Recognition: unknown
MeshOn: Intersection-Free Mesh-to-Mesh Composition
Pith reviewed 2026-05-10 16:41 UTC · model grok-4.3
The pith
MeshOn fits an accessory mesh onto a base mesh in a target region by initializing rigid alignment with vision-language models, then optimizing geometric attractions against a physics barrier to block intersections, followed by diffusion-pri
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MeshOn demonstrates that a three-stage optimization—vision-language rigid initialization, combined geometric attraction and physics-inspired barrier losses, and diffusion-guided final deformation—can produce physically plausible, intersection-free fittings of one mesh onto another while preserving semantic intent and integrating directly with existing artist workflows.
What carries the argument
A multi-step optimization that couples attractive geometric losses with a physics-inspired barrier loss to enforce non-intersection, seeded by vision-to-language rigid alignment and completed by diffusion-prior deformation.
If this is right
- Accessories made of rigid, soft, or articulated materials can be placed over a wide range of target body regions without manual collision resolution.
- The compositions remain compatible with standard 3D artist tools because they output deformed meshes rather than implicit fields or point clouds.
- The barrier term guarantees that the final surfaces do not penetrate even when the accessory must wrap around curved or concave target geometry.
- Optional text conditioning allows semantic guidance without requiring the user to supply explicit correspondence points.
Where Pith is reading between the lines
- The same barrier-plus-diffusion pattern could be applied to animate the composed object while preserving non-intersection across frames.
- Replacing the vision-language initializer with a learned pose predictor trained on the same loss might remove the need for text prompts altogether.
- The method’s emphasis on artist workflow compatibility suggests it could serve as a plug-in for existing sculpting packages rather than a standalone generator.
Load-bearing premise
The vision-to-language model supplies an initial rigid pose close enough that the subsequent optimization can escape poor local minima and reach a non-intersecting solution.
What would settle it
Running the pipeline on a diverse test set of accessory-base pairs and finding that more than a small fraction of outputs still contain surface intersections or visibly implausible deformations after all stages would falsify the central claim.
Figures






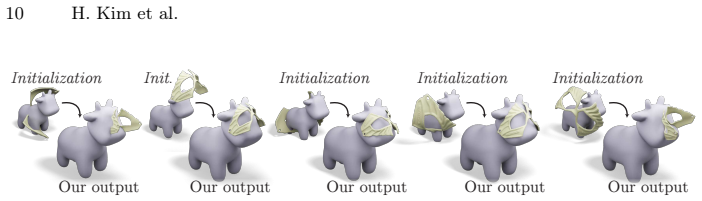




read the original abstract
We propose MeshOn, a method that finds physically and semantically realistic compositions of two input meshes. Given an accessory, a base mesh with a user-defined target region, and optional text strings for both meshes, MeshOn uses a multi-step optimization framework to realistically fit the meshes onto each other while preventing intersections. We initialize the shapes' rigid configuration via a structured alignment scheme using Vision-to-Language Models, which we then optimize using a combination of attractive geometric losses, and a physics-inspired barrier loss that prevents surface intersections. We then obtain a final deformation of the object, assisted by a diffusion prior. Our method successfully fits accessories of various materials over a breadth of target regions, and is designed to fit directly into existing digital artist workflows. We demonstrate the robustness and accuracy of our pipeline by comparing it with generative approaches and traditional registration algorithms.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. MeshOn proposes a multi-step optimization pipeline for composing an accessory mesh onto a base mesh within a user-specified target region. It initializes rigid alignment using vision-to-language models, optimizes the configuration with attractive geometric losses plus a physics-inspired barrier loss to avoid surface intersections, and applies a diffusion prior to deform the accessory. The method claims to produce physically and semantically realistic, intersection-free results that integrate into existing digital artist workflows, with qualitative demonstrations against generative and registration baselines.
Significance. If the intersection-free guarantee and robustness claims hold with supporting evidence, the work would offer a practical advance for automated 3D asset composition in graphics and animation pipelines. The combination of VLM-guided initialization, barrier terms, and diffusion priors addresses a common pain point in mesh fitting, and explicit workflow compatibility is a positive aspect. However, the absence of quantitative metrics in the provided description limits assessment of whether the approach meaningfully outperforms existing methods.
major comments (2)
- [Optimization and deformation sections] The central claim of producing truly intersection-free output meshes relies on the physics-inspired barrier loss during rigid alignment and the subsequent diffusion-based deformation. This loss is described as a soft penalty (typically based on penetration depth or signed distance), which does not provide a strict guarantee of zero intersections after the diffusion step alters vertex positions. The paper must add explicit post-processing verification (e.g., minimum signed-distance histograms or penetration-volume statistics across all test cases) and report failure rates; without this, the headline claim remains unverified. (Optimization and deformation sections.)
