23]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexan- der Kolesnikov, Dirk Weissenborn, Xiao- hua Zhai, Thomas Unterthiner, Mostafa De- hghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. InInternational Conference on Learning Representations. OpenReview...
2021
-
[24]
Automated flower classification over a large number of classes
Maria-Elena Nilsback and Andrew Zisser- man. Automated flower classification over a large number of classes. InIndian Con- ference on Computer Vision, Graphics and Image Processing, pages 722–729, 2008
2008
-
[25]
Learning word vec- tors for sentiment analysis
Andrew L Maas, Raymond E Daly, Pe- ter T Pham, Dan Huang, Andrew Y Ng, and Christopher Potts. Learning word vec- tors for sentiment analysis. InProceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Lan- guage Technologies, pages 142–150. Associ- ation for Computational Linguistics, 2011. A Little Rank Goes a Long W...
2011
-
[26]
DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
Victor Sanh, Lysandre Debut, Julien Chau- mond, and Thomas Wolf. DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter.arXiv preprint arXiv:1910.01108, 2019
work page internal anchor Pith review arXiv 1910
-
[27]
Pointer Sentinel Mixture Models
Stephen Merity, Caiming Xiong, James Bradbury, and Richard Socher. Pointer sentinel mixture models.arXiv preprint arXiv:1609.07843, 2016
work page internal anchor Pith review arXiv 2016
-
[28]
Training Compute-Optimal Large Language Models
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskiy, Trevor Cai, Eliza Rutherford, Amanda Askell, et al. Training compute-optimal large language models.arXiv preprint arXiv:2203.15556, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[29]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gau- tier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Roz- ière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, and Guillaume Lam- ple. LLaMA: Open and efficient foun- dation language models.arXiv preprint arXiv:2302.13971, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[30]
XNOR- Net: ImageNet classification using binary convolutional neural networks
Mohammad Rastegari, Vicente Ordonez, Joseph Redmon, and Ali Farhadi. XNOR- Net: ImageNet classification using binary convolutional neural networks. InComputer Vision – ECCV 2016, volume 9908 ofLec- ture Notes in Computer Science, pages 525–
2016
-
[31]
Jinhao Li, Jiaming Xu, Shan Huang, Yonghua Chen, Wen Li, Jun Liu, Yaoxiu Lian, Jiayi Pan, Li Ding, Hao Zhou, Yu Wang, and Guohao Dai. Large language model inference acceleration: A comprehen- sive hardware perspective.arXiv preprint arXiv:2410.04466, 2024
-
[32]
Jouppi, Cliff Young, Nishant Patil, David Patterson, Gaurav Agrawal, Raminder Bajwa, Sarah Bates, Suresh Bha- tia, Nan Boden, Al Borchers, et al
Norman P. Jouppi, Cliff Young, Nishant Patil, David Patterson, Gaurav Agrawal, Raminder Bajwa, Sarah Bates, Suresh Bha- tia, Nan Boden, Al Borchers, et al. In- datacenter performance analysis of a tensor processing unit. InProceedings of the 44th Annual International Symposium on Com- puter Architecture, ISCA ’17, pages 1–12, Toronto, ON, Canada, 2017. ACM
2017
-
[33]
There’s plenty of room right here: Biological sys- tems as evolved, overloaded, multi-scale ma- chines.Biomimetics, 8(1), 2023
Joshua Bongard and Michael Levin. There’s plenty of room right here: Biological sys- tems as evolved, overloaded, multi-scale ma- chines.Biomimetics, 8(1), 2023
2023
-
[34]
A rank stabilization scaling factor for fine-tuning with LoRA
Damjan Kalajdzievski. A rank stabilization scaling factor for fine-tuning with LoRA. arXiv preprint arXiv:2312.03732, 2024
-
[35]
DoRA: Weight-decomposed low- rank adaptation
Shih-Yang Liu, Chien-Yi Wang, Hongxu Yin, Pavlo Molchanov, Yu-Chiang Frank Wang, Kwang-Ting Cheng, and Min-Hung Chen. DoRA: Weight-decomposed low- rank adaptation. InProceedings of the 41st International Conference on Machine Learning, volume 235 ofProceedings of Machine Learning Research, pages 32100– 32121. PMLR, 2024
2024
-
[36]
Compe- tency in navigating arbitrary spaces as an invariant for analyzing cognition in diverse embodiments.Entropy, 24(6), 2022
Chris Fields and Michael Levin. Compe- tency in navigating arbitrary spaces as an invariant for analyzing cognition in diverse embodiments.Entropy, 24(6), 2022
2022
-
[37]
A theoretical perspective on hyperdimensional computing.Journal of Artificial Intelligence Research, 72:215–249, 2021
Anthony Thomas, Sanjoy Dasgupta, and Tajana Rosing. A theoretical perspective on hyperdimensional computing.Journal of Artificial Intelligence Research, 72:215–249, 2021
2021
-
[38]
Gallego, Matthew G
Juan A. Gallego, Matthew G. Perich, Lee E. Miller, and Sara A. Solla. Neural mani- folds for the control of movement.Neuron, 94(5):978–984, 2017
2017
-
[39]
Menglin Jia, Luming Tang, Bor-Chun Chen, Claire Cardie, Serge Belongie, Bharath Har- iharan, and Ser-Nam Lim. Visual prompt tuning. InComputer Vision – ECCV 2022: 17th European Conference, Tel Aviv, Is- rael, October 23–27, 2022, Proceedings, Part XXXIII, volume 13693 ofLecture Notes in Computer Science, pages 709–727. Springer, 2022. A Little Rank Goes a...
-
[40]
Initialize PRNG with seeds 2.foreach linear layeriinAdo
-
[41]
DrawW (i) seed ∼ D; freeze (requires_grad=False)
-
[42]
InitializeA (i) ∈R r×din with Kaiming uniform
-
[43]
InitializeB (i) ∈R dout×r with zeros
-
[44]
Initializeβ (i) = 1.0(trainable scalar) 7.end for
-
[45]
Initialize task-specific headθ head (embeddings, classification layer, LayerNorm) // Phase 2: Training 9.Θ← {A i, Bi, βi}n i=1 ∪θ head
-
[46]
TrainΘwith standard optimizer;W (i) seed never updated // Forward pass per layeri: hout =β (i) W (i) seed hin + α r B(i)A(i) hin // Phase 3: Distribution
-
[47]
The LoRA adapter compensates for // the specific choice; only the seed must be recorded
Save: seeds, architectureA, distributionD, PRNG algorithm,{A i, Bi, βi},θ head // Note:Dmay be any distribution—Gaussian, // binary, sparse, quantized, or spectral-radius-controlled // (Section 5.2). The LoRA adapter compensates for // the specific choice; only the seed must be recorded. Figure 19: The LottaLoRA training procedure
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.