- [Evaluation section] The abstract states that robustness and accuracy are demonstrated via comparisons to generative approaches and traditional registration algorithms, yet no quantitative metrics, error bars, intersection-rate tables, or details on how intersections are measured are referenced. The evaluation section should include specific numbers (e.g., mean penetration depth, success rates over a benchmark set) and ablation studies on the barrier loss weight to substantiate the superiority claims.
minor comments (2)
- Clarify the exact formulation and weighting of the barrier loss relative to the attractive geometric terms, including any schedule for the loss weights during optimization.
- The optional text strings for the meshes are mentioned but their precise role in the VLM alignment or diffusion prior could be illustrated with an example or diagram.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help strengthen the verification of our intersection-free claims and the quantitative evaluation of MeshOn. We address each point below and have revised the manuscript and supplementary material accordingly.
read point-by-point responses
-
Referee: The central claim of producing truly intersection-free output meshes relies on the physics-inspired barrier loss during rigid alignment and the subsequent diffusion-based deformation. This loss is described as a soft penalty, which does not provide a strict guarantee of zero intersections after the diffusion step alters vertex positions. The paper must add explicit post-processing verification (e.g., minimum signed-distance histograms or penetration-volume statistics across all test cases) and report failure rates.
Authors: We agree that the barrier loss is a soft constraint and that the diffusion deformation step can in principle introduce intersections. In the revised manuscript we have added a post-processing verification pipeline that computes per-vertex signed-distance fields between the final accessory and base meshes, reports minimum signed-distance values, penetration volumes, and failure rates (cases with positive penetration volume) over the full test set. Histograms of signed distances and a table of aggregate statistics are now included in the supplementary material, providing the requested empirical support for the headline claim. revision: yes
-
Referee: The abstract states that robustness and accuracy are demonstrated via comparisons to generative approaches and traditional registration algorithms, yet no quantitative metrics, error bars, intersection-rate tables, or details on how intersections are measured are referenced. The evaluation section should include specific numbers (e.g., mean penetration depth, success rates over a benchmark set) and ablation studies on the barrier loss weight to substantiate the superiority claims.
Authors: We acknowledge the value of quantitative evidence. The revised evaluation section now contains a table reporting mean penetration depth, intersection rate, and success rate (zero-penetration cases) over a benchmark of 50 compositions, with error bars from three independent runs per method. We also added an ablation study that varies the barrier-loss weight and plots its effect on both intersection rate and geometric fitting error, allowing direct comparison against the generative and registration baselines. revision: yes
Circularity Check
No circularity: optimization pipeline with no self-referential derivations
full rationale
The paper describes a multi-step algorithmic pipeline (VLM-based rigid initialization, geometric + barrier losses, diffusion-assisted deformation) rather than any closed-form derivation or mathematical claim. No equations are presented that reduce outputs to fitted inputs by construction, no self-citations are invoked to justify uniqueness or ansatzes, and no predictions are statistically forced from subsets of the same data. The central claims rest on empirical demonstration of the method, which is self-contained against external benchmarks and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
free parameters (1)
- loss weights
axioms (2)
- domain assumption Vision-to-language models produce semantically plausible initial rigid poses for mesh pairs
- domain assumption Diffusion priors yield realistic non-intersecting deformations
Forward citations
Cited by 2 Pith papers
-
SpUDD: Superpower Contouring of Unsigned Distance Data
SpUDD defines superpower contours on power diagrams of unsigned distance samples, proves their convergence to the true surface, and uses them to generate approximating meshes that outperform other strategies for this ...
-
SpUDD: Superpower Contouring of Unsigned Distance Data
SpUDD defines superpower contours from power diagrams of unsigned distance samples, proves convergence to the true surface, and uses them to generate approximating polygonal meshes that outperform prior strategies.
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2205.02904 (2022)
Aigerman, N., Gupta, K., Kim, V.G., Chaudhuri, S., Saito, J., Groueix, T.: Neural jacobian fields: Learning intrinsic mappings of arbitrary meshes. arXiv preprint arXiv:2205.02904 (2022)
-
[2]
In: Proceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition
Aoki, Y., Goforth, H., Srivatsan, R.A., Lucey, S.: Pointnetlk: Robust & efficient point cloud registration using pointnet. In: Proceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition. pp. 7163–7172 (2019)
2019
-
[3]
In: Proceedings of the 25th annual conference on Computer graphics and interactive techniques
Baraff, D., Witkin, A.: Large steps in cloth simulation. In: Proceedings of the 25th annual conference on Computer graphics and interactive techniques. pp. 43–54 (1998)
1998
-
[4]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Barda, A., Gadelha, M., Kim, V.G., Aigerman, N., Bermano, A.H., Groueix, T.: Instant3dit: Multiview inpainting for fast editing of 3d objects. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 16273–16282 (2025)
2025
-
[5]
In: Sensor fusion IV: control paradigms and data structures
Besl, P.J., McKay, N.D.: Method for registration of 3-d shapes. In: Sensor fusion IV: control paradigms and data structures. vol. 1611, pp. 586–606. Spie (1992)
1992
-
[6]
IEEE Transactions on Visualization and Computer Graphics14(1), 213–230 (2008)
Botsch, M., Sorkine, O.: On linear variational surface deformation methods. IEEE Transactions on Visualization and Computer Graphics14(1), 213–230 (2008). https://doi.org/10.1109/TVCG.2007.1054
-
[7]
In: ACM SIGGRAPH Asia (2024)
Chen, Y.C., Ling, S., Chen, Z., Kim, V.G., Gadelha, M., Jacobson, A.: Text-guided controllable mesh refinement for interactive 3d modeling. In: ACM SIGGRAPH Asia (2024)
2024
-
[8]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Choy, C.B., Dong, W., Koltun, V.: Deep global registration. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 2514–2523 (2020)
2020
-
[9]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Decatur, D., Lang, I., Hanocka, R.: 3d highlighter: Localizing regions on 3d shapes via text descriptions. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 20930–20939 (2023)
2023
-
[10]
In: Proceedings of the Computer Vision and Pattern Recognition Conference (CVPR)
Dinh, N.A., Lang, I., Kim, H., Stein, O., Hanocka, R.: Geometry in style: 3d stylization via surface normal deformation. In: Proceedings of the Computer Vision and Pattern Recognition Conference (CVPR). pp. 28456–28467 (2025)
2025
-
[11]
Computer Graphics Forum (2019)
Fulton, L., Modi, V., Duvenaud, D., Levin, D.I.W., Jacobson, A.: Latent-space dynamics for reduced deformable simulation. Computer Graphics Forum (2019)
2019
-
[12]
Gao, W., Aigerman, N., Groueix, T., Kim, V.G., Hanocka, R.: Textdeformer: Ge- ometrymanipulationusingtextguidance.In:ACMTransactionsonGraphics(SIG- GRAPH) (2023)
2023
-
[13]
In: 2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)
Guo, M., Tang, M., Cha, H., Zhang, R., Liu, C.K., Wu, J.: Craft: Designing creative and functional 3d objects. In: 2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV). pp. 7215–7224. IEEE (2025)
2025
-
[14]
arXiv preprint arXiv:2412.09548 , year=
Hao, Z., Romero, D.W., Lin, T.Y., Liu, M.Y.: Meshtron: High-fidelity, artist-like 3d mesh generation at scale. arXiv preprint arXiv:2412.09548 (2024)
-
[15]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Huang, S., Liang, Z., Cho, Y., Li, X., Wang, Y., Yang, Y.: Feature-metric regis- tration: A fast, robust, feature-metric deep learning method for point cloud reg- istration. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 9969–9978 (2020)
2020
-
[16]
In: ACM SIGGRAPH 2014 Courses (2014)
Jacobson, A., Deng, Z., Kavan, L., Lewis, J.: Skinning: Real-time shape deforma- tion. In: ACM SIGGRAPH 2014 Courses (2014)
2014
-
[17]
In: Thirty-seventh Conference on Neural Information Processing Systems (2023) 16 H
Jiang, H., Salzmann, M., Dang, Z., Xie, J., Yang, J.: Se (3) diffusion model-based point cloud registration for robust 6d object pose estimation. In: Thirty-seventh Conference on Neural Information Processing Systems (2023) 16 H. Kim et al
2023
-
[18]
ACM Trans
Kerbl, B., Kopanas, G., Leimkühler, T., Drettakis, G.: 3d gaussian splatting for real-time radiance field rendering. ACM Trans. Graph.42(4), 139–1 (2023)
2023
-
[19]
In: 2025 International Conference on 3D Vision (3DV)
Kim, H., Lang, I., Aigerman, N., Groueix, T., Kim, V.G., Hanocka, R.: Meshup: Multi-target mesh deformation via blended score distillation. In: 2025 International Conference on 3D Vision (3DV). pp. 222–239. IEEE (2025)
2025
-
[20]
arXiv preprint arXiv:2403.19272 (2024)
Lan, L., Lu, Z., Long, J., Yuan, C., Li, X., He, X., Wang, H., Jiang, C., Yang, Y.: Efficient gpu cloth simulation with non-distance barriers and subspace reuse. arXiv preprint arXiv:2403.19272 (2024)
-
[21]
In: Proceedings of the International Conference on 3D Vision (3DV)
Lang, I., Ginzburg, D., Avidan, S., Raviv, D.: DPC: Unsupervised Deep Point Cor- respondence via Cross and Self Construction. In: Proceedings of the International Conference on 3D Vision (3DV). pp. 1442–1451 (2021)
2021
-
[22]
ACM Trans
Li, M., Ferguson, Z., Schneider, T., Langlois, T.R., Zorin, D., Panozzo, D., Jiang, C., Kaufman, D.M.: Incremental potential contact: intersection-and inversion-free, large-deformation dynamics. ACM Trans. Graph.39(4), 49 (2020)
2020
-
[23]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition
Lin, C.H., Gao, J., Tang, L., Takikawa, T., Zeng, X., Huang, X., Kreis, K., Fidler, S., Liu, M.Y., Lin, T.Y.: Magic3d: High-resolution text-to-3d content creation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition. pp. 300–309 (2023)
2023
-
[24]
In: European Conference on Computer Vision
Lin, Z., Pathak, D., Li, B., Li, J., Xia, X., Neubig, G., Zhang, P., Ramanan, D.: Evaluating text-to-visual generation with image-to-text generation. In: European Conference on Computer Vision. pp. 366–384. Springer (2024)
2024
-
[25]
In: Proceedings of the IEEE International Conference on Computer Vision (ICCV)
Litany, O., Remez, T., Rodolà, E., Bronstein, A.M., Bronstein, M.M.: Deep func- tional maps: Structured prediction for dense shape correspondence. In: Proceedings of the IEEE International Conference on Computer Vision (ICCV). pp. 5660–5668. IEEE Computer Society (Oct 2017).https://doi.org/10.1109/ICCV.2017.603, https://openaccess.thecvf.com/content_ICCV_...
-
[26]
In: Proceedings of the SPIE Videometrics VIII (2003)
McKay, N.D.: 3d registration: A review of techniques. In: Proceedings of the SPIE Videometrics VIII (2003)
2003
-
[27]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (CVPR)
Michel, O., Bar-On, R., Liu, R., Benaim, S., Hanocka, R.: Text2mesh: Text-driven neural stylization for meshes. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (CVPR). pp. 13492–13502 (2022)
2022
-
[28]
Commu- nications of the ACM65(1), 99–106 (2021)
Mildenhall, B., Srinivasan, P.P., Tancik, M., Barron, J.T., Ramamoorthi, R., Ng, R.: Nerf: Representing scenes as neural radiance fields for view synthesis. Commu- nications of the ACM65(1), 99–106 (2021)
2021
-
[29]
In: International conference on machine learning
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International conference on machine learning. pp. 8748–8763. PmLR (2021)
2021
-
[30]
ACM Transactions on Graphics (TOG)34(6), 1–14 (2015)
Sacht, L., Vouga, E., Jacobson, A.: Nested cages. ACM Transactions on Graphics (TOG)34(6), 1–14 (2015)
2015
-
[31]
Image and Vision Computing25(5), 578–596 (2007)
Salvi,J.,Matabosch,C.,Fofi,D.,Forest,J.:Areviewofrecentregistrationmethods for 3d modelling. Image and Vision Computing25(5), 578–596 (2007)
2007
-
[32]
In: Robotics: science and sys- tems
Segal, A., Haehnel, D., Thrun, S.: Generalized-icp. In: Robotics: science and sys- tems. vol. 2, p. 435. Seattle, WA (2009)
2009
-
[33]
AK Peters/CRC Press (2009)
Shirley, P., Ashikhmin, M., Marschner, S.: Fundamentals of computer graphics. AK Peters/CRC Press (2009)
2009
-
[34]
In: Acm siggraph 2012 courses, pp
Sifakis,E.,Barbic,J.:Femsimulationof3ddeformablesolids:apractitioner’sguide to theory, discretization and model reduction. In: Acm siggraph 2012 courses, pp. 1–50 (2012) MeshOn: Intersection-Free Mesh-to-Mesh Composition 17
2012
-
[35]
In: Symposium on Geometry processing
Sorkine, O., Alexa, M.: As-rigid-as-possible surface modeling. In: Symposium on Geometry processing. vol. 4, pp. 109–116. Citeseer (2007)
2007
-
[36]
In: Proceedings of the 2004 Eurographics/ACM SIGGRAPH symposium on Geometry processing
Sorkine, O., Cohen-Or, D., Lipman, Y., Alexa, M., Rössl, C., Seidel, H.P.: Lapla- cian surface editing. In: Proceedings of the 2004 Eurographics/ACM SIGGRAPH symposium on Geometry processing. pp. 175–184 (2004)
2004
-
[37]
IEEE Transactions on Visualization and Computer Graphics19(7), 1199–1217 (2013)
Tam, G.K.L., Cheng, K., Lai, Y.K., Langbein, F.C., Liu, Y., Marshall, D., Martin, R.R., Sun, X.F., Rosin, P.L.: Registration of 3d point clouds: A survey. IEEE Transactions on Visualization and Computer Graphics19(7), 1199–1217 (2013)
2013
-
[38]
Gemini: A Family of Highly Capable Multimodal Models
Team, G., Anil, R., Borgeaud, S., Alayrac, J.B., Yu, J., Soricut, R., Schalkwyk, J., Dai, A.M., Hauth, A., Millican, K., et al.: Gemini: a family of highly capable multimodal models. arXiv preprint arXiv:2312.11805 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[39]
In: Proceedings of the AAAI conference on artificial intelligence
Wang, J., Chan, K.C., Loy, C.C.: Exploring clip for assessing the look and feel of images. In: Proceedings of the AAAI conference on artificial intelligence. vol. 37, pp. 2555–2563 (2023)
2023
-
[40]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) (October 2019)
Wang, Y., Solomon, J.M.: Deep closest point: Learning representations for point cloud registration. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) (October 2019)
2019
-
[41]
In: Proceedings of the IEEE/CVF international conference on computer vision
Wang, Y., Solomon, J.M.: Deep closest point: Learning representations for point cloud registration. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 3523–3532 (2019)
2019
-
[42]
The Visual Computer40(7), 4701–4712 (2024)
Xu, H., Wu, Y., Tang, X., Zhang, J., Zhang, Y., Zhang, Z., Li, C., Jin, X.: Fu- siondeformer: Text-guided mesh deformation using diffusion models. The Visual Computer40(7), 4701–4712 (2024)
2024
-
[43]
Xu, J., Cheng, W., Gao, Y., Wang, X., Gao, S., Shan, Y.: Instantmesh: Efficient 3d mesh generation from a single image with sparse-view large reconstruction models (2024),https://arxiv.org/abs/2404.07191
work page internal anchor Pith review arXiv 2024
-
[44]
In: European Conference on Computer Vision (ECCV) (2024)
Yang, H., Chen, Y., Pan, Y., Yao, T., Chen, Z., Wu, Z., Jiang, Y.G., Mei, T.: Dreammesh: Jointly manipulating and texturing triangle meshes for text-to-3d generation. In: European Conference on Computer Vision (ECCV) (2024)
2024
-
[45]
IEEE transactions on pattern analysis and machine intelligence38(11), 2241–2254 (2015)
Yang, J., Li, H., Campbell, D., Jia, Y.: Go-icp: A globally optimal solution to 3d icp point-set registration. IEEE transactions on pattern analysis and machine intelligence38(11), 2241–2254 (2015)
2015
-
[46]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2022)
Yew, Z.J., Lee, G.h.: Regtr: End-to-end point cloud correspondences with trans- formers. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2022)
2022
-
[47]
Yu, Y., Zhou, K., Xu, D., Shi, X., Bao, H., Guo, B., Shum, H.Y.: Mesh editing with poisson-based gradient field manipulation. In: ACM SIGGRAPH 2004 Papers. p. 644–651. SIGGRAPH ’04, Association for Computing Machinery, New York, NY, USA (2004).https://doi.org/10.1145/1186562.1015774,https://doi.org/ 10.1145/1186562.1015774
-
[48]
In: European conference on computer vision
Zhou, Q.Y., Park, J., Koltun, V.: Fast global registration. In: European conference on computer vision. pp. 766–782. Springer (2016)
2016
-
[49]
Open3D: A Modern Library for 3D Data Processing
Zhou, Q.Y., Park, J., Koltun, V.: Open3D: A modern library for 3D data process- ing. arXiv:1801.09847 (2018)
work page internal anchor Pith review arXiv 2018
-
[50]
good-enough
Zhou, Y., Barnes, C., Lu, J., Yang, J., Li, H.: On the continuity of rotation rep- resentations in neural networks. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 5745–5753 (2019) Supplementary Materials A Technical Details In this section, we will delineate some of the technical details and derivations we have ...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